Mechatronikai rendszerek programozása C++ nyelven
Szerzői jog © 2014 Dr. Tamás Péter, Molnár József, Devecseri Viktor, Gräff József

A tananyag a TÁMOP-4.1.2.A/1-11/1-2011-0042 azonosító számú „ Mechatronikai mérnök MSc tananyagfejlesztés ” projekt keretében készült. A tananyagfejlesztés az Európai Unió támogatásával és az Európai Szociális Alap társfinanszírozásával valósult meg.

Kézirat lezárva: 2014 február
Lektorálta: Tóth Bertalan
A kiadásért felel a(z): BME MOGI
Felelős szerkesztő: BME MOGI
2014
- I. A C++ alapjai és adatkezelése
- I.1. A C++ programok készítése
- I.2. Alaptípusok, változók és konstansok
- I.3. Alapműveletek és kifejezések
- I.3.1. Az operátorok csoportosítása az operandusok száma alapján
- I.3.2. Elsőbbségi és csoportosítási szabályok
- I.3.3. Matematikai kifejezések
- I.3.4. Értékadás
- I.3.5. Léptető (inkrementáló/dekrementáló) műveletek
- I.3.6. Feltételek megfogalmazása
- I.3.7. Bitműveletek
- I.3.8. A vessző operátor
- I.3.9. Típuskonverziók
- I.4. Vezérlő utasítások
- I.5. Kivételkezelés
- I.6. Mutatók, hivatkozások és a dinamikus memóriakezelés
- I.7. Tömbök és sztringek
- I.8. Felhasználói típusok
- II. Moduláris programozás C++ nyelven
- II.1. Függvények - alapismeretek
- II.1.1. Függvények definíciója, hívása és deklarációja
- II.1.2. Függvények visszatérési értéke
- II.1.3. A függvények paraméterezése
- II.1.3.1. A paraméterátadás módjai
- II.1.3.2. Különböző típusú paraméterek használata
- II.1.3.2.1. Aritmetikai típusú paraméterek
- II.1.3.2.2. Felhasználói típusú paraméterek
- II.1.3.2.3. Tömbök átadása függvénynek
- II.1.3.2.4. Sztring argumentumok
- II.1.3.2.5. A függvény, mint argumentum
- II.1.3.2.6. Alapértelmezés szerinti (default) argumentumok
- II.1.3.2.7. Változó hosszúságú argumentumlista
- II.1.3.2.8. A main() függvény paraméterei és visszatérési értéke
- II.1.4. Programozás függvényekkel
- II.2. A függvényekről magasabb szinten
- II.3. Névterek és tárolási osztályok
- II.3.1. A változók tárolási osztályai
- II.3.2. A függvények tárolási osztályai
- II.3.3. Több modulból felépülő C++ programok
- II.3.4. Névterek
- II.4. A C++ előfeldolgozó utasításai
- III. Objektum-orientált programozás C++ nyelven
- III.1. Bevezetés az objektum-orientált világba
- III.2. Osztályok és objektumok
- III.2.1. A struktúráktól az osztályokig
- III.2.2. Az osztályokról bővebben
- III.2.3. Operátorok túlterhelése (operator overloading)
- III.3. Öröklés (származtatás)
- III.4. Polimorfizmus (többalakúság)
- III.5. Osztálysablonok (class templates)
- IV. A Microsoft Windows programozása C++ nyelven
- IV.1. A CLI specialitásai, a szabványos C++ és a C++/CLI
- IV.1.1. A nativ kód fordítási és futtatási folyamata Windows alatt
- IV.1.2. Problémák a natív kódú programok fejlesztése és használata során.
- IV.1.3. Platformfüggetlenség
- IV.1.4. Az MSIL kód futtatása
- IV.1.5. Integrált fejlesztő környezet
- IV.1.6. A vezérlők, vizuális programozás
- IV.1.7. A .NET keretrendszer
- IV.1.8. C#
- IV.1.9. A C++ bővitése a CLI-hez
- IV.1.10. A C++/CLI bővitett adattípusai
- IV.1.11. Az előredefiniált referencia osztály: String
- IV.1.12. A System::Convert statikus osztály
- IV.1.13. A CLI array template-tel megvalósitott tömb referencia osztálya
- IV.1.14. C++/CLI: Gyakorlati megvalósitás pl. a Visual Studio 2008-as változatban
- IV.1.15. Az Intellisense beépitett segítség
- IV.1.16. A CLR-es program típusának beállitása.
- IV.2. Az ablakmodell és az alapvezérlők.
- IV.2.1. A Form alapvezérlő
- IV.2.2. A Form vezérlő gyakran használt tulajdonságai
- IV.2.3. A Form vezérlő eseményei
- IV.2.4. A vezérlők állapotának aktualizálása
- IV.2.5. Alapvezérlők: Label (címke) vezérlő
- IV.2.6. Alapvezérlők: TextBox (szövegmező) vezérlő
- IV.2.7. Alapvezérlők: a Button (nyomógomb) vezérlő
- IV.2.8. Logikai értékekhez használható vezérlők: a CheckBox (jelölő négyzet)
- IV.2.9. Logikai értékekhez használható vezérlők: a RadioButton (opciós gomb)
- IV.2.10. Konténerobjektum vezérlő: a GroupBox (csoport mező)
- IV.2.11. Diszkrét értékeket bevivő vezérlők: a HscrollBar (vízszintes csúszka) és a VscrollBar (függőleges csúszka)
- IV.2.12. Egész szám beviteli vezérlője: NumericUpDown
- IV.2.13. Több objektumból választásra képes vezérlők: ListBox és a ComboBox
- IV.2.14. Feldolgozás állapotát mutató vezérlő: ProgressBar
- IV.2.15. Pixelgrafikus képeket megjeleníteni képes vezérlő: a PictureBox (képmező)
- IV.2.16. Az ablakunk felső részén lévő menüsor: a MenuStrip (menüsor) vezérlő
- IV.2.17. Az alaphelyzetben nem látható ContextMenuStrip vezérlő
- IV.2.18. Az eszközkészlet menüsora: a ToolStrip vezérlő
- IV.2.19. Az ablak alsó sorában megjelenő állapotsor, a StatusStrip vezérlő
- IV.2.20. A fileok használatában segítő dialógusablakok: OpenFileDialog, SaveFileDialog és FolderBrowserDialog
- IV.2.21. Az előre definiált üzenetablak: MessageBox
- IV.2.22. Az időzítésre használt vezérlő: Timer
- IV.2.23. A SerialPort
- IV.3. Szöveges, bináris állományok, adatfolyamok.
- IV.3.1. Előkészületek a fájlkezeléshez
- IV.3.2. A statikus File osztály metódusai
- IV.3.3. A FileStream referencia osztály
- IV.3.4. A BinaryReader referencia osztály
- IV.3.5. A BinaryWriter referencia osztály
- IV.3.6. Szövegfájlok kezelése: StreamReader és StreamWriter referencia osztályok
- IV.3.7. A MemoryStream referencia osztály
- IV.4. A GDI+
- IV.4.1. A GDI+használata
- IV.4.2. A GDI rajzolási lehetőségei
- IV.4.3. A Graphics osztály
- IV.4.4. Koordináta-rendszerek
- IV.4.5. Koordináta-transzformáció
- IV.4.6. A GDI+ színkezelése (Color)
- IV.4.7. Geometriai adatok (Point, Size, Rectangle, GraphicsPath)
- IV.4.8. Régiók
- IV.4.9. Képek kezelése (Image, Bitmap, MetaFile, Icon)
- IV.4.10. Ecsetek
- IV.4.11. Tollak
- IV.4.12. Font, FontFamily
- IV.4.13. Rajzrutinok
- IV.4.14. Nyomtatás
- Irodalmak:
- V. Nyílt forráskódú rendszerek fejlesztése
- VI. Célspecifikus alkalmazások
- A. Függelék – Szabványos C++ összefoglaló táblázatok
- A.1. Az ASCII kódtábla
- A.2. C++ nyelv foglalt szavai
- A.3. Escape karakterek
- A.4. C++ adattípusok és értékkészletük
- A.5. A C++ nyelv utasításai
- A.6. C++ előfeldolgozó (perprocesszor) utasítások
- A.7. C++ műveletek elsőbbsége és csoportosítása
- A.8. Néhány gyakran használt matematikai függvény
- A.9. C++ tárolási osztályok
- A.10. Input/Output (I/O) manipulátorok
- A.11. A szabványos C++ nyelv deklarációs állományai
- B. Függelék – C++/CLI összefoglaló táblázatok
- I.1. A projektválasztás
- I.2. A projekt beállításai
- I.3. A lehetséges forrásfájlok
- I.4. A futó program ablaka
- I.5. A C++ program fordításának lépései
- I.6. C++ adattípusok csoportosítása
- I.7. Az egyszerű if utasítás működése
- I.8. Az if-else szerkezet logikai vázlata
- I.9. A többirányú elágazás logikai vázlata
- I.10. A while ciklus működésének logikai vázlata
- I.11. A for ciklus működésének logikai vázlata
- I.12. A do-while ciklus működési logikája
- I.13. C++ program memóriahasználat
- I.14. Dinamikus memóriafoglalás
- I.15. Egydimenziós tömb grafikus ábrázolása
- I.16. Kétdimenziós tömb grafikus ábrázolása
- I.17. Mutatók és a tömbök kapcsolata
- I.18. Kétdimenziós tömb a memóriában
- I.19. Dinamikus foglalású sorvektorok
- I.20. Dinamikus foglalású mutatóvektor és sorvektorok
- I.21. Sztring konstans a memóriában
- I.22. Sztringtömb kétdimenziós tömbben tárolva
- I.23. Optimális tárolású sztringtömb
- I.24. Struktúra a memóriában
- I.25. A CDTar program adatfeldolgozása
- I.26. Egyszeresen láncolt lista
- I.27. Unió a memóriában
- I.28. A datum struktúra a memóriában
- II.1. Függvény-definíció
- II.2. A függvényhívás menete
- II.3. A harmadfokú polinom grafikonja
- II.4. Az argv paraméter értelmezése
- II.5. Parancssor argumentumok megadása
- II.6. Háromszög területének számítása
- II.7. A változók hatókörei
- II.8. A C++ fordítás folyamata
- III.1. Az énAutóm objektum (a Teherautó osztály példánya)
- III.2. Az öröklés menete
- III.3. Többszörös öröklés
- III.4. Az Alkalmazott osztály és az objektumai
- III.5. A C++ többszörös örölésű I/O osztályai
- III.6. Geometriai osztályok hierarchiája
- III.7. Virtuális alaposztályok alkalmazása
- III.8. Korai kötés példa
- III.9. Késői kötés példa
- III.10. A példaprogram virtuális metódustáblái
- IV.1. Memória takarítás előtt
- IV.2. Memória takarítás után
- IV.3. Projekttípus
- IV.4. A projekt
- IV.5. Az ablakmodell
- IV.6. A kódablak
- IV.7. A szerszámos láda
- IV.8. A vezérlő menüje
- IV.9. A vezérlő tulajdonságai
- IV.10. A vezérlő eseményei
- IV.11. A vezérlő Click eseménye
- IV.12. A beépített segítség
- IV.13. A projekt adatai
- IV.14. A program típusa
- IV.15. A program ablakának részlete
- IV.16. A program ablaka
- IV.17. A program ablaka
- IV.18. Az átméretezett ablak
- IV.19. A Bitmap középen
- IV.20. A zoomolt Bitmap
- IV.21. A menü
- IV.22. A menü definíció
- IV.23. A Súgó menü
- IV.24. Almenük
- IV.25. Kontextus menü
- IV.26. Menülem készlet
- IV.27. A MessageBox gombjainak beállítása
- IV.28. A MessageBox
- IV.29. A fájlkezelés modellje
- IV.30. A GDI+ osztályai
- IV.31. A rajzolt vonal minden átméretezés után automatikusan megjelenik
- IV.32. Ha nem a Paint-ben rajzolunk, minimalizálás utáni nagyításkor eltűnik a kék vonal
- IV.33. Az általános axonometria
- IV.34. Az izometrikus axonometria
- IV.35. A katonai axonometria
- IV.36. A 2D-s koordinátarendszer
- IV.37. Kocka axonometriában
- IV.38. Centrális vetítés
- IV.39. A kocka perspektív nézetei
- IV.40. A torzítás megadása
- IV.41. A torzítás
- IV.42. Eltolás nyújtás mátrix-szal
- IV.43. Eltolás és forgatás
- IV.44. Eltolás és nyírás
- IV.45. A mm skála és a PageScale tulajdonság
- IV.46. Színkeverő
- IV.47. Alternate és Winding görbelánc
- IV.48. Ellipszisív
- IV.49. A harmadfokú Bezier-görbe
- IV.50. A harmadfokú Bezier-görbék folytonosan illesztve
- IV.51. A kardinális spline
- IV.52. Catmull-Rom spline
- IV.53. Szövegek a figurában
- IV.54. Két összefűzött figura összekötve és nem összekötve
- IV.55. Szélesített figura
- IV.56. Torzított figura
- IV.57. Körbevágott figura
- IV.58. Vektoros A
- IV.59. Raszteres A
- IV.60. Image a formon
- IV.61. Halftone ábrázolás
- IV.62. Elforgatott kép
- IV.63. Bitkép színezés
- IV.64. Nem menedzselt bitkép kezelés
- IV.65. Ecsetek
- IV.66. Tollak
- IV.67. Karakterjellemzők
- IV.68. Hagyományos karakter szélességek
- IV.69. ABC karakterszélességek
- IV.70. Fontcsaládok
- IV.71. Font torzítások
- IV.72. Nagyított és nagyított torzított kép
- IV.73. Az OnNote az alapértelmezett nyomtató
- VI.1. A PIC32MX blokkdiagramja
- VI.2. RealTek SOC csatlakoztatási lehetőségei
- VI.3. A mintaprogram
- VI.4. Az MPLAB IDE
- VI.5. CORBA beépítés
- VI.6. Az ICE programok szerkezete
- VI.7. Az ICE könyvtárak
I. fejezet - A C++ alapjai és adatkezelése
- I.1. A C++ programok készítése
- I.2. Alaptípusok, változók és konstansok
- I.3. Alapműveletek és kifejezések
- I.3.1. Az operátorok csoportosítása az operandusok száma alapján
- I.3.2. Elsőbbségi és csoportosítási szabályok
- I.3.3. Matematikai kifejezések
- I.3.4. Értékadás
- I.3.5. Léptető (inkrementáló/dekrementáló) műveletek
- I.3.6. Feltételek megfogalmazása
- I.3.7. Bitműveletek
- I.3.8. A vessző operátor
- I.3.9. Típuskonverziók
- I.4. Vezérlő utasítások
- I.5. Kivételkezelés
- I.6. Mutatók, hivatkozások és a dinamikus memóriakezelés
- I.7. Tömbök és sztringek
- I.8. Felhasználói típusok
A C++ nyelven történő programfejlesztéshez szükséges ismereteket három nagy csoportba osztva tárgyaljuk. Az első csoport (I. fejezet - A C++ alapjai és adatkezelése) olyan alapelemeket, programstruktúrákat mutat be, amelyek többsége egyaránt megtalálható a C és a C++ nyelvekben. Az elmondottak begyakorlásához elegendő egyetlen main() függvényt tartalmazó programot készítenünk.
A következő (II. fejezet - Moduláris programozás C++ nyelven) fejezet az algoritmikus gondolkodásnak megfelelő, jól strukturált C és C++ programok készítését segíti a bemutatott megoldásokkal. Ebben a részben a függvényeké a főszerep.
A harmadik (III. fejezet - Objektum-orientált programozás C++ nyelven) fejezet a napjainkban egyre inkább egyeduralkodóvá váló objektum-orientált programépítés eszközeit ismerteti. Itt az adatokat és a rajtuk elvégzendő műveleteket egyetlen egységbe kovácsoló osztályoké a főszerep.
I.1. A C++ programok készítése
Mielőtt sorra vennénk a C++ nyelv elemeit, érdemes áttekinteni a C++ programok előállításával és futtatásával kapcsolatos kérdéseket. Megismerkedünk a C++ forráskód írásakor alkalmazható néhány szabállyal, a programok felépítésével, illetve a futtatáshoz szükséges lépésekkel a Microsoft Visual C++ rendszerben.
I.1.1. Néhány fontos szabály
A szabványos C++ nyelv azon hagyományos programozási nyelvek közé tartozik, ahol a program megírása a program teljes szövegének begépelését is magában foglalja. A program szövegének (forráskódjának) beírása során figyelnünk kell néhány megkötésre:
A program alapelemei csak a hagyományos 7-bites ASCII kódtábla karaktereit (lásd A.1. szakasz - Az ASCII kódtábla függelék) tartalmazhatják, azonban a karakter- és szöveg konstansok, illetve a megjegyzések tetszőleges kódolású (ANSI, UTF-8, Unicode) karakterekből állhatnak. Néhány példa:
/* Értéket adunk egy egész, egy karakteres és egy szöveges (sztring) változónak (többsoros megjegyzés) */ int valtozo = 12.23; // értékadás (megjegyzés a sor végéig) char jel = 'Á'; string fejlec = "Öröm a programozás"
A C++ fordító megkülönbözteti a kis- és a nagybetűket a programban használt szavakban (nevekben). A nyelvet felépítő nevek nagy többsége csak kisbetűket tartalmaz.
Bizonyos (angol) szavakat nem használhatunk saját névként, mivel ezek a fordító által lefoglalt kulcsszavak (lásd A.2. szakasz - C++ nyelv foglalt szavai függelék).
Saját nevek képzése során ügyelnünk kell arra, hogy a név betűvel (vagy aláhúzás jellel) kezdődjön, és a további pozíciókban is csak betűt, számjegyet vagy aláhúzás jelet tartalmazzon. (Megjegyezzük, hogy az aláhúzás jel használata nem ajánlott.)
Még egy utolsó szabály az első C++ program megírása előtt, hogy lehetőleg ne túl hosszú, azonban ún. beszédes neveket képezzünk, mint például: ElemOsszeg, mereshatar, darab, GyokKereso.
I.1.2. Az első C++ program két változatban
Mivel a C++ nyelv a szabványos (1995) C nyelvvel felülről kompatibilis, egyszerű programok készítése során C programozási ismeretekkel is célt érhetünk. Vegyük például egy síkbeli kör kerületének és területének számítását! Az algoritmus igen egyszerű, hiszen a sugár bekérése után csupán néhány képletet kell használnunk.
Az alábbi két megoldás alapvetően csak az input/output műveletekben különbözik egymástól. A C-stílusú esetben a printf() és a scanf() függvényeket használjuk, míg a C++ jellegű, második esetben a cout és a cin objektumokat alkalmazzuk. (A későbbi példákban az utóbbi megoldásra támaszkodunk.) A forráskódot mindkét esetben .CPP kiterjesztésű szövegfájlban kell elhelyeznünk.
A C stílusú megoldást csekély módosítással C fordítóval is lefordíthatjuk:
// Kör1.cpp
#include "cstdio"
#include "cmath"
int main()
{
const double pi = 3.14159265359;
double sugar, terulet, kerulet;
// A sugár beolvasása
printf("Sugar = ");
scanf("%lf", &sugar);
// Szamítások
kerulet = 2*sugar*pi;
terulet = pow(sugar,2)*pi;
printf("Kerulet: %7.3f\n", kerulet);
printf("Terulet: %7.3f\n", terulet);
// Várakozás az Enter lenyomására
getchar();
getchar();
return 0;
}
A C++ objektumokat alkalmazó megoldás valamivel áttekinthetőbb:
// Kör2.cpp
#include "iostream"
#include "cmath"
using namespace std;
int main()
{
const double pi = 3.14159265359;
// A sugár beolvasása
double sugar;
cout << "Sugar = ";
cin >> sugar;
// Szamítások
double kerulet = 2*sugar*pi;
double terulet = pow(sugar,2)*pi;
cout << "Kerulet: " << kerulet << endl;
cout << "Terulet: " << terulet << endl;
// Várakozás az Enter lenyomására
cin.get();
cin.get();
return 0;
}
Mindkét megoldásban használunk C++ és saját neveket (sugar, terulet, kerulet. pi). Nagyon fontos szabály, hogy minden nevet felhasználása előtt ismertté kell tenni (deklarálni kell) a C++ fordító számára. A példában a double és a const double kezdetű sorok a nevek leírásán túlmenően létre is hozzák (definiálják) a hozzájuk kapcsolódó tárolókat a memóriában. Nem találunk azonban hasonló leírásokat a printf(), scanf(), pow(), cin és cout nevekre. Ezek deklarációit a program legelején beépített (#include) állományok (rendre cstdio, cmath és iostream) tartalmazzák, A cin és cout esetén az std névtérbe zárva.
A printf() függvény segítségével formázottan jeleníthetünk meg adatokat. A cout objektumra irányítva (<<) az adatokat, a formázás sokkal bonyolultabban végezhető el, azonban itt nem kell foglalkoznunk a különböző adattípusokhoz tartozó formátumelemekkel. Ugyanez mondható el az adatbevitelre használt scanf() és cin elemekre is. További fontos különbség az alkalmazott megoldás biztonsága. A scanf() hívásakor meg kell adnunk az adatok tárolására szánt memóriaterület kezdőcímét (&), mely művelet egy sor hibát vihet a programunkba. Ezzel szemben a cin alkalmazása teljesen biztonságos.
Még egy megjegyzés a programok végén álló getchar() és cin.get() hívásokhoz kapcsolódóan. Az utolsó scanf() illetve cin hívását követően az adatbeviteli pufferben benne marad az Enter billentyűnek megfelelő adat. Mivel mindkét, karaktert olvasó függvényhívás az Enter leütése után végzi el a feldolgozást, az első hívások a pufferben maradt Entert veszik ki, és csak a második hívás várakozik egy újabb Enter-lenyomásra.
Mindkét esetben egy egész (int) típusú, main() nevű függvény tartalmazza a program érdemi részét, a függvény törzsét képző kapcsos zárójelek közé zárva. A függvények - a matematikai megfelelőjükhöz hasonlóan - rendelkeznek értékkel, melyet C++ nyelven a return utasítás után adunk meg. Még a C nyelv ősi változataiból származik az érték értelmezése, mely szerint a 0 azt jelenti, hogy minden rendben volt. Ezt a függvényértéket a main() esetében az operációs rendszer kapja meg, hisz a függvényt is ő hívja (elindítva ezzel a program futását).
I.1.3. C++ programok fordítása és futtatása
A legtöbb fejlesztőrendszerben a programkészítés alapját egy ún. projekt összeállítása adja. Ehhez először ki kell választanunk az alkalmazás típusát, majd pedig projekthez kell adnunk a forrásállományokat. A Visual C++ rendszer számos lehetősége közül a Win32 konzolalkalmazás az egyszerű, szöveges felületű C++ alkalmazások típusa. Vegyük sorra a szükséges lépéseket!
A File / New / Project… Win32 / Win32 Console Application választások után meg kell adnunk a projekt nevét:
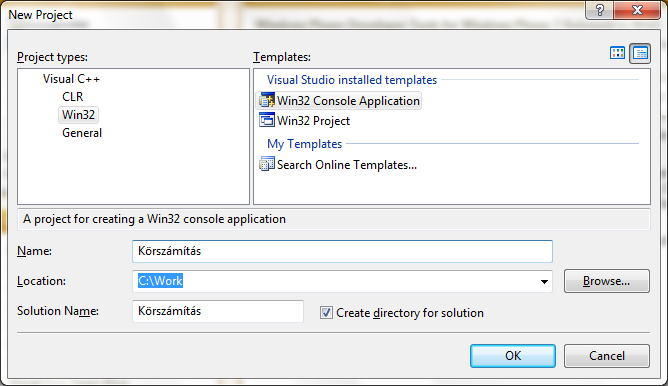
Az OK gomb megnyomása után elindul a Konzolalkalmazás varázsló, melynek beállításaival egy üres projektet készítünk:
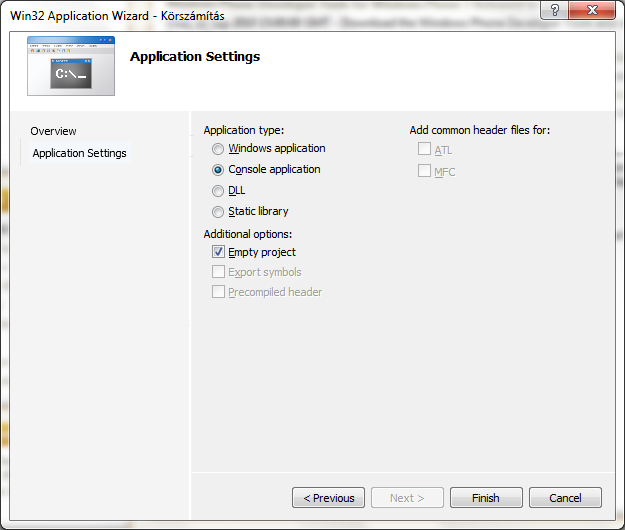
A Finish gomb megnyomását követően megjelenik a megoldás ablaka (Solution Explorer), ahol a Source Files elemre kattintva az egér jobb gombjával, új forrásállomány adhatunk a projekthez ( Add / New Item… ).
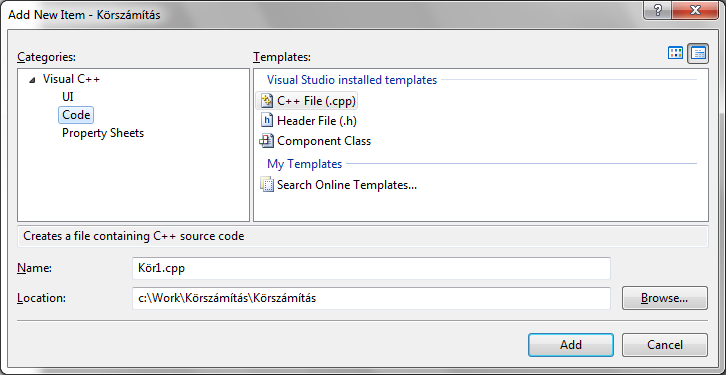
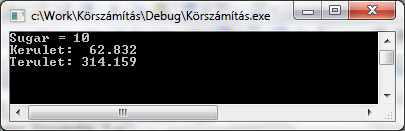
A program szövegének beírása után a fordításhoz a Build / Build Solution vagy a Build / Rebuild Solution menüpontokat használhatjuk. Sikeres fordítás esetén (Körszámítás - 0 error(s), 0 warning(s)) a Debug / Start Debugging (F5) vagy a Debug / Start Without Debugging (Ctrl+F5)menüválasztással indíthatjuk a programot.
A Build / Configuration Manager... menüválasztás hatására megjelenő párbeszédablakban megadhatjuk, hogy nyomon követhető ( Debug ) vagy pedig végleges ( Release ) változatot kívánunk fordítani. (Ez a választás meghatározza a keletkező futtatható állomány tartalmát, illetve a helyét a lemezen.)
Bármelyik Build (felépítés) választásakor a fordítás valójában több lépésben megy végbe. Ez egyes lépéseket a következő ábrán (I.5. ábra - A C++ program fordításának lépései) követhetjük nyomon.
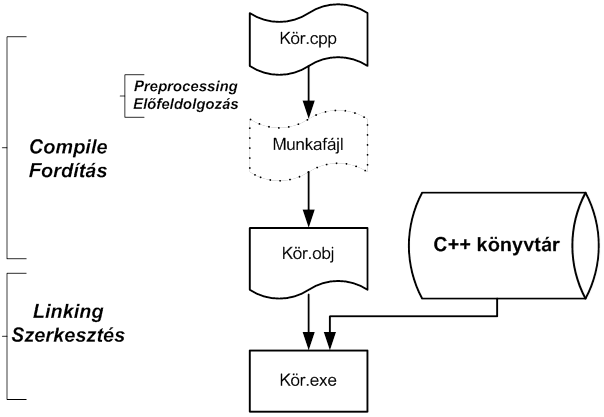
Az előfeldolgozó értelmezi a kettőskereszttel (#) kezdődő sorokat, melynek eredményeként keletkezik a C++ nyelvű forráskód. Ezt a kódot a C++ fordító egy olyan tárgykóddá fordítja, amelyből hiányzik a könyvtári elemeket megvalósító gépi kód. Utolsó lépésben a szerkesztő pótolja ezt a hiányt, és futtaható alkalmazássá alakítja a már teljes gépi (natív) kódot.
Megjegyezzük, hogy több forrásfájlt (modult) tartalmazó projekt esetén a fordítást modulonként végzi az előfeldolgozó és a C++ fordító, majd az így keletkező tárgymodulokat a szerkesztő építi egyetlen futtatható állománnyá.
A futtatást követően még el kell mentenünk az elkészült programot, hogy a későbbiekben ismét tudjunk vele dolgozni. A sokféle megoldás közül a következő bevált lépéssor lehet segítségünkre: először minden fájlt lemezre mentünk ( File / SaveAll ), majd pedig lezárjuk a projektet a megoldással együtt. ( File / Close Solution ). (A megoldás (solution) egymással összefüggő projektek halmazát jelöli, melyeket szüksége esetén egyetlen lépésben újrafordíthatunk.)
Végezetül nézzük meg a projekt fordításakor keletkező könyvtárstruktúrát a merevlemezen!
C:\Work\Körszámítás\Körszámítás.sln C:\Work\Körszámítás\Körszámítás.ncb C:\Work\Körszámítás\Debug\Körszámítás.exe C:\Work\Körszámítás\Release\Körszámítás.exe C:\Work\Körszámítás\Körszámítás\Körszámítás.vcproj C:\Work\Körszámítás\Körszámítás\Kör1.cpp C:\Work\Körszámítás\Körszámítás\Debug\Kör1.obj C:\Work\Körszámítás\Körszámítás\Release\ Kör1.obj
A magasabban elhelyezkedő Debug illetve Release könyvtárak tartalmazzák a kész futtatható alkalmazást, míg a mélyebben fekvő, azonos nevű könyvtárakban munkafájlokat találunk. Ez a négy mappa törölhető, hisz fordításkor ismét létrejönnek. Ugyancsak ajánlott eltávolítani a fejlesztői környezet intellisense szolgáltatásait segítő Körszámítás.ncb fájlt, melynek mérete igen nagyra nőhet. A megoldás (projekt) ismételt megnyitását a Körszámítás.sln állománnyal kezdeményezhetjük ( File / Open / Project / Solution ).
I.1.4. A C++ programok felépítése
Mint ahogy az előző részben láttuk, minden C++ nyelven megírt program egy vagy több forrásfájlban (fordítási egységben, modulban) helyezkedik el, melyek kiterjesztése .CPP. A C++ modulok önállóan fordíthatók tárgykóddá.
A programhoz általában ún. deklarációs (include, header, fej-) állományok is tartoznak, melyeket az #include előfordító utasítás segítségével építünk be a forrásfájlokba. A deklarációs állományok önállóan nem fordíthatók, azonban a legtöbb fejlesztői környezet támogatja azok előfordítását (precompile), meggyorsítva ezzel a C++ modulok feldolgozását.
A C++ modulok felépítése alapvetően követi a C nyelvű programokét. A program kódja - a procedurális programozás elvének megfelelően - függvényekben helyezkedik el. Az adatok (deklarciók/definíciók) a függvényeken kívül (globális, fájlszinten), illetve a függvényeken belül (lokális szinten) egyaránt elhelyezkedhetnek. Az előbbieket külső (extern), míg az utóbbiakat automatikus (auto) tárolási osztályba sorolja a fordító. Az elmondottakat jól szemlélteti az alábbi példaprogram:
// C++ preprocesszor direktívák
#include <iostream>
#define MAX 2012
// a szabványos könyvtár neveinek eléréséhez
using namespace std;
// globális deklarációk és definíciók
double fv1(int, long); // függvény prototípusa
const double pi = 3.14159265; // definíció
// a main() függvény
int main()
{
/* lokális deklarációk és definíciók
utasítások */
return 0; // kilépés a programból
}
// függvénydefiníció
double fv1(int a, long b)
{
/* lokális deklarációk és definíciók
utasítások */
return a+b; // vissztérés a függvényből
}
C++ nyelven az objektum-orientált (OO) megközelítést is alkalmazhatjuk a programok készítése során. Ennek az elvnek megfelelően a programunk alapegysége a függvényeket és adatdefiníciókat összefogó osztály (class) (részletesebben lásd a III. fejezet - Objektum-orientált programozás C++ nyelven fejezetet). Ebben az esetben is a main() függvény definiálja a programunk belépési pontját. Az osztályokat általában a globális deklarációk között helyezzük el, akár közvetlenül a C++ modulban, vagy akár egy deklarációs állomány beépítésével. Az osztályban elhelyezett ’’tudást” az osztály példányain (változóin) keresztül érjük el.
Példaként tekintsük a körszámítás feladat objektum-orientált eszközökkel való megfogalmazását!
/// Kör3.cpp
#include "iostream"
#include "cmath"
using namespace std;
// Az osztály definíciója
class Kor
{
double sugar;
static const double pi;
public:
Kor(double s) { sugar = s; }
double Kerulet() { return 2*sugar*pi; }
double Terulet() { return pow(sugar,2)*pi; }
};
const double Kor::pi = 3.14159265359;
int main()
{
// A sugár beolvasása
double sugar;
cout << "Sugar = ";
cin >> sugar;
// A Kor objektumának létrehozása, és használata
Kor kor(sugar);
cout << "Kerulet: " << kor.Kerulet() << endl;
cout << "Terulet: " << kor.Terulet() << endl;
// Várakozás az Enter lenyomására
cin.get();
cin.get();
return 0;
}
I.2. Alaptípusok, változók és konstansok
A programozás során a legkülönbözőbb tevékenységeinket igyekszünk érthetővé tenni a számítógép számára, azzal a céllal, hogy a gép azok elvégzését, illetve, hogy elvégezze azokat helyettünk. Munkavégzés közben adatokat kapunk, amelyeket általában elteszünk, hogy később elővéve feldolgozzuk azokat, és információt nyerjünk belőlük. Adataink igen változatosak, de legtöbbjük számok, szövegek formájában vannak jelen az életünkben.
Ebben a fejezetben az adatok C++ nyelven történő leírásával és tárolásával foglalkozunk. Ugyancsak megismerkedünk az adatok megszerzésének (bevitelének), illetve megjelenítésének módszereivel.
Az adatok tárolása – a Neumann elv alapján – egységes formában történik a számítógép memóriájában, ezért a C++ programban kell gondoskodnunk az adat milyenségének, típusának leírásáról.
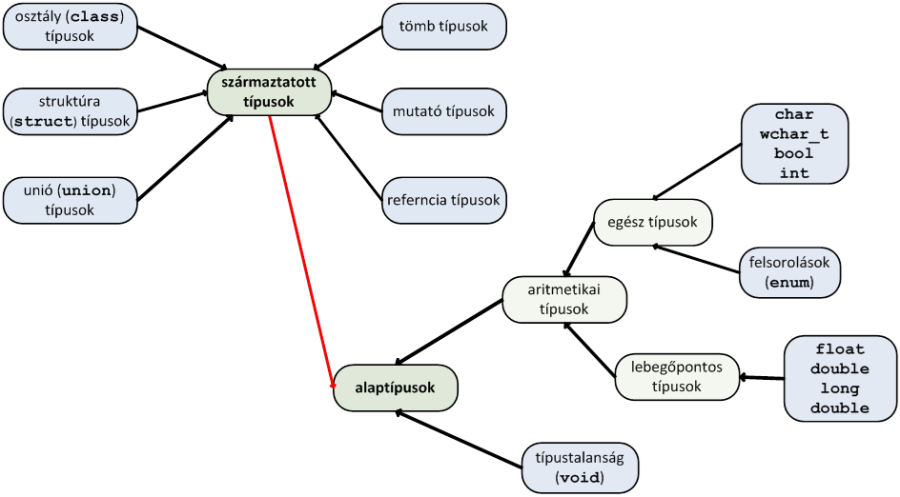
I.2.1. A C++ adattípusok csoportosítása
Az adattípus meghatározza a tárolásra használt memóriaterület (változó) bitjeinek darabszámát és értelmezését. Az adattípus hatással van az adatok feldolgozására is, hisz a C++ nyelv erősen típusos, így nagyon sok mindent ellenőriz a fordítóprogram.
A C++ adattípusait (röviden típusait) sokféle módon csoportosíthatjuk. Szerepeljen itt most a Microsoft VC++ nyelvben is alkalmazott felosztás (I.6. ábra - C++ adattípusok csoportosítása)! E szerint vannak alaptípusaink, amelyek egy-egy érték (egész szám, karakter, valós szám) tárolására képesek. Vannak azonban származtatott típusaink is, amelyek valamilyen módon az alaptípusokra épülve bonyolultabb, akár több értéket is tároló adatstruktúrák kialakítását teszik lehetővé.
I.2.1.1. Típusmódosítók
C++ nyelvben az egész alaptípusok jelentését típusmódosítókkal pontosíthatjuk. A signed/unsigned módosítópárral a tárolt bitek előjeles vagy előjel nélküli értelmezését írhatjuk elő. A short/long párral pedig a tárolási méretet rögzíthetjük 16 illetve 32 bitre. A legtöbb C++ fordító támogatja a 64-bites tárolást előíró long long módosító használatát, ezért könyvünkben ezt is tárgyaljuk. A típusmódosítók önmagukban típuselőírásként is használhatók. Az alábbiakban összefoglaltuk a lehetséges típuselőírásokat. Az előírások soronként azonos típusokat jelölnek.
|
char |
signed char | ||
|
short int |
short |
signed short int |
signed sh o rt |
|
int |
signed |
signed int | |
|
long int |
long |
signed long int |
signed long |
|
long long int |
long long |
signed long long int |
signed long long |
|
unsigned char | |||
|
unsigned short int |
unsigned short | ||
|
unsigned int |
unsigned | ||
|
unsigned long int |
unsigned long | ||
|
unsigned long long int |
unsigned long long |
A típusmódosítókkal ellátott aritmetikai típusok memóriaigényét és a tárolt adatok értéktartományát az A.4. szakasz - C++ adattípusok és értékkészletük függelékben foglaltuk össze.
Az alaptípusok részletes bemutatása jelen alfejezet témája, míg a származtatott típusokat az I. fejezet - A C++ alapjai és adatkezelése fejezet további részeiben tárgyaljuk.
I.2.2. Változók definiálása
Az adatok memóriában való tárolása és elérése alapvető fontosságú minden C++ program számára. Ezért először a névvel ellátott memóriaterületekkel, a változókkal kezdjük az ismerkedést. A változókat az estek többségében definiáljuk, vagyis megadjuk a típusukat (deklaráljuk), és egyúttal helyet is „foglalunk” számukra a memóriában. (A helyfoglalást egyelőre a fordítóra bízzuk.)
Egy változó teljes definíciós sora első látásra igen összetett, azonban a mindennapos használat sokkal egyszerűbb formában történik.
〈tárolási osztály〉 〈típusminősítő〉 〈típusmódosító ... 〉 típus változónév 〈= kezdőérték〉 〈, … 〉;
〈tárolási osztály〉 〈típusminősítő〉 〈típusmódosító ... 〉 típus változónév 〈(kezdőérték)〉 〈, … 〉;
(Az általánosított formában a 〈 〉 jelek az opcionálisan megadható részeket jelölik, míg a három pont az előző definíciós elem ismételhetőségére utal.)
A C++ nyelv tárolási osztályai - auto, register, static, extern – meghatározzák a változók élettartamát és láthatóságát. Egyelőre nem adunk meg tárolási osztályt, így a C++ nyelv alapértelmezése érvényesül. E szerint minden függvényeken kívül definiált változó extern (globális), míg a függvényeken belül megadott változók auto (lokális) tárolási osztállyal rendelkezik. Az extern változók a program indításakor jönnek létre, és a program végéig léteznek, és eközben bárhonnan elérhetők. Ezzel szemben az auto változók csak a definíciójukat tartalmazó függvénybe való belépéskor születnek meg, és függvényből való kilépéskor törlődnek. Elérhetőségük is függvényre korlátozódik.
A típusminősítők alkalmazásával a változókhoz további információkat rendelhetünk.
A const kulcsszóval definiált változó értéke nem változtatható meg (csak olvasható - konstans).
A volatile típusminősítővel pedig azt jelezzük, hogy a változó értékét a programunktól független kód (például egy másik futó folyamat vagy szál) is megváltoztathatja. A volatile közli a fordítóval, hogy nem tud mindent, ami az adott változóval történhet. (Ezért például a fordító minden egyes, ilyen tulajdonságú változóra történő hivatkozáskor a memóriából veszi fel a változó értéket.)
int const const double volatile char float volatile const volatile bool
I.2.2.1. Változók kezdőértéke
A változódefiníciót a kezdő (kiindulási) érték megadása zárja. A kezdőértéket egyaránt megadhatjuk egy egyenlőségjel után, vagy pedig kerek zárójelek között:
using namespace std;
int osszeg, szorzat(1);
int main()
{
int a, b=2012, c(2004);
double d=12.23, e(b);
}
A fenti példában két változó (osszeg és a) esetén nem szerepel kezdőérték, ami általában programhibához vezet. Ennek ellenére az osszeg változó 0 kiindulási értékkel rendelkezik, mivel a globális változókat mindig inicializálja (nullázza) a fordító. A lokális a esetén azonban más a helyzet, mivel értékét a változóhoz rendelt memória aktuális tartalma adja, ami pedig bármi lehet! Ilyen esetekben a felhasználás előtti értékadással állíthatjuk be a változó értékét. Értékadás során az egyenlőségjel bal oldalán álló változó felveszi a jobb oldalon szereplő kifejezés értékét:
a = 1004;
C++ nyelven a kezdőértéket tetszőleges fordítás, illetve futás közben meghatározható kifejezéssel is megadhatjuk:
#include <cmath>
#include <cstdlib>
using namespace std;
double pi = 4.0*atan(1.0); // π
int veleten(rand() % 1000);
int main()
{
double ahatar = sin(pi/2);
}
Felhívjuk a figyelmet arra, hogy a definíciós és az értékadó utasításokat egyaránt pontosvessző zárja.
I.2.3. Az alaptípusok áttekintése
Az alaptípusokra úgy tekinthetünk, mint az emberi írott művekben a számjegyekre és a betűkre. Segítségükkel egy matematikai értékezés és a Micimackó egyaránt előállítható. Az alábbi áttekintésben az egész jellegű típusokat kisebb csoportokra osztjuk.
I.2.3.1. Karakter típusok
A char típus kettős szereppel rendelkezik. Egyrészről lehetővé teszi az ASCII (American Standard Code for Information Interchange) kódtábla (A.1. szakasz - Az ASCII kódtábla függelék) karaktereinek tárolását, másrészről pedig egybájtos előjeles egészként is használható.
char abetu = 'A'; cout << abetu << endl; char valasz; cout << "Igen vagy Nem? "; cin>>valasz; // vagy valasz = cin.get();
A char típus kettős voltát jól mutatják a konstans értékek (literálok) megadási lehetőségei. Egyetlen karaktert egyaránt megadhatunk egyszeres idézőjelek (aposztrófok) között, illetve az egész értékű kódjával. Egész értékek esetén a decimális forma mellet - nullával kezdve - az oktális, illetve - 0x előtaggal - a hexadecimális alak is használható. Példaként tekintsük a nagy C betű megadását!
’C’ 67 0103 0x43
Bizonyos szabványos vezérlő és speciális karakterek megadására az ún. escape szekvenciákat használjuk. Az escape szekvenciában a fordított osztásjel (backslash - \) karaktert speciális karakterek, illetve számok követik, mint ahogy az A.3. szakasz - Escape karakterek függelék táblázatában látható: ’\n’, ’\t’, ’\’’, ’\”’, ’\\’.
Amennyiben a 8-bites ANSI kódtábla karaktereivel, illetve bájtos egész értékekkel kívánunk dolgozni, az unsigned char típust ajánlott használni.
Az Unicode kódtábla karaktereinek feldolgozásához a kétbájtos wchar_t típussal hozunk létre változót, a konstans karakterértékek előtt pedig a nagy L betűt szerepeltetjük. (Ezek írására olvasására az std névtér wcout és wcin objektumok szolgálnak.)
wchar_t uch1 = L'\u221E'; wchar_t uch2 = L'K'; wcout<<uch1; wcin>>uch1; uch1 = wcin.get();
Felhívjuk a figyelmet arra, hogy nem szabad összekeverni az aposztrófot (’) az idézőjellel ("). Kettős idézőjelek között szöveg konstansokat (sztring literálokat) adunk meg a programban.
"Ez egy ANSI sztring konstans!"
illetve
L"Ez egy Unicode sztring konstans!"
I.2.3.2. A logikai bool típus
A bool típusú változók két értéket vehetnek fel. A false (0) a logikai hamis, míg a true (1) a logikai igaz értéknek felel meg. Input/Output (I/O) műveletekben a logikai értékeket a 0 és az 1 egész számok reprezentálják.
bool start=true, vege(false); cout << start; cin >>vege;
Ezt az alapértelmezés szerinti működést felülbírálhatjuk a boolalpha és a noboolalpha I/O manipulátorok segítségével:
bool start=true, vege(false); cout << boolalpha << start << noboolalpha; // true cout << start; // 1 cin >> boolalpha>> vege; // false cout << vege; // 0
I.2.3.3. Az egész típusok
Valószínűleg a C++ nyelv leggyakrabban használt alaptípusa az int a hozzá tartozó típusmódosítókkal. Amikor a programban megadunk egy egész értéket, akkor a fordító automatikusan az int típust próbálja hozzárendelni. Amennyiben az érték kívül esik az int típus értékkészletén, akkor a fordító valamelyik nagyobb értékkészletű egész típust alkalmazza, illetve hibajelzést ad túl nagy konstans esetén.
A konstans egész értékek típusát U és L utótagokkal mi is meghatározhatjuk. Az U betű az unsigned, míg az L a long típusmódosítók kezdőbetűje:
|
2012 |
int |
|
2012U |
unsigned int |
|
2012L |
long int |
|
2012UL |
unsigned long int |
|
2012LL |
long long int |
|
2012ULL |
unsigned long long int |
Természetesen az egész értékeket a decimális (2012) forma mellett oktális (03724) és hexadecimális (0x7DC) számrendszerben egyaránt megadhatjuk. Ezeket a számrendszereket az I/O műveletekben is előírhatjuk a „kapcsoló” manipulátorok ( dec , oct , hex ) felhasználásával, melyek hatása a következő manipulátorig tart:
#include <iostream>
using namespace std;
int main()
{
int x=20121004;
cout << hex << x << endl;
cout << oct << x << endl;
cout << dec << x << endl;
cin>> hex >> x;
}
Adatbevitel esetén a számrendszert jelző előtagok használata nem kötelező. Más manipulátorok egyszerű formázási lehetőséget biztosítanak. A setw () paraméteres manipulátorral a megjelenítéshez használt mező szélességét állíthatjuk be, melyen belül balra ( left ) és az alapértelmezés szerint jobbra ( right ) is igazíthatunk. A setw () manipulátor hatása csak a következő adatelemre terjed ki, míg a kiigazítás manipulátorainak hatása a következő kiigazítás manipulátorig tart.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
unsigned int szam = 123456;
cout << '|' << setw(10) << szam << '|' << endl;
cout << '|' << right << setw(10) << szam << '|' << endl;
cout << '|' << left << setw(10) << szam << '|' << endl;
cout << '|' << setw(10) << szam << '|' << endl;
}
A program futásának eredménye jól tükrözi a manipulátorok hatását:
| 123456| | 123456| |123456 | |123456 |
I.2.3.4. A lebegőpontos típusok
Matematikai és műszaki számításokhoz az egészek mellett elengedhetetlen a törtrészeket is tartalmazó számok használata. Mivel ezekben a tizedespont helye nem rögzített, az ilyen számok tárolását segítő típusok a lebegőpontos típusok: float, double, long double. Az egyes típusok a szükséges memória mérete, a számok nagyságrendje és a pontos jegyek számában különböznek egymástól (lásd A.4. szakasz - C++ adattípusok és értékkészletük függelék). (A Visual C++ a szabvány ajánlásától eltérően double típusként kezeli a long double típust.)
Már az ismerkedés legelején le kell szögeznünk, hogy a lebegőpontos típusok alkalmazásával le kell mondanunk a törtrészek pontos ábrázolásáról. Ennek oka, hogy a számok kitevős alakban (mantissza, kitevő), méghozzá 2-es számrendszerben tárolódnak.
double d =0.01; float f = d; cout<<setprecision(12)<<d*d<< endl; // 0.0001 cout<<setprecision(12)<<f*f<< endl; // 9.99999974738e-005
Egyetlen garantáltan egzakt érték a 0, tehát a lebegőpontos változók nullázása után értékük: 0.0.
A lebegőpontos konstansokat kétféleképpen is megadhatjuk. Kisebb számok esetén általában a tizedes tört alakot használjuk, ahol a törtrészt tizedespont választja el az egész résztől: 3.141592653, 100., 3.0. Nagyobb számok esetén a matematikából ismert kitevős forma számítógépes változatát alkalmazzuk, ahol az e , E betűk 10 hatványát jelölik: 12.34E-4, 1e6.
A lebegőpontos konstans értékek alapértelmezés szerint double típusúak. Az F utótaggal float típusú, míg L utótaggal long double típusú értékeket adhatunk meg: 12.3F, 1.2345E-10L. (Gyakori programhiba, hogy szándékaink szerint lebegőpontos konstans érték megadásakor sem tizedespontot, sem pedig kitevőt nem adunk meg, így a konstans egész típusú lesz.)
A lebegőpontos változók értékének megjelenítése során a már megismert mezőszélesség ( setw ()) mellet a tizedes jegyek számát is megadhatjuk – setprecision () (lásd A.10. szakasz - Input/Output (I/O) manipulátorok függelék). Amennyiben az érték nem jeleníthető meg a formátum alapján, az alapértelmezés szerinti megjelenítés érvényesül. A tizedes tört és a kitevős forma közül választhatunk a fixed és scientific manipulátorokkal.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double a = 2E2, b=12.345, c=1.;
cout << fixed;
cout << setw(10)<< setprecision(4) << a << endl;
cout << setw(10)<< setprecision(4) << b << endl;
cout << setw(10)<< setprecision(4) << c << endl;
}
A program futásának eredménye:
200.0000
12.3450
1.0000
Mielőtt továbblépnénk érdemes elidőzni a C++ nyelv aritmetikai típusai között végzett automatikus típus-átalakításnál. Könnyen belátható, hogy egy kisebb értékkészletű típus bármely nagyobb értékkészletű típussá adatvesztés nélkül átalakítható. Fordított helyzetben azonban általában adatvesztéssel jár az átalakítás, amire nem figyelmeztet a futtató rendszer, és a nagyobb szám egy része megjelenhet a „kisebb” típusú változóban.
short int s;
double d;
float f;
unsigned char b;
s = 0x1234;
b = s; // 0x34 ↯
// ------------------------
f = 1234567.0F;
b = f; // 135 ↯
s = f; // -10617 ↯
// ------------------------
d = 123456789012345.0;
b = d; // 0 ↯
s = d; // 0 ↯
f = d; // f=1.23457e+014 - pontosságvesztés ↯
I.2.3.5. Az enum típus
A programokban gyakran használunk olyan egész típusú konstans értékeket, amelyek logikailag összetartoznak. A programunk olvashatóságát nagyban növeli, ha ezeket az értékeket nevekkel helyettesítjük. Ennek módja egy új típus a felsorolás (enum) definiálása az értékkészletének megadásával:
enum 〈típusazonosító〉 { felsorolás };
A típusazonosító elhagyásával a típus nem jön létre, csak a konstansok születnek meg. Példaként tekintsük a hét munkanapjait tartalmazó felsorolást!
enum munkanapok {hetfo, kedd, szerda, csutorok, pentek};
A felsorolásban szereplő nevek mindegyike egy-egy egész számot képvisel. Alapértelmezés szerint az első elem (hetfo) értéke 0, a rákövetkező elemé (kedd) pedig 1, és így tovább (a pentek értéke 4 lesz).
A felsorolásban az elemekhez közvetlenül értéket is rendelhetünk. Ilyenkor az automatikus növelés a megadott értéktől folytatódik. Az sem okoz gondot, ha azonos értékek ismétlődnek, vagy ha negatív értéket adunk értékül. Arra azonban ügyelnünk kell, hogy egy adott láthatósági körön (névtéren) belül nem szerepelhet két azonos nevű enum elem a definíciókban.
enum konzolszinek {fekete,kek,zold,piros=4,sarga=14,feher};
Az konzolszinek felsorolásban a feher elem értéke 15.
A közvetlen értékbeállítást nem tartalmazó felsorolásban az elemek számát megkaphatjuk egy további elem megadásával:
enum halmazallapot { jeg, viz, goz, allapotszam};
Az allapotszam elem értéke az állapotok száma, vagyis 3.
Az alábbi példában az enum típus és az enum konstansok felhasználását szemléltetjük:
#include <iostream>
using namespace std;
int main()
{
enum kartya { treff, karo, kor, pikk };
enum kartya lapszin1 = karo;
kartya lapszin2 = treff;
cout << lapszin2 << endl;
int szin = treff;
cin >> szin;
lapszin1 = kartya(szin);
}
Felsorolás típusú változót a C nyelv és a C++ nyelv szabályai szerint egyaránt definiálhatunk. A C nyelv szerint az enum kulcsszó és a típusazonosító együtt alkotják az enum típust. A C++ nyelvben a típusazonosító önállóan is képviseli az enum típust.
Felsorolás típusú változó vagy felsorolási konstans kiírásakor az elemnek megfelelő egész érték jelenik meg. Beolvasással azonban egészen más a helyzet. Mivel az enum nem előre definiált típusa a C++ nyelvnek - ellentétben a fent ismertetett típusokkal -, a cin nem ismeri azt. A beolvasás – a példában látható módon – egy int típusú változó felhasználásával megoldható. Itt azonban gondot jelent a C++ nyelv típusossága, ami bizonyos átalakításokat csak akkor végez el, ha erre külön „megkérjük” a típus-átalakítás (cast) műveletének kijelölésével: típusnév(érték). (A megfelelő értéke ellenőrzéséről magunknak kell gondoskodni, a C++ nem foglalkozik vele.)
I.2.4. A sizeof művelet
A C++ nyelv tartalmaz egy olyan fordítás idején kiértékelésre kerülő operátort, amely megadja tetszőleges típus, illetve változó és kifejezés típusának bájtban kifejezett méretét.
sizeof (típusnév)
sizeof változó/kifejezés
sizeof (változó/kifejezés)
Ebből például következtethetünk a megadott kifejezés eredményének típusára:
cout << sizeof('A' + 'B') <<endl; // 4 - int
cout << sizeof(10 + 5) << endl; // 4 - int
cout << sizeof(10 + 5.0) << endl; // 8 - double
cout << sizeof(10 + 5.0F) << endl; // 4 - float
I.2.5. Szinonim típusnevek készítése
A változók definiálása során alkalmazott típusok - a típusminősítők és a típusmódosítók jóvoltából - általában több kulcsszóból épülnek fel. Az ilyen deklarációs utasítások nehezen olvashatók, sőt nem egy esetben megtévesztőek.
volatile unsigned short int jel;
Valójában előjel nélküli 16-bites egészeket szeretnénk tárolni a jel változóban. A volatile előírás csak a fordító számára közöl kiegészítő információt, a programozás során nincs vele dolgunk. A typedef deklaráció segítségével a fenti definíciót olvashatóbbá tehetjük:
typedef volatile unsigned short int uint16;
A fenti utasítás hatására létrejön az uint16 típusnév, így a jel változó definíciója:
uint16 jel;
A typedef-et felsorolások esetén is haszonnal alkalmazhatjuk:
typedef enum {hamis = -1, ismeretlen, igaz} bool3;
bool3 start = ismeretlen;
A típusnevek készítése mindig eredményes lesz, ha betartjuk a következő tapasztalati szabályt:
Írjunk fel egy kezdőérték nélküli változódefiníciót, ahol az a típus szerepel, amelyhez szinonim nevet kívánunk kapcsolni!
Írjuk a definíció elé a typedef kulcsszót, ami által a megadott név nem változót, hanem típust fog jelölni!
Különösen hasznos a typedef használata összetett típusok esetén, ahol a típusdefiníció felírása nem mindig egyszerű.
Végezetül nézzünk néhány gyakran használt szinonim típusnevet!
typedef unsigned char byte, uint8;
typedef unsigned short word, uint16;
typedef long long int int64;
I.2.6. Konstansok a C++ nyelvben
A programunk olvashatóságát nagyban növeli, ha a konstans értékek helyett neveket használunk. A C nyelv hagyományait követve C++-ban több lehetőség közül is választhatunk.
Kezdjük az áttekintést a #define konstansokkal (makrókkal), melyeket a C++ nyelvben javasolt elkerülni! A #define előfeldolgozó utasítás után két szöveg szerepel, szóközzel elválasztva. A preprocesszor végigmegy a C++ forráskódon, és felcseréli a definiált első szót a másodikkal. Felhívjuk a figyelmet arra, hogy az előfordító által használt neveket csupa nagybetűvel szokás írni, továbbá, hogy az előfordító utasításokat nem kell pontosvesszővel zárni.
#define ON 1
#define OFF 0
#define PI 3.14159265
int main()
{
int kapcsolo = ON;
double rad90 = 90*PI/180;
kapcsolo = OFF;
}
Az előfeldolgozás után az alábbi C++ programot kapja meg a fordító:
int main()
{
int kapcsolo = 1;
double rad90 = 90*3.14159265/180;
kapcsolo = 0;
}
E megoldás nagy előnye és egyben hátránya is a típusnélküliség.
Az C++ nyelv által támogatott konstans megoldások a const típusminősítőre és az enum típusra épülnek. A const kulcsszóval tetszőleges, kezdőértékkel ellátott változót konstanssá alakíthatunk. A C++ fordító semmilyen körülmények között sem engedi az így létrehozott konstansok értékének megváltoztatását. A fenti példaprogram átírt változata:
const int on = 1;
const int off = 0;
const double pi = 3.14159265;
int main()
{
int kapcsolo = on;
double rad90 = 90*pi/180;
kapcsolo = off;
}
A harmadik lehetőség, az enum típus használata, ami azonban csak egész (int) típusú konstansok esetén alkalmazható. Az előző példa kapcsoló konstansait felsorolásban állítjuk elő:
enum kibe { off, on };
int kapcsolo = on;
kapcsolo = off;
Az enum és a const konstansok igazi konstansok, hisz nem tárolja őket a memóriában a fordító. Míg a #define konstansok a definiálás helyétől a fájl végéig fejtik hatásukat, addig az enum és a const konstansokra a szokásos C++ láthatósági és élettartam szabályok érvényesek.
I.3. Alapműveletek és kifejezések
Az adatok tárolásának megoldását követően továbbléphetünk az információk megszerzésének irányába. Az információ általában egy adatfeldolgozási folyamat eredményeként jön létre, amely folyamat a C++ nyelven utasítások sorozatának végrehajtását jelenti. A legegyszerűbb adatfeldolgozási mód, amikor az adatainkon, mint operandusokon különböző (aritmetikai, logikai, bitenkénti stb.) műveleteket végzünk. Ennek eredménye egy újabb adat, vagy maga a számunkra szükséges információ. (Az adatot a célirányossága teszi információvá.) A műveleti jelekkel (operátorokkal) összekapcsolt operandusokat kifejezésnek nevezzük. C++ nyelvben a legnépesebb utasításcsoportot a pontosvesszővel lezárt kifejezések (értékadás, függvényhívás, …) alkotják
Egy kifejezés kiértékelése általában valamilyen érték kiszámításához vezet, függvényhívást idéz elő, vagy mellékhatást (side effect) okoz. Az esetek többségében a fenti három hatás valamilyen kombinációja megy végbe a kifejezések feldolgozása (kiértékelése) során.
A műveletek az operandusokon fejtik ki hatásukat. Azokat az operandusokat, amelyek nem igényelnek további kiértékelést elsődleges (primary) kifejezéseknek nevezzük. Ilyenek az azonosítók, a konstans értékek és a zárójelben megadott kifejezések.
I.3.1. Az operátorok csoportosítása az operandusok száma alapján
Az operátorokat több szempont alapján lehet csoportosítani. A csoportosítást elvégezhetjük az operandusok száma szerint. Az egyoperandusú (unary) operátorok esetén a kifejezés általános alakja:
op operandus vagy operandus op
Az első esetben, amikor az operátor (op) megelőzi az operandust előrevetett (prefixes), míg a második esetben hátravetett (postfixes) alakról beszélünk:
|
|
előjelváltás, |
|
|
n értékének növelése (postfix), |
|
|
n értékének csökkentése (prefix), |
|
|
n értékének valóssá alakítása. |
A műveletek többsége két operandussal rendelkezik - ezek a kétoperandusú (binary) operátorok: operandus1 op operandus2
Ebben a csoportban a hagyományos aritmetikai és relációs műveletek mellett a bitműveleteket is helyet kapnak:
|
|
n alsó bájtjának kinyerése, |
|
|
n + 2 kiszámítása, |
|
|
n bitjeinek eltolása 3 pozícióval balra, |
|
|
n értékének növelése 5-tel. |
A C++ nyelv egy háromoperandusú művelettel is rendelkezik, ez a feltételes operátor:
operandus1 ? operandus2 : operandus3
I.3.2. Elsőbbségi és csoportosítási szabályok
Akárcsak a matematikában, a kifejezések kiértékelése az elsőbbségi (precedencia) szabályok szerint történik. Ezek a szabályok meghatározzák a kifejezésekben szereplő, különböző elsőbbséggel rendelkező műveletek végrehajtási sorrendjét. Az azonos elsőbbségi operátorok esetén a balról-jobbra, illetve a jobbról-balra csoportosítás (asszociativitás) ad útmutatást. A C++ nyelv műveleteit az A.7. szakasz - C++ műveletek elsőbbsége és csoportosítása függelék tartalmazza, az elsőbbségek csökkenő sorrendjében. A táblázat jobb oldalán az azonos precedenciájú műveletek végrehajtási irányát is feltüntettük.
I.3.2.1. A precedencia-szabály
Ha egy kifejezésben különböző elsőbbségű műveletek szerepelnek, akkor mindig a magasabb precedenciával rendelkező operátort tartalmazó részkifejezés értékelődik ki először.
A kiértékelés sorrendjét a matematikából ismert zárójelek segítségével megerősíthetjük vagy megváltoztathatjuk. C++ nyelvben csak a kerek zárójel () használható, bármilyen mélységű zárójelezést is készítünk. Tapasztalati szabályként elmondható, ha egy kifejezésben két vagy kettőnél több különböző művelet szerepel, használjunk zárójeleket az általunk kívánt kiértékelési sorrend biztosítása érdekében. Inkább legyen eggyel több felesleges zárójelünk, mintsem egy hibás kifejezésünk.
Az a+b*c-d*e és az a+(b*c)-(d*e) kifejezések kiértékelési sorrendje megegyezik, így a kifejezések kiértékelésének lépései (* a szorzás művelete):
int a = 6, b = 5, c = 4, d = 2, e = 3; b * c ⇒ 20 d * e ⇒ 6 a + b * c ⇒ a + 20 ⇒ 26 a + b * c - d * e ⇒ 26 - 6 ⇒ 20
Az (a+b)*(c-d)*e kifejezés feldolgozásának lépései:
int a = 6, b = 5, c = 4, d = 2, e = 3; (a + b) ⇒ 11 (c - d) ⇒ 2 (a + b) * (c - d) ⇒ 11 * 2 ⇒ 22 22 * e ⇒ 22 * 3 ⇒ 66
I.3.2.2. Az asszociativitás szabály
Az asszociativitás határozza meg, hogy az adott precedenciaszinten található műveleteket balról-jobbra vagy jobbról-balra haladva kell elvégezni.
Például, az értékadó utasítások csoportjában a kiértékelés jobbról-balra halad, ami lehetővé teszi, hogy több változónak egyszerre adjunk értéket:
a = b = c = 0; azonos az a = (b = (c = 0));
Amennyiben azonos precedenciájú műveletek szerepelnek egy aritmetikai kifejezésben, akkor a balról-jobbra szabály lép életbe. Az a+b*c/d*e kifejezés kiértékelése három azonos elsőbbségű művelet végrehajtásával indul. Az asszociativitás miatt a kiértékelési sorrend:
int a = 6, b = 5, c = 4, d = 2, e = 3; b * c ⇒ 20 b * c / d ⇒ 20 / d ⇒ 10 b * c / d * e ⇒ 10 * e ⇒ 30 a + b * c / d * e ⇒ a + 30 ⇒ 36
Matematikai képletre átírva jól látszik a műveletek sorrendje:
Ha a feladat az 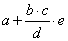 képlet programozása, akkor ezt kétféleképpen is megoldhatjuk:
képlet programozása, akkor ezt kétféleképpen is megoldhatjuk:
zárójelbe tesszük a nevezőt, így a szorzattal osztunk:
a+b*c/(d*e),a nevezőben szereplő szorzat mindkét tagjával osztunk:
a+b*c/d/e.
I.3.3. Matematikai kifejezések
A legegyszerűbb programokat általában matematikai feladatok megoldásához hívjuk segítségül. A matematikai kifejezésekben az alapműveletek (C++ szóhasznával aritmetikai operátorok) mellett különböző függvényeket is használunk.
I.3.3.1. Aritmetikai operátorok
Az aritmetikai operátorok csoportja a szokásos négy alapműveleten túlmenően a maradékképzés operátorát (%) is tartalmazza. Az összeadás (+), a kivonás (-), a szorzás (*) és az osztás (/) művelete egész és lebegőpontos számok esetén egyaránt elvégezhető. Az osztás egésztípusú operandusok esetén egészosztást jelöl:
29 / 7 a kifejezés értéke (a hányados) 4
29 % 7 az kifejezés értéke (a maradék) 1
Nem nulla, egész a és b esetén mindig igaz az alábbi kifejezés:
(a / b) * b + (a % b) ⇒ a
A csoportba tartoznak az egyoperandusú mínusz (-) és plusz (+) operátorok is. A mínusz előjel a mögötte álló operandus értékét ellentétes előjelűre változtatja (negálja).
I.3.3.2. Matematikai függvények
Amennyiben a fenti alapműveleteken túlmenően további matematikai műveletekre is szükségünk van, a szabványos C++ könyvtár matematikai függvényeit kell használnunk. A függvények eléréséhez a cmath deklarációs állományt szükséges beépíteni a programunkba. A leggyakrabban használt matematikai függvényeket az A.8. szakasz - Néhány gyakran használt matematikai függvény függelékben foglaltuk össze. A könyvtár minden függvényt három változatban bocsát rendelkezésünkre, a három lebegőpontos típusnak (float, double, long double) megfelelően.
Példaként tekintsük a mindenki által jól ismert egyismeretlenes, másodfokú egyenlet megoldóképletét, ahol a, b és c az egyenlet együtthatói!
|
|
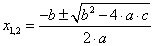
A megoldóképlet C++ programban:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
double a = 1, b = -5, c =6, x1, x2;
x1 = (-b + sqrt(b*b-4*a*c))/(2*a);
x2 = (-b - sqrt(b*b-4*a*c))/(2*a);
cout << x1 << endl;
cout << x2 << endl;
}
I.3.4. Értékadás
A változók általában az értékadás során kapnak értéket, melynek általános alakja:
változó = érték;
A C++ nyelven az értékadó műveletet (=) tartalmazó utasítás valójában egy kifejezés, amit a fordítóprogram kiértékel, és értéke a jobb oldalon megadott érték. Az értékadás operátorának mindkét oldalán szerepelhetnek kifejezések, melyek azonban alapvetően különböznek egymástól. A bal oldalon szereplő kifejezés azt a memóriaterületet jelöli ki, ahol a jobb oldalon megadott kifejezés értékét tárolni kell.
I.3.4.1. Balérték és jobbérték
A C++ nyelv külön nevet ad az értékadás két oldalán álló kifejezések értékeinek. Az egyenlőségjel bal oldalán álló kifejezésnek az értéke a balérték (lvalue), míg a jobb oldalon szereplő kifejezés értéke a jobbérték (rvalue). Tekintsünk példaként két egyszerű értékadást!
int x;
x = 12;
x = x + 11;
Az első értékadás során az x változó, mint balérték szerepel, vagyis a változó címe jelöli ki azt a tárolót, ahova a jobb oldalon megadott konstans értéket be kell másolni. A második értékadás során az x változó az értékadás mindkét oldalán megtalálható. A bal oldalon álló x ugyancsak a tárolót jelöli ki a memóriában (lvalue), míg a jobb oldalon álló x egy jobbérték kifejezésben szerepel, melynek értékét (23) a fordító határozza meg az értékadás elvégzése előtt. (Megjegyezzük, hogy a teljes kifejezés értéke is egy jobbérték, melyet semmire sem használunk.)
I.3.4.2. Mellékhatások a kiértékelésekben
Mint már említettük, minden kifejezés kiértékelésének alapvető célja a kifejezés értékének kiszámítása. Ennek ellenére bizonyos műveletek – az értékadás, a függvényhívás és a később bemutatásra kerülő léptetés (++, --) – feldolgozása során a kifejezés értékének megjelenése mellett az operandusok értéke is megváltozhat. Ezt a jelenséget mellékhatásnak (side effect) hívjuk.
A mellékhatások kiértékelésének sorrendjét nem határozza meg a C++ szabvány, ezért javasolt minden olyan megoldás elkerülése, ahol a kifejezés eredménye függ a mellékhatások kiértékelésének sorrendjétől, például:
a[i] = i++; // ↯ y = y++ + ++y; // ↯ cout<<++n<<pow(2,n)<<endl; // ↯
I.3.4.3. Értékadó operátorok
Már említettük, hogy C++ nyelvben az értékadás egy olyan kifejezés, amely a bal oldali operandus által kijelölt tárolónak adja a jobb oldalon megadott kifejezés értékét, másrészt pedig ez az érték egyben az értékadó kifejezés értéke is. Ebből következik, hogy értékadás tetszőleges kifejezésben szerepelhet. Az alábbi példában a bal oldalon álló kifejezések eredménye megegyezik a jobb oldalon állókéval:
|
|
|
|
|
|
Az értékadások gyakran használt formája, amikor egy változó értékét valamilyen művelettel módosítjuk, és a keletkező új értéket tároljuk a változóban:
a = a + 2;
Az ilyen alakú kifejezések tömörebb formában is felírhatók:
a += 2;
Általánosan is elmondható, hogy a
kifejezés1 = kifejezés1 op kifejezés2
alakú kifejezések felírására az ún. összetett értékadás műveletét is használhatjuk:
kifejezés1 op= kifejezés2
A két felírás egyenértékű, attól a különbségtől eltekintve, hogy a második esetben a bal oldali kifejezés kiértékelése csak egyszer történik meg. Operátorként (op) a kétoperandusú aritmetikai és bitműveleteket használhatjuk. (Megjegyezzük, hogy az operátorokban szereplő karakterek közzé nem szabad szóközt tenni!)
Az összetett értékadás használata általában gyorsabb kódot eredményez, és könnyebben értelmezhetővé teszi a forrásprogramot.
I.3.5. Léptető (inkrementáló/dekrementáló) műveletek
A C++ nyelv hatékony lehetőséget biztosít a numerikus változók értékének eggyel való növelésére ++ (increment), illetve eggyel való csökkentésére -- (decrement). Az operátorok csak balérték operandussal használhatók, azonban mind az előrevetett, mind pedig a hátravetett forma alkalmazható:
int a; // prefixes alakok: ++a; --a; // postfixes alakok: a++; a--;
Amennyiben az operátorokat a fent bemutatott módon használjuk, nem látszik különbség az előrevetett és hátravetett forma között, hiszen mindkét esetben a változó értéke léptetődik. Ha azonban az operátort bonyolultabb kifejezésben alkalmazzuk, akkor a prefixes alak használata esetén a léptetés a kifejezés feldolgozása előtt megy végbe, és az operandus az új értékével vesz részt a kifejezés kiértékelésében:
int n, m = 5; m = ++n; // m ⇒ 6, n ⇒ 6
Postfixes forma esetén a léptetés az kifejezés kiértékelését követi, így az operandus az eredeti értékével vesz részt a kifejezés feldolgozásában:
double x, y = 5.0; x = y++; // x ⇒ 5.0, y ⇒ 6.0
A léptető operátorok működését jobban megértjük, ha a bonyolultabb kifejezéseket részkifejezésekre bontjuk. Az
int a = 2, b = 3, c; c = ++a + b--; // a 3, b 2, c pedig 6 lesz
kifejezés az alábbi (egy, illetve többutasításos) kifejezésekkel megegyező eredményt szolgáltat (a vessző műveletről később szólunk):
a++, c=a+b, b--; a++; c=a+b; b--;
Az eggyel való növelés és csökkentés hagyományos formái
a = a + 1; a += 1; a = a - 1; a -= 1;
helyett mindig érdemes a megfelelő léptető operátort alkalmazni,
++a; vagy a++; --a; vagy a--;
amely a jobb áttekinthetőség mellett, gyorsabb kód létrehozását is eredményezi.
Felhívjuk a figyelmet arra, hogy egy adott változó, egy kifejezésen belül ne szerepeljen többször léptető művelet operandusaként! Az ilyen kifejezések értéke teljes mértékben fordítófüggő.
a += a++ * ++a; // ↯
I.3.6. Feltételek megfogalmazása
A C++ nyelv utasításainak egy része valamilyen feltétel függvényében végzi a tevékenységét. Az utasításokban szereplő feltételek tetszőleges kifejezések lehetnek, melyek nulla vagy nem nulla értéke szolgáltatja a logikai hamis, illetve igaz eredményt. A feltételek felírása során összehasonlító (relációs) és logikai műveleteket használunk.
I.3.6.1. Összehasonlító műveletek
Az összehasonlítások elvégzésére kétoperandusú, összehasonlító operátorok állnak rendelkezésünkre, az alábbi táblázatnak megfelelően:
|
Matematikai alak |
C++ kifejezés |
Jelentés |
|---|---|---|
|
|
|
a kisebb, mint b |
|
|
|
a kisebb vagy egyenlő, mint b |
|
|
|
a nagyobb, mint b |
|
|
|
a nagyobb vagy egyenlő, mint b |
|
|
|
a egyenlő b-vel |
|
|
|
a nem egyenlő b-vel |
A fenti C++ kifejezések mindegyike int típusú. A kifejezések értéke true (1), ha a vizsgált reláció igaz, illetve false (0), ha nem.
Példaként írjunk fel néhány különböző típusú operandusokat tartalmazó igaz kifejezést!
int i = 3, k = 2, n = -3; i > k n <= 0 i+k > n i != k char elso = 'A', utolso = 'Z'; elso <= utolso elso == 65 'N' > elso double x = 1.2, y = -1.23E-7; -1.0 < y 3 * x >= (2 + y) fabs(x-y)>1E-5
Felhívjuk a figyelmet arra, hogy számítási és ábrázolási pontatlanságok következtében két lebegőpontos változó azonosságát általában nem szabad az == operátorral ellenőrizni. Helyette a két változó különbségének abszolút értékét kell vizsgálnunk adott hibahatárral:
double x = log(sin(3.1415926/2)); double y = exp(x); cout << setprecision(15)<<scientific<< x<< endl; // x ⇒ -3.330669073875470e-016 cout << setprecision(15)<<scientific<< y<< endl; // y ⇒ .999999999999997e-001 cout << (x == 0) << endl; // hamis cout << (y == 1) << endl; // hamis cout << (fabs(x)<1e-6) << endl; // igaz cout << (fabs(y-1.0)<1e-6)<< endl; // igaz
Gyakori programhiba az értékadás (=) és az azonosságvizsgálat (==) műveleteinek összekeverése. Változó konstanssal való összehasonlítása biztonságossá tehető, ha bal oldali operandusként a konstanst adjuk meg, hiszen értékadás esetén itt balértéket vár a fordító:
dt == 2004 helyett 2004 == dt
I.3.6.2. Logikai műveletek
Ahhoz, hogy bonyolultabb feltételeket is meg tudjunk fogalmazni, a relációs operátorok mellett logikai operátorokra is szükségünk van. C++-ban a logikai ÉS (konjunkció , &&), a logikai VAGY (diszjunkció, ||) és a tagadás (negáció, !) művelete használható a feltételek felírása során.
A logikai operátorok működését ún. igazságtáblával írhatjuk le:
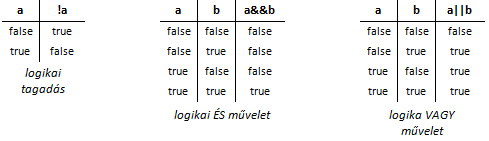
Az alábbi feltétel akkor igaz, ha az x változó értéke -1 és +1 közé esik. A zárójelekkel csupán megerősítjük a precedenciát.
-1 < x && x < 1
(-1 < x) && (x < 1)
Vannak esetek, amikor valamely feltétel felírása helyett egyszerűbb az ellentett feltételt megfogalmazni, és alkalmazni rá a logikai tagadás (NEM) operátorát (!). Az előző példában alkalmazott feltétel egyenértékű az alábbi feltétellel:
!(-1 >= x || x >= 1)
A logikai tagadás során minden relációt az ellentétes irányú relációra, az ÉS operátort pedig a VAGY operátorra (illetve fordítva) cseréljük.
A C++ programokban, a numerikus ok változóval gyakran találkozhatunk a
ok == 0 kifejezés helyett a !ok
ok != 0 kifejezés helyett az ok
kifejezéssel. A jobb oldali kifejezéseket leginkább bool típusú ok változóval javasolt alkalmazni.
I.3.6.3. Rövidzár kiértékelés
A művelettáblázatból látható, hogy a logikai kifejezések kiértékelése balról-jobbra haladva történik. Bizonyos műveleteknél nem szükséges a teljes kifejezést feldolgozni ahhoz, hogy egyértelmű legyen a kifejezés értéke.
Példaként vegyük a logikai ÉS (&&) műveletet, mely használata esetén a bal oldali operandus false (0) értéke a jobb oldali operandus feldolgozását feleslegessé teszi! Ezt a kiértékelési módot rövidzár (short-circuit) kiértékelésnek nevezzük.
Ha a rövidzár kiértékelése során a logikai operátor jobb oldalán valamilyen mellékhatás kifejezés áll,
x || y++
az eredmény nem mindig lesz az, amit várunk. A fenti példában x nem nulla értéke esetén az y léptetésére már nem kerül sor. A rövidzár kiértékelés akkor is érvényesül, ha a logikai műveletek operandusait zárójelek közé helyezzük:
(x) || (y++)
I.3.6.4. A feltételes operátor
A feltételes operátor (?:) három operandussal rendelkezik:
feltétel ? igaz_kifejezés : hamis_kifejezés
Ha a feltétel igaz (true), akkor az igaz_kifejezés értéke adja a feltételes kifejezés értékét, ellenkező esetben pedig a kettőspont (:) után álló hamis_kifejezés. Ily módon a kettőspont két oldalán álló kifejezések közül mindig csak az egyik értékelődik ki. A feltételes kifejezés típusa a nagyobb pontosságú részkifejezés típusával egyezik meg. Az
(n > 0) ? 3.141534 : 54321L;
kifejezés típusa, függetlenül az n értékétől mindig double lesz.
Nézzünk egy jellegzetes példát a feltételes operátor alkalmazására! Az alábbi kifejezés segítségével az n változó 0 és 15 közötti értékeit hexadecimális számjeggyé alakítjuk:
ch = n >= 0 && n <= 9 ? '0' + n : 'A' + n - 10;
Felhívjuk a figyelmet arra, hogy a feltételes művelet elsőbbsége elég alacsony, épphogy megelőzi az értékadásét, ezért összetettebb kifejezésekben zárójelet kell használnunk:
c = 1 > 2 ? 4 : 7 * 2 < 3 ? 4 : 7 ; // 7 ↯
c = (1 > 2 ? 4 : (7 * 2)) < 3 ? 4 : 7 ; // 7 ↯
c = (1 > 2 ? 4 : 7) * (2 < 3 ? 4 : 7) ; //28
I.3.7. Bitműveletek
Régebben a számítógépek igen kevés memóriával rendelkeztek, így nagyon értékesek voltak azok a megoldások, amelyek a legkisebb címezhető egységen, a bájton belül is lehetővé tették több adat tárolását és feldolgozását. Bitműveletek segítségével egy bájtban akár 8 darab logikai értéket is elhelyezhetünk. Napjainkban ez a szempont csak igen ritkán érvényesül, és inkább a program érthetőségét tartjuk szem előtt.
Van mégis egy terület, ahol a bitműveleteknek napjainkban is hasznát vehetjük, nevezetesen a különböző hardverelemek, mikrovezérlők programozása. A C++ nyelv tartalmaz hat operátort, amelyekkel különböző bitenkénti műveleteket végezhetünk előjeles és előjel nélküli egész adatokon.
I.3.7.1. Bitenkénti logikai műveletek
A műveletek első csoportja, a bitenkénti logikai műveletek, lehetővé teszik, hogy biteket teszteljünk, töröljünk vagy beállítsunk:
|
Operátor |
Művelet |
|---|---|
|
|
1-es komplemens, bitenkénti tagadás |
|
|
bitenkénti ÉS |
|
|
bitenkénti VAGY |
|
|
bitenkénti kizáró VAGY |
A bitenkénti logikai műveletek működésének leírását az alábbi táblázat tartalmazza, ahol a 0 és az 1 számjegyek a törölt, illetve a beállított bitállapotot jelölik.
|
a |
b |
a & b |
a | b |
a ^ b |
~a |
|---|---|---|---|---|---|
|
0 |
0 |
0 |
0 |
0 |
1 |
|
0 |
1 |
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
1 |
1 |
0 |
|
1 |
1 |
1 |
1 |
0 |
0 |
A számítógép hardverelemeinek alacsony szintű vezérlése általában bizonyos bitek beállítását, törlését, illetve kapcsolását igényli. Ezeket a műveleteket összefoglaló néven „maszkolásnak” nevezzük, mivel minden egyes művelethez megfelelő bitmaszkot kell készítenünk, amellyel aztán logikai kapcsolatba hozva a megváltoztatni kívánt értéket, végbemegy a kívánt bitművelet.
Mielőtt sorra vennénk a szokásos bitműveleteket, meg kell ismerkednünk az egész adatelemek bitjeinek sorszámozásával. A bitek sorszámozása a bájton a legkisebb helyértékű bittől indulva 0-val kezdődik, és balra haladva növekszik. Több bájtból álló egészek esetén azonban tisztáznunk kell a számítógép processzorában alkalmazott bájtsorrendet is.
A Motorola 68000, SPARC, PowerPC stb. processzorok által támogatott „nagy a végén” (big-endian) bájtsorrend esetén a legnagyobb helyiértékű bájt (MSB) a memóriában a legalacsonyabb címen tárolódik, míg az eggyel kisebb helyiértékű a következő címen és így tovább.
Ezzel szemben a legelterjedtebb Intel x86 alapú processzorcsalád tagjai a „kicsi a végén” (little-endian) bájtsorrendet használják, amely szerint legkisebb helyiértékű bájt (LSB) helyezkedik el a legalacsonyabb címen a memóriában.
A hosszú bitsorozatok elkerülése érdekében a példáinkban unsigned short int típusú adatelemeket használunk. Nézzük meg ezen adatok felépítését és tárolását mindkét bájtsorrend szerint! A tárolt adat legyen 2012, ami hexadecimálisan 0x07DC!
big-endian bájtsorrend:

little-endian bájtsorrend:

(A példákban a memóriacímek balról jobbra növekednek.) Az ábrán jól látható, hogy a hexadecimális konstans értékek megadásakor az első, „nagy a végén” formát használjuk, ami megfelel a 16-os számrendszer matematikai értelmezésének. Ez nem okoz gondot, hisz a memóriában való tárolás a fordítóprogram feladata. Ha azonban az egész változókat bájtonként kívánjuk feldolgozni, ismernünk kell a bájtsorrendet. Könyvünk további részeiben a második, a „kicsi a végén” forma szerint készítjük el a példaprogramjainkat, amelyek azonban az elmondottak alapján az első tárolási módszerre is adaptálhatók.
Az alábbi példákban az unsigned short int típusú 2525 szám 4. és 13. bitjeit kezeljük:
unsigned short int x = 2525; // 0x09dd
|
Művelet |
Maszk |
C++ utasítás |
Eredmény |
|---|---|---|---|
|
Bitek beállítása |
0010 0000 0001 0000 |
x = x | 0x2010; |
0x29dd |
|
Bitek törlése |
1101 1111 1110 1111 |
x = x & 0xdfef; |
0x09cd |
|
Bitek negálása (kapcsolása) |
0010 0000 0001 0000 |
x = x ^ 0x2010; x = x ^ 0x2010; |
0x29cd (10701) 0x09dd (2525) |
|
Az összes bit negálása |
1111 1111 1111 1111 |
x = x ^ 0xFFFF; |
0xf622 |
|
Az összes bit negálása |
x = ~x; |
0xf622 |
Felhívjuk a figyelmet a kizáró vagy operátor (^) érdekes viselkedésére. Ha ugyanazzal a maszkkal kétszer végezzük el a kizáró vagy műveletet, akkor visszakapjuk az eredeti értéket, esetünkben a 2525-öt. Ezt a működést felhasználhatjuk két egész változó értékének segédváltozó nélküli felcserélésére:
int m = 2, n = 7; m = m ^ n; n = m ^ n; m = m ^ n;
Nehezen kideríthető programhibához vezet, ha a programunkban összekeverjük a feltételekben használt logikai műveleti jeleket (!, &&, ||) a bitenkénti operátorokkal (~, &, |).
I.3.7.2. Biteltoló műveletek
A bitműveletek másik csoportjába, a biteltoló (shift) operátorok tartoznak. Az eltolás balra (<<) és jobbra (>>) egyaránt elvégezhető. Az eltolás során a bal oldali operandus bitjei annyiszor lépnek balra (jobbra), amennyi a jobb oldali operandus értéke.
Balra eltolás esetén a felszabaduló bitpozíciókba 0-ás bitek kerülnek, míg a kilépő bitek elvesznek. A jobbra eltolás azonban figyelembe veszi, hogy a szám előjeles vagy sem. Előjel nélküli (unsigned) típusok esetén balról 0-ás bit lép be, míg előjeles (signed) számoknál 1-es bit. Ez azt jelenti, hogy a jobbra való biteltolás előjelmegőrző.
short int x;
|
Értékadás |
Bináris érték |
Művelet |
Eredmény decimális (hexadecimális) bináris |
|---|---|---|---|
|
x = 2525; |
0000 1001 1101 1101 |
x = x << 2; |
10100 (0x2774) 0010 0111 0111 0100 |
|
x = 2525; |
0000 1001 1101 1101 |
x = x >> 3; |
315 (0x013b) 0000 0001 0011 1011 |
|
x = -2525; |
1111 0110 0010 0011 |
x = x >> 3; |
-316 (0xfec4) 1111 1110 1100 0100 |
Az eredményeket megvizsgálva láthatjuk, hogy az 2 bittel való balra eltolás során az x változó értéke négyszeresére (22) nőtt, míg három lépéssel jobbra eltolva, x értéke nyolcad (23) részére csökkent. Általánosan is megfogalmazható, hogy valamely egész szám bitjeinek balra tolása n lépéssel a szám 2n értékkel való megszorzását eredményezi. Az m bittel való jobbra eltolás pedig 2m értékkel elvégzett egész osztásnak felel meg. Megjegyezzük, hogy egy egész szám 2n-nel való szorzásának/osztásának ez a leggyorsabb módja.
Az alábbi példában a beolvasott 16-bites egész számot két bájtra bontjuk:
short int num; unsigned char lo, hi; // A szám beolvasása cout<<"\nKerek egy egesz szamot [-32768,32767] : "; cin>>num; // Az alsó bájt meghatározása maszkolással lo=num & 0x00FFU; // Az felső byte meghatározása biteltolással hi=num >> 8;
Az utolsó példában felcseréljük a 4-bájtos, int típusú változó bájtsorrendjét:
int n =0x12345678U;
n = (n >> 24) | // az első bájtot a végére mozgatjuk,
((n << 8) & 0x00FF0000U) | // a 2. bájtot a 3. bájtba,
((n >> 8) & 0x0000FF00U) | // a 3. bájtot a 2. bájtba,
(n << 24); // az utolsó bájtot pedig az elejére.
cout <<hex << n <<endl; // 78563412
I.3.7.3. Bitműveletek az összetett értékadásban
A C++ mind az öt kétoperandusú bitművelethez összetett értékadás művelet is tartozik, melyekkel a változók értéke könnyebben módosítható.
|
Operátor |
Műveleti jel |
Használat |
Művelet |
|---|---|---|---|
|
Balra eltoló értékadás |
|
|
x bitjeinek eltolása balra y bittel, |
|
Jobbra eltoló értékadás |
|
|
x bitjeinek eltolása jobbra y bittel, |
|
Bitenkénti VAGY értékadás |
|
|
x új értéke: x | y, |
|
Bitenkénti ÉS értékadás |
|
|
x új értéke: x & y, |
|
Bitenkénti kizáró VAGY értékadás |
|
|
x új értéke: x ^ y, |
Fontos megjegyeznünk, hogy a bitműveletek eredményének típusa legalább int vagy az int-nél nagyobb egész típus, a bal oldali operandus típusától függően. Biteltolás esetén a lépések számát ugyan tetszőlegesen megadhatjuk, azonban a fordító a típus bitméretével képzett maradékát alkalmazza az eltoláshoz. Például a 32-bites int típusú változók esetében az alábbiakat tapasztalhatjuk:
unsigned z; z = 0xFFFFFFFF, z <<= 31; // z ⇒ 80000000 z = 0xFFFFFFFF, z <<= 32; // z ⇒ ffffffff z = 0xFFFFFFFF, z <<= 33; // z ⇒ fffffffe
I.3.8. A vessző operátor
Egyetlen kifejezésben több, akár egymástól független kifejezést is elhelyezhetünk, a legkisebb elsőbbségű vessző operátor felhasználásával. A vessző operátort tartalmazó kifejezés balról-jobbra haladva értékelődik ki, a kifejezés értéke és típusa megegyezik a jobb oldali operandus értékével, illetve típusával. Példaként tekintsük az
x = (y = 4 , y + 3);
kifejezést! A kiértékelés a zárójelbe helyezett vessző operátorral kezdődik, melynek során először az y változó kap értéket (4), majd pedig a zárójelezett kifejezés (4+3=7). Végezetül az x változó megkapja a 7 értéket.
A vessző operátort gyakran használjuk változók különböző kezdőértékének egyetlen utasításban (kifejezésben) történő beállítására:
x = 2, y = 7, z = 1.2345 ;
Ugyancsak a vessző operátort kell alkalmaznunk, ha két változó értékét egyetlen utasításban kívánjuk felcserélni (harmadik változó felhasználásával):
c = a, a = b, b = c;
Felhívjuk a figyelmet arra, hogy azok a vesszők, amelyeket a deklarációkban a változónevek, illetve a függvényhíváskor az argumentumok elkülönítésére használunk nem vessző operátorok.
I.3.9. Típuskonverziók
A kifejezések kiértékelése során gyakran előfordul, hogy egy kétoperandusú műveletet különböző típusú operandusokkal kell végrehajtani. Ahhoz azonban, hogy a művelet elvégezhető legyen, a fordítónak azonos típusúra kell átalakítania a két operandust, vagyis típuskonverziót kell végrehajtania.
C++-ban a típus-átalakítások egy része automatikusan, a programozó beavatkozása nélkül megy végbe, a nyelv definíciójában rögzített szabályok alapján. Ezeket a konverziókat implicit vagy automatikus konverzióknak nevezzük.
C++ programban a programozó is előírhat típus-átalakítást a típuskonverziós operátorok (cast) felhasználásával ( explicit típuskonverzió).
I.3.9.1. Implicit típus-átalakítások
Általánosságban elmondható, hogy az automatikus konverziók során a „szűkebb értéktartományú” operandus adatvesztés nélkül átalakul a „szélesebb értéktartományú” operandus típusára. Az alábbi példában az m+d kifejezés kiértékelése során az int típusú m operandus double típusúvá alakul, ami egyben a kifejezés típusát is jelenti:
int m=4, n; double d=3.75; n = m + d;
Az implicit konverziók azonban nem minden esetben mennek végbe adatvesztés nélkül. Az értékadás és a függvényhívás során tetszőleges típusok közötti konverzió is előfordulhatnak. Például, a fenti példában az összeg n változóba töltésekor adatvesztés lép fel, hiszen az összeg törtrésze elvész, és 7 lesz a változó értéke. (Felhívjuk a figyelmet, hogy semmilyen kerekítés nem történt az értékadás során!)
A következőkben röviden összefoglaljuk az x op y alakú kifejezések kiértékelése során automatikusan végrehajtódó konverziókat.
A char, wchar_t, short, bool, enum típusú adatok automatikusan int típussá konvertálódnak. Ha az int típus nem alkalmas az értékük tárolására, akkor unsigned int lesz a konverzió céltípusa. Ez a típus-átalakítási szabály az „egész konverzió” (integral promotion) nevet viseli. A fenti konverziók értékmegőrző átalakítások, mivel érték- és előjelhelyes eredményt adnak.
Ha az első lépés után a kifejezésben különböző típusok szerepelnek, életbe lép a típusok hierarchiája szerinti konverzió. A típus-átalakítás során a „kisebb” típusú operandus a „nagyobb” típusúvá konvertálódik. Az átalakítás során felhasznált szabályok a „szokásos aritmetikai konverziók” nevet viselik.
int < unsigned < long < unsigned long < longlong < unsigned longlong < float < double < long double
I.3.9.2. Explicit típus-átalakítások
Az explicit módon megadott felhasználói típus-átalakítások célja az implicit módon nem végrehajtódó típuskonverziók elvégzése. Most csak az alaptípusokkal használható átalakításokkal foglalkozunk, míg a const_cast, a dynamic_cast és a reinterpret_cast műveletekről az I.6. szakasz - Mutatók, hivatkozások és a dinamikus memóriakezelés fejezetben olvashatunk.
Az alábbi (statikus) típuskonverziók mindegyike a C++ program fordítása során hajtódik végre. A típus-átalakítások egy lehetséges csoportosítása:
|
típus-átalakítás (C/C++) |
(típusnév) kifejezés |
|
|
függvényszerű forma |
típusnév (kifejezés) |
|
|
ellenőrzött típus-átalakítások |
static_cast< típusnév >(kifejezés) |
|
Minden kifejezés felírásakor gondolnunk kell az implicit és az esetleg szükséges explicit konverziókra. Az alábbi programrészlettel két hosszú egész változó átlagát kívánjuk meghatározni, és double típusú változóba tárolni:
long a =12, b=7; double d = (a+b)/2; cout << d << endl; // 9
Az eredmény hibás, mivel az egész konverziók következtében az értékadás jobb oldalán egy long típusú eredmény keletkezik, és ez kerül a d változóba. Az eredmény csak akkor lesz helyes (9.5), ha az osztás valamelyik operandusát double típusúvá alakítjuk, az alábbi lehetőségek egyikével:
d = (a+b)/2.0; d = (double)(a+b)/2; d = double(a+b)/2; d = static_cast<double>(a+b)/2;
I.4. Vezérlő utasítások
Az eddigi ismereteink alapján csak olyan programokat tudunk készíteni, melynek main () függvényében csak pontosvesszővel lezárt kifejezések szerepelnek (adatbevitel, értékadás, kiírás stb.) egymás után. Bonyolultabb algoritmusok programozásához azonban ez a soros felépítésű programszerkezet nem elegendő. Meg kell ismerkednünk a C++ nyelv vezérlő utasításaival, melyek lehetővé teszik bizonyos programrészek feltételtől függő, illetve ismételt végrehajtását. (Tájékoztatásul, a C++ utasítások összefoglalását az A.5. szakasz - A C++ nyelv utasításai függelék tartalmazza.)
I.4.1. Az üres utasítás és az utasításblokk
Az C++ nyelv vezérlő utasításai más utasítások végrehajtását „vezérlik”. Amennyiben semmilyen tevékenységes sem kívánunk „vezéreltetni” az üres utasítást adjuk meg. Ha azonban több utasítás „vezérlésére” van szüksége, akkor az ún. összetett utasítást, vagyis az utasításblokkot kell alkalmaznunk.
Az üres utasítás egyetlen pontosvesszőből (;) áll. Használatára akkor van szükség, amikor logikailag nem kívánunk semmilyen tevékenységet végrehajtani, azonban a szintaktikai szabályok szerint a program adott pontján utasításnak kell szerepelnie.
Kapcsos zárójelek ( { és } ) segítségével a logikailag összefüggő deklarációkat és utasításokat egyetlen összetett utasításba vagy blokkba csoportosíthatjuk. Az összetett utasítás mindenütt felhasználható, ahol egyetlen utasítás megadását engedélyezi a C++ nyelv leírása. Összetett utasítást, melynek általános formája:
{
lokális definíciók, deklarációk
utasítások
}
a következő három esetben használunk:
amikor több, logikailag összefüggő utasítást egyetlen utasításként kell kezelni (ilyenkor általában csak utasításokat tartalmaz a blokk),
függvények törzseként,
definíciók és deklarációk érvényességének lokalizálására.
Az utasításblokkon belül az utasításokat és a definíciókat/deklarációkat tetszőleges sorrendben megadhatjuk. (Felhívjuk a figyelmet arra, hogy blokkot nem kell pontosvesszővel lezárni.)
Az alábbi példában az egyismeretlenes másodfokú egyenlet megoldását csak akkor végezzük el, ha az egyenlet diszkriminánsa (a gyök alatti mennyiség) nem negatív. A helyes programszerkezet kialakításához a következő részben bemutatásra kerülő if utasítást használjuk:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
double a, b, c;
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
cout << "c = "; cin >> c;
if (b*b-4*a*c>=0) {
double x1, x2;
x1 = (-b + sqrt(b*b-4*a*c))/(2*a);
x2 = (-b - sqrt(b*b-4*a*c))/(2*a);
cout << x1 << endl;
cout << x2 << endl;
}
}
I.4.2. Szelekciós utasítások
A szelekciós utasításokkal (if, switch) feltételtől függően jelölhetjük ki a program további futásának lépéseit. Megvalósíthatunk leágazást, kettéágaztatást vagy többirányú elágaztatást. A szelekciókat egymásba is ágyazhatjuk. A feltételek megfogalmazásakor a már megismert összehasonlító (relációs) és logikai műveleteket használjuk.
I.4.2.1. Az if utasítás
Az if utasítás segítségével valamely tevékenység (utasítás) végrehajtását egy kifejezés (feltétel) értékétől tehetjük függővé. Az if utasítás három formában szerepelhet a programunkban
Leágazás
Az if alábbi formájában az utasítás csak akkor hajtódik végre, ha a feltétel értéke nem nulla (igaz, true). (Felhívjuk a figyelmet arra, hogy a feltételt mindig kerek zárójelek között kell megadni.)
if (feltétel)
utasítás
Blokk-diagram segítségével a különböző vezérlési szerkezetek működése grafikus formában ábrázolható. Az egyszerű if utasítás feldolgozását akövetkező ábrán(I.7. ábra - Az egyszerű if utasítás működése) követhetjük nyomon.
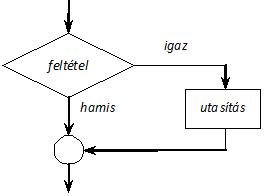
A következő példában csak akkor számítjuk ki a beolvasott szám négyzetgyökét, ha az nem negatív:
#include <iostream>
#include <cmath>
using namespace std;
int main() {
double x = 0;
cout << "x = "; cin >> x;
if (x >= 0) {
cout<<sqrt(x)<<endl;
}
}
Kétirányú elágazás
Az if utasítás teljes formájában arra az esetre is megadhatunk egy tevékenységet (utasítás2), amikor a feltétel kifejezés értéke nulla (hamis, false) (I.8. ábra - Az if-else szerkezet logikai vázlata). (Ha az utasítás1 és az utasítás2 nem összetett utasítások, akkor pontosvesszővel kell őket lezárni.)
if (feltétel)
utasítás1
else
utasítás2
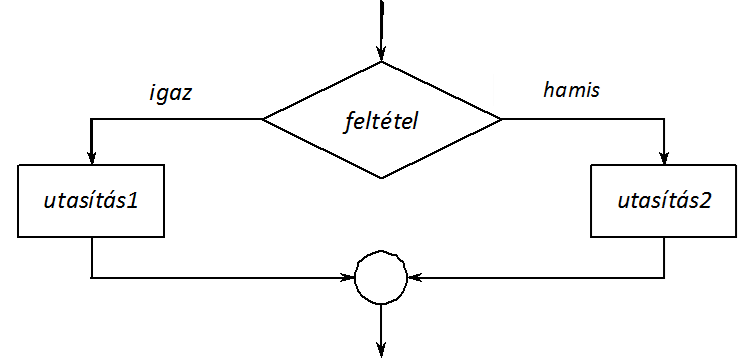
Az alábbi példában a beolvasott egész számról if utasítás segítségével döntjük el, hogy páros vagy páratlan:
#include <iostream>
using namespace std;
int main()
{
int n;
cout<<"Kerek egy egesz szamot: "; cin>>n;
if (n % 2 == 0)
cout<<"A szam paros!"<<endl;
else
cout<<"A szam paratlan!"<<endl;
}
Az if utasítások egymásba is ágyazhatók. Ilyenkor azonban körültekintően kell eljárnunk az else ág(ak) használatával. A fordító mindig a legközelebbi, megelőző if utasításhoz kapcsolja az else ágat.
Az alábbi példában egy megadott egész számról megmondjuk, hogy az pozitív páratlan szám-e, vagy nem pozitív szám. A helyes megoldáshoz kétféleképpen is eljuthatunk. Az egyik lehetőség, ha a belső if utasításhoz egy üres utasítást (;) tartalmazó else-ágat kapcsolunk:
if (n > 0)
if (n % 2 == 1)
cout<<"Pozitiv paratlan szam."<< endl;
else;
else
cout<<"Nem pozitiv szam."<<endl;
A másik járható út, ha a belső if utasítást kapcsos zárójelek közé, azaz utasításblokkba helyezzük:
if (n > 0) {
if (n % 2 == 1)
cout<<"Pozitiv paratlan szam."<< endl;
} else
cout<<"Nem pozitiv szam."<<endl;
A probléma fel sem vetődik, ha eleve utasításblokkokat használunk minkét if esetén, ahogy azt a biztonságos programozás megkívánja:
if (n > 0) {
if (n % 2 == 1) {
cout<<"Pozitiv paratlan szam."<< endl;
}
}
else {
cout<<"Nem pozitiv szam."<<endl;
}
Ebben az esetben bármelyik ág biztonságosan bővíthető újabb utasításokkal.
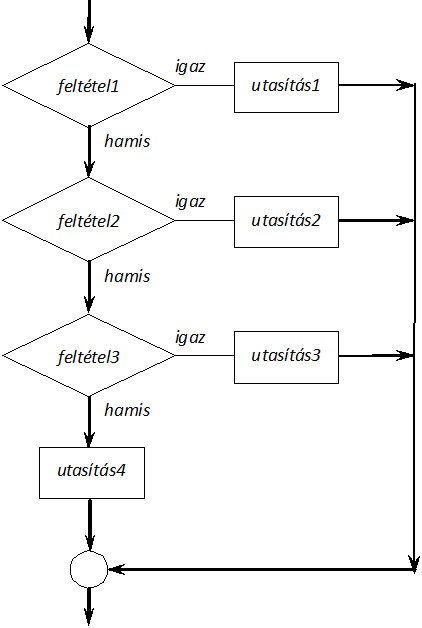
Többirányú elágazás
Az egymásba ágyazott if utasítások gyakori formája, amikor az else-ágakban szerepelnek az újabb if utasítások (I.9. ábra - A többirányú elágazás logikai vázlata).
Ezzel a szerkezettel a programunk többirányú elágaztatását valósíthatjuk meg. Ha bármelyik feltétel igaz, akkor a hozzá kapcsolódó utasítás hajtódik végre. Amennyiben egyik feltétel sem teljesül, a program végrehajtása az utolsó else utasítással folytatódik.
if (feltétel1)
utasítás1
else if (feltétel2)
utasítás2
else if (feltétel3)
utasítás3
else
utasítás4
Az alábbi példában az n számról eldöntjük, hogy az negatív, 0 vagy pozitív:
if (n > 0)
cout<<"Pozitiv szam"<<endl;
else if (n==0)
cout<<"0"<<endl;
else
cout<<"Negativ szam"<<endl;
Az else-if szerkezet speciális esete, amikor feltételek egyenlőség-vizsgálatokat (==) tartalmaznak. A következő példában egyszerű összeget és különbséget számoló kalkulátort valósítunk meg:
#include <iostream>
using namespace std;
int main()
{
char op;
double a, b, c;
cout<<"kifejezes : ";
cin >>a>>op>>b; // beolvasás, pl. 4+10 <Enter>
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else {
cout << "Hibas muveleti jel: " << op <<endl;
return -1;
}
cout <<a<<op<<b<<'='<<c<<endl;
return 0;
}
Az utolsó példában a szerzett pontszámok alapján leosztályozzuk a hallgatókat С++ programozásból:
#include <iostream>
using namespace std;
int main()
{
int pontszam, erdemjegy = 0;
cout << "Pontszam: "; cin >> pontszam;
if (pontszam >= 0 && pontszam <= 100)
{
if (pontszam < 40)
erdemjegy = 1;
else if (pontszam >= 40 && pontszam < 55)
erdemjegy = 2;
else if (pontszam >= 55 && pontszam < 70)
erdemjegy = 3;
else if (pontszam >= 70 && pontszam < 85)
erdemjegy = 4;
else if (pontszam >= 86)
erdemjegy = 5;
cout << "Erdemjegy: " << erdemjegy << endl;
}
else
cout <<"Hibas adat!" << endl;
}
I.4.2.2. A switch utasítás
A switch utasítás valójában egy utasításblokk, amelybe a megadott egész kifejezés értékétől függően különböző helyen léphetünk be. A belépési pontokat az ún. esetcímkék (case konstans kifejezés) jelölik ki.
switch (kifejezés)
{
case konstans_kifejezés1 :
utasítások1
case konstans_kifejezés2 :
utasítások2
case konstans_kifejezés3 :
utasítások3
default :
utasítások4
}
A switch utasítás először kiértékeli a kifejezést, majd átadja a vezérlést arra a case (eset) címkére, amelyben a konstans_kifejezés értéke megegyezik a kiértékelt kifejezés értékével. Ezt követően a belépési ponttól az összes utasítás végrehajtódik, egészen a blokk végéig. Amennyiben egyik case konstans sem egyezik meg a kifejezés értékével, a program futása a default címkével megjelölt utasítástól folytatódik. Ha nem adtuk meg a default címkét, akkor a vezérlés a switch utasítás blokkját záró kapcsos zárójel utáni utasításra kerül.
Ezt a kissé furcsa működést egy rendhagyó példaprogrammal szemléltetjük. Az alábbi switch utasítás képes meghatározni 0 és 5 közé eső egészszámok faktoriálisát. (A rendhagyó jelző esetünkben azt jelenti, hogy nem követendő.)
int n = 4, f(1);
switch (n) {
case 5: f *= 5;
case 4: f *= 4;
case 3: f *= 3;
case 2: f *= 2;
case 1: f *= 1;
case 0: f *= 1;
}
A switch utasítást az esetek többségében - az else-if szerkezethez hasonlóan - többirányú programelágazás megvalósítására használjuk. Ehhez azonban minden esethez tartozó utasítássorozatot valamilyen ugró utasítással (break, goto vagy return) kell lezárnunk. A break a switch blokkot közvetlenül követő utasításra, a goto a függvényen belül címkével megjelölt utasításra adja a vezérlést, míg a return kilép a függvényből.
Mivel célunk áttekinthető szerkezetű, jól működő programok készítése, az ugró utasítások használatát a programban minimálisra kell csökkenteni. Ennek ellenére a break alkalmazása a switch utasításokban teljes mértékben megengedett. Általában a default címke utáni utasításokat is break-kel zárjuk, azon egyszerű oknál fogva, hogy a default eset bárhol elhelyezkedhet a switch utasításon belül.
Az elmondottak alapján minden nehézség nélkül elkészíthetjük az előző alfejezet kalkulátor programját switch alkalmazásával:
#include <iostream>
using namespace std;
int main()
{
char op;
double a, b, c;
cout<<"kifejezes :";
cin >>a>>op>>b;
switch (op) {
case '+':
c = a + b;
break;
case '-':
c = a - b;
break;
default:
cout << "Hibas muveleti jel: " << op <<endl;
return -1;
}
cout <<a<<op<<b<<'='<<c<<endl;
return 0;
}
A következő példában bemutatjuk, hogyan lehet több esethez ugyanazt a programrészletet rendelni. A programban a válaszkaraktert feldolgozó switch utasításban az 'i' és 'I', illetve az 'n' és 'N' esetekhez tartozó case címkéket egymás után helyeztük el.
#include <iostream>
using namespace std;
int main()
{
cout<<"A valasz [I/N]?";
char valasz=cin.get();
switch (valasz) {
case 'i': case 'I':
cout<<"A valasz IGEN."<<endl;
break;
case 'n':
case 'N':
cout<<"A valasz NEM."<<endl;
break;
default:
cout<<"Hibas valasz!"<<endl;
break;
}
}
I.4.3. Iterációs utasítások
A programozási nyelveken utasítások automatikus ismétlését biztosító programszerkezetet iterációnak vagy ciklusnak (loop) nevezzük. A C++ nyelv ciklusutasításai egy ún. ismétlési feltétel függvényében mindaddig ismétlik a megadott utasítást, amíg a feltétel igaz.
while (feltétel) utasítás
for (inicializáló kifejezés opt ; feltétel opt ; léptető kifejezés opt ) utasítás
do utasítás while (feltétel)
A for utasítás esetén az opt index arra utal, hogy a megjelölt kifejezések használata opcionális.
A ciklusokat csoportosíthatjuk a vezérlőfeltétel feldolgozásának helye alapján. Azokat a ciklusokat, amelyeknél az utasítás végrehajtása előtt értékelődik ki vezérlőfeltétel, az elöltesztelő ciklusok. A ciklus utasítása csak akkor hajtódik végre, ha a feltétel igaz. A C++ elöltesztelő ciklusai a while és a for.
Ezzel szemben a do ciklus utasítása legalább egyszer mindig lefut, hisz a vezérlőfeltétel ellenőrzése az utasítás végrehajtása után történik – hátultesztelő ciklus.
Mindhárom esetben a helyesen szervezett ciklus befejezi működését, amikor a vezérlőfeltétel hamissá (0) válik. Vannak azonban olyan esetek is, amikor szándékosan vagy véletlenül olyan ciklust hozunk létre, melynek vezérlőfeltétele soha sem lesz hamis. Ezeket a ciklusokat végtelen ciklusnak nevezzük:
for (;;) utasítás; while (true) utasítás; do utasítás while (true);
A ciklusokból a vezérlőfeltétel hamis értékének bekövetkezte előtt is ki lehet ugrani (a végtelen ciklusból is). Erre a célra további utasításokat biztosít a C++ nyelv, mint a break, a return, illetve a ciklus törzsén kívülre irányuló goto. A ciklus törzsének bizonyos utasításait átugorhatjuk a continue utasítás felhasználásával. A continue hatására a ciklus következő iterációjával folytatódik a program futása.
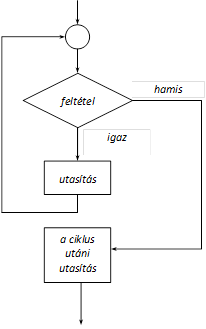
I.4.3.1. A while ciklus
A while ciklus mindaddig ismétli a hozzá tartozó utasítást (a ciklus törzsét), amíg a vizsgált feltétel értéke true (igaz, nem 0). A vizsgálat mindig megelőzi az utasítás végrehajtását. A while ciklus működésének folyamata az elöző ábrán (I.10. ábra - A while ciklus működésének logikai vázlata) követhető nyomon.
while (feltétel)
utasítás
A következő példaprogramban meghatározzuk az első n természetes szám összegét:
#include <iostream>
using namespace std;
int main()
{
int n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
unsigned long sum = 0;
while (n>0) {
sum += n;
n--;
}
cout<<"osszege: "<<sum<<endl;
}
A megoldás while ciklusát tömörebben is felírhatjuk, természetesen a program olvashatóságának rovására:
|
|
|
|
A C++ nyelv megengedi, hogy a változók deklarációját bárhova helyezzük a program kódján belül. Egyetlen feltétel, hogy a változót mindenképpen deklarálnunk (definiálnunk) kell a felhasználása előtt. Bizonyos esetekben a változó-definíciót a ciklusutasítások fejlécébe is bevihetjük, amennyiben a változót azonnal inicializáljuk, például véletlen számmal.
Az alábbi példaprogram while ciklusa az első 10-el osztható véletlen számig fut. A megoldásban az
srand((unsigned)time(NULL));
utasítás a véletlen szám generátorát az aktuális idővel inicializálja, így minden futtatáskor új számsort kapunk. A véletlen számot a rand () függvény szolgáltatja 0 és RAND_MAX (32767) értékhatáron belül.
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main()
{
srand((unsigned)time(NULL));
while (int n = rand()%10)
cout<< n<< endl;
}
Felhívjuk a figyelmet arra, hogy az így definiált n változó csak a while cikluson belül érhető el, vagyis a while ciklusra nézve lokális.
I.4.3.2. A for ciklus
A for utasítást általában akkor használjuk, ha a ciklusmagban megadott utasítást adott számsor mentén kívánjuk végrehajtani (I.11. ábra - A for ciklus működésének logikai vázlata). A for utasítás általános alakjában feltüntettük az egyes kifejezések szerepét:
for (inicilizáció; feltétel; léptetés)
utasítás
A for utasítás valójában a while utasítás speciális alkalmazása, így a fenti for ciklus minden további nélkül átírható while ciklussá:
inicilizáció;
while (feltétel) {
utasítás;
léptetés;
}
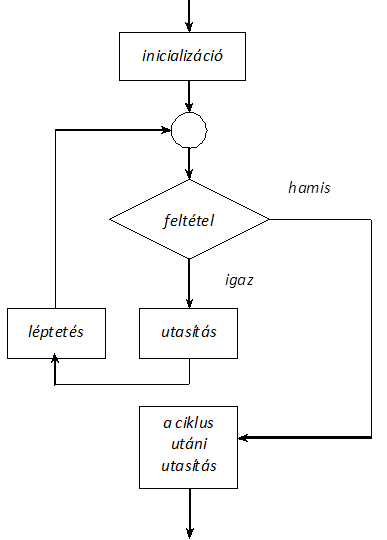
Példaként a for ciklusra, tekintsük a már megoldott, természetes számok összegét meghatározó programot! Azonnal látható, hogy a megoldásnak ez a változata sokkal áttekinthetőbb és egyszerűbb:
#include <iostream>
using namespace std;
int main()
{
unsigned long sum;
int i, n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
for (i=1, sum=0 ; i<=n ; i++)
sum += i;
cout<<"osszege: "<<sum<<endl;
}
A példában szereplő ciklus magjában csak egyetlen kifejezés-utasítás található, ezért a for ciklus az alábbi tömörebb formákban is felírható:
for (i=1, sum=0 ; i<=n ; sum += i, i++) ;
illetve
for (i=1, sum=0 ; i<=n ; sum += i++) ;
A ciklusokat egymásba is ágyazhatjuk, hisz a ciklus utasítása újabb ciklusutasítás is lehet. A következő példában egymásba ágyazott ciklusokat használunk a megadott méretű piramis megjelenítésére. Mindhárom ciklusban lokálissá tettük a ciklusváltozót:
#include <iostream>
using namespace std;
int main ()
{
const int maxn = 12;
for (int i=0; i<maxn; i++) {
for (int j=0; j<maxn-i; j++) {
cout <<" ";
}
for (int j=0; j<i; j++) {
cout <<"* ";
}
cout << endl;
}
}
|
*
* *
* * *
* * * *
* * * * *
* * * * * *
* * * * * * *
* * * * * * * *
* * * * * * * * *
* * * * * * * * * *
* * * * * * * * * * *
|
I.4.3.3. A do-while ciklus
A do-while utasításban a ciklus törzsét képező utasítás végrehajtása után kerül sor a tesztelésre (I.12. ábra - A do-while ciklus működési logikája), így a ciklus törzse legalább egyszer mindig végrehajtódik.
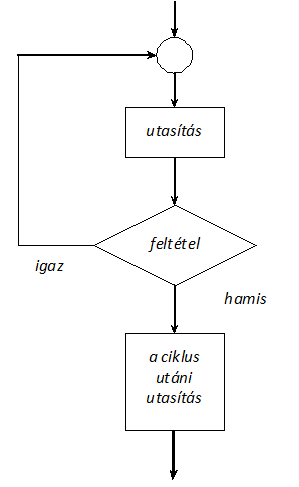
do
utasítás
while (feltétel);
Első példaként készítsük el a természetes számokat összegző program do-while ciklust használó változatát!
#include <iostream>
using namespace std;
int main()
{
int n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
unsigned long sum = 0;
do {
sum += n;
n--;
} while (n>0);
cout<<"osszege: "<<sum<<endl;
}
Az alábbi ciklus segítségével ellenőrzött módon olvasunk be egy egész számot 2 és 100 között:
int m =0;
do {
cout<<"Kerek egy egesz szamot 2 es 100 kozott: ";
cin >> m;
} while (m < 2 || m > 100);
Az utolsó példánkban egész kitevőjű hatványt számolunk:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
double alap;
int kitevo;
cout << "alap: "; cin >> alap;
cout << "kitevo: "; cin >> kitevo;
double hatvany = 1;
if (kitevo != 0)
{
int i = 1;
do
{
hatvany *= alap;
i++;
} while (i <= abs(kitevo));
hatvany = kitevo < 0 ? 1.0 / hatvany : hatvany;
}
cout <<"a hatvany erteke: " << hatvany << endl;
}
Igen gyakori programozási hiba, amikor a ciklusok fejlécét pontosvesszővel zárjuk. Nézzük az 1-től 10-ig a páratlan egész számok kiírására tett kísérleteket!
|
|
|
|
A while esetén az üres utasítást ismétli vég nélkül a ciklus. A for ciklus lefut az üres utasítás ismétlésével, majd pedig kiírja a ciklusváltozó kilépés utáni értékét, a 11-et. A do-while ciklus esetén a fordító hibát jelez, ha a do után pontosvesszőt teszünk, így a közölt kód teljesen jó megoldást takar.
I.4.3.4. A brake utasítás a ciklusokban
Vannak esetek, amikor egy ciklus szokásos működésébe közvetlenül be kell avatkoznunk. Ilyen feladat például, amikor adott feltétel teljesülése esetén ki kell ugrani egy ciklusból. Erre ad egyszerű megoldást a break utasítás, melynek hatására az utasítást tartalmazó legközelebbi while, for és do-while utasítások működése megszakad, és a vezérlés a megszakított ciklus utáni első utasításra kerül.
Az alábbi while ciklus kilép, ha megtalálja a megadott két egész szám legkisebb közös többszörösét:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
int a, b, lkt;
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
lkt = min(a,b);
while (lkt<=a*b) {
if (lkt % a == 0 && lkt % b == 0)
break;
lkt++;
}
cout << "Legkisebb kozos tobbszoros: " << lkt << endl;
}
A break utasítás használata kiküszöbölhető, ha a hozzá kapcsolódó if utasítás feltételét beépítjük a ciklus feltételébe, ami ezáltal sokkal bonyolultabb lesz:
while (lkt<=a*b && !(lkt % a == 0 && lkt % b == 0)) {
lkt++;
}
Ha a break utasítást egymásba ágyazott ciklusok közül a belsőben használjuk, akkor csak a belső ciklusból lépünk ki vele. Az alábbi példában megjelenítjük a prímszámokat 2 és maxn között. A kilépés okát egy logikai (flag, jelző) változó (prim) segítségével adjuk a külső ciklus tudtára:
#include <iostream>
using namespace std;
int main () {
const int maxn =2012;
int oszto;
bool prim;
for(int szam=2; szam<=maxn; szam++) {
prim = true;
for(oszto = 2; oszto <= (szam/oszto); oszto++) {
if (szam % oszto == 0) {
prim = false;
break; // van osztoja, nem prím
}
}
if (prim)
cout << szam << " primszam" << endl;
}
}
Ha feladat úgy hangzik, hogy keressük meg a legelső Pitagoraszi számhármast a megadott intervallumban, akkor találat esetén egyszerre két for ciklusból kell kilépnünk. Ekkor a legegyszerűbb megoldáshoz egy jelző (talalt) bevezetésével jutunk:
#include <iostream>
#include<cmath>
using namespace std;
int main () {
int bal, jobb;
cout <<"bal = "; cin >> bal;
cout <<"jobb = "; cin >> jobb;
bool talalt = false;
for(int a = bal, c, c2; a<=jobb && !talalt; a++) {
for(int b = bal; b<=jobb && !talalt; b++) {
c2 = a*a + b*b;
c = static_cast<int>(sqrt(float(c2)));
if (c*c == c2) {
talalt = true;
cout << a << ", " << b << ", " << c << endl;
} // if
} // for
} // for
} // main()
I.4.3.5. A continue utasítás
A continue utasítás elindítja a while, a for és a do-while ciklusok soron következő iterációját. Ekkor a ciklustörzsben a continue után elhelyezkedő utasítások nem hajtódnak végre.
A while és a do-while utasítások esetén a következő iteráció a ciklus feltételének ismételt kiértékelésével kezdődik. A for ciklus esetében azonban, a feltétel feldolgozását megelőzi a léptetés elvégzése.
A következő példában a continue segítségével értük el, hogy a 1-től maxn-ig egyesével lépkedő ciklusban csak a 7-tel vagy 12-gyel osztható számok jelenjenek meg:
#include <iostream>
using namespace std;
int main(){
const int maxn = 123;
for (int i = 1; i <= maxn; i++) {
if ((i % 7 != 0) && (i % 12 != 0))
continue;
cout<<i<<endl;
}
}
A break és a continue utasítások gyakori használata rossz programozói gyakorlat. Mindig érdemes átgondolnunk, hogy meg lehet-e valósítani az adott programszerkezetet vezérlésátadó utasítások nélkül. Az előző példában ezt könnyedén megtehetjük az if feltételének megfordításával:
for (int i = 1; i <= maxn; i++) {
if ((i % 7 == 0) || (i % 12 == 0))
cout<<i<<endl;
}
I.4.4. A goto utasítás
A fejezet lezárásaként nézzük meg a C++ nyelv vezérlésátadó utasításainak egy, még nem tárgyalt tagját! Már a break és a continue utasításoknál is óva intettünk a gyakori használattól, azonban ez hatványozottan igaz a goto utasításra.
A függvényeken belüli ugrásokra használható goto utasítás rászolgált a rossz hírnevére, ugyanis kuszává, áttekinthetetlenné teszi a forrásprogramot. Nem is beszélve egy ciklusba való beugrás tragikus következményeiről. Ezért kijelenthetjük, hogy strukturált, jól áttekinthető programszerkezet kialakítása során nem szabad goto utasítást használni. A legtöbb programfejlesztő cégnél ez egyenesen tilos.
A goto utasítás felhasználásához utasításcímkével kell megjelölnünk azt az utasítást, ahova később ugrani szeretnénk. Az utasításcímke valójában egy azonosító, amelyet kettősponttal választunk el az utána álló utasítástól:
utasításcímke: utasítás
A goto utasítás, amellyel a fenti címkével megjelölt sorra adhatjuk a vezérlést:
goto utasításcímke;
Bizonyos, jól megindokolt esetekben, például kiugrás egy nagyon bonyolult programszerkezetből, egyszerű megoldást biztosít a goto.
I.5. Kivételkezelés
Kivételnek (exception) nevezzük azt a hibás állapotot vagy eseményt, melynek bekövetkezte esetén az alkalmazás további, szabályszerű futása már nem lehetséges.
C nyelven a program minden kérdéses helyén felkészültünk a hibák helyi kezelésére. Általában ez egy hibaüzenet megjelenítését ( cerr ) jelentette, majd pedig a program futásának megszakítását ( exit ()). Például, ha a másodfokú egyenlet együtthatóinak bekérése után a másodfokú tag együtthatója 0, nem használható a megoldóképlet:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
double a, b, c;
cout<<" egyutthatok (szokozzel tagolva) :";
cin >> a >> b >> c;
if (0 == a) {
cerr << "Az egyenlet nem masodfoku!" << endl;
exit(-1);
}
cout <<a<<"x^2+"<<b<<"x+"<<c<<"=0"<< endl;
}
A C++ nyelv lehetővé teszi, hogy a kivételeket (hibákat) különböző típussal azonosítva, a hibakezelést akár egyetlen helyen végezzük el. A kivételek kezelése a megszakításos (termination) modell alapján történik, ami azt jelenti, hogy a kivételt kiváltó programrész (függvény) futása megszakad a kivétel bekövetkeztekor.
A szabványos C++ nyelv viszonylag kevés beépített kivételt tartalmaz, azonban a különböző osztálykönyvtárak előszeretettel alkalmazzák a kivételeket a hibás állapotok jelzésére. Kivételeket mi is kiválthatunk egy adott típusú érték „dobásával” (throw). A továbbított (dobott) kivételek a legközelebbi kezelőkhöz kerülnek, amelyek vagy “elkapják” (catch) vagy pedig továbbítják azokat.
A fentiekben vázolt működés csak akkor érvényesül, ha a hibagyanús kódrészletünket egy olyan utasításblokkba zárjuk, amely megkísérli (try) azt végrehajtani.
Az elmondottaknak megfelelően a C++ nyelv típusorientált kivételkezeléséhez az alábbi három elem szükséges:
kivételkezelés alatt álló programrész kijelölése (try-blokk),
a kivételek továbbítása (throw),
a kivételek „elfogása” és kezelése (catch).
I.5.1. A try – catch programszerkezet
A try-catch programstruktúra általános formája egyetlen try blokkot és tetszőleges számú catch blokkot tartalmaz:
try
{
// kivételfigyelés alatt álló utasítások
utasítások
}
catch (kivétel1 deklaráció) {
// a kivétel1 kezelője
utasítások1
}
catch (kivétel2 deklaráció) {
// a kivétel2 kezelője
utasítások2
}
catch (...) {
// minden más kivétel kezelője
utasítások3
}
// a sikeres kezelés utáni utasítások
utasítások4
Amennyiben a try (próbálkozás) blokk bármelyik utasítása kivételt okoz, az utasítások végrehajtása megszakad, és a vezérlés a try blokkot követő, megfelelő típusú catch blokkhoz adódik (ha van ilyen). Ha nincs megfelelő típusú kezelő, akkor a kivétel egy külső try blokkhoz tartozó kezelőhöz továbbítódik. A típusegyezés nélküli kivételek végső soron a futtató rendszerhez kerülnek (kezeletlen kivételként). Ezt a helyzetet egy angol nyelvű, szöveges üzenetet jelzi: „This application has requested the Runtime to terminate it in an unusual way. Please contact the application's support team for more information.”, ami arról tudósít, hogy a programunk nem a szokásos módon fejeződött be, és keressük fel az alkalmazás fejlesztőcsapatát további információért.
A catch kulcsszó után álló kivétel deklarációkat többféleképpen is megadhatjuk. Szerepelhet egy típus , egy változó deklaráció (típus azonosító) vagy három pont . Az eldobott kivételhez csak a 2. forma használatával férhetünk hozzá. A három pont az jelenti, hogy tetszőleges típusú kivételt fogadunk. Mivel a kivételek azonosítása a catch blokkok megadási sorrendjében történik, a három pontos alakot a lista végén adjuk meg.
Példaként alakítsuk át a bevezetőben szereplő program hibavizsgálatát kivételkezeléssé!
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
try {
double a, b, c;
cout<<" egyutthatok (szokozzel tagolva) :";
cin >> a >> b >> c;
if (0 == a) throw false;
cout <<a<<"x^2+"<<b<<"x+"<<c<<"=0"<< endl;
}
catch (bool) {
cerr << "Az egyenlet nem masodfoku!" << endl;
exit(-1);
}
catch (...) {
cerr << "Valami hiba tortent..." << endl;
exit(-1);
}
}
I.5.2. Kivételek kiváltása – a throw utasítás
A kivételkezelést a programunk adott részén belül, lokálisan kell kialakítanunk a try, a throw és a catch kulcsszavak felhasználásával. A kivételkezelés csak a próbálkozás blokkban megadott (illetve az abból hívott) kód végrehajtása esetén fejti ki hatását. A kijelölt kódrészleten belül a throw utasítással
throw kifejezés;
adhatjuk át a vezérlést a kifejezés típusának megfelelő kezelőnek (handler), amelyet a catch kulcsszót követően adunk meg.
Amikor egy kivételt a throw utasítással továbbítunk, akkor az utasításban megadott kifejezés értéke átmásolódik a catch fejlécében szereplő paraméterébe, így a kezelőben lehetőség nyílik ezen érték feldolgozására. Ehhez persze arra van szüksége, hogy a típus mellett egy azonosító is szerepeljen a catch utasításban.
A catch blokkban elhelyezett throw utasítással a kapott kivételt más kivétellé alakítva továbbíthatjuk, illetve a megkapott kivételt is továbbadhatjuk. Ez utóbbihoz a throw kifejezés nélküli alakját kell használnunk: throw;
Programjaink kivételkezelését igazából kivételosztályok definiálásával tehetjük teljessé. Az exception fejállomány tartalmazza az exception osztály leírását, amely a különböző logikai és futásidejű kivételek alaposztálya. Az osztályok what () függvénye megadja a kivétel szöveges leírását. Az alábbi táblázatban összefoglaltuk a C++ szabványos könyvtáraiban definiált osztályok által továbbított kivételeket. Minden kivétel alapját az exception osztály képezi.
|
Kivételosztályok |
Fejállomány | ||
|---|---|---|---|
|
exception |
<exception> | ||
|
bad_alloc |
<new> | ||
|
bad_cast |
<typeinfo> | ||
|
bad_typeid |
<typeinfo> | ||
|
logic_failure |
<stdexcept> | ||
|
domain_error |
<stdexcept> | ||
|
invalid_argument |
<stdexcept> | ||
|
length_error |
<stdexcept> | ||
|
out_of_range |
<stdexcept> | ||
|
runtime_error |
<stdexcept> | ||
|
range_error |
<stdexcept> | ||
|
overflow_error |
<stdexcept> | ||
|
underflow_error |
<stdexcept> | ||
|
ios_base::failure |
<ios> | ||
|
bad_exception |
<exception> | ||
Kivételosztályok segítségével egyszerű értékek helyett „okos” objektumokat továbbíthatunk kivételként. A szükséges ismereteket csak könyvünk III. fejezet - Objektum-orientált programozás C++ nyelven fejezetében tárjuk az Olvasó elé.
Kényelmes hibakezelést biztosít, amikor csak szöveget továbbítunk kivételként. Így a program felhasználója mindig értelmes üzenetet kap a munkája során. (A sztringkonstansokat a következő fejezet const char * típusával azonosítjuk.)
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
int szam;
srand(unsigned(time(NULL)));
try {
while (true) {
szam = rand();
if (szam>1000)
throw "A szam tul nagy";
else if (szam<10)
throw "A szam tul kicsi";
cout << 10*szam << endl;
} // while
} // try
catch (const char * s) {
cerr << s << endl;
} // catch
} // main()
I.5.3. Kivételek szűrése
A C++ függvények is fontos szerepet játszanak a kivételkezelésben. Egy függvényben keletkező kivételeket általában a függvényen belül dolgozzuk fel, hisz ott van meg a feldolgozáshoz szükséges ismeret. Vannak azonban olyan kivételek is, amelyek a függvény sikertelen működését jelzik a függvény hívójának. Ezeket természetesen továbbítjuk a függvényen kívülre.
A függvény-definíció fejlécében a throw kulcsszó speciális alakjával megadhatjuk, hogy milyen típusú kivételek továbbítódjanak a függvényen kívüli kezelőhöz. Alaphelyzetben minden kivétel továbbítódik.
// minden kivétel továbbítódik int fv1(); // csak a bool típusú kivételek továbbítódnak int fv2() throw(char, bool); // a char és a bool típusú kivételek továbbítódnak int fv3() throw(bool); // egyetlen kivétel sem továbbítódik int fv4() throw();
Amikor egy olyan kivételt továbbítunk, amelynek nincs kezelője a programban, a futtató rendszer a terminate () függvényt aktivizálja, amely kilépteti a programunkat ( abort ()). Ha egy olyan kivételt továbbítunk, amelyik nincs benne az adott függvény által továbbítandó kivételek listájában, akkor az unexpected () rendszerhívás állítja le a programunkat. Mindkét kilépési folyamatba beavatkozhatunk saját kezelők definiálásával, melyek regisztrációját az except fejállományban deklarált set_termi nate (), illetve set_unexpected () függvényekkel végezhetjük el.
I.5.4. Egymásba ágyazott kivételek
Valamely próbálkozás blokkban egy másik try-catch kivételkezelő szerkezet is elhelyezhető, akár közvetlenül, akár közvetve, a próbálkozás blokkból hívott függvényben.
Példaként egy szöveges kivételt továbbítunk a belső próbálkozás blokkból. Ezt feldogozzuk a belső szerkezetben, majd továbbadjuk a kifejezés nélküli throw; felhasználásával. A külső szerkezetben véglegesen kezeljük azt.
#include <iostream>
using namespace std;
int main()
{
try {
try {
throw "kivetel";
}
catch (bool) {
cerr << "bool hiba" << endl;
}
catch(const char * s) {
cout << "belso " << s << endl;
throw;
}
}
catch(const char * s) {
cout << "kulso " << s << endl;
}
catch(...) {
cout << "ismeretlen kivetel" << endl;
}
}
A fejezet zárásaként tanulmányozzuk az alábbi számológép programot! A saját kivételeket felsorolásként hoztuk létre. A programból az x operátor megadásával léphetünk ki.
#include <iostream>
using namespace std;
enum nulloszt {NullavalOsztas};
enum hibasmuv {HibasMuvelet};
int main()
{
double a, b, e=0;
char op;
while (true) // kilepes, ha op x vagy X
{
cout << ':';
cin >>a>>op>>b;
try {
switch (op) {
case '+': e = a + b;
break;
case '-': e = a - b;
break;
case '*': e = a * b;
break;
case '/': if (b==0)
throw NullavalOsztas;
else
e = a / b;
break;
case 'x': case 'X' :
throw true;
default: throw HibasMuvelet;
}
cout << e <<endl;
} // try
catch (nulloszt) {
cout <<" Nullaval osztas" <<endl;
}
catch (hibasmuv) {
cout <<" Hibas muvelet" <<endl;
}
catch (bool) {
cout<<"Off"<<endl;
break; // while
}
catch(...) {
cout<<" Valami nem jo "<< endl;
}
} // while
}
I.6. Mutatók, hivatkozások és a dinamikus memóriakezelés
Minden program legértékesebb erőforrása a számítógép memóriája, hisz a program kódja mellett a közvetlenül elérhető (on-line) adataink is itt tárolódnak. Az eddigi példáinkban a memóriakezelést teljes mértékben a fordítóra bíztuk.
|
A fordító – a tárolási osztály alapján – a globális (extern) adatokat egybegyűjtve helyezi el egy olyan területen, amely a program futása során végig rendelkezésre áll. A lokális (auto) adatok a függvényekbe lépve jönnek létre a verem (stack) memóriablokkban, illetve törlődnek kilépéskor (I.13. ábra - C++ program memóriahasználat). Van azonban egy terület, az ún. halomterület (heap), ahol mi magunk helyezhetünk el változókat, illetve törölhetjük azokat, ha már nincs szükség rájuk. Ezek a - dinamikus módon - kezelt változók eltérnek az eddig használt változóktól, hisz nincs nevük. Rájuk a címüket tároló változókkal, a mutatókkal (pointerekkel) hivatkozhatunk. A C++ nyelv operátorok sorával is segíti a dinamikus memóriakezelést *, &, new, delete. |
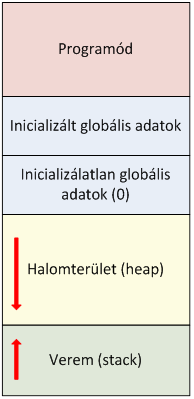 I.13. ábra - C++ program memóriahasználat
|
Az elmondottakon túlmenően nagyon sok területeken használunk mutatókat a C/C++ programokban: függvények paraméterezése, láncolt adatstruktúrák kezelése stb. A pointerek kizárólagos alkalmazását a C++ egy sokkal biztonságosabb típussal, a hivatkozással (referenciával) igyekszik ellensúlyozni.
I.6.1. Mutatók (pointerek)
Minden változó definiálásakor a fordító lefoglalja a változó típusának megfelelő méretű területet a memóriában, és hozzárendeli a definícióban szereplő nevet. Az esetek többségében a változónevet használva adunk értéket a változónak, illetve kiolvassuk a tartalmát. Van amikor ez a megközelítés nem elegendő, és közvetlenül a változó memóriabeli címét kell használnunk (például a scanf () könyvtári függvény hívása).
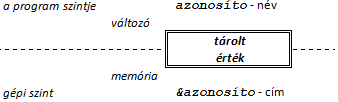
A mutatók segítségével tárolhatjuk, illetve kezelhetjük a változók (memóriában tárolt adatok) és függvények címét. Egy mutató azonban nemcsak címet tárol, hanem azt az információt is hordozza, hogy az adott címtől kezdve hány bájtot, hogyan kell értelmezni. Ez utóbbi pedig nem más, mint a hivatkozott adat típusa, amit felhasználunk a pointer(változó) definíciójában.
I.6.1.1. Egyszeres indirektségű mutatók
Először ismerkedjünk meg a mutatók leggyakrabban használt, és egyben legegyszerűbb formájával, az egyszeres indirektségű pointerekkel, melyek általános definíciója:
típus *azonosító;
A csillag jelzi, hogy mutatót definiálunk, míg a csillag előtti típus a hivatkozott adat típusát jelöli. A mutató automatikus kezdőértékére a szokásos szabályok érvényesek: 0, ha a függvényeken kívül hozzuk létre, és definiálatlan, ha valamely függvényen belül. Biztonságos megoldás, ha a mutatót a létrehozása után mindig inicializáljuk - a legtöbb fejállományban megtalálható - NULL értékkel:
típus *azonosító = NULL;
Több, azonos típusú mutató létrehozásakor a csillagot minden egyes azonosító előtt meg kell adni:
típus *azonosító1, *azonosító2;
A mutatókkal egy sor művelet elvégezhető, azonban létezik három olyan operátor, melyeket kizárólag pointerekkel használunk:
|
*ptr |
A ptr által mutatott objektum elérése. |
|
ptr->tag |
A ptr által mutatott struktúra adott tagjának elérése (I.8. szakasz - Felhasználói típusok fejezet). |
|
&balérték |
A balérték címének lekérdezése. |
Érthetőbbé válik a bevezetőben vázolt két szint, ha példa segítségével szemléltetjük az elmondottakat. Hozzunk létre egy egész típusú változót!
int x = 2;
A változó definiálásakor a memóriában (például az 2004-es címen) létrejön egy (int típusú) terület, amelybe bemásolódik a kezdőérték:

Az
int *p;
definíció hatására szintén keletkezik egy változó (például az 2008-as címen), melynek típusa int*. A C++ nyelv szóhasználatával élve a p egy int* típusú változó, vagy a p egy int típusú mutató. Ez a mutató int típusú változók címének tárolására használható, melyet például a „címe” & művelet során szerezhetünk meg, például:
p = &x;
A művelet után az x név és a *p érték ugyanarra a memóriaterületre hivatkoznak. (A *p kifejezés a „p által mutatott” tárolót jelöli.)
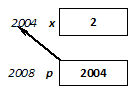
Ennek következtében a
*p = x +10;
kifejezés feldolgozása során az x változó értéke 12-re módosul.
Alternatív mutatótípus is létrehozható a typedef kulcsszó felhasználásával:
int x = 2; typedef int *tpi; tpi p = &x;
Egyetlen változóra több mutatóval is hivatkozhatunk, és a változó értékét bármelyik felhasználásával módosíthatjuk:
int x = 2; int * p, *pp; p = &x; pp = p; *pp += 10; // x tartalma ismét 12 lesz
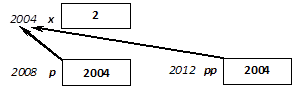
Ha egy mutatót eltérő típusú változó címével inicializálunk, fordítási hibát kapunk
long y = 0; char *p = &y; // hiba! ↯
Amennyiben nem tévedésről van szó, és valóban bájtonként szeretnénk elérni a long típusú adatot, a fordítót típus-átalakítással kérhetjük az értékadás elvégzésére:
long y = 0; char *p = (char *)&y;
vagy
char *p = reinterpret_cast<char *>(&y);
Gyakori, súlyos programhiba, ha egy mutatót inicializálás nélkül kezdünk el használni. Ez általában a program futásának megszakadását eredményezi:
int *p; *p = 1002; // ↯ ↯ ↯
I.6.1.2. Mutató-aritmetika
Mutató operandusokkal a már bemutatott (* és &) operátorokon túlmenően további műveleti jeleket is használhatunk. Ezeket a műveleteket összefoglaló néven pointer-aritmetikának nevezzük. Minden más művelet elvégzése definiálatlan eredményre vezet, így azokat javasolt elkerülni.
A megengedett pointer-aritmetikai műveleteket táblázatban foglaltuk össze, ahol a q és a p (nem void* típusú) mutatók, az n pedig egész (int vagy long):
|
Művelet |
Kifejezés |
Eredmény |
|---|---|---|
|
két, azonos típusú mutató kivonható egymásból |
q - p |
egész |
|
a mutatóhoz egész szám hozzáadható |
p + n, p++,++p, p += n, |
mutató |
|
a mutatóból egész szám kivonható |
p – n, p--, --p, p -= n |
mutató |
|
két mutató összehasonlítható |
p == q, p > q stb. |
bool (false vagy true) |
Amikor hozzáadunk vagy kivonunk egy egészet egy pointerhez/ből, akkor a fordító automatikusan skálázza az egészet a mutató típusának megfelelően, így a tárolt cím nem n bájttal, hanem
n * sizeof(pointertípus)
bájttal módosul, vagyis a mutató n elemnyit „lép” a memóriában.
Ennek megfelelően a léptető operátorok az aritmetikai típusokon kívül a mutatókra is alkalmazhatók, ahol azonban nem 1 bájttal való elmozdulást, hanem a szomszédos elemre való léptetést jelentik.
A pointer léptetése a szomszédos elemre többféle módon is elvégezhető:
int *p, *q; p = p + 1; p += 1; p++; ++p;
Az előző elemre való visszalépésre szintén több lehetőség közül választhatunk:
p = p - 1; p -= 1; p--; --p;
A két mutató különbségénél szintén érvényesül a skálázás, így a két mutató között elhelyezkedő elemek számát kapjuk eredményül:
int h = p - q;
I.6.1.3. A void * típusú általános mutatók
A C++ nyelv típus nélküli (void típusú), általános mutatók használatát is lehetővé teszi,
int x; void * ptr = &x;
amelyek csak címet tárolnak, így sohasem jelölnek ki változót.
A C++ nyelv a mutatókkal kapcsolatban két implicit konverziót biztosít. Tetszőleges típusú mutató átalakítható általános (void) típusú mutatóvá, valamint a nulla (0) számértékkel minden mutató inicializálható. Ellenkező irányú konverzióhoz explicit típusátalakítást kell használnunk.
Ezért, ha értéket szeretnénk adni a ptr által megcímzett változónak, akkor felhasználói típuskonverzióval típust kell rendelnünk a cím mellé. A típus-átalakítást többféleképpen is elvégezhetjük:
int x; void *ptr = &x; *(int *)ptr = 1002; typedef int * iptr; *iptr(ptr) = 1002; *static_cast<int *>(ptr) = 1002; *reinterpret_cast<int *>(ptr) = 1002;
Mindegyik indirekt módon elvégzett értékadást követően, az x változó értéke 1002 lesz.
Megjegyezzük, hogy a mutatót visszaadó könyvtári függvények többsége void* típusú.
I.6.1.4. Többszörös indirektségű mutatók
A mutatókat többszörös indirektségű kapcsolatok esetén is használhatjuk. Ekkor a mutatók definíciójában több csillag (*) szerepel:
típus * *mutató;
A mutató előtt közvetlenül álló csillag azt jelöli, hogy pointert definiálunk, és ami ettől a csillagtól balra található, az a mutató típusa (típus *). Ehhez hasonlóan tetszőleges számú csillagot értelmezhetünk, azonban megnyugtatásul megjegyezzük, hogy a C++ nyelv szabványos könyvtárának elemei is legfeljebb kétszeres indirektségű mutatókat használnak.
Tekintsünk néhány definíciót, és mondjuk meg, hogy mi a létrehozott változó!
|
int x; |
x egy int típusú változó, |
|
int *p; |
p egy int típusú mutató (amely int változóra mutathat), |
|
int * *q; |
q egy int* típusú mutató (amely int* változóra, vagyis egészre mutató pointerre mutathat). |
Alternatív (typedef) típusnevekkel a fenti definíciók érthetőbb formában is felírhatók:
typedef int *iptr; // iptr - egészre mutató pointer típusa iptr p, *q;
vagy
typedef int *iptr; // iptr - egészre mutató pointer típusa // iptr típusú változóra mutató pointer típusa typedef iptr *ipptr; iptr p; ipptr q;
|
A fenti definíciók megadása után az x = 2; p = &x; q = &p; x = x + *p + **q; utasítások végrehajtását követően az x változó értéke 6 lesz. |
|
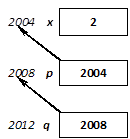
Megjegyezzük, hogy bonyolultabb pointeres kapcsolatok értelmezésében hasznos segítséget jelent a grafikus ábrázolás.
I.6.1.5. Konstans mutatók
A C++ fordító szigorúan ellenőrzi a const típusú konstansok felhasználását, például egy konstansra csak megfelelő mutatóval hivatkozhatunk:
const double pi = 3.141592565; // double adatra mutató pointer double *ppi = π // hiba! ↯
Konstansra mutató pointer segítségével az értékadás már elvégezhető:
// double konstansra mutató pointer const double *pdc; const double dc = 10.2; double d = 2012; pdc = &dc; // a pdc pointer a dc-re mutat
cout <<*pdc<<endl; // 10.2
pdc = &d; // a pdc pointert a d-re állítjuk
cout <<*pdc<<endl; // 2012
A pdc pointer felhasználásával a d változó értéke nem módosítható:
*pdc = 7.29; // hiba! ↯
Konstans értékű pointer, vagyis a mutató értéke nem változtatható meg:
int honap; // int típusú adatra mutató konstans pointer int *const akthonap = &honap; //
Az akthonap pointer értéke nem változtatható meg, de a *akthonap módosítható!
*akthonap = 9; cout<< honap << endl; // 9 akthonap = &honap; // hiba! ↯
Konstansra mutató konstans értékű pointer:
const int honap = 10; const int ahonap = 8; // int típusú konstansra mutató konstans pointer const int *const akthonap = &honap; cout << *akthonap << endl; // 10
Sem a mutató, sem pedig a hivatkozott adat nem változtatható meg!
akthonap = &ahonap; // hiba! ↯ *akthonap = 12 // hiba! ↯
I.6.2. Hivatkozások (referenciák)
A hivatkozási (referencia) típus felhasználásával már létező változókra hivatkozhatunk, alternatív nevet definiálva. A definíció általános formája:
típus &azonosító = változó;
Az & jelzi, hogy referenciát definiálunk, míg az & előtti típus a hivatkozott adat típusát jelöli, melynek egyeznie kell a kezdőértékként megadott változó típusával. Több azonos típusú hivatkozás készítésekor az & jelet minden referencia előtt meg kell adnunk:
típus &azonosító1 = változó1, &azonosító2 = változó2 ;
A referencia definiálásakor a balértékkel történő inicializálás kötelező. Példaként készítsünk hivatkozást az int típusú x változóra!
int x = 2; int &r = x;
Ellentétben a mutatókkal, a referencia tárolására általában nem jön létre külön változó. A fordító egyszerűen második névként egy új nevet ad az x változónak (r).

Ennek következtében az alábbi kifejezés kiértékelése után 12 lesz az x változó értéke:
r = x +10;
Míg a mutatók értéke, ezáltal a hivatkozott tároló bármikor megváltoztatható, az r referencia a változóhoz kötött.
int x = 2, y = 4; int &r = x; r = y; // normál értékadás cout << x << endl; // 4
Ha egy referenciát konstans értékkel, vagy eltérő típusú változóval inicializálunk fordítási hibát kapunk. Még az sem segít, ha a második esetben típus-átalakítást használunk. Az ilyen eseteket csak akkor kezeli a fordító, ha ún. konstans (csak olvasható) referenciát készítünk. Ekkor a fordító először létrehozza a hivatkozás típusával megegyező típusú tárolót, majd pedig inicializálja az egyenlőségjel után szereplő jobbérték kifejezés értékével.
const char &lf = '\n'; |
unsigned int b = 2004; const int &r = b; b = 2012; cout << r << endl; // 2004 |
Szinonim referenciatípus szintén létrehozható a typedef kulcsszó segítségével:
typedef int &rint; int x = 2; rint r = x;
Mutatóhoz referenciát más típusú változókhoz hasonlóan készíthetünk:
int n = 10; int *p = &n; // p mutató az n változóra int* &rp = p; // rp referencia a p mutatóra *rp = 4; cout << n << endl; // 4
Ugyanez a typedef segítségével:
typedef int *tpi; // egészre mutató pointer típusa typedef tpi &rtpi; // referencia egészre mutató pointerre int n = 10; tpi p = &n; rtpi rp = p;
Felhívjuk a figyelmet arra, hogy referenciához referenciát, illetve mutatót nem definiálhatunk.
int n = 10; int &r = n; int& *pr = &r; // hiba! ↯ int& &rr =r; // hiba! ↯ int *p = &r; // a p mutató az r referencián keresztül az n-re mutat
Referenciát bitmezőkhöz (I.8. szakasz - Felhasználói típusok) sem készíthetünk, sőt referencia elemeket tartalmazó tömböt (I.7. szakasz - Tömbök és sztringek) sem hozhatunk létre.
A referencia típus igazi jelentőségét függvények készítésekor fogjuk megtapasztalni.
I.6.3. Dinamikus memóriakezelés
Általában nem azért használunk mutatókat, hogy más változókra mutassunk velük, bár ez sem elvetendő (lásd paraméterátadás). A mutatók a kulcs a C++ nyelv egyik fontos lehetőségéhez, az ún. dinamikus memóriakezeléshez. Ennek segítségével a program futásához szükséges tárolóterületeket mi foglaljuk le, amikor szükségesek, és mi szabadítjuk fel, amikor már nem kellenek.
A szabad memória (heap) dinamikus kezelése alapvető részét képezi minden programnak. A C nyelv könyvtári függvényeket biztosít a szükséges memóriafoglalási ( malloc (),...) illetve felszabadítási ( free ()) műveletekhez. A C++ nyelvben a new és delete operátorok nyelvdefiníció szintjén helyettesítik a fenti könyvtári függvényeket (bár szükség esetén azok is elérhetők).
A dinamikus memóriakezelés az alábbi három lépést foglalja magában:
egy szabad memóriablokk foglalása, a foglalás sikerességének ellenőrzésével,
a terület elérése mutató segítségével,
a lefoglalt memória felszabadítása.
I.6.3.1. Szabad memória foglalása és elérése
A dinamikus memóriakezelés első lépése egy szükséges méretű tárterület lefoglalása a szabad memóriából (heap). Erre a célra a new operátor áll rendelkezésünkre. A new operátor az operandusában megadott típusnak megfelelő méretű területet foglal a szabad memóriában, és a terület elejére mutató pointert ad eredményül. Szükség esetén kezdőértéket is megadhatunk a típust követő zárójelben.
mutató = new típus;
mutató = new típus(kezdőérték);
A new segítségével nemcsak egyetlen elemnek, hanem több egymás után elhelyezkedő elemnek is helyet foglalhatunk a memóriában. Ez így létrejövő adatstruktúrát dinamikus tömbnek nevezzük (I.7. szakasz - Tömbök és sztringek).
mutató = new típus[elemszám];
Nézzünk néhány példát a new műveletre!
int main() {
int *p1;
double *p2;
p1 = new int(2);
p2 = new double;
}
Az definíció hatására a veremben létrejönnek a p1 és p2 mutatóváltozók. Az értékadásokat követően a halomterületen megszületik két dinamikus változó, melyek címe megjelenik a megfelelő mutatókban (I.14. ábra - Dinamikus memóriafoglalás).
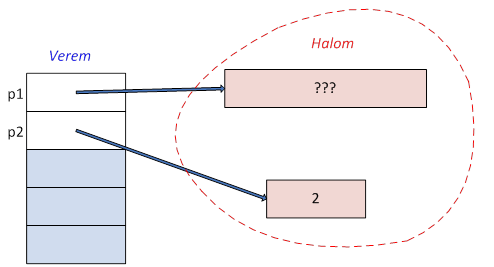
A memóriafoglalásnál, főleg amikor nagyméretű dinamikus tömb számára kívánunk tárterületet foglalni, előfordulhat, hogy nem áll rendelkezésünkre elegendő, összefüggő, szabad memória. A C++ futtatórendszer ezt a helyzetet a bad_alloc kivétel (exception fejállomány) létrehozásával jelzi. Így a kivételkezelés eszköztárát használva programunkat biztonságossá tehetjük.
#include <iostream>
#include <exception>
using namespace std;
int main() {
long * padat;
// Memóriafoglalás
try {
padat = new long;
}
catch (bad_alloc) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria!" << endl;
return -1; // Kilépünk a programból
}
// ...
// A lefoglalt memória felszabadítása
delete padat;
return 0;
}
Amennyiben nem kívánunk élni a kivételkezelés adta lehetőségekkel, a new operátor után meg kell adnunk a nothrow memóriafoglalót (new fejállomány). Ennek hatására a new operátor sikertelen tárfoglalás esetén a kivétel helyett 0 értékkel tér vissza.
#include <iostream>
#include <new>
using namespace std;
int main() {
long * padat;
// Memóriafoglalás
padat = new (nothrow)long;
if (0 == padat) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria!" << endl;
return -1; // Kilépünk a programból
}
// ...
// A lefoglalt memória felszabadítása
delete padat;
return 0;
}
Az alfejezet végén felhívjuk a figyelmet a new operátor egy további lehetőségére. A new után közvetlenül zárójelben megadott mutató is állhat, melynek hatására az operátor a mutató címével tér vissza (vagyis nem foglal memóriát):
int *p=new int(10); int *q=new(p) int(2); cout <<*p << endl; // 2
A fenti példákban a q pointer a p által mutatott területre hivatkozik. A mutatók eltérő típusúak is lehetnek:
long a = 0x20042012; short *p = new(&a) short; cout << hex <<*p << endl; // 2012
I.6.3.2. A lefoglalt memória felszabadítása
A new operátorral lefoglalt memóriablokkot a delete operátorral szabadíthatjuk fel:
delete mutató;
delete[] mutató;
A művelet első formáját egyetlen dinamikus változó felszabadítására, míg a második alakot dinamikus tömbök esetén használjuk.
A delete művelet 0 értékű mutatók esetén is helyesen működik. Minden más, nem new-val előállított érték esetén a delete működése megjósolhatatlan.
A tárterület felszabadításával az előző rész bevezető példája teljessé tehető:
int main() {
int *p1;
double *p2;
p1 = new int(2);
p2 = new double;
delete p1;
delete p2;
p1 = 0;
p2 = 0;
}
I.7. Tömbök és sztringek
Az eddigi példáink változói egyszerre csak egy érték (skalár) tárolására voltak alkalmasak. A programozás során azonban gyakran van arra szükség, hogy több, azonos vagy különböző típusú elemekből álló adathalmazt a memóriában tároljunk, és azon műveleteket végezzünk. C++ nyelven a származtatott típusok közé tartozó tömb és felhasználói típusok (struct, class, union – I.8. szakasz - Felhasználói típusok) segítségével hatékonyan megoldhatjuk ezeket a feladatokat.
I.7.1. A C++ nyelv tömbtípusai
A tömb (array) azonos típusú adatok (elemek) halmaza, amelyek a memóriában folytonosan helyezkednek el. Az elemek elérése a tömb nevét követő indexelés operátor(ok)ban ( [] ) megadott elemsorszám(ok) (index(ek)) segítségével történik, mely(ek) kezdőértéke mindig 0.
A leggyakrabban használt tömbtípus egyetlen kiterjedéssel (dimenzióval) rendelkezik – egydimenziós tömb (vektor) Amennyiben az adatainkat több egész számmal kívánjuk azonosítani, a tárolásra többdimenziós tömböket vehetünk igénybe. Ezek közül könyvünkben csak a második leggyakoribb, kétdimenziós tömbtípussal (mátrix) foglalkozunk részletesen, mely elemeinek tárolása soronként (sorfolytonosan) történik.
Mielőtt rátérnék a kétféle tömbtípus tárgyalására, nézzük általánosan a tömbtípus használatát! Az n-dimenziós tömb definíciója:
elemtípus tömbnév[méret 1 ][méret 2 ][méret 3 ]…[méret n-1 ][méret n ]
ahol a méret i az i-dik kiterjedés méretét határozza meg. Az elemekre való hivatkozáshoz minden dimenzióban meg kell adni egy sorszámot a 0, méret i -1 zárt intervallumon:
tömbnév[index 1 ][index 2 ][index 3 ]…[index n-1 ][index n ]
Így, első látásra igen ijesztőnek tűnhet a tömbtípus, azonban egyszerűbb esetekben igen hasznos és kényelmes adattárolása megoldás jelent.
I.7.1.1. Egydimenziós tömbök
Az egydimenziós tömbök definíciójának formája:
elemtípus tömbnév[méret];
A tömbelemek típusát meghatározó elemtípus a void és a függvénytípusok kivételével tetszőleges típus lehet. A szögletes zárójelek között megadott méretnek a fordító által kiszámítható konstans kifejezésnek kell lennie. A méret a tömbben tárolható elemek számát definiálja. Az elemeket 0-tól (méret-1)-ig indexeljük.

Példaként tekintsünk egy 7-elemű egész tömböt, melynek egész típusú elemeit az indexek négyzetével töltjük fel (I.15. ábra - Egydimenziós tömb grafikus ábrázolása)! Helyes gyakorlat a tömbméret konstansban való tárolása. Az elmondattak alapján a negyzet tömb definíciója:
const int maxn =7; int negyzet[maxn];
A tömb elemeinek egymás után történő elérésére általában a for ciklust használjuk, melynek változója a tömb indexe. (A ciklus helyes felírásában az index 0-tól kisebb, mint a méret fut). A tömb elemeire az indexelés operátorával ([]) hivatkozunk.
for (int i = 0; i< maxn; i++)
negyzet[i] = i * i;
A negyzet tömb számára lefoglalt memóriaterület bájtban kifejezett mérete a sizeof (negyzet) kifejezéssel pontosan lekérdezhető, míg a sizeof (negyzet[0]) kifejezés egyetlen elem méretét adja meg. Így a két kifejezés hányadosából (egész osztás) mindig megtudható a tömb elemeinek száma:
int elemszam = sizeof(negyzet) / sizeof(negyzet[0]);
Felhívjuk a figyelmet arra, hogy a C++ nyelv semmilyen ellenőrzést nem végez a tömb indexeire vonatkozóan. Az indexhatár átlépése a legkülönbözőbb futás közbeni hibákhoz vezethet, melyek felderítése sok időt vehet igénybe.
double oktober [31]; oktober [-1] = 0; // hiba ↯ oktober [31] = 0; // hiba ↯
Az alábbi példában egy 5-elemű vektorba beolvasott float számokat átlagoljuk, majd kiírjuk az átlagot és az egyes elemek eltérését ettől az átlagtól.
#include <iostream>
using namespace std;
const int maxn = 5 ;
int main()
{
float szamok[maxn], atlag = 0.0;
for (int i = 0; i <maxn; i++)
{
cout<<"szamok["<< i <<"] = ";
cin>>szamok[i]; // az elemek beolvasása
atlag += szamok[i]; // az elemek összegzése
}
cin.get();
atlag /= maxn; // az átlag kiszámítása
cout<< endl << "Az atlag: " << atlag << endl;
// az eltérések kiírása
for (int i = 0; i <maxn; i++) {
cout<< i << ".\t" << szamok[i];
cout<< '\t' << atlag-szamok[i] << endl;
}
}
A program futási eredményének tanulmányozásakor felhívjuk a figyelmet az adatbevitel megvalósítására. A tömböket csak elemenként olvashatjuk be, és elemenként jeleníthetjük meg.
szamok[0] = 12.23 szamok[1] = 10.2 szamok[2] = 7.29 szamok[3] = 11.3 szamok[4] = 12.7 Az atlag: 10.744 0. 12.23 -1.486 1. 10.2 0.544001 2. 7.29 3.454 3. 11.3 -0.556 4. 12.7 -1.956 |
I.7.1.1.1. Az egydimenziós tömbök inicializálása és értékadása
A C++ nyelv lehetővé teszi, hogy a tömbelemeknek kezdőértéket adjunk. A tömbdefinícióban az egyenlőség jel után, kapcsos zárójelek között megadott inicializációs lista értékeit a tömbelemek a tárolási sorrendjüknek megfelelően veszik fel:
elemtípus tömbnév[méret] = { vesszővel tagolt inicilizációs lista };
Nézzünk néhány példát vektorok inicializálására!
int primek[10] = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 27 };
char nev[8] = { 'I', 'v', 'á', 'n'};
double szamok[] = { 1.23, 2.34, 3.45, 4.56, 5.67 };
A primek esetében vigyáztunk, és pontosan az elemszámnak megfelelő számú értéket adtunk meg. Ha véletlenül a szükségesnél több kezdőérték szerep a listában, a fordító hibával jelzi azt.
A második példában az inicializációs lista a tömb elemeinek számánál kevesebb értéket tartalmaz. Ekkor a nev tömb első 4 eleme felveszi a megadott értékeket, míg a többi elem értéke 0 lesz. Ezt kihasználva bármekkora tömböt egyszerűen nullázhatunk:
int nagy[2013] = {0};
Az utolsó példában a szamok tömb elemeinek számát az inicializációs listában megadott konstansok számának (5) megfelelően állítja be a fordítóprogram. Jól használható ez a megoldás, ha a tömb elemeit fordításonként változtatjuk. Ekkor az elemek számát a fentiekben bemutatott módszerrel tudhatjuk meg:
double szamok[] = { 1.23, 2.34, 3.45, 4.56, 5.67 };
const int nszam = sizeof(szamok) / sizeof(szamok[0]);
Az inicializációs lista tetszőleges futásidejű kifejezést is tartalmazhat:
double eh[3]= { sqrt(2.3), exp(1.2), sin(3.14159265/4) };
Tömbök gyors, de kevésbé biztonságos kezeléséhez a cstring fejállományban deklarált „mem” kezdetű könyvtári függvényeket is használhatjuk. A memset () függvény segítségével char tömböket tölthetünk fel azonos karakterekkel, illetve bármilyen típusú tömböt 0 értékű bájtokkal:
char vonal[80]; memset( vonal, '=', 80 ); double merleg[365]; memset( merleg, 0, 365*sizeof(double) ); // vagy memset( merleg, 0, sizeof(merleg) );
Ez utóbbi példa felvet egy jogos kérdést, hogy az indexelésen és a sizeof operátoron kívül milyen C++ műveleteket használhatunk a tömbökkel. A válasz gyors és igen tömör, semmilyet. Ennek oka, hogy a C/C++ nyelvek a tömbneveket konstans értékű pointerként kezelik, melyeket a fordító állít be. Ezt memset () hívásakor ki is használtuk, hisz a függvény első argumentumaként egy mutatót vár.
Két azonos típusú és méretű tömb közötti értékadás elvégzésére kétfele megoldás közül is választhatunk. Első esetben a for ciklusban végezzük az elemek átmásolását, míg második megoldásban a könyvtári memcpy () könyvtári függvényt használjuk.
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
const int maxn = 8 ;
int forras[maxn]= { 2, 10, 29, 7, 30, 11, 7, 12 };
int cel[maxn];
for (int i=0; i<maxn; i++) {
cel[i] = forras[i]; // elemek másolása
}
// vagy
memcpy(cel, forras, sizeof(cel));
}
A memcpy () nem mindig működik helyesen, ha a forrás- és a célterület átfedésben van, például amikor a tömb egy részét kell elmozdítani, helyet felszabadítva egy új elemnek. Ekkor is két lehetőségünk van, a for ciklus, illetve a memmove () könyvtári függvény. Az alábbi példa rendezett tömbjének az 1 indexű pozíciójába szeretnénk egy új elemet beszúrni:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
const int maxn = 10 ;
int rendezett[maxn]= { 2, 7, 12, 23, 29 };
for (int i=5; i>1; i--) {
rendezett[i] = rendezett[i-1]; // elemek másolása
}
rendezett[1] = 3;
// vagy
memmove(rendezett+2, rendezett+1, 4*sizeof(int));
rendezett[1] = 3;
}
Megjegyezzük, hogy a cél- és a forrásterület címét a pointer-aritmetikát használva adtuk meg: rendezett+2, rendezett+1.
I.7.1.1.2. Egydimenziós tömbök és a typedef
Mint már említettük a programunk olvashatóságát nagyban növeli, ha a bonyolultabb típusneveket szinonim nevekkel helyettesítjük. Erre származtatott típusok esetén is a typedef biztosít lehetőséget.
Legyen a feladatunk két 3-elemű egész vektor vektoriális szorzatának számítása, és elhelyezése egy harmadik vektorban! A számításhoz az alábbi összefüggést használjuk:
|
| ||
|
|
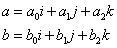
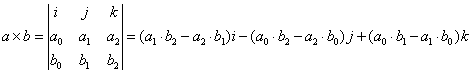
A feladat megoldásához szükséges tömböket kétféleképpen is létrehozhatjuk:
int a[3], b[3], c[3];
vagy
typedef int vektor3[3]; vektor3 a, b, c;
Az a és b vektorokat konstansokkal inicializáljuk:
typedef int vektor3[3];
vektor3 a = {1, 0, 0}, b = {0, 1, 0}, c;
c[0] = a[1]*b[2] - a[2]*b[1];
c[1] = -(a[0]*b[2] - a[2]*b[0]);
c[2] = a[0]*b[1] - a[1]*b[0];
Ugyancsak segít a typedef, ha például egy 12-elemű double elemeket tartalmazó tömbre pointerrel szeretnénk hivatkozni. Első gondolatunk a
double *xp[12];
típus felírása. A típuskifejezések értelmezésénél is az operátorok elsőbbségi táblázata lehet segítségünkre (A.7. szakasz - C++ műveletek elsőbbsége és csoportosítása függelék). Ez alapján az xp először egy 12-elemű tömb, és a tömbnév előtt az elemek típusa szerepel. Ebből következik xp 12-elemű mutatótömb. Az értelmezés sorrendjét zárójelekkel módosíthatjuk:
double (*xp)[12];
Ekkor xp először egy mutató, és a hivatkozott adat típusa double[12], vagyis 12-elemű double tömb. Készen vagyunk! Azonban sokkal gyorsabban és biztonságosabban célt érünk a typedef felhasználásával:
typedef double dvect12[12]; dvect12 *xp; double a[12]; xp = &a; (*xp)[0]=12.3; cout << a[0]; // 12.3
I.7.1.2. Kétdimenziós tömbök
Műszaki feladatok megoldása során szükség lehet arra, hogy mátrixokat számítógépen tároljunk. Ehhez a többdimenziós tömbök legegyszerűbb formáját, a kétdimenziós tömböket használhatjuk
elemtípus tömbnév[méret1][méret2];
ahol dimenziónként kell megmondani a méreteket. Példaként tároljuk az alábbi 3x4-es, egész elemeket tartalmazó mátrixot kétdimenziós tömbben!
|
|

A definíciós utasításban többféleképpen is megadhatjuk a mátrix elemeit, csak arra kell ügyelnünk, hogy sorfolytonos legyen a megadás.
int matrix[3][4] = { { 12, 23, 7, 29 },
{ 11, 30, 12, 7 },
{ 10, 2, 20, 12 } };
A tömb elemeinek eléréséhez az indexelés operátorát használjuk méghozzá kétszer. A
matrix[1][2]
hivatkozással a 1. sor 2. sorszámú elemét (12) jelöljük ki. (Emlékeztetünk arra, hogy az indexek értéke minden dimenzióban 0-val kezdődik!)
A következő ábrán (I.16. ábra - Kétdimenziós tömb grafikus ábrázolása) a kétdimenziós matrix tömb elemei mellett feltüntettük a sorok és az oszlopok (s/o) indexeit is.
A következő programrészletben megkeressük a fenti matrix legnagyobb (maxe) és legkisebb (mine) elemét. A megoldásban, a kétdimenziós tömbök feldolgozásához használt, egymásba ágyazott for ciklusok szerepelnek:
int maxe, mine;
maxe = mine = matrix[0][0];
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
if (matrix[i][j] > maxe )
maxe = matrix[i][j];
if (matrix[i][j] < mine )
mine = matrix[i][j];
}
}
A kétdimenziós tömbök mátrixos formában való megjelenítését az alábbi tipikus kódrészlet végzi:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++)
cout<<'\t'<<matrix[i][j];
cout<<endl;
}
I.7.1.3. Változó hosszúságú tömbök
A korábbi C++ szabvány szerint a tömbök a fordítás során jönnek létre, a méretet definiáló konstans kifejezések felhasználásával. A C++11 szabvány (Visual C++ 2012) a változó méretű tömbök (variable-length array) bevezetésével bővíti a tömbök használatának lehetőségeit. A futásidőben létrejövő változó hosszúságú tömb csak automatikus élettartamú, lokális változó lehet, és a definíciója nem tartalmazhat kezdőértéket. Mivel az ilyen tömbök csak függvényben használhatók, elképzelhető, hogy a tömbök mérete minden híváskor más és más - innen az elnevezés.
A változó hosszúságú tömb méretét tetszőleges egész típusú kifejezéssel megadhatjuk, azonban a létrehozást követően a méret nem módosítható. A változóméretű tömbökkel a sizeof operátor futásidejű változatát alkalmazza a fordító.
Az alábbi példában a tömb létrehozása előtt bekérjük annak méretét:
#include <iostream>
using namespace std;
int main() {
int meret;
cout << "A vektor elemeinek szama: ";
cin >> meret;
int vektor[meret];
for (int i=0; i<meret; i++) {
vektor[i] = i*i;
}
}
I.7.1.4. Mutatók és a tömbök kapcsolata
A C++ nyelvben a mutatók és a tömbök között szoros kapcsolat áll fenn. Minden művelet, ami tömbindexeléssel elvégezhető, mutatók segítségével szintén megvalósítható. Az egydimenziós tömbök (vektorok) és az egyszeres indirektségű („egycsillagos”) mutatók között teljes a tartalmi és a formai analógia. A többdimenziós tömbök és a többszörös indirektségű („többcsillagos”) mutatók esetén ez a kapcsolat csak formai.
Nézzük meg, honnan származik ez a vektorok és az egyszeres indirektségű mutatók között fennálló szoros kapcsolat! Definiáljunk egy 5-elemű egész vektort!
int a[5];
A vektor elemei a memóriában adott címtől kezdve folytonosan helyezkednek el. Mindegyik elemre a[i] formában hivatkozhatunk (I.17. ábra - Mutatók és a tömbök kapcsolata). Vegyünk fel egy p, egészre mutató pointert, majd a „címe” operátor segítségével állítsuk az a tömb elejére (a 0. elemre)!
int *p; p = &a[0]; vagy p = a;
A mutató beállítására a tömb nevét is használhatjuk, hisz az is egy int * típusú mutató, csak éppen nem módosítható. (Fordítási hibához vezet azonban a p = &a; kifejezés, hisz ekkor a jobb oldal típusa int (*)[5].)
Ezek után, ha hivatkozunk a p mutató által kijelölt (*p) változóra, akkor valójában az a[0] elemet érjük el.
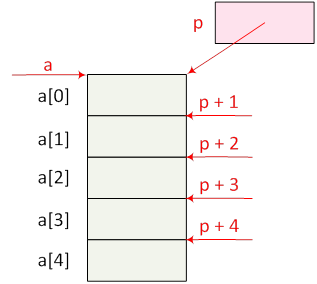
A mutatóaritmetika szabályai alapján a p+1, a p+2 stb. címek a p által kijelölt elem után elhelyezkedő elemeket jelölik ki. (Megjegyezzük, hogy negatív számokkal a változót megelőző elemeket címezhetjük meg.) Ennek alapján a *(p+i) kifejezéssel a tömb minden elemét elérhetjük:
A p mutató szerepe teljesen megegyezik az a tömbnév szerepével, hisz mindkettő az elemek sorozatának kezdetét jelöli ki a memóriában. Lényeges különbség azonban a két mutató között, hogy míg a p mutató változó (tehát értéke tetszőlegesen módosítható), addig az a egy konstans értékű mutató, amelyet a fordító rögzít a memóriában.
Az I.17. ábra - Mutatók és a tömbök kapcsolata jelöléseit használva, az alábbi táblázat soraiban szereplő hivatkozások azonosak:
|
|
A tömb i-dik elemének címe: | |||||
|
|
|
|
| |||
|
A tömb 0-dik eleme: | ||||||
|
|
|
|
|
|
| |
|
A tömb i-dik eleme: | ||||||
|
|
|
|
| |||
A legtöbb C++ fordító az a[i] hivatkozásokat automatikusan *(a+i) alakúra alakítja, majd ezt a pointeres alakot lefordítja. Az analógia azonban visszafelé is igaz, vagyis az indirektség (*) operátora helyett mindig használhatjuk az indexelés ([]) operátorát.
Többdimenziós esetben az analógia csak formai, azonban sok esetben ez is segíthet bonyolult adatszerkezetek helyes kezelésében. Példaként tekintsük az alábbi valós mátrixot:
double m[2][3] = { { 10, 2, 4 },
{ 7, 2, 9 } };
A tömb elemei a memóriában sorfolytonosan helyezkednek el. Ha az utolsó dimenziót elhagyjuk, a kijelölt sor mutatójához jutunk: m[0], m[1], míg a tömb m neve a teljes tömbre mutat (I.18. ábra - Kétdimenziós tömb a memóriában). Megállapíthatjuk, hogy a kétdimenziós tömb valójában egy olyan vektor (egydimenziós tömb), melynek elemei vektorok (mutatók). Ennek ellenére a többdimenziós tömbök mindig folytonos memóriaterületen helyezkednek el. A példánkban a kezdőértékként megadott mátrix sorai képezik azokat a vektorokat, amelyekből az m vektor felépül.
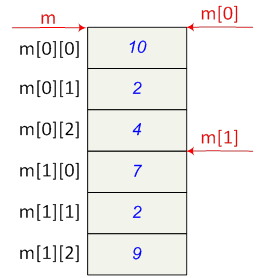
Használva a vektorok és a mutatók közötti formai analógiát, az indexelés operátorai minden további nélkül átírhatók indirektség operátorává. Az alábbi kifejezések mindegyike a kétdimenziós m tömb ugyanazon elemére (9) hivatkozik:
m[1][2] *(m[1] + 2) *(*(m+1)+2)
I.7.2. Dinamikus helyfoglalású tömbök
A tömbök segítségével nagymennyiségű adatot egyszerűen és hatékonyan tárolhatunk, illetve feldolgozhatunk. A hagyományos tömbök használatának azonban nagy hátránya, hogy méretük már a fordítás során eldől, és csak futás közben derül ki, ha túl nagy memóriát igényeltünk. Különösen igaz ez a függvényekben létrehozott lokális tömbökre.
Általános szabály, hogy függvényen belül, csak kisméretű tömböket definiáljunk. Amennyiben nagyobb adatmennyiséget kell tárolnunk, alkalmazzuk a dinamikus memóriafoglalás eszközeit, hisz a halomterületen sokkal több szabad tárterület áll a rendelkezésünkre, mint a veremben.
Emlékeztetőül, a new operátor segítségével nemcsak egyetlen elemnek, hanem több egymás után elhelyezkedő elemnek is helyet foglalhatunk a memóriában. Ebben az esetben a lefoglalt tárterület felszabadításához a delete[] operátor kell használnunk.
A dinamikus memóriafoglalás és felszabadítás műveletei szabványos könyvtári függvények formájában is jelen vannak a C/C++ nyelvben. A függvények eléréséhez az cstdlib fejállományt kell a programunkba építeni. A malloc () függvény adott bájtméretű területet foglal le, és visszaadja a terület kezdőcímét. A calloc () hasonlóan működik, azonban a tárterület méretét elemszám, elemméret formában kell megadni, és nullázza a lefoglalt memóriablokkot. A realloc () újraméretezi a már lefoglalt memóriaterületet, megőrizve annak eredeti tartalmát (ha nagyobbat foglalunk). A free () függvényt a lefoglalt területet felszabadítására használjuk.
Amennyiben objektumokat kezelünk a programunkban, a new és a delete operátorokat kell alkalmaznunk, a hozzájuk kapcsolódó kiegészítő működés elérése érdekében.
I.7.2.1. Egydimenziós dinamikus tömbök
Leggyakrabban egydimenziós, dinamikus tömböket használunk a programozási feladatok megoldása során.
típus *mutató;
mutató = new típus [elemszám];
vagy
mutató = new (nothrow) típus [elemszám];
A különbség a kétféle megoldás között csak sikertelen foglalás esetén tapasztalható. Az első esetben a rendszer kivétellel ( bad_alloc ) jelzi, ha nem áll rendelkezésre a kívánt méretű, folytonos tárterület, míg a második formával 0 értékű pointert kapunk.
Tömbök esetén különösen fontos, hogy ne feledkezzünk meg a lefoglalt memória szabaddá tételéről:
delete [] mutató;
Az alábbi példában a felhasználótól kérjük be a tömb méretét, helyet foglalunk a tömb számára, majd pedig feltöltjük véletlen számokkal.
#include <iostream>
#include <exception>
#include <ctime>
#include <cstdlib>
using namespace std;
int main() {
long *adatok, meret;
cout << "\nKerem a tomb meretet: ";
cin >> meret;
cin.get();
// Memóriafoglalás
try {
adatok = new long [meret];
}
catch (bad_alloc) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria !\n" << endl;
return -1; // Kilépünk a programból
}
// A tömb feltöltése véletlen számokkal
srand(unsigned(time(0)));
for (int i=0; i<meret; i++) {
adatok[i] = rand() % 2012;
// vagy *(adatok+i) = rand() %2012;
}
// A lefoglalt memória felszabadítása
delete[] adatok;
return 0;
}
I.7.2.2. Kétdimenziós dinamikus tömbök
Már a korábbi részekben is említettük, hogy a kétdimenziós tömbök valójában egydimenziós vektorok (a sorok) vektora. Ennek következménye, hogy nem tudunk akármekkora kétdimenziós tömböt futás közben létrehozni, hisz a fordítónak ismernie kell az elemek (sorvektorok) típusát (méretét). Az elemek (sorok) száma azonban tetszőlegesen megadható. A new az alábbi példában is egy mutatót ad vissza, ami a létrehozott kétdimenziós tömbre mutat.
const int sorhossz = 4; int sorokszama; cout<<"Sorok szama: "; cin >> sorokszama; int (*mp)[sorhossz] = new int [sorokszama][sorhossz];
Sokkal érthetőbb a megoldás, ha segítségül hívjuk a typedef kulcsszót:
const int sorhossz = 4; int sorokszama; cout<<"Sorok szama: "; cin >> sorokszama; typedef int sortipus[sorhossz]; sortipus *mp = new sortipus [sorokszama];
Bármelyik megoldást is választjuk, az egész elemek nullázására az alábbi ciklusokat használhatjuk:
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
mp[i][j]=0;
ahol mp[i] kijelöli az i-dik sort, az mp[i][j] pedig az i-dik sor j-dik elemét. A fenti utasításokat a main () függvénybe helyezve, az mp mutató a veremben jön létre, míg a teljes kétdimenziós tömb a halomterületen. A megoldásunk két szépséghibával rendelkezik: a tömb számára folytonos tárterületre van szükség, másrészt pedig zavaró a sorok hosszának fordítás közben való megadása.
Nézzük meg, miként küszöbölhetjük ki a folytonos memóriaterület és a rögzített sorhossz adta korlátozásokat! A következő két megoldás alapját az adja, hogy a mutatókból is készíthetünk tömböket.
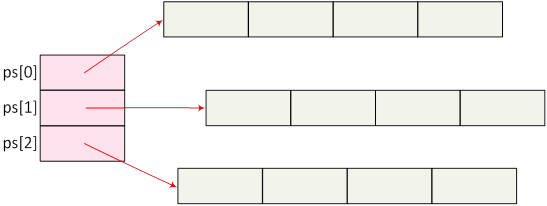
Az első esetben a sorok számát rögzítő mutatótömböt a veremben hozzuk létre, és csak a sorvektorok jönnek létre dinamikusan (I.19. ábra - Dinamikus foglalású sorvektorok).
A sorokat kijelölő háromelemű mutatóvektor:
int* ps[3]= {0};A sorok dinamikus létrehozása 4-elemű sorokat feltételezve:
for (int i=0; i<3; i++) ps[i] = new int[4];Az elemeket a * és az [] operátorok segítségével egyaránt elérhetjük:
*(ps[1] + 2) = 123; cout << ps[1][2];
Végül ne feledkezzünk meg a dinamikusan foglalt területek felszabadításáról!
for (int i=0; i<3; i++) delete[] ps[i];
Amennyiben a sorok és az oszlopok számát egyaránt futás közben szeretnénk beállítani, az előző megoldás mutatótömbjét is dinamikusan kell létrehoznunk. Ekkor a verem egyetlen int * típusú mutatót tartalmaz (I.20. ábra - Dinamikus foglalású mutatóvektor és sorvektorok).
A memória foglalása, elérése és felszabadítása jól nyomom követhető az alábbi példaprogramban:
#include <iostream>
using namespace std;
int main() {
int sorokszama, sorhossz;
cout<<"Sorok szama : "; cin >> sorokszama;
cout<<"Sorok hossza: "; cin >> sorhossz;
// Memóriafoglalás
int* *pps;
// A mutatóvektor létrehozása
pps = new int* [sorokszama];
// A sorok foglalása
for (int i=0; i<sorokszama; i++)
pps[i] = new int [sorhossz];
// A tömb elérése
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
pps[i][j]=0;
// A memória felszabadítása
for (int i=0; i<sorokszama; i++)
delete pps[i];
delete pps;
}
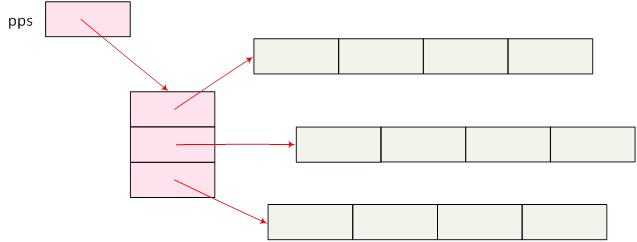
I.7.3. A vector típus használata
Napjaink C++ programjaiban a hagyományos egy- és kétdimenziós tömbök helyett egyre inkább teret hódít a C++ szabványos sablonkönyvtárának (STL) vector típusa. Ez a típus minden olyan jellemzővel (újraméretezés, indexhatár-ellenőrzés, automatikus memória-felszabadítás) rendelkezik, amelyek teljesen biztonságossá teszik a tömbök használatát.
A vector típus az eddig használt típusokkal szemben egy paraméterezhető típus, ami azt jelenti, hogy a tárolt elemek típusát vector szó után <> jelek között kell megadnunk. A létrehozott vektor - a cout és cin objektumokhoz hasonlóan - szintén objektum, melyhez műveletek és függvények egyaránt tartoznak.
I.7.3.1. Egydimenziós tömbök a vektorban
A vector típussal - a nevének megfelelően - az egydimenziós tömböket helyettesíthetjük. A típus teljes eszköztárának bemutatása helyett, néhány alapfogásra korlátozzuk az ismerkedést.
Nézzünk néhány vektordefiniálási megoldást, melyekhez a vector fejállomány kell a programunkba beépíteni!
vector<int> ivektor; ivektor.resize(10); vector<long> lvektor(12); vector<float> fvector(7, 1.0);
Az ivektor egy üres vektor, melynek méretét a resize () függvénnyel 10-re állítjuk. Az lvektor 12 darab long típusú elemet tartalmaz. Mindkét esetben az elemek 0 kezdőértéket kapnak. Az fvektor 7 darab float típusú elemmel jön létre, melyek mindegyike 1.0 értékkel inicializálódik.
A vektor aktuális elemszámát a size () függvénnyel bármikor lekérdezhetjük, az elemek elérésére pedig a szokásos indexelés operátorát használhatjuk. A vector típus érdekes lehetősége, hogy az elemeit akár egyesével is bővíthetjük a push_back () hívással.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> ivektor(10, 5);
ivektor.push_back(10);
ivektor.push_back(2);
for (unsigned index=0; index<ivektor.size(); index++) {
cout << ivektor[index] << endl;
}
}
Megjegyezzük, hogy az STL adattárolók használata az előre definiált algoritmusokkal válik teljessé ( algorithm fejállomány).
I.7.3.2. Kétdimenziós tömb vektorokban
A vector típusok egymásba ágyazásával kétdimenziós, dinamikus tömböket is létrehozhatunk, az eddigieknél sokkal egyszerűbb módon.
#include <iostream>
#include <vector>
using namespace std;
int main() {
int sorokszama, sorhossz;
cout<<"Sorok szama : "; cin >> sorokszama;
cout<<"Sorok hossza: "; cin >> sorhossz;
vector< vector<int> > m (sorokszama, sorhossz);
// A tömb elérése
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
m[i][j]= i+j;
}
I.7.4. C-stílusú sztringek kezelése
A C/C++ nyelv az alaptípusai között nem tartalmazza a karaktersorozatok tárolására alkalmas sztring típust. Mivel azonban a szövegek tárolása és feldolgozása elengedhetetlen része a C/C++ programoknak, a tároláshoz egydimenziós karaktertömböket használhatunk. A feldolgozáshoz szükséges még egy megegyezés, ami szerint az értékes karaktereket mindig egy 0 értékű bájt zárja a tömbben. A sztringek kezelését operátorok ugyan nem segítik, azonban egy gazdag függvénykészlet áll a rendelkezésünkre (lásd cstring fejállomány).
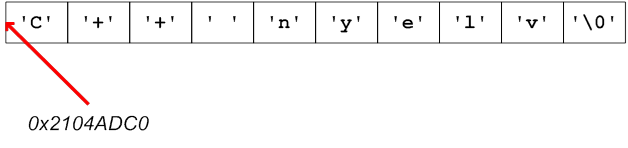
A programban gyakran használunk kettős idézőjelekkel határolt szövegeket (sztringliterálokat), amiket a fordító az inicializált adatok között tárol a fent elmondottak szerint. A
cout << "C++ nyelv";
utasítás fordításakor a szöveg a memóriába másolódik, (I.21. ábra - Sztring konstans a memóriában) és a << művelet jobb operandusaként a const char * típusú tárolási cím jelenik meg. Futtatáskor a cout objektum karakterenként megjeleníti a kijelöl tárterület tartalmát, a 0 értékű bájt eléréséig.
A széles karakterekből álló sztringek szintén a fentiek szerint tárolódnak, azonban ebben az esetben a tömb elemeinek típusa wchar_t.
wcout << L"C++ nyelv";
A C++ nyelven a string illetve a wstring típusokat is használhatjuk szövegek feldolgozásához, ezért dióhéjban ezekkel a típusokkal is megismerkedünk.
I.7.4.1. Sztringek egydimenziós tömbökben
Amikor helyet foglalunk valamely karaktersorozat számára, akkor a sztring végét jelző bájtot is figyelembe kell vennünk. Ha az str tömbben maximálisan 80-karakteres szöveget szeretnénk tárolni, akkor a tömb méretét 80+1=81-nek kell megadnunk:
char sor[81];
A programozás során gyakran használunk kezdőértékkel ellátott sztringeket. A kezdőérték megadására alkalmazhatjuk a tömböknél bemutatott megoldásokat, azonban nem szabad megfeledkeznünk a '\0' karakter elhelyezéséről:
char st1[10] = { 'O', 'm', 'e', 'g', 'a', '\0' };
wchar_t wst1[10] = { L'O', L'm', L'e', L'g', L'a', L'\0' };
char st2[] = { 'O', 'm', 'e', 'g', 'a', '\0' };
wchar_t wst2[] = { L'O', L'm', L'e', L'g', L'a', L'\0' };
Az st1 sztring számára 10 bájt helyet foglal a fordító, és az első 6 bájtba bemásolja a megadott karaktereket. Az st2 azonban pontosan annyi bájt hosszú lesz, ahány karaktert megadtunk az inicializációs listában. A széles karakteres wst1 és wst2 sztringek esetén az előző bájméretek kétszeresét foglalja le a fordító.
A karaktertömbök inicializálása azonban sokkal biztonságosabban elvégezhető a sztringliterálok (sztring konstansok) felhasználásával:
char st1[10] = "Omega"; wchar_t wst1[10] = L"Omega"; char st2[] = "Omega"; wchar_t wst2[] = L"Omega";
A kezdőértékadás ugyan mindkét esetben - a karakterenként illetve a sztring konstanssal elvégzett - azonos eredményt ad, azonban a sztring konstans használata sokkal áttekinthetőbb. Nem beszélve arról, hogy a sztringeket lezáró 0-ás bájtot szintén a fordító helyezi el a memóriában.
A tömbben történő tárolás következménye, hogy a sztringekre vonatkozóan szintén nem tartalmaz semmilyen műveletet (értékadás, összehasonlítás stb.) a C++ nyelv. A karaktersorozatok kezelésére szolgáló könyvtári függvények azonban gazdag lehetőséget biztosítanak a programozónak. Nézzünk néhány karaktersorozatokra vonatkozó alapművelet elvégzésére szolgáló függvényt!
|
Művelet |
Függvény (char) |
Függvény (wchar_t) |
|---|---|---|
|
szöveg beolvasása |
cin>>, cin.get () , cin.getline () |
wcin>>, wcin.get () , wcin.getline () |
|
szöveg kiírása |
cout<< |
wcout<< |
|
értékadás |
strcpy () , strncpy () |
wcscpy () , wcsncpy () |
|
hozzáfűzés |
strcat () , strncat () |
wcscat () , wcsncat () |
|
sztring hosszának lekérdezése |
strlen () |
wcslen () |
|
sztringek összehasonlítása |
strcmp () , strcnmp () |
wcscmp () , wcsncmp () |
|
karakter keresése szringben |
strchr () |
wcschr () |
A char típusú karakterekből álló sztringek kezeléséhez az iostream és a cstring deklarációs állományok beépítése szükséges, míg a széles karakteres függvényekhez a cwchar .
Az alábbi példaprogram a beolvasott szöveget nagybetűssé alakítva, fordítva írja vissza a képernyőre. A példából jól látható, hogy a sztringek hatékony kezelése érdekében egyaránt használjuk a könyvtári függvényeket és a karaktertömb értelmezést.
#include <iostream>
#include <cstring>
#include <cctype>
using namespace std;
int main() {
char s[80];
cout <<"Kerek egy szoveget: ";
cin.get(s, 80);
cout<<"A beolvasott szoveg: "<< s << endl;
for (int i = strlen(s)-1; i >= 0; i--)
cout<<(char)toupper(s[i]);
cout<<endl;
}
A megoldás széles karakteres változata:
#include <iostream>
#include <cwchar>
#include <cwctype>
using namespace std;
int main() {
wchar_t s[80];
wcout <<L"Kerek egy szoveget: ";
wcin.get(s, 80);
wcout<<L"A beolvasott szoveg: "<< s << endl;
for (int i = wcslen(s)-1; i >= 0; i--)
wcout<<(wchar_t)towupper(s[i]);
wcout<<endl;
}
Mindkét példában a szöveg beolvasásához a biztonságos cin . get () függvényt használtuk. A függvény minden karaktert beolvas az <Enter> lenyomásáig. A megadott tömbbe azonban legfeljebb az argumentumként megadott méret -1 karakter kerül, így nem lehet túlírni a tömböt.
I.7.4.2. Sztringek és a pointerek
A sztringek kezelésére karaktertömböket és karaktermutatókat egyaránt használhatunk, azonban a mutatókkal óvatosan kell bánni. Tekintsük az alábbi gyakran alkalmazott definíciókat!
char str[16] = "alfa"; char *pstr = "gamma";
Első esetben a fordító létrehozza a 16-elemű str tömböt, majd belemásolja a kezdőértékként megadott szöveg karaktereit, valamint a 0-ás bájtot. A második esetben a fordító az inicializáló szöveget eltárolja a sztringliterálok számára fenntartott területen, majd a sztring kezdőcímével inicializálja a pstr mutatót.
A pstr mutató értéke a későbbiek folyamán természetesen megváltoztatható (ami a példánkban a "gamma" sztring elvesztését okozza):
pstr = "iota";
Ekkor mutató-értékadás történik, hisz a pstr felveszi az új sztringliterál címét. Ezzel szemben az str tömb nevére irányuló értékadás fordítási hibához vezet:
str = "iota"; // hiba! ↯
Amennyiben egy sztringet karakterenként kell feldolgozni, akkor választhatunk a tömbös és a pointeres megközelítés között. A következő példaprogramban a beolvasott karaktersorozatot először titkosítjuk a kizáró vagy művelet felhasználásával, majd pedig visszaállítjuk az eredeti tartalmát. (A titkosításnál a karaktertömb, míg a visszakódolásnál a mutató értelmezést alkalmazzuk.) Mind a két esetben a ciklusok leállási feltétele a sztringet záró nullás bájt elérése.
#include <iostream>
using namespace std;
const unsigned char kulcs = 0xCD;
int main() {
usigned char s[80], *p;
cout <<"Kerek egy szoveget: ";
cin.get(s, 80);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
cout << "A titkositott szoveg : "<< s << endl;
p = s;
while (*p) // visszaállítás
*p++ ^= kulcs;
cout << "Az eredeti szoveg : "<< s << endl;
}
A következő példában a léptető és az indirektség operátorokat együtt alkalmazzuk, amihez kellő óvatosság szükséges. Az alábbi példában az sp mutatóval egy dinamikusan tárolt karaktersorozatra mutatunk. (Megjegyezzük, hogy a C++ implementációk többsége nem engedi módosítani a sztringliterálokat.)
char *sp = new char [33]; strcpy(sp, "C++"); cout << ++*sp << endl; // D cout << sp << endl; // D++ cout << *sp++ << endl; // D cout << sp << endl; // ++
Az első esetben (++*sp) először az indirektség operátorát értelmezi a fordító, majd pedig elvégzi a hivatkozott karakter léptetését. A második esetben (*sp++) először a mutató léptetése értékelődik ki, azonban a hátravetett forma következtében csak a teljes kifejezés feldolgozása után megy végbe a léptetés. A kifejezés értéke pedig a hivatkozott karakter.
I.7.4.3. Sztringtömbök használata
A C++ programok többsége tartalmaz olyan szövegeket, például üzeneteket, amelyeket adott index (hibakód) alapján kívánunk kiválasztani. Az ilyen szövegek tárolására a legegyszerűbb megoldás a sztringtömbök definiálása.
A sztringtömbök kialakítása során választhatunk a kétdimenziós tömb és a mutatótömb között. Kezdő C++ programozók számára sokszor gondot jelent ezek megkülönböztetése. Tekintsük az alábbi két definíciót!
int a[4][6]; int* b[4];
Az a „igazi” kétdimenziós tömb, amely számára a fordító 24 (4x6) darab int típusú elem tárolására alkalmas folytonos területet foglal le a memóriában. Ezzel szemben a b 4-elemű mutatóvektor. A fordító csak a 4 darab mutató számára foglal helyet a definíció hatására. A inicializáció további részeit a programból kell elvégeznünk. Inicializáljuk úgy a mutatótömböt, hogy az alkalmas legyen 5x10 egész elem tárolására!
int s1[6], s2[6], s3[6], s4[6];
int* b[4] = { s1, s2, s3, s4 };
Látható, hogy a 24 int elem tárolására szükséges memóriaterületen felül, további területet is felhasználtunk (a mutatók számára). Joggal vetődik fel a kérdés, hogy mi az előnye a mutatótömbök használatának. A választ a sorok hosszában kell keresni. Míg a kétdimenziós tömb esetén minden sor ugyanannyi elemet tartalmaz,
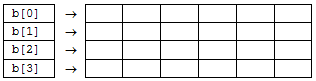
addig a mutatótömb esetén az egyes sorok mérete tetszőleges lehet.
int s1[1], s2[3], s3[2], s4[6];
int* b[4] = { s1, s2, s3, s4 };
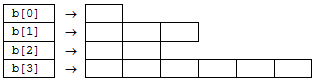
A mutatótömb másik előnye, hogy a felépítése összhangban van a dinamikus memóriafoglalás lehetőségeivel, így fontos szerepet játszik a dinamikus helyfoglalású tömbök kialakításánál.
E kis bevezető után térjünk rá az alfejezet témájára, a sztringtömbök kialakítására! A sztringtömböket általában kezdőértékek megadásával definiáljuk. Az első példában kétdimenziós karaktertömböt definiálunk, az alábbi utasítással:
static char nevek1[][10] = { "Iván",
"Olesya",
"Anna",
"Adrienn" };
Az definíció során létrejön egy 4x10-es karaktertömb - a sorok számát a fordítóprogram az inicializációs lista alapján határozza meg. A kétdimenziós karaktertömb sorai a memóriában folytonosan helyezkednek el (I.22. ábra - Sztringtömb kétdimenziós tömbben tárolva).

A második esetben mutatótömböt használunk a nevek címének tárolására:
static char* nevek2[] = { "Iván",
"Olesya",
"Anna",
"Adrienn" };
A fordító a memóriában négy különböző méretű területet foglal le a következő ábrán (I.23. ábra - Optimális tárolású sztringtömb) látható módon:
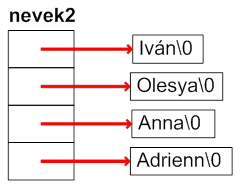
Érdemes összehasonlítani a két megoldást mind a definíció, mind pedig a memóriaelérés szempontjából.
cout << nevek1[0] << endl; // Iván cout << nevek1[1][4] << endl; // y cout << nevek2[0] << endl; // Iván cout << nevek2[1][4] << endl; // y
I.7.5. A string típus
A C++ nyelv szabványos sablonkönyvtárában (STL) a szövegkezelést támogató osztályokat is találunk. Az előzőekben bemutatott megoldások a C-stílusú karaktersorozatokra vonatkoznak, most azonban megismerkedünk a string és a wstring típusok lehetőségeivel.
A C++ stílusú karaktersorozat-kezelés eléréséhez a string nevű fejállományt kell a programunkba beépíteni. A string típussal definiált objektumokon keresztül egy sor kényelmes szövegkezelő művelet áll a rendelkezésünkre, operátorok és tagfüggvények formájában. Nézzünk néhányat ezek közül! (A táblázatban a tagfüggvények előtt pont szerepel. A tagfüggvények nevét az objektum neve után, ponttal elválasztva adjuk meg.) Széles karakterekből álló karaktersorozatok kezeléséhez a string fejállomány mellet a cwchar fájlra is szükségünk van.
|
Művelet |
C++ megoldás - string |
C++ megoldás - wstring |
|---|---|---|
|
szöveg beolvasása |
cin>>, getline () |
wcin>>, getline () |
|
szöveg kiírása |
cout<< |
wcout<< |
|
értékadás |
=, .assign () |
=, .assign () |
|
összefűzés |
+, += |
+, += |
|
a sztring karaktereinek elérése |
[] |
[] |
|
sztring hosszának lekérdezése |
.size() |
.size () |
|
sztringek összehasonlítása |
.compare () , ==, !=, <, <=, >, >= |
.compare () , ==, !=, <, <=, >, >= |
|
átalakítás C-stílusú karaktersorozattá |
.c_str () , .data () |
.c_str () , .data () |
Példaként írjuk át szövegtitkosító programunkat C++ stílusú sztringkezelés felhasználásával!
#include <string>
#include <iostream>
using namespace std;
const unsigned char kulcs = 0xCD;
int main() {
string s;
char *p;
cout<<"Kerek egy szoveget : ";
getline(cin, s);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
cout<<"A titkositott szoveg : "<<s<<endl;
p=(char *)s.c_str();
while (*p) // visszaállítás
*p++ ^= kulcs;
cout<<"Az eredeti szoveg : "<<s<<endl;
}
A feladat megoldása széles karaktereket tartalmazó sztringekkel (wstring) az alábbiakban látható
#include <string>
#include <iostream>
#include <cwchar>
using namespace std;
const unsigned wchar_t kulcs = 0xCD;
int main()
{
wstring s;
wchar_t *p;
wcout<<L"Kerek egy szoveget : ";
getline(wcin, s);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
wcout<<L"A titkositott szoveg : "<<s<<endl;
p=(wchar_t *)s.c_str();
while (*p) // visszaállítás
*p++ ^= kulcs;
wcout<<L"Az eredeti szoveg : "<<s<<endl;
}
I.8. Felhasználói típusok
A tömbök segítségével azonos típusú adatokat összefogva tárolhatunk, és könnyen fel is dolgozhatunk. A programozási feladatok nagy részében azonban különböző típusú adatokat kell logikailag egyetlen egységben kezelni. A C++ nyelv több lehetőséget is kínál erre, melyek közül a struktúra (struct) és az osztály (class) típusok külön jelentőséggel bírnak, hiszen rájuk épülnek a könyvünkben (III. fejezet - Objektum-orientált programozás C++ nyelven) tárgyalt objektum-orientált megoldások.
A következő részben az összeállított (aggregate) típusok közül megismerkedünk a struktúra, az osztály, a bitmező és az unió (union) típusokkal. Az ismerkedés során a hangsúlyt a struktúrára (struct) helyezzük. Ennek oka, hogy a struktúra típussal kapcsolatos fogalmak és megoldások minden további nélkül alkalmazhatók a többi felhasználói típusra.
I.8.1. A struktúra típus
C++ nyelven a struktúra (struct) típus több tetszőleges típusú (kivéve a void és a függvénytípust) adatelem együttese. Ezek az adatelemek, melyek szokásos elnevezése struktúraelem vagy adattag (data member), csak a struktúrán belül érvényes nevekkel rendelkeznek. (A más nyelveken a mező (field) elnevezést alkalmazzák, mely elnevezést azonban a bitstruktúrákhoz kapcsolja a C++ nyelv.)
I.8.1.1. Struktúra típus és struktúra változó
Egy struktúra típusú változót két lépésben hozunk létre. Először megadjuk magát a struktúra típust, melyet felhasználva változókat definiálhatunk. A struktúra felépítését meghatározó deklaráció általános formája:
struct struktúra_típus {
típus 1 tag 1 ; // kezdőérték nélkül!
típus 2 tag 2 ;
. . .
típus n tag n ;
};
Felhívjuk a figyelmet arra, hogy a struktúra deklarációját záró kapcsos zárójel mögé a pontosvesszőt kötelező kitenni. Az adattagok deklarációjára a C++ nyelv szokásos változó-deklarációs szabályai érvényesek, azonban kezdőérték nem adható meg. A fenti típussal struktúra változót (struktúrát) a már megismert módon készíthetünk:
struct struktúra_típus struktúra_változó; // C/C++
struktúra_típus struktúra_változó; // csak C++
A C++ nyelvben a struct, a union és a class kulcsszavak után álló név típusnévként használható a kulcsszó megadása nélkül. A typedef alkalmazásával eltűnik a különbség a két nyelv között:
typedef struct {
típus 1 tag 1 ;
típus 2 tag 2 ;
. . .
típus n tag n ;
} struktúra_típus;
struktúra_típus struktúra_változó; // C/C++
A tömbökhöz hasonlóan a struktúra definíciójában is szerepelhet kezdőértékadás. Az egyes adattagokat inicializáló kifejezések vesszővel elválasztott listáját kapcsos zárójelek közé kell zárni.
struktúra_típus struktúra_változó = {kezdőértéklista}; // C/C++
Megjegyezzük, hogy a legtöbb szoftverfejlesztő cégnél ez utóbbi (typedef-es) struktúra definíciót támogatják a keveredések elkerülése érdekében.
Felhívjuk a figyelmet arra, hogy a struct típusban megadott tagnevek láthatósága a struktúrára korlátozódik. Ez azt jelenti, hogy ugyanazt a nevet egy adott láthatósági szinten belül (modul, blokk), több struktúrában valamint független névként egyaránt felhasználhatjuk:
struct s1 {
int a;
double b;
};
struct s2 {
char a[7];
s1 b;
};
long a;
double b[12];
Nézzünk egy példát a struktúratípus megadására! Zenei CD-ket nyilvántartó program készítése során jól használható a következő adatstruktúra:
struct zeneCD {
string eloado, cim; // a CD előadója és címe
int ev; // a kiadás éve
int ar; // a CD ára
};
A zeneCD típussal változókat is definiálhatunk:
zeneCD klasszikus = {"Vivaldi", "A negy evszak", 2009, 2590};
zeneCD *pzene = 0, rock, mese = {};
A struktúra típusú változók közül a rock inicializálatlan, míg a mese struktúra minden tagja a típusának megfelelő az alapértelmezés szerinti kezdőértéket veszi fel. A pzene mutató nem hivatkozik egyetlen struktúrára sem.
A struktúra definíciójával létrehoztunk egy új felhasználói típust. A struktúra típusú változó adattagjait a fordító a deklaráció sorrendjében tárolja a memóriában. Az I.24. ábra - Struktúra a memóriában grafikusan ábrázolja a
zeneCD relax;
definícióval létrehozott adatstruktúra felépítését.
Az ábráról is leolvasható, hogy az adattagok nevei a struktúra elejétől mért távolságokat jelölnek. A struktúra mérete általában megegyezik az adattagok méretének összegével. Bizonyos esetekben azonban (optimalizálás sebességre, adatok memóriahatárra való igazítása stb.) „lyukak” keletkezhetnek a struktúra tagjai között. A sizeof operátor alkalmazásával azonban mindig a pontos méretet kapjuk.
Az esetek többségében az adattagok memóriahatárra igazítását rábízzuk a fordítóra, ami a gyors elérés érdekében az adott hardverre optimalizálva helyezi el az adatokat. Ha azonban különböző platformok között struktúrákat fájl segítségével cserélünk, a mentéshez használt igazítást kell a felolvasó programban beállítanunk.
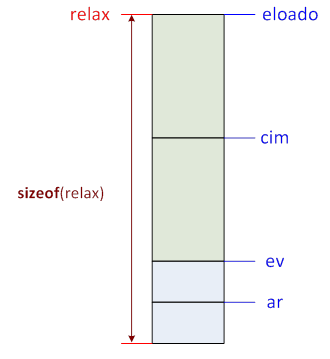
A C++ fordítóprogram működésének vezérlésére a #pragma előfordító előírást (direktívát) használjuk, melynek lehetőségei teljes egészében implementációfüggők.
I.8.1.2. Hivatkozás a struktúra adattagjaira
A struktúra szót gyakran önállóan is használjuk, ilyenkor azonban nem a típusra, hanem az adott struktúra típussal létrehozott változóra gondolunk. Definiáljunk néhány változót az előzőekben deklarált zeneCD típus felhasználásával!
zeneCD s1, s2, *ps;
Az s1 és s2 zeneCD típusú változók tárolásához szükséges memóriaterület lefoglalásáról a fordító gondoskodik. Ahhoz, hogy a pszeneCD típusú mutatóval is hivatkozhassunk egy struktúrára, két lehetőség közül választhatunk. Az első esetben a ps-t egyszerűen ráirányítjuk az s1 struktúrára:
ps = &s1;
A második lehetőség a dinamikus memóriafoglalás alkalmazását jelenti. Az alábbi programrészletben memóriát foglalunk a zeneCD struktúra számára, majd pedig felszabadítjuk azt:
ps = new (nothrow) zeneCD; if (!ps) exit(-1); // ... delete ps;
A megfelelő definíciók megadása után három struktúrával rendelkezünk: s1, s2 és *ps. Nézzük meg, hogyan lehet értéket adni a struktúráknak! Erre a célra a C++ nyelvben a pont ( . ) operátor használható. A pont operátor bal oldali operandusa a struktúra-változó, a jobb oldali operandusa pedig a struktúrán belül jelöli ki az adattagot.
s1.eloado = "Vivaldi"; s1.cim = "A négy évszak"; s1.ev = 2005; s1.ar = 2560;
Amikor a pont operátort a ps által mutatott struktúrára alkalmazzuk, a precedencia szabályok miatt zárójelek között kell megadnunk a *ps kifejezést:
(*ps).eloado = "Vivaldi"; (*ps).cim = "A négy évszak"; (*ps).ev = 2005; (*ps).ar = 2560;
Mivel a C++ nyelvben gyakran használunk mutató által kijelölt struktúrákat, a nyelv ezekben az esetekben egy önálló operátort – a nyíl (->) operátor – biztosít az adattag-hivatkozások elvégzésére. (A nyíl operátor két karakterből, a mínusz és a nagyobb jelből áll.) A nyíl operátor használatával olvashatóbb formában írhatjuk fel ps által kijelölt struktúra adattagjaira vonatkozó értékadásokat:
ps->eloado = "Vivaldi"; ps->cim = "A négy évszak"; ps->ev = 2005; ps->ar = 2560;
A nyíl operátor bal oldali operandusa a struktúra változóra mutató pointer, míg a jobb oldali operandusa – a pont operátorhoz hasonlóan – a struktúrán belül jelöli ki az adattagot. Ennek megfelelően a ps->ar kifejezés jelentése: "a ps mutató által kijelölt struktúra ar adattagja".
A pont és a nyíl operátorok használatával kapcsolatban javasoljuk, hogy a pont operátort csak közvetlen (a struktúra típusú változó adattagjára történő) hivatkozás esetén, míg a nyíl operátort kizárólag közvetett (mutató által kijelölt struktúra adattagjára vonatkozó) hivatkozás esetén használjuk.
A struktúrára vonatkozó értékadás speciális esete, amikor egy struktúra típusú változó tartalmát egy másik, azonos típusú változónak kívánjuk megfeleltetni. Ezt a műveletet adattagonként is elvégezhetjük,
s2.eloado = s1.eloado; s2.cim = s1.cim; s2.ev = s1.ev; s2.ar = s1.ar;
azonban a C++ nyelv a struktúra változókra vonatkozó értékadás (=) műveletét is értelmezi:
s2 = s1 ; // ez megfelel a fenti 4 értékadásnak *ps = s2 ; s1 = *ps = s2 ;
Az értékadásnak ez a módja egyszerűen a struktúra által lefoglalt memóriablokk átmásolását jelenti. Ez a művelet azonban gondot okoz, amikor a struktúra olyan mutatót tartalmaz, amely külső memóriaterületre hivatkozik. Ekkor az adattagonkénti értékadás módszerét használva magunknak kell kiküszöbölni a jelentkező problémát, másrészt pedig a másolás műveletének túlterhelésével (operator overloading) saját értékadó operátort (lásd III. fejezet - Objektum-orientált programozás C++ nyelven) hozhatunk létre a struktúrához.
Az adatbeviteli és -kiviteli műveletek során szintén tagonként érjük el a struktúrákat. Az alábbi példában billentyűzetről töltjük fel a zeneCD típusú struktúrát, majd pedig megjelenítjük a bevitt adatokat:
#include <iostream>
#include <string>
using namespace std;
struct zeneCD {
string eloado, cim;
int ev, ar;
};
int main() {
zeneCD cd;
// az adatok beolvasása
cout<<"Kerem a zenei CD adatait!" << endl;
cout<<"Eloado : "; getline(cin, cd.eloado);
cout<<"Cim : "; getline(cin, cd.cim);
cout<<"Megjelenes eve : "; cin>>cd.ev;
cout<<"Ar : "; cin>>cd.ar;
cin.get();
// az adatok megjelenítése
cout<<"\nA zenei CD adatai:" << endl;
cout<<"Eloado : "; cout << cd.eloado << endl;
cout<<"Cim : "; cout << cd.cim << endl;
cout<<"Megjelenes eve : "; cout << cd.ev << endl;
cout<<"Ar : "; cout << cd.ar << endl;
}
I.8.1.3. Egymásba ágyazott struktúrák
Már említettük, hogy a struktúráknak tetszőleges típusú adattagjai lehetnek. Ha egy struktúrában elhelyezünk egy vagy több struktúra adattagot, akkor ún. egymásba ágyazott struktúrákat kapunk.
Tételezzük fel, hogy személyi adatokat struktúra felhasználásával szeretnénk tárolni! A személyi adatok közül a dátumok kezelésére külön struktúrát definiálunk:
struct datum {
int ev, ho, nap;
};
struct szemely {
string nev;
datum szulinap;
};
Hozzunk létre két személyt, méghozzá úgy, hogy az egyiknél használjunk kezdőértékadást, míg a másikat tagonkénti értékadással inicializáljuk!
szemely fiver = { "Iván", {2004, 10, 2} };
szemely hallgato;
hallgato.nev = "Nagy Ákos";
hallgato.szulinap.ev = 1990;
hallgato.szulinap.ho = 10;
hallgato.szulinap.nap = 20;
A kezdőértékadás során a belső struktúrát inicializáló konstansokat nem kötelező kapcsos zárójelek közé helyezni. A hallgato struktúra adattagjait inicializáló értékadás során az első pont (.) operátorral a hallgato struktúrában elhelyezkedő szulinap struktúrára hivatkozunk, majd ezt követi a belső struktúra adattagjaira vonatkozó hivatkozás.
Ha a datum típusú struktúrát máshol nem használjuk, akkor névtelen struktúraként közvetlenül beépíthetjük a szemely struktúrába:
struct szemely {
string nev;
struct {
int ev, ho, nap;
} szulinap;
};
Bonyolultabb dinamikus adatszerkezetek (például lineáris lista) kialakításánál adott típusú elemeket kell láncba fűznünk. Az ilyen elemek általában valamilyen adatot és egy mutatót tartalmaznak. A C++ nyelv lehetővé teszi, hogy a mutatót az éppen deklarálás alatt álló struktúra típusával definiáljuk. Az ilyen struktúrákat, amelyek önmagukra mutató pointert tartalmaznak adattagként, önhivatkozó struktúráknak nevezzük. Példaként tekintsük az alábbi listaelem deklarációt!
struct listaelem {
double adattag;
listaelem *kapcsolat;
};
Ez a rekurzív deklaráció mindössze annyit tesz, hogy a kapcsolat mutatóval listaelem típusú struktúrára mutathatunk. A fenti megoldás nem ágyazza egymásba a két struktúrát, hiszen az a struktúra, amelyre a későbbiek során a mutatóval hivatkozunk, valahol máshol fog elhelyezkedni a memóriában. A C++ fordító számára a deklaráció általában azért szükséges, hogy a deklarációnak megfelelően tudjon memóriát foglalni, vagyis hogy ismerje a létrehozandó változó méretét. A fenti deklarációban a létrehozandó tároló egy mutató, amelynek mérete független a struktúra méretétől.
I.8.1.4. Struktúrák és tömbök
A programkészítés lehetőségeit nagyban megnöveli, ha a tömböket és struktúrákat együtt használjuk, egyetlen adattípusba ötvözve. Az alábbi, egyszerű megoldásokban először egydimenziós tömböt helyezünk el struktúrán belül, majd pedig struktúra típusú elemekből készítünk egydimenziós tömböt.
I.8.1.4.1. Tömb, mint struktúratag
Az alábbi példában az egész vektor (v) mellet az értékes elemek számát is tároljuk (n) az svektor struktúrában:
const int maxn = 10;
struct svektor {
int v[maxn];
int n;
};
svektor a = {{23, 7, 12}, 3};
svektor b = {{0}, maxn};
svektor c = {};
int sum=0;
for (int i=0; i<a.n; i++) {
sum += a.v[i];
}
c = a;
Az a.v[i] kifejezésben nem kell zárójelezni, mivel a két azonos elsőbbségű művelet balról jobbra haladva értékelődik ki. Vagyis először kiválasztódik az a struktúra v tagja, majd pedig az a.v tömb i-dik eleme. További érdekessége ennek a megoldásnak, a struktúrák közötti értékadás során a vektor elemei is átmásolódnak.
Az svektor típusú struktúrát dinamikusan is létrehozhatjuk. Ekkor azonban a nyíl operátorral kell kijelölni a struktúrát a memóriában.
svektor *p = new svektor; p->v[0] = 2; p->v[1] = 10; p->n = 2; delete p;
I.8.1.4.2. Struktúra, mint tömbelem
Struktúratömböt pontosan ugyanúgy kell definiálni, mint bármilyen más típusú tömböt. Példaként, az előzőekben deklarált zeneCD típust használva hozzunk létre egy 100-elemű CD-tárat, és lássuk el kezdőértékkel a CDtar első két elemét!
zeneCD CDtar[100]={{"Vivaldi","A négy évszak",2004,1002},{}};
A tömbelem struktúrák adattagjaira való hivatkozáshoz először kiválasztjuk a tömbelemet, majd pedig a struktúratagot:
CDtar[10].ar = 2004;
Amennyiben dinamikusan kívánjuk a CD-tárat létrehozni, mutatót kell használnunk az azonosításhoz:
zeneCD *pCDtar;
A struktúraelemek számára a new operátorral foglalhatunk helyet a dinamikusan kezelt memóriaterületen:
pCDtar = new zeneCD[100];
A tömbelemben tárolt struktúrára a pont operátor segítségével hivatkozhatunk:
pCDtar[10].ar = 2004;
Ha már nincs szükségünk a tömb elemeire, akkor a delete [] operátorral felszabadítjuk a lefoglalt tárterületet:
delete[] pCDtar;
Bizonyos műveletek (például a rendezés) hatékonyabban elvégezhetők, ha mutatótömbben tároljuk a dinamikusan létrehozott CD-lemezek mutatóit:
zeneCD* dCDtar[100];
A struktúrák számára az alábbi ciklus segítségével foglalhatunk helyet a dinamikusan kezelt memóriaterületen:
for (int i=0; i<100; i++) dCDtar[i] = new zeneCD;
Ekkor a tömbelemek által kijelölt struktúrákra a nyíl operátor segítségével hivatkozhatunk:
dCDtar[10]->ar = 2004;
Ha már nincs szükségünk a struktúrákra, akkor az elemeken végighaladva felszabadítjuk a lefoglalt memóriaterületeket:
for (int i = 0; i < 100; i++) delete dCDtar[i];
Az alábbi példában a dinamikusan létrehozott, adott számú CD-lemezt tartalmazó CD-tárból, kigyűjtjük az 2010 és 2012 között megjelent műveket.
#include <iostream>
#include <string>
using namespace std;
struct zeneCD {
string eloado, cim;
int ev, ar;
};
int main() {
cout<<"A CD-lemezek szama:";
int darab;
cin>>darab;
cin.ignore(80, '\n');
// Helyfoglalás ellenőrzéssel
zeneCD *pCDtar = new (nothrow) zeneCD[darab];
if (!pCDtar) {
cerr<<"\a\nNincs eleg memoria!\n";
return -1;
}
// A CD-lemezek beolvasása
for (int i=0; i<darab; i++) {
cout<<endl<<i<<". CD adatai:"<<endl;
cout<<"Eloado: "; getline(cin, pCDtar[i].eloado);
cout<<"Cim: "; getline(cin, pCDtar[i].cim);
cout<<"Ev: "; cin>>pCDtar[i].ev;
cout<<"Ar: "; cin>>pCDtar[i].ar;
cin.ignore(80, '\n');
}
// A keresett CD-k kiválogatása
int talalt = 0;
for (int i = 0; i < darab; i++) {
if (pCDtar[i].ev >=2010 && pCDtar[i].ev <= 2012) {
cout<<endl<<pCDtar[i].eloado<<endl;
cout<<pCDtar[i].cim<<endl;
cout<<pCDtar[i].ev<<endl;
talalt++;
}
}
// A keresés eredményének kijelzése
if (talalt)
cout<<"\nA talalatok szama: "<<talalt<<endl;
else
cout<<"Nincs a feltetelnek megfelelo CD!"<<endl;
// A lefoglalt terület felszabadítása
delete [] pCDtar;
}
A program interaktív, vagyis a felhasználótól várja az adatokat, és a képernyőn jeleníti meg az eredményeket. Nagyobb adatmennyiséggel való tesztelés igen fáradtságos ily módon.
Az operációs rendszerek többsége azonban lehetővé teszi, hogy a program szabványos bemenetét és kimentét fájlba irányítsuk. Az átirányításhoz egy fájlba kell begépelnünk az input adatokat, abban a formában, ahogy azt a program várja (például CDk.txt), és meg kell adnunk egy kisebb jel után a program (CDTar) parancssorában:
CDTar <CDk.txt CDTar <CDk.txt >Eredmeny.txt
A második parancssorral az eredményeket is fájlban kapjuk meg (I.25. ábra - A CDTar program adatfeldolgozása). (A Visual C++ fejlesztői környezetben az átirányítási előírásokat a Project /projekt Properties ablak, Debugging lapjának Command Arguments sorában is elhelyezhetjük.)

I.8.1.5. Egyszeresen láncolt lista kezelése
A láncolt listák legegyszerűbb formája az egyszeresen láncolt lista, amelyben elemenként egy hivatkozás található, ami a lista következő elemére mutat. Az utolsó elem esetén ez a hivatkozás nulla értékű (I.26. ábra - Egyszeresen láncolt lista).
A lista pStart mutató jelöli ki a memóriában, ezért ennek értékét mindig meg kell őriznünk. Amennyiben a pStart felülíródik, a lista elérhetetlenné válik a programunk számára.
Nézzük meg, milyen előnyökkel jár a lineáris lista használata a vektorral (egydimenziós tömbbel) összehasonlítva! A vektor mérete definiáláskor eldől, a lista mérete azonban dinamikusan növelhető, illetve csökkenthető. Ugyancsak lényeges eltérés tapasztalható az elemek beszúrása és törlése között. Míg a listában ezek a műveletek csupán néhány mutató másolását jelentik, addig a vektorban nagymennyiségű adat mozgatását igénylik. További lényeges különbség van a tárolási egység, az elem felépítésében:
A vektor elemei csak a tárolandó adatokat tartalmazzák, míg a lista esetében az adaton kívül a kapcsolati információk tárolására (mutató) is szükség van. C++ nyelven a listaelemeket a már bemutatott önhivatkozó struktúrával hozhatjuk létre.
Példaként tároljuk egész számokat lineáris listában, mely elemeinek típusa:
struct listaelem {
int adat;
listaelem *pkov;
};
Mivel a példában többször foglalunk memóriát egy új listaelem számára, ezt a műveletet a könyvünk következő részében ismertetésre kerülő függvénnyel valósítjuk meg:
listaelem *UjElem(int adat) {
listaelem * p = new (nothrow) listaelem;
assert(p);
p->adat = adat;
p->pkov = NULL;
return p;
}
A függvény sikeres esetben az új listaelem mutatójával tér vissza, és egyben inicializálja is az új elemet. Felhívjuk a figyelmet nothrow argumentumra, mely arra szolgál, hogy foglalási hiba esetén ne kapjunk hibaüzenetet, hanem a null pointerrel térjen vissza a new (I.6. szakasz - Mutatók, hivatkozások és a dinamikus memóriakezelés). Az assert () makró megszakítja a program futását, és kiírja az „Assertion failed: p, file c:\temp\lista.cpp, line 16” üzenetet, ha az argumentuma 0 értékű.
A listát létrehozáskor az alábbi tömb elemeivel töltjük fel.
int adatok [] = {2, 7, 10, 12, 23, 29, 30};
const int elemszam = sizeof(adatok)/sizeof(adatok[0]);
A lista kezelése során szükségünk van segédváltozókra, illetve a lista kezdetét jelölő pStart mutatóra:
listaelem *pStart = NULL, *pAktualis, *pElozo, *pKovetkezo;
Amikor a lista adott elemével (pAktualis) dolgozunk, szükségünk lehet a megelőző (pElozo) és a rákövetkező (pKovetkezo) elemek helyének ismeretére is. A példában a vizsgálatok elkerülése érdekében feltételezzük, hogy a lista a létrehozása után mindig létezik, tehát a pStart mutatója soha sem 0.
A lista felépítése, és az elemek feltöltése az adatok tömbből. A lista létrehozása során minden egyes elem esetén három jól elkülöníthető tevékenységet kell elvégeznünk:
helyfoglalás (ellenőrzéssel) a listaelem számára (UjElem()),
a listaelem adatainak feltöltése (UjElem()),
a listaelem hozzáfűzése a listához (a végéhez). A hozzáfűzés során az első és a nem első elemek esetén más-más lépéseket kell végrehajtanunk.
for (int index = 0; index<elemszam; index++) { pKovetkezo = UjElem(adatok[index]); if (pStart==NULL) pAktualis = pStart = pKovetkezo ; // első elem else pAktualis = pAktualis->pkov = pKovetkezo; // nem első elem } pAktualis->pkov = NULL; // a lista lezárása // a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30
A lista elemeinek megjelenítése során a pStart mutatótól indulunk, és a ciklusban mindaddig lépkedünk a következő elemre, amíg el nem érjük a lista végét jelző nullaértékű mutatót:
pAktualis = pStart;
while (pAktualis != NULL) {
cout<< pAktualis->adat << endl;
// lépés a következő elemre
pAktualis = pAktualis->pkov;
}
Gyakran használt művelet a listaelem törlése. A példában a törlendő listaelemet a sorszáma alapján azonosítjuk (A sorszámozás 0-val kezdődik a pStart által kijelölt elemtől kezdődően – a programrészlet nem alkalmas a 0. és az utolsó elem törlésére!) A törlés művelete szintén három tevékenységre tagolható:
// a 4. sorszámú elem (23) helyének meghatározása
pAktualis = pStart;
for (int index = 0; index<4; index++) {
pElozo = pAktualis;
pAktualis = pAktualis->pkov;
}
// törlés - kifűzés a láncból
pElozo->pkov = pAktualis->pkov;
// a terület felszabadítása
delete pAktualis;
// a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 29 ➝ 30
A 0. elem eltávolítása esetén a pStart mutató értékét a törlés előtt a pStart->pkov értékre kell állítanunk. Az utolsó elem törlése esetén pedig az utolsó előtti elem pkov tagjának nullázásáról is gondoskodnunk kell.
A törléssel ellentétes művelet az új elem beillesztése a listába, két meglévő elem közé. A beszúrás helyét annak az elemnek a sorszámával azonosítjuk, amely mögé az új elem kerül. A példában a 3. sorszámú elem mögé illesztünk új listaelemet:
// a megelőző, 3. sorszámú elem (12) helyének meghatározása
pAktualis = pStart;
for (int index = 0; index<3; index++)
pAktualis = pAktualis->pkov;
// területfoglalás az új elem számára
pKovetkezo = UjElem(23);
// az új elem befűzés a láncba
pKovetkezo->pkov = pAktualis->pkov;
pAktualis ->pkov = pKovetkezo;
// a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30
A fenti programrészlet az utolsó elem után is helyesen illeszti be az új listaelemet.
Szintén gyakori művelet új elem hozzáfűzése a listához (a lista végére).
// az utolsó elem megkeresése pAktualis = pStart; while (pAktualis->pkov!=NULL && (pAktualis = pAktualis->pkov)); // területfoglalás az új elem számára pKovetkezo = UjElem(80); // az új elem hozzáfűzése a listához pAktualis->pkov = pKovetkezo; // a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30 ➝ 80
Hasonlóképpen, adott értékű elemre is rákereshetünk a listában.
int adat = 29;
pAktualis = pStart;
while (pAktualis->adat!=adat && (pAktualis = pAktualis->pkov));
if (pAktualis!=NULL)
cout<<"Talalt: "<<pAktualis->adat<< endl;
else
cout<<" Nem talalt!"<<endl;
A programból való kilépés előtt fel kell szabadítanunk a dinamikusan foglalt memóriaterületeket. A lista elemeinek megszüntetése céljából végig kell mennünk a listán, ügyelve arra, hogy még az aktuális listaelem törlése előtt kiolvassuk a következő elem helyét:
pAktualis = pStart;
while (pAktualis != NULL) {
pKovetkezo = pAktualis->pkov;
delete pAktualis;
pAktualis = pKovetkezo;
}
pStart = NULL; // nincs listaelem!
I.8.2. A class osztály típus
A C++ nyelv, a könyvünkben szereplő (III. fejezet - Objektum-orientált programozás C++ nyelven) objektum-orientált programozás megvalósításához egyrészt kibővíti a C nyelv struct típusát, másrészről pedig egy új class típust vezet be. Mindkét típus alkalmas arra, hogy osztályt definiáljunk segítségükkel. (Az osztályban az adattagok mellett általában tagfüggvényeket is elhelyezünk.) Minden, amit az előző pontban az struktúrával kapcsolatban elmondtunk, érvényes az osztály típusra is, egyetlen apró, ám igen lényeges különbséggel. Ez a különbség a tagok alapértelmezés szerinti elérhetőségében jelentkezik.
A C nyelvvel való kompatibilitás megtartása érdekében a struktúra tagjainak korlátozás nélküli (nyilvános, public) elérését meg kellett tartani a C++ nyelvben. Az objektum-orientált programozás alapelveinek azonban olyan adatstruktúra felel meg, melynek tagjai alapértelmezés szerint nem érhetők el. Annak érdekében, hogy mindkét követelménynek megfeleljen a C++ nyelv, bevezették az új class kulcsszót. A class segítségével olyan „struktúrát” definiálhatunk, melynek tagjai (saját, private) alaphelyzetben nem érhetők el kívülről.
Az osztálytagok szabályozott elérése érdekében a struktúra, illetve az osztály deklarációkban public (nyilvános), private (privát) és protected (védett) kulcsszavakat helyezhetünk el. Az elérhetőség megadása nélkül (alapértelmezés szerint), a class típusú osztály tagjai kívülről nem érhetők el (private), míg a struct típusú osztály tagjai korlátozás nélkül elérhetők (public).
Az elmondottak alapján az alábbi táblázat soraiban megadott típusdefiníciók - a felhasználás szempontjából - azonosnak tekinthetők:
|
struct ido { int ora; int perc; int masodperc; };
|
class ido { public: int ora; int perc; int masodperc; }; |
|
struct ido { private: int ora; int perc; int masodperc; }; |
class ido { int ora; int perc; int masodperc; };
|
A struct vagy class típusú változók definíciójában csak akkor adhatunk meg kezdőértéket, ha az osztály típus csupa nyilvános adattaggal rendelkezik.
class ido {
public:
int ora;
int perc;
int masodperc;
};
int main() {
ido kezdet ={7, 10, 2};
}
I.8.3. A union típus
A C nyelv kidolgozásakor a takarékos memóriahasználat céljából olyan lehetőségeket is beépítettek a nyelvbe, amelyek jóval kisebb jelentőséggel bírnak, mint például a dinamikus memóriakezelés. Nézzük meg, miben áll a következő két alfejezetben bemutatott megoldások lényege!
Helyet takarítunk meg, ha ugyanazt a memóriaterületet több változó közösen használja (de nem egyidejűleg). Az ilyen változók összerendelése a union (unió - egyesítés) típussal valósítható meg.
A másik lehetőség, hogy azokat a változókat, amelyek értéke 1 bájtnál kisebb területen is elfér, egyetlen bájtban helyezzük el. Ehhez a megoldáshoz a C++ nyelv a bitmezőket biztosítja. Azt, hogy milyen (hány bites) adatok kerüljenek egymás mellé, a struct típussal rokon bitstruktúra deklarációjával adhatjuk meg.
Az unió és a bitstruktúra alkalmazásával nem lehet jelentős memória-megtakarítást elérni, viszont annál inkább romlik a programunk hordozhatósága. A memóriaigény csökkentését célzó módszerek hordozható változata a dinamikus memóriakezelés. Fontos megjegyeznünk, hogy az unió tagjainak nyilvános elérése nem korlátozható.
Napjainkban az uniót elsősorban gyors, gépfüggő adatkonverziók megvalósítására, míg a bitstruktúrát a hardver különböző elemeinek vezérlését végző parancsszavak előállítására használjuk.
A struct típussal kapcsolatban elmondott formai megoldások, kezdve a deklarációtól, a pont és nyíl operátorokon át, egészen a struktúratömbök kialakításáig, a union típusra is alkalmazhatók. Az egyetlen és egyben lényegi különbség a két típus között az adattagok elhelyezkedése között áll fenn. Míg a struktúra adattagjai a memóriában egymás után helyezkednek el, addig az unió adattagjai közös címen kezdődnek (átlapoltak). A struct típus méretét az adattagok összmérete (a kiigazításokkal korrigálva) adja, míg a union mérete megegyezik a „leghosszabb” adattagjának méretével.
Az alábbi példában egy 4-bájtos, unsigned long típusú adattagot szavanként, illetve bájtonként egyaránt elérhetünk. A konv unió adattagjainak elhelyezkedését a memóriában az I.27. ábra - Unió a memóriában szemlélteti.
#include <iostream>
using namespace std;
union konv {
unsigned long l;
struct {
unsigned short lo;
unsigned short hi;
} s;
unsigned char c[4];
};
int main()
{
konv adat = { 0xABCD1234 };
cout<<hex<<adat.s.lo<<endl; // 1234
cout<<adat.s.hi<<endl; // ABCD
for (int i=0; i<4; i++)
cout<<(int)adat.c[i]<<endl; // 34 12 CD AB
adat.c[0]++;
adat.s.hi+=2;
cout <<adat.l<<endl; // ABCF1235
}
I.8.3.1. Névtelen uniók használata
A C++ szabvány lehetővé teszi, hogy az unió definíciójában csupán adattagok szerepeljenek. Az ilyen, ún. névtelen uniók tagjai az uniót tartalmazó környezet változóiként jelennek meg. Ez a környezet lehet egy modul, egy függvény, egy struktúra vagy egy osztály.
Az alábbi példában az a és b, illetve a c és f normál változókként érhetők el, azonban az uniónak megfelelő módon, átlapoltan tárolódnak a memóriában.
static union {
long a;
double b;
};
int main() {
union {
char c[4];
float f;
};
a = 2012;
b = 1.2; // a értéke megváltozott!
f = 0;
c[0] = 1; // f értéke megváltozott!
}
Amennyiben egy struktúrába (osztályba) névtelen uniót ágyazunk, annak adattagjai a struktúra (osztály) tagjaivá válnak, bár továbbra is átlapoltak lesznek.
A következő példában bemutatjuk a struct és a union típusok együttes alkalmazását. Sokszor szükség lehet arra, hogy egy állomány rekordjaiban tárolt adatok rekordonként más-más felépítésűek legyenek. Tételezzük fel, hogy minden rekord tartalmaz egy nevet és egy értéket, amely hol szöveg, hol pedig szám! Helytakarékos megoldáshoz jutunk, ha a struktúrán belül unióba egyesítjük a két lehetséges értéket ( variáns rekord ):
#include <iostream>
using namespace std;
struct vrekord {
char tipus;
char nev[25];
union {
char cim[50];
unsigned long ID;
}; // <---- nincs tagnév!
};
int main() {
vrekord vr1={0,"BME","Budapest, Muegyetem rkpt 3-11."};
vrekord vr2={1, "Nemzeti Bank"};
vr2.ID=3751564U;
for (int i=0; i<2; i++) {
cout<<"Nev : "<<vr1.nev<<endl;
switch (vr1.tipus) {
case 1 :
cout<<"ID : "<<vr1.ID<<endl;
break;
case 0 :
cout<<"Cim : "<<vr1.cim<<endl;
break;
default :
cout<<"Hibas adattipus!"<<endl;
}
vr1 = vr2;
}
}
A program futásának eredménye:
|
Nev : BME Cim : Budapest, Muegyetem rkpt 3-11. Nev : Nemzeti Bank ID : 3751564 |
I.8.4. Bitmezők használata
Az osztályok és a struktúrák olyan tagokat is tartalmazhatnak, melyek tárolásához az egész típusoknál kisebb helyet használ a fordító. Mivel ezeknél a tagoknál bitszámban mondjuk meg a tárolási hosszt, bitmezőknek hívjuk őket. A bitmezők általános deklarációja:
típus bitmezőnév : bithossz;
A típus tetszőleges egész jellegű típus lehet (az enum is). A bitmező nevének elhagyásával névtelen bitmezőt hozunk létre, melynek célja a nem használt bitpozíciók kitöltése. A bitmező hosszát konstans kifejezéssel kell megadnunk. A bithossz maximális értékét az adott számítógépen a legnagyobb egész típus bitmérete határozza meg.
A struktúra és az osztály típusokban a bitmezők és az adattagok vegyesen is szerepelhetnek:
#include <iostream>
using namespace std;
#pragma pack(1)
struct datum {
unsigned char unnep : 1; // 0..1
unsigned char nap : 6; // 0..31
unsigned char honap : 5; // 0..16
unsigned short ev;
};
int main() {
datum ma = { 0, 2, 10, 2012 };
datum unnep = {1};
unnep.ev = 2012;
unnep.honap = 12;
unnep.nap = 25;
}
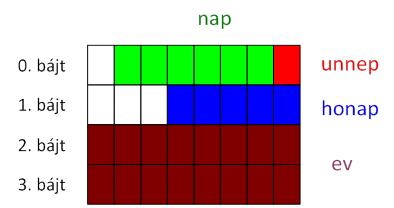
Ha a bitstruktúra deklarációjában nem adunk nevet a bitmezőnek, akkor a megadott bithosszúságú területet nem tudjuk elérni (hézagpótló bitek). Amennyiben a névtelen bitmezők hosszát 0-nak adjuk meg, akkor az ezt követő adattagot (vagy bitmezőt) int határra igazítja a fordítóprogram.
Az alábbi példában az RS232 portok vonalvezérlő regiszterének (LCR) elérését tesszük kényelmessé bitmezők segítségével:
#include <iostream>
#include <conio.h>
using namespace std;
union LCR {
struct {
unsigned char adathoosz : 2;
unsigned char stopbitek : 1;
unsigned char paritas : 3;
unsigned char : 2;
} bsLCR;
unsigned char byLCR;
};
enum RS232port {eCOM1=0x3f8, eCOM2=0x2f8 };
int main() {
LCR reg = {};
reg.bsLCR.adathoosz = 3; // 8 adatbit
reg.bsLCR.stopbitek = 0; // 1 stopbit
reg.bsLCR.paritas = 0; // nincs paritás
outport(eCOM1+3, reg.byLCR);
}
A már megismert bitenkénti operátorok segítségével szintén elvégezhetők a szükséges műveletek, azonban a bitmezők használatával strukturáltabb kódot kapunk.
A fejezet végén felhívjuk a figyelmet a bitmezők használatának hátrányaira:
A keletkező forráskód nem hordozható, hiszen a különböző rendszerekben a bitek elhelyezkedése a bájtokban, a szavakban eltérő lehet.
A bitmezők címe nem kérdezhető le (&), hiszen nem biztos, hogy bájthatáron helyezkednek el.
Amennyiben a bitmezőkkel közös tárolási egységben több változót is elhelyezünk, a fordító kiegészítő kódot generál a változók kezelésére (lassul a program futása, és nő a kód mérete.)
II. fejezet - Moduláris programozás C++ nyelven
- II.1. Függvények - alapismeretek
- II.1.1. Függvények definíciója, hívása és deklarációja
- II.1.2. Függvények visszatérési értéke
- II.1.3. A függvények paraméterezése
- II.1.3.1. A paraméterátadás módjai
- II.1.3.2. Különböző típusú paraméterek használata
- II.1.3.2.1. Aritmetikai típusú paraméterek
- II.1.3.2.2. Felhasználói típusú paraméterek
- II.1.3.2.3. Tömbök átadása függvénynek
- II.1.3.2.4. Sztring argumentumok
- II.1.3.2.5. A függvény, mint argumentum
- II.1.3.2.6. Alapértelmezés szerinti (default) argumentumok
- II.1.3.2.7. Változó hosszúságú argumentumlista
- II.1.3.2.8. A main() függvény paraméterei és visszatérési értéke
- II.1.4. Programozás függvényekkel
- II.2. A függvényekről magasabb szinten
- II.3. Névterek és tárolási osztályok
- II.3.1. A változók tárolási osztályai
- II.3.2. A függvények tárolási osztályai
- II.3.3. Több modulból felépülő C++ programok
- II.3.4. Névterek
- II.4. A C++ előfeldolgozó utasításai
A C++ nyelv különböző programozási technikákat támogat. Könyvünk előző részében a strukturált programozás került előtérbe, melynek egyik alapelve szerint a programok háromféle építőelemből állnak: utasítássorok (ezek tagjait a végrehajtás sorrendjében adjuk meg), döntési szerkezetek (if, switch) és ismétlődő részek (while, for, do). Mint látható, ebből a felsorolásból a goto utasítás teljesen hiányzik, ennek használatát kerüljük.
Ugyancsak a strukturált programozás eszköztárába tartozik a felülről-lefelé haladó (top-down) tervezés, melynek lényege, hogy a programozási feladat megoldása során egyre kisebb részekre osztjuk a feladatot, egészen addig haladva, míg jól kézben tartható, tesztelhető programelemekig nem jutunk. A C/C++ nyelvekben a legkisebb, önálló funkcionalitással rendelkező programstruktúra a függvény .
Amennyiben az elkészült függvényt, vagy a rokon függvények csoportját külön modulban (forrásfájlban) helyezzük el, eljutunk a moduláris programozás hoz. A modulok önállóan fordíthatók, tesztelhetők, és akár más projektekbe is átvihetők. A (forrásnyelvű vagy lefordított) modulok tartalmát interfészek (esetünkben fejállományok) segítségével tesszük elérhetővé más modulok számára. A modulok bizonyos részeit pedig elzárjuk a külvilág elől (data hiding). A kész modulokból (komponensekből) való programépítéshez is ad segítséget a strukturált programozás, az alulról-felfelé való (bottom-up) tervezéssel.
A következő fejezetekben a moduláris és a procedurális programozás C++ nyelven való megvalósításával ismertetjük meg az Olvasót. Procedurális programozásról beszélünk, ha egy feladat megoldását egymástól többé-kevésbé független alprogramokból (függvényekből) építjük fel. Ezek az alprogramok a főprogramból (main()) kiindulva egymást hívják, és paramétereken keresztül kommunikálnak. A procedurális programozás jól ötvözhető a strukturált és a moduláris programozás eszközeivel.
II.1. Függvények - alapismeretek
A függvény a C++ program olyan névvel ellátott egysége (alprogram), amely a program más részeiből annyiszor hívható, ahányszor csak szükség van a függvényben definiált tevékenységre. A hagyományos C++ program kisméretű, jól kézben tartható függvényekből épül fel. A lefordított függvényeket könyvtárakba rendezhetjük, amelyekből a szerkesztő program a hivatkozott függvények kódját beépíti a programunkba.
A függvények hatékony felhasználása érdekében a függvény bizonyos belső változóinak a függvényhívás során adunk értéket. Ezek a paraméterek nek hívott tárolókat függvény definíciójában a függvény neve után zárójelben kell deklarálnunk. A függvény hívásánál (aktiválásánál) pedig hasonló formában kell felsorolnunk az egyes paramétereknek átadni kívánt értékeket, az argumentumokat.
A függvényhívás során az argumentumok (amennyiben vannak) átkerülnek a hívott függvényhez, és a vezérlés a hívó függvénytől átkerül az aktivizált függvényhez. A függvényben megvalósított algoritmus végrehajtását követően egy return utasítással, illetve a függvény fizikai végének elérésével a hívott függvény visszatér a hívás helyére. A return utasításban szereplő kifejezés értéke, mint függvényérték (visszatérési érték) jelenik meg a függvényhívás kifejezés kiértékelésének eredményeként.
II.1.1. Függvények definíciója, hívása és deklarációja
A C++ szabványos könyvtára egy sor előre elkészített függvényt bocsájt a rendelkezésünkre. Az ilyen függvényeket csupán deklarálnunk kell a felhasználást megelőzően. Ebben hatékony segítséget nyújt a megfelelő fejállomány beépítése a programunkba. Az alábbi táblázatban összeszedtünk néhány gyakran használt függvényt és a hozzájuk tartozó include fájlokat:
|
függvény |
fejállomány |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A könyvtári függvényekkel ellentétben a saját késztésű függvényeket mindig definiálni is kell. A definíció, amit csak egyszer lehet megadni, a C++ programon belül bárhol elhelyezkedhet. Amennyiben a függvény definíciója megelőzi a felhasználás (hívás) helyét akkor, ez egyben a függvény deklarációja is.
A függvény-definíció általános formájában a 〈 〉 jelek az opcionális részeket jelölik. A függvény fejsorában elhelyezkedő paraméter-deklarációs lista az egyes paramétereket vesszővel elválasztva tartalmazza, és minden egyes paraméter előtt szerepel a típusa.

A függvények definíciójában a visszatérési típus előtt megadhatjuk a tárolási osztályt is. Függvények esetén az alapértelmezés szerinti tárolási osztály az extern, ami azt jelöli, hogy a függvény más modulból is elérhető. Amennyiben a függvény elérhetőségét az adott modulra kívánjuk korlátozni, a static tárolási osztályt kell használnunk. (A paraméterek deklarációjában csak a register tárolási osztály specifikálható). Ha a függvényt saját névterületen szeretnénk elhelyezni, úgy a függvény definícióját, illetve a prototípusát a kiválasztott névterület (namespace) blokkjába kell vinnünk. (A tárolási osztályok és a névterületek részletes ismertetését későbbi fejezetek tartalmazzák.)
Példaként készítsük el az első n pozitív egész szám összegét meghatározó függvényt! Az isum() függvény egy int típusú értéket vár, és egy int típusú eredményt ad vissza.
int isum(int n)
{
int s = 0;
for (int i=1; i<=n; i++)
s += i;
return s;
}
Tételezzük fel, hogy a forrásfájlban az isum() függvény definíciója után helyezkedik el a main () függvény, amelyből hívjuk az isum() függvényt:
int main()
{
cout << isum(10) << endl;
int s = isum(7) * isum(10) + 2;
}
A függvényhívás általános formájában a függvény nevét zárójelben követi az argumentumok veszővel tagolt listája. A hívás lépéseit a II.2. ábra - A függvényhívás menete követhetjük nyomon.
függvénynév (〈argumentum 1 , argumentum 2 , … argumentum n 〉)
A zárójelpárt akkor is meg kell adnunk, ha nincs paramétere a függvénynek. A függvényhívást bárhol szerepeltethetjük, ahol kifejezés állhat a programban.
Az argumentumok kiértékelésének sorrendjét nem definiálja a C++ nyelv. Egyetlen dolgot garantál mindössze a függvényhívás operátora, hogy mire a vezérlés átadódik a hívott függvénynek, az argumentumlista teljes kiértékelése (a mellékhatásokkal együtt) végbemegy.
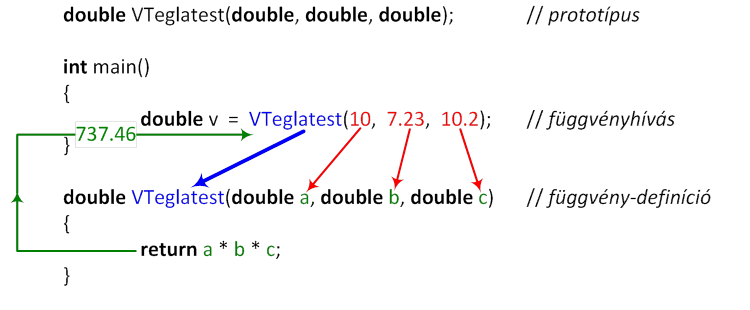
A szokásos C++ szabályok szerint a függvényeket deklarálni kell a függvényhívás helyéig. A függvény definíciója egyben a függvény deklarációja is lehet. Felvetődik a kérdés, hogyan tudjuk biztosítani, hogy a hívott függvény mindig megelőzze a hívó függvény. Természetesen ez nem biztosítható, gondoljunk csak az egymást hívó függvényekre! Amennyiben a fenti példában felcseréljük a main () és az isum() függvényeket a forrásfájlban, mindaddig fordítási hibát kapunk, míg el nem helyezzük a függvény teljes leírását tartalmazó prototípus t a hívás előtt:
int isum(int); // prototípus
int main() {
cout << isum(10) << endl;
int s = isum(7) * isum(10) + 2;
}
int isum(int n)
{
int s = 0;
for (int i=1; i<=n; i++)
s += i;
return s;
}
A függvény teljes deklarációja ( prototípusa ) tartalmazza a függvény nevét, típusát valamint információt szolgáltat a paraméterek számáról és típusáról:
visszatérési típus függvénynév (〈paraméter-deklarációs lista〉);
visszatérési típus függvénynév (〈típuslista〉);
A C++ fordító csak a prototípus ismeretében fordítja le a függvényhívást:
a paraméterlista és az argumentumlista összevetésével ellenőrzi a paraméterek számának és típusainak összeférhetőségét,
az argumentumokat a prototípusban definiált típusoknak megfelelően konvertálja, nem pedig az automatikus konverziók szerint.
(Megjegyezzük, hogy a függvény definíciója helyettesíti a prototípust.) Az esetek többségében prototípusként a függvényfejet használjuk pontosvesszővel lezárva. A prototípusban nincs jelentősége a paraméterneveknek, elhagyhatjuk őket, vagy bármilyen nevet alkalmazhatunk. Az alábbi prototípusok a fordító szempontjából teljesen azonosak:
int isum(int); int isum(int n); int isum(int sok);
Valamely függvény prototípusa többször is szerepelhet a programban, azonban a paraméternevektől eltekintve azonosaknak kell lenniük.
A C++ nyelv lehetővé teszi, hogy a legalább egy paramétert tartalmazó paraméterlistát három pont (...) zárja. Az így definiált függvény legalább egy, de különben tetszőleges számú és típusú argumentummal hívható. Példaként tekintsük a sscanf () függvény prototípusát!
int sscanf ( const char * str, const char * format, ...);
Felhívjuk a figyelmet arra, hogy a paraméterrel nem rendelkező függvények prototípusát eltérő módon értelmezi a C és a C++ nyelv:
|
deklaráció |
C értelmezés |
C++ értelmezés |
|---|---|---|
|
típus fv(); |
típus fv(...); |
típus fv(void); |
|
típus fv(...); |
típus fv(...); |
típus fv(...); |
|
típus fv(void); |
típus fv(void); |
típus fv(void); |
A kivételeket tárgyaló (I.5. szakasz - Kivételkezelés) fejezetben volt róla szó, hogy a függvények fejsorában engedélyezhetjük, vagy tilthatjuk a kivételek továbbítását a hívó függvény felé. A throw kulcsszó felhasználásával a függvénydefiníció a következőképpen módosul:
visszatérési típus függvénynév (〈paraméterlista〉) 〈throw(〈típuslista〉)〉
{
〈lokális definíciók és deklarációk〉
〈utasítások〉
return 〈kifejezés〉;
}
A definíciónak megfelelő prototípusban is fel kell tüntetni a throw kiegészítést:
visszatérési típus függvénynév (〈paraméterlista〉) 〈throw(〈típuslista〉)〉;
Nézzünk néhány prototípust a továbbított kivételek típusának feltüntetésével:
int fv() throw(int, const char*); // csak int és const char * int fv(); // minden int fv() throw(); // egyetlen egyet sem
II.1.2. Függvények visszatérési értéke
A függvények definíciójában/deklarációjában szereplő visszatérési típus határozza meg a függvényérték típusát, amely tetszőleges C++ típus lehet, a tömbtípus és a függvénytípus kivételével. A függvények nem adhatnak vissza volatile vagy const típusminősítővel ellátott adatokat, azonban ilyen adatra mutató pointert vagy hivatkozó referenciát igen.
A függvény a return utasítás feldolgozását követően visszatér a hívóhoz, és függvényértékként megjelenik az utasításban szereplő kifejezés értéke, melynek típusa a visszatérési típus:
return kifejezés;
A függvényen belül tetszőleges számú return utasítás elhelyezhető, azonban a strukturált programozás elveinek megfelelően törekednünk kell egyetlen kilépési pont használatára.
Az alábbi prímszámellenőrző függvényből a három return utasítással, három ponton is kiléphetünk, ami nehezen áttekinthető programszerkezetet eredményez.
bool Prime(unsigned n)
{
if (n<2) // 0, 1
return false;
else {
unsigned hatar = (unsigned)sqrt(1.0*n);
for (unsigned d=2; d<=hatar; d++)
if ((n % d) == 0)
return false;
}
return true;
}
Egy segédváltozó (eredmeny) bevezetésével elkésztett megoldás sokkal áttekinthetőbb kódot tartalmaz:
bool Prime(unsigned n)
{
bool eredmeny = true;
if (n<2) // 0, 1
eredmeny = false;
else {
unsigned hatar = (unsigned)sqrt(1.0*n);
for (unsigned d=2; d<=hatar && eredmeny; d++)
if ((n % d) == 0)
eredmeny = false;
}
return eredmeny;
}
A void típus felhasználásával olyan függvényeket is készíthetünk, amelyek nem adnak vissza értéket. (Más programozási nyelveken ezeket az alprogramokat eljárásoknak nevezzük.) Ebben az esetben a függvényből való visszatérésre a return utasítás kifejezés nélküli alakját használhatjuk. Ebben az esetben azonban nem kötelező a return használata, a void függvények gyakran a függvény törzsét záró kapcsos zárójel elérésével térnek vissza.
Az alábbi függvény a tökéletes számokat jeleníti meg egy megadott intervallumon belül. (Valamely pozitív egész szám tökéletes, ha a nála kisebb pozitív osztóinak összege egyenlő magával a számmal. A legkisebb tökéletes szám a 6, mert 6 = 1+2+3, de tökéletes szám a 28 is, mert 28 = 1+2+4+7+14.)
void TokeletesSzamok(int tol, int ig)
{
int osszeg = 0;
for(int i=tol; i<=ig; i++) {
osszeg = 0;
for(int j=1; j<i; j++) {
if(i%j == 0)
osszeg += j;
}
if(osszeg == i)
cout<< i <<endl;
}
}
A függvények mutatóval és referenciával is visszatérhetnek, azonban nem szabad lokális változó címét, illetve magát a változót visszaadni, hiszen az megszűnik a függvényből való kilépést követően. Nézzünk néhány helyes megoldást!
#include <cassert>
using namespace std;
double * Foglalas(int meret) {
double *p = new (nothrow) double[meret];
assert(p);
return p;
}
int & DinInt() {
int *p = new (nothrow) int;
assert(p);
return *p;
}
int main() {
double *pd = Foglalas(2012);
pd[2] = 8;
delete []pd;
int &x = DinInt();
x = 10;
delete &x;
}
A Foglalas() függvény megadott elemszámú, double típusú tömböt foglal, és visszatér a lefoglalt dinamikus tömb kezdőcímével. A DinInt() függvény mindössze egyetlen egész változónak foglal tárterületet a halmon, és visszaadja a dinamikus változó referenciáját. Ezt az értéket egy hivatkozás típusú változóba töltve, a dinamikus változót a * operátor nélkül érhetjük el.
II.1.3. A függvények paraméterezése
A függvények készítése során arra törekszünk, hogy minél szélesebb körben használjuk a függvényben megvalósított algoritmust. Ehhez arra van szükség, hogy az algoritmus bemenő értékeit (paramétereit) a függvény hívásakor adjuk meg. Az alábbi paraméter nélküli függvény egy üdvözlést jelenít meg:
void Udvozles(void) {
cout << "Üdvözöllek dícső lovag..." << endl;
}
A függvény minden hívásakor ugyanazt a szöveget látjuk a képernyőn:
Udvozles();
Mit kell tennünk ahhoz, hogy például a napszaknak megfelelően üdvözöljük a felhasználót? A választ a függvény paraméterezése adja:
#include <iostream>
#include <string>
using namespace std;
void Udvozles(string udv) {
cout << udv << endl;
}
int main() {
Udvozles("Jó reggelt");
Udvozles("Good evening!");
}
A C++ függvény-definícióban szereplő paraméterlistában minden paraméter előtt ott áll a paraméter típusa, semmilyen összevonás sem lehetséges. A deklarált paramétereket a függvényen belül a függvény lokális változóiként használhatjuk, azonban a függvényen kívülről csak a paraméterátadás során érhetők el. A paraméterek típusa a skalár (bool, char, wchar_t, short, int, long, long long, float, double, felsorolási, referencia és mutató), valamint a struktúra, unió, osztály és tömb típusok közül kerülhet ki.
A különböző típusú paraméterek szemléltetésére készítsük el egy polinom helyettesítési értékét a Horner-elrendezés alapján számító függvényt!
a polinom általános alakja: 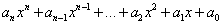
a Horner-elrendezés: 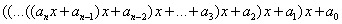
A függvény bemenő paraméterei az x értéke, a polinom fokszáma és a polinom együtthatóinak (fokszám+1 elemű) tömbje. (A const típusminősítő megakadályozza a tömb elemeinek módosítását a függvényen belül.)
double Polinom(double x, int n, const double c[]) {
double y = 0;
for (int i = n; i > 0; i--)
y = (y + c[i]) * x;
return y + c[0];
}
int main(){
const int fok = 3;
double egyutthatok[fok + 1] = { 5, 2, 3, 1};
cout << Polinom(2, fok, egyutthatok)<< endl; // 29
}
II.1.3.1. A paraméterátadás módjai
A C++ nyelvben a paramétereket - az átadásuk módja szerint - két csoportra oszthatjuk. Megkülönböztetünk érték szerint átadott, bemenő paramétereket és hivatkozással átadott (változó) paramétereket.
II.1.3.1.1. Érték szerinti paraméterátadás
Az érték szerinti paraméterátadás során az argumentumok értéke adódik át a hívott függvénynek. A függvény paraméterei az átadott értékekkel inicializálódnak, és ezzel meg is szűnik a kapcsolat az argumentumok és a paraméterek között. Ennek következtében a paramétereken végzett műveleteknek nincs hatása a híváskor megadott argumentumokra.
Az argumentumok csak olyan kifejezések lehetnek, melyek típusai konvertálhatók a hívott függvény megfelelő paramétereinek típusára.
Az eszam() függvény az e szám közelítő értékét szolgáltatja a
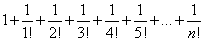
sor első n+1 elemének összegzésével:
double eszam(int n) {
double f = 1;
double esor = 1;
for (int i=2; i<=n; i++) {
esor += 1.0 / f;
f *= i;
}
return esor;
}
Az eszam() függvény tetszőleges numerikus kifejezéssel hívhatjuk:
int main(){
long x =1000;
cout << eszam(x)<< endl;
cout << eszam(123) << endl;
cout << eszam(x + 12.34) << endl;
cout << eszam(&x) << endl; // hiba
}
Az első híváskor a long típusú x változó értéke int típusúvá alakítva adódik át a függvénynek. A második esetben az int típusú konstans lesz a paraméter értéke. A harmadik hívás argumentuma egy double típusú kifejezés, melynek értéke egésszé alakítva adódik át. Ez az átalakítás adatvesztéssel járhat, ezért erre a fordító figyelmeztet. Az utolsó eset kakukktojásként szerepel a hívások listájában, mivel ebben az esetben az x változó címének számmá alakítását visszautasítja a fordító. Mivel a hasonló típus-átalakítások futás közbeni hibához vezethetnek, az átalakítást külön kérnünk kell:
cout << eszam((int)&x) << endl;
Amennyiben függvényen belül szeretnénk módosítani egy külső változó értékét, a változó címét kell argumentumként átadni, és a címet mutató típusú paraméterben kell fogadni. Példaként tekintsük a klasszikusnak számító, változók értékét felcserélő függvényt:
void pcsere(double *p, double *q) {
double c = *p;
*p = *q;
*q = c;
}
int main(){
double a = 12, b =23;
pcsere(&a, &b);
cout << a << ", " << b<< endl; // 23, 12
}
Ebben az esetben is szerelhetnek kifejezések argumentumként, azonban csak balérték kifejezések. Megjegyezzük, hogy a tömbök a kezdőcímükkel adódnak át a függvényeknek.
A const típusminősítő paraméterlistában való elhelyezésével korlátozhatjuk a mutató által kijelölt terület módosítását ( const double *p), illetve a mutató értékének megváltoztatását ( double * const p) a függvényen belül.
II.1.3.1.2. Referencia szerinti paraméterátadás
Az érték szerint átadott paramétereket a függvény lokális változóiként használjuk. Ezzel szemben a referencia paraméterek nem önálló változók, csupán alternatív nevei a híváskor megadott argumentumoknak.
A referencia paramétereket a függvény fejlécében a típus és a paraméternév közé helyezett & karakterrel jelöljük, híváskor pedig a paraméterekkel azonos típusú változókat használunk argumentumként. Referenciával átadott paraméterekkel a változók értékét felcserélő függvény sokkal egyszerűbb formát ölt:
void rcsere(double & a, double & b) {
double c = a;
a = b;
b = c;
}
int main(){
double x = 12, y =23;
rcsere(x, y);
cout << x << ", " << y << endl; // 23, 12
}
A referencia paraméter értéke (jobbértéke) és címe (balértéke) megegyezik a hivatkozott változó értékével és címével, így minden szempontból helyettesíti azt.
Megjegyezzük, hogy a pcsere() és rcsere() függvények lefordított kódja Visual Studio rendszerben teljes mértékben megegyezik. Ezért semmilyen hatékonysági megfontolás nem indokolja a pcsere() használatát a C++ nyelven készített programokban.
Mindkét féle paraméterátadás során a paramétereknek a veremben foglal helyet a fordító. Érték paramétereknél a lefoglalt terület mérete függ a paraméter típusától, tehát igen nagy is lehet, míg referencia paraméterek esetén mindig az adott rendszerben használt mutatóméret a mérvadó. Egy nagyobb struktúra vagy objektum esetén a megnövekedett memóriaigény mellett a hívásidő növekedése sem elhanyagolható.
Az alábbi példában egy struktúrát adunk át a függvénynek hivatkozással, azonban szeretnénk megakadályozni a struktúra megváltoztatását függvényen belül. Erre a célra a leghatékonyabb megoldás a konstans referencia típusú paraméter alkalmazása:
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
struct svektor {
int meret;
int a[1000];
};
void MinMax(const svektor & sv, int & mi, int & ma) {
mi = ma = sv.a[0];
for (int i=1; i<sv.meret; i++) {
if (sv.a[i]>ma)
ma = sv.a[i];
if (sv.a[i]<mi)
mi = sv.a[i];
}
}
int main() {
const int maxn = 1000;
srand(unsigned(time(0)));
svektor v;
v.meret=maxn;
for (int i=0; i<maxn; i++) {
v.a[i]=rand() % 102 + (rand() % 2012);
}
int min, max;
MinMax(v, min, max);
cout << min << endl;
cout << max << endl;
}
Megjegyezzük, hogy a fenti megoldásban ugyan gyorsabb a MinMax() függvény hívása, és kisebb helyre van szükség a veremben, azonban a paraméterek függvényen belüli elérése hatékonyabb az érték típusú paraméterek használata eseten.
A konstans referencia paraméterek teljes mértékben helyettesítik a konstans érték paramétereket, így tetszőleges kifejezést (nemcsak változót) használhatunk argumentumként. A két szám legnagyobb közös osztóját meghatározó példa szemlélteti ezt:
int Lnko(const int & a, const int & b ) {
int min = a<b ? a : b, lnko = 0;
for (int n=min; n>0; n--)
if ( (a % n == 0) && (b % n) == 0) {
lnko = n;
break;
}
return lnko;
}
int main() {
cout << Lnko(24, 32) <<endl; // 8
}
II.1.3.2. Különböző típusú paraméterek használata
A következő alfejezetekben különböző típusok esetén, példák segítségével mélyítjük el a paraméterek használatával kapcsolatos ismereteket. Az alfejezet példáiban a függvények definícióját - kipontozott sor után - követi a hívás bemutatása. Természetesen bonyolultabb esetekben teljes programlistát is közlünk.
II.1.3.2.1. Aritmetikai típusú paraméterek
A bool, char, wchar_t, int, enum, float és double típusokkal paramétereket deklarálhatunk, illetve függvények típusaként is megadhatjuk őket.
Általában rövid megfontolásra van szükség ahhoz, hogy eldöntsük, milyen paramétereket használjunk, és mi legyen a függvény értéke. Ha egy függvény nem ad vissza semmilyen értéket, csupán elvégez egy tevékenységet, akkor void visszatérési típust és érték paramétereket alkalmazunk:
void KiirF(double adat, int mezo, int pontossag) {
cout.width(mezo);
cout.precision(pontossag);
cout << fixed << adat << endl;
}
...
KiirF(123.456789, 10, 4); // 123.4568
Ugyancsak egyszerű a dolgunk, ha egy függvény a bemenő értékekből egyetlen értéket állít elő:
long Szorzat(int a, int b) {
return long(a) * b;
}
...
cout << Szorzat(12, 23) <<endl; // 276
Ha azonban egy függvénytől több értéket szeretnénk visszakapni, akkor referencia (vagy pointer) paraméterekre építjük a megoldást. Ekkor a függvényérték void vagy pedig a működés eredményességét jelző típusú, például bool. Az alábbi Kocka() függvény az élhossz felhasználásával kiszámítja a kocka felszínét, térfogatát és testátlójának hosszát:
void Kocka(double a, double & felszin, double & terfogat,
double & atlo) {
felszin = 6 * a * a;
terfogat = a * a * a;
atlo = a * sqrt(3.0);
}
...
double f, v, d;
Kocka(10, f, v, d);
II.1.3.2.2. Felhasználói típusú paraméterek
A felhasználói típusok (struct, class, union) paraméterlistában, illetve függvényértékként való felhasználására az aritmetikai típusoknál bemutatott megoldások érvényesek. Ennek alapja, hogy a C++ nyelv definiálja az azonos típusú objektumok, illetve uniók közötti értékadást.
A felhasználói típusú argumentumokat érték szerint, referenciával, illetve mutató segítségével egyaránt átadhatjuk a függvényeknek. A szabványos C++ nyelvben a függvény visszatérési értéke felhasználói típusú is lehet. A lehetőségek közül általában ki kell választanunk az adott feladathoz legjobban illeszkedő megoldást.
Példaként tekintsük a komplex számok tárolására alkalmas struktúrát!
struct komplex {
double re, im;
};
Készítsünk függvényt két komplex szám összeadására, amelyben a tagok és az eredmény tárolására szolgáló struktúrát mutatójuk segítségével adjuk át a függvénynek (KOsszeg1())! Mivel a bemenő paramétereket nem kívánjuk a függvényen belül megváltoztatni, const típusminősítőt használunk.
void KOsszeg1(const komplex*pa,const komplex*pb,komplex *pc){
pc->re = pa->re + pb->re;
pc->im = pa->im + pb->im;
}
A második függvény visszatérési értékként szolgáltatja a két érték szerint átadott komplex szám összegét (KOsszeg2()). Az összegzést egy lokális struktúrában végezzük el, melynek csupán értékét adjuk vissza a return utasítással.
komplex KOsszeg2(komplex a, komplex b) {
komplex c;
c.re = a.re + b.re;
c.im = a.im + b.im;
return c;
}
A második megoldás természetesen sokkal biztonságosabb, és sokkal jobban kifejezi a művelet lényegét, mint az első. Minden más szempontból (memóriaigény, sebesség) az első függvényt kell választanunk. A referenciatípus használatával azonban olyan megoldáshoz juthatunk, amely magában hordozza a KOsszeg2() függvény előnyös tulajdonságait, azonban az KOsszeg1() függvénnyel is felveszi a versenyt (memóriaigény, sebesség).
komplex KOsszeg3(const komplex & a, const komplex & b) {
komplex c;
c.re = a.re + b.re;
c.im = a.im + b.im;
return c;
}
A három különböző megoldáshoz két különböző hívási mód tartozik. Az alábbi main() függvény mindhárom összegző függvény hívását tartalmazza:
int main() {
komplex c1 = {10, 2}, c2 = {7, 12}, c3;
KOsszeg1(&c1, &c2, &c3); // mindhárom argumentum pointer
c3 = KOsszeg2(c1, c2); // két struktúra az argumentum
// két struktúra referencia az argumentum
c3 = KOsszeg3(c1, c2);
}
II.1.3.2.3. Tömbök átadása függvénynek
Az alábbiakban áttekintjük, hogy milyen lehetőségeket biztosít a C++ nyelv tömbök függvénynek való átadására. Már szóltunk róla, hogy tömböt nem lehet érték szerint (a teljes tömb átmásolásával) függvénynek átadni, illetve függvényértékként megkapni. Sőt különbség van az egydimenziós (vektorok) és a többdimenziós tömbök argumentumként való átadása között is.
Egydimenziós tömbök (vektorok) függvényargumentumként való megadása esetén a tömb első elemére mutató pointer adódik át. Ebből következik, hogy a függvényen belül a vektor elemein végrehajtott változtatások a függvényből való visszatérés után is érvényben maradnak.
A vektor típusú paramétert mutatóként , illetve az üres indexelés operátorával egyaránt deklarálhatjuk. Mivel a C++ tömbök semmilyen információt sem tartalmaznak az elemek számáról, ezt az adatot külön paraméterben kell átadnunk. A függvényen belül az elemek eléréséhez a már megismert két módszer (index, pointer) bármelyikét alkalmazhatjuk. Egy int vektor első n elemének összegét meghatározó függvényt többféleképpen is megfogalmazhatjuk. A vektor paraméterében a const típusminősítővel, azt biztosítjuk, hogy a függvényen belül a vektor elemeit nem lehet megváltoztatni.
long VektorOsszeg1 (const int vektor[], int n) {
long osszeg = 0;
for (int i = 0; i < n; i++) {
osszeg+=vektor[i]; // vagy osszeg+=*(vektor+i);
}
return osszeg;
}
...
int v[7] = { 10, 2, 11, 30, 12, 7, 23};
cout <<VektorOsszeg1(v, 7)<< endl; // 95
cout <<VektorOsszeg1(v, 3)<< endl; // 23
A fentivel teljes mértékben megegyező megoldást kapunk, ha mutatóban fogadjuk a vektor kezdőcímét. (A második const minősítővel biztosítjuk, hogy ne lehessen a mutató értéket módosítani.)
long VektorOsszeg2 (const int * const vektor, int n) {
long osszeg = 0;
for (int i = 0; i < n; i++) {
osszeg+=vektor[i]; // vagy osszeg+=*(vektor+i);
}
return osszeg;
}
Amennyiben módosítanunk kell az átadott vektor elemeit, például rendezni, az első const típusminősítőt el kell hagynunk:
void Rendez(double v[], int n) {
double temp;
for (int i = 0; i < n-1; i++)
for (int j=i+1; j<n; j++)
if (v[i]>v[j]) {
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
}
int main() {
const int meret=7;
double v[meret]={10.2, 2.10, 11, 30, 12.23, 7.29, 23.};
Rendez(v, meret);
for (int i = 0; i < meret; i++)
cout << v[i]<< '\t';
cout << endl;
}
Az egydimenziós tömböket referenciával is átadhatjuk, azonban ekkor rögzítenünk kell a feldolgozni kívánt vektor méretét.
long VektorOsszeg3 (const int (&vektor)[6]) {
long osszeg = 0;
for (int i = 0; i < 6; i++) {
osszeg+=vektor[i]; // vagy osszeg+=*(vektor+i);
}
return osszeg;
}
...
int v[6] = { 10, 2, 11, 30, 12, 7};
cout << VektorOsszeg3(v) << endl;
A kétdimenziós tömb argumentumok bemutatása során a kétdimenziós tömb elnevezés alatt csak a fordító által (statikusan) létrehozott tömböket értjük:
int m[2][3];
A tömb elemeire való hivatkozás (m[i][j]) mindig felírható a *(( int *)m+(i*3)+j) formában (ezt teszik a fordítók is). Ebből a kifejezésből jól látható, hogy a kétdimenziós tömb második dimenziója (3) alapvető fontossággal bír a fordító számára, míg a sorok száma tetszőleges lehet.
Célunk olyan függvény készítése, amely tetszőleges méretű, kétdimenziós egész tömb elemeit mátrixos formában megjeleníti. Első lépésként írjuk meg a függvény 2x3-as tömbök megjelenítésére alkalmas változatát!
void PrintMatrix23(const int matrix[2][3]) {
for (int i=0; i<2; i++) {
for (int j=0; j<3; j++)
cout <<matrix[i][j] <<'\t';
cout<<endl;
}
}
...
int m[2][3] = { {10, 2, 12}, {23, 7, 29} };
PrintMatrix23(m);
10 2 12 23 7 29 |
A kétdimenziós tömb is a terület kezdőcímét kijelölő mutatóként adódik át a függvénynek. A fordító az elemek elérése során kihasználja, hogy a sorok 3 elemet tartalmaznak. Ennek figyelembevételével a fenti függvény egyszerűen átalakítható tetszőleges nx3-as tömb kiírására alkalmas alprogrammá, csak a sorok számát kell átadni második argumentumként:
void PrintMatrixN3(const int matrix[][3], int n) {
for (int i=0; i<n; i++) {
for (int j=0; j<3; j++)
cout <<matrix[i][j] <<'\t';
cout<<endl;
}
}
...
int m[2][3] = { {10, 2, 12}, {23, 7, 29} };
PrintMatrixN3(m, 2);
cout << endl;
int m2[3][3] = { {1}, {0, 1}, {0, 0, 1} };
PrintMatrixN3(m2, 3);
10 2 12 23 7 29 1 0 0 0 1 0 0 0 1 |
Arra azonban nincs lehetőség, hogy a második dimenziót is elhagyjuk, hiszen akkor a fordító nem képes a tömb sorait azonosítani. Egyetlen dolgot tehetünk az általános megoldás megvalósításának érdekében, hogy a fenti kifejezés felhasználásával átvesszük a tömbterület elérésének feladatát a fordítótól:
void PrintMatrixNM(const void *pm, int n, int m) {
for (int i=0; i<n; i++) {
for (int j=0; j<m; j++)
cout <<*((int *)pm+i*m+j) <<'\t';
cout<<endl;
}
}
...
int m[2][3] = { {10, 2, 12}, {23, 7, 29} };
PrintMatrixNM(m, 2, 3);
cout << endl;
int m2[4][4] = { {0,0,0,1}, {0,0,1}, {0,1}, {1} };
PrintMatrixNM(m2, 4, 4);
10 2 12 23 7 29 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0 |
II.1.3.2.4. Sztring argumentumok
Függvények készítése során szintén választhatunk a karaktersorozatok C-stílusú (char vektor) vagy felhasználói típusú ( string ) feldolgozása között. Mivel az előzőekben már mindkét paramétertípust ismertettük, most csak néhány példa bemutatására szorítkozunk.
A karaktersorozatok kezelése során három megközelítési módot használunk. Az első esetben, mint vektort kezeljük a sztringet (indexelve), a második megközelítés szerint mutató segítségével végezzük el a szükséges műveleteket, míg harmadik esetben a string típus tagfüggvényeit használjuk.
Felhívjuk a figyelmet arra, hogy a sztring literálok (karaktersorozat konstansok) tartalmának módosítása általában futás közbeni hibához vezet, így azokat csak konstans vagy pedig string típusú érték paraméternek lehet közvetlenül átadni.
Az első példában csupán olvassuk a karaktersorozat elemeit, így megszámlálva egy megadott karakter előfordulásainak számát.
Amennyiben vektorként dolgozzuk fel a sztringet, szükségünk van egy indexváltozóra (i), amellyel a karaktereket indexeljük. A számlálást leállító feltétel a karaktersorozatot záró 0-ás bájt elérése, amihez az indexváltozó léptetésével jutunk el.
unsigned SzamolChC1(const char s[], char ch) {
unsigned db = 0;
for (int i=0; s[i]; i++) {
if (s[i] == ch)
db++;
}
return db;
}
A pointeres megközelítés során a karaktersorozat elejére hivatkozó mutató léptetésével megyünk végig a karaktereken, egészen a sztringet záró '\0' karakter (0-ás bájt) eléréséig
unsigned SzamolChC2(const char *s, char ch) {
unsigned db = 0;
while (*s) {
if (*s++ == ch)
db++;
}
return db;
}
A string típus alkalmazásakor az indexelés mellett tagfüggvényeket is használhatunk:
unsigned SzamolChCpp(const string & s, char ch) {
int db = -1, pozicio = -1;
do {
db++;
pozicio = s.find(ch, pozicio+1);
} while (pozicio != string::npos);
return db;
}
A függvények hívását konstans sztring, karakter tömb és string típusú argumentummal szemléltetjük. Mindhárom függvény hívható sztring literál, illetve karakter tömb argumentummal:
char s1[] = "C, C++, Java, C++/CLI / C#";
string s2 = s1;
cout<<SzamolChC1("C, C++, Java, C++/CLI / C#", 'C')<<endl;
cout<<SzamolChC2(s1, 'C')<<endl;
A string típusú argumentum alkalmazása azonban, már beavatkozást igényel az első két függvénynél:
cout << SzamolChC2(s2.c_str(), 'C') << endl; cout << SzamolChCpp(s2, 'C') << endl;
Sokkal szigorúbb feltételek érvényesülnek, ha elhagyjuk a const deklarációt a paraméterek elől. A következő példában a függvénynek átadott sztringet helyben „megfordítjuk”, és a sztringre való hivatkozással térünk vissza. A megoldást mindhárom fent tárgyalt esetre elkészítettük:
char * StrForditC1(char s[]) {
char ch;
int hossz = -1;
while(s[++hossz]); // a sztring hosszának meghatározása
for (int i = 0; i < hossz / 2; i++) {
ch = s[i];
s[i] = s[hossz-i-1];
s[hossz-i-1] = ch;
}
return s;
}
char * StrForditC2(char *s) {
char *q, *p, ch;
p = q = s;
while (*q) q++; // lépkedés a sztringet záró 0 bájtra
p--; // p sztring első karaktere elé mutat
while (++p <= --q) {
ch = *p;
*p = *q;
*q = ch;
}
return s;
}
string& StrForditCpp(string &s) {
char ch;
int hossz = s.size();
for (int i = 0; i < hossz / 2; i++) {
ch = s[i];
s[i] = s[hossz-i-1];
s[hossz-i-1] = ch;
}
return s;
}
A függvényeket a paraméter típusával egyező típusú argumentummal kell hívni:
int main() {
char s1[] = "C++ programozas";
cout << StrForditC1(s1) << endl; // sazomargorp ++C
cout << StrForditC2(s1) << endl; // C++ programozas
string s2 = s1;
cout << StrForditCpp(s2) << endl; // sazomargorp ++C
cout << StrForditCpp(string(s1)); // sazomargorp ++C
}
II.1.3.2.5. A függvény, mint argumentum
Matematikai alkalmazások készítése során jogos az igény, hogy egy jól megvalósított algoritmust különböző függvények esetén tudjunk használni. Ehhez a függvényt argumentumként kell átadni az algoritmust megvalósító függvénynek.
II.1.3.2.5.1. A függvénytípus és a typedef
A typedef segítségével a függvény típusát egyetlen szinonim névvel jelölhetjük. A függvénytípus deklarálja azt a függvényt, amely az adott számú és típusú paraméterkészlettel rendelkezik, és a megadott adattípussal tér vissza. Tekintsük például a 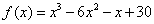 harmadfokú polinom helyettesítési értékeit számító függvényt, melynek prototípusa és definíciója:
harmadfokú polinom helyettesítési értékeit számító függvényt, melynek prototípusa és definíciója:
double poli3(double); // prototípus
double poli3(double x) // definíció
{
return x*x*x - 6*x*x - x + 30;
}
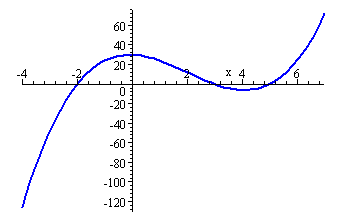
Vegyük a függvény prototípusát, tegyük elé a typedef kulcsszót, végül cseréljük le a poli3 nevet mathfv-re!
typedef double matfv(double);
A mathfv típus felhasználásával a poli3() függvény prototípusa:
matfv poli3;
II.1.3.2.5.2. Függvényre mutató pointerek
A C++ nyelvben a függvényneveket kétféle módon használhatjuk. A függvénynevet a függvényhívás operátor bal oldali operandusaként megadva, függvényhívás kifejezést kapunk
poli3(12.3)
melynek értéke a függvény által visszaadott érték. Ha azonban a függvénynevet önállóan használjuk
poli3
akkor egy mutatóhoz jutunk, melynek értéke az a memóriacím, ahol a függvény kódja elhelyezkedik (kódpointer), típusa pedig a függvény típusa.
Definiáljunk egy olyan mutatót, amellyel a poli3() függvényre mutathatunk, vagyis értékként felveheti a poli3() függvény címét! A definíciót egyszerűen megkapjuk, ha a poli3 függvény fejsorában szereplő nevet a (*fvptr) kifejezésre cseréljük:
double (*fvptr)(double);
Az fvptr olyan pointer, amely double visszatérési értékkel és egy double típusú paraméterrel rendelkező függvényre mutathat.
A definíció azonban sokkal olvashatóbb formában is megadható, ha használjuk a typedef segítségével előállított matfv típust:
matfv *fvptr;
Az fvptr mutató inicializálása után a poli3 függvényt indirekt módon hívhatjuk:
fvptr = poli3;
double y = (*fvptr)(12.3); vagy doubley = fvptr(12.3);
Hasonló módon kell eljárnunk, ha a függvényhez referenciát akarunk készíteni. Ebben az esetben a kezdőértéket már a definíció során meg kell adni:
double (&fvref)(double) = poli3;
vagy
matfv &fvref = poli3;
A függvényhívás a referencia felhasználásával:
double y = fvref(12.3);
II.1.3.2.5.3. Függvényre mutató pointer példák
A fentiek alapján érthetővé válik a qsort () könyvtári függvény prototípusa:
void qsort(void *base, size_t nelem, size_t width,
int (*fcmp)(const void *, const void *));
A qsort () segítségével tömbben tárolt adatokat rendezhetünk a gyorsrendezés algoritmusának felhasználásával. A függvénnyel a base címen kezdődő, nelem elemszámú, elemenként width bájtot foglaló tömböt rendezhetünk. A rendezés során hívott összehasonlító függvényt magunknak kell megadni az fcmp paraméterben.
Az alábbi példában a qsort () függvényt egy egész, illetve egy sztringtömb rendezésére használjuk:
#include <iostream>
#include <cstdlib>
#include <cstring>
using namespace std;
int icmp(const void *p, const void *q) {
return *(int *)p-*(int *)q;
}
int scmp(const void *p, const void *q) {
return strcmp((char *)p,(char *)q);
}
void main() {
int m[8]={2, 10, 7, 12, 23, 29, 11, 30};
char nevek[6][20]={"Dennis Ritchie", "Bjarne Stroustrup",
"Anders Hejlsberg","Patrick Naughton",
"James Gosling", "Mike Sheridan"};
qsort(m, 8, sizeof(int), icmp);
for (int i=0; i<8; i++)
cout<<m[i]<<endl;
qsort(nevek, 6, 20, scmp);
for (int i=0; i<6; i++)
cout<<nevek[i]<<endl;
}
A következő példaprogramokban szereplő tabellaz() függvény tetszőleges double típusú paraméterrel és double visszatérési értékkel rendelkező függvény értékeinek táblázatos megjelenítésére alkalmas. A tabellaz() függvény paraméterei között szerepel még az intervallum két határa és a lépésköz.
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
// Prototípusok
void tabellaz(double (*)(double), double, double, double);
double sqr(double);
int main() {
cout<<"\n\nAz sqr() fuggveny ertekei ([-2,2] dx=0.5)"<<endl;
tabellaz(sqr, -2, 2, 0.5);
cout<<"\n\nAz sqrt() fuggveny ertekei ([0,2] dx=0.2)"<<endl;
tabellaz(sqrt, 0, 2, 0.2);
}
// A tabellaz() függvény definíciója
void tabellaz(double (*fp)(double), double a, double b,
double lepes){
for (double x=a; x<=b; x+=lepes) {
cout.precision(4);
cout<<setw(12)<<fixed<<x<< '\t';
cout.precision(7);
cout<<setw(12)<<fixed<<(*fp)(x)<< endl;
}
}
// Az sqr() függvény definíciója
double sqr(double x) {
return x * x;
}
A program futásának eredménye:
Az sqr() fuggveny ertekei ([-2,2] dx=0.5)
-2.0000 4.0000000
-1.5000 2.2500000
-1.0000 1.0000000
-0.5000 0.2500000
0.0000 0.0000000
0.5000 0.2500000
1.0000 1.0000000
1.5000 2.2500000
2.0000 4.0000000
Az sqrt() fuggveny ertekei ([0,2] dx=0.2)
0.0000 0.0000000
0.2000 0.4472136
0.4000 0.6324555
0.6000 0.7745967
0.8000 0.8944272
1.0000 1.0000000
1.2000 1.0954451
1.4000 1.1832160
1.6000 1.2649111
1.8000 1.3416408
2.0000 1.4142136
|
II.1.3.2.6. Alapértelmezés szerinti (default) argumentumok
A C++ függvények prototípusában bizonyos paraméterekhez ún. alapértelmezés szerinti értéket rendelhetünk. A fordító ezeket az értékeket használja fel a függvény hívásakor, ha a paraméternek megfelelő argumentum nem szerepel a hívási listában:
// prototípus
long SorOsszeg(int n = 10, int d = 1, int a0 = 1);
long SorOsszeg(int n, int d, int a0) { // definíció
long osszeg = 0, ai;
for(int i = 0; i < n; i++) {
ai = a0 + d * i;
cout << setw(5) << ai;
osszeg += ai;
}
return osszeg;
}
A SorOsszeg() függvény n elemű számtani sorozatot készít, amelynek az első eleme a0, differenciája pedig d. A függvény visszatérési értéke a sorozat elemeinek összege.
Felhívjuk a figyelmet arra, hogy az alapértelmezés szerinti értékkel ellátott paraméterek jobbról-balra haladva folytonosan helyezkednek el, míg híváskor az argumentumokat balról jobbra haladva folytonosan kell megadni. Prototípus használata esetén, az alapértelmezés szerinti értékeket csak a prototípusban adhatjuk meg.
A fenti függvény lehetséges hívásait felsorolva, nézzük meg a paraméterek értékét!
|
Hívás |
Paraméterek | ||
|---|---|---|---|
|
n |
d |
a0 | |
|
SorOsszeg() |
10 |
1 |
1 |
|
SorOsszeg(12) |
12 |
1 |
1 |
|
SorOsszeg(12, 3) |
12 |
3 |
1 |
|
SorOsszeg(12, 3, 7) |
12 |
3 |
7' |
Az alapértelmezés szerinti argumentumok rugalmasabbá teszik a függvények használatát. Például, ha valamely függvényt sokszor hívunk egyazon argumentumlistával, érdemes a gyakran használt argumentumokat alapértelmezés szerintivé tenni, és a hívást az argumentumok megadása nélkül elvégezni.
II.1.3.2.7. Változó hosszúságú argumentumlista
Vannak esetek, amikor nem lehet pontosan megadni a függvény paramétereinek számát és típusát. Az ilyen függvények deklarációjában a paraméterlistát három pont zárja:
int printf(const char * formatum, ... );
A három pont azt jelzi a fordítóprogramnak, hogy még lehetnek további argumentumok. A printf () (cstdio) függvény esetén az első argumentumnak mindig szerepelnie kell, amelyet tetszőleges számú további argumentum követhet:
char nev[] = "Bjarne Stroustrup";
double a=12.3, b=23.4, c=a+b;
printf("C++ nyelv\n");
printf("Nev: %s \n", nev);
printf("Eredmeny: %5.3f + %5.3f = %8.4f\n", a, b, c);
A printf () függvény a formatum alapján dolgozza fel a függvény a soron következő argumentumot.
A hasonló deklarációjú függvények hívásakor a fordító csak a „...” listaelemig egyezteti az argumentumok és a paraméterek típusát. Ezt követően a megadott argumentumok (esetleg konvertált) típusa szerint megy végbe az argumentumok átadása a függvénynek.
A C++ nyelv lehetővé teszi, hogy saját függvényeinkben is használjuk a három pontot – az ún. változó hosszúságú argumentumlistát. Ahhoz, hogy a paramétereket tartalmazó memóriaterületen megtaláljuk az átadott argumentumok értékét, legalább az első paramétert mindig meg kell adnunk.
A C++ szabvány tartalmaz néhány olyan makrót, amelyek segítségével a változó hosszúságú argumentumlista feldolgozható. A cstdarg fejállományban definiált makrók a va_list típusú mutatót használják az argumentumok eléréséhez:
|
|
Megadja az argumentumlista következő elemét. |
|
|
Takarítás az argumentumok feldolgozása után. |
|
|
Inicializálja az argumentumok eléréséhez használt mutatót. |
Példaként tekintsük a tetszőleges számú double érték átlagát számító Atlag() függvényt, melynek hívásakor az átlagolandó számsor elemeinek számát az első argumentumban kell átadni!
#include<iostream>
#include<cstdarg>
using namespace std;
double Atlag(int darab, ... ) {
va_list szamok;
// az első (darab) argumentum átlépése
va_start(szamok, darab);
double osszeg = 0;
for(int i = 0; i < darab; ++i ) {
// double argumentumok elérése
osszeg += va_arg(szamok, double);
}
va_end(szamok);
return (osszeg/darab);
}
int main() {
double avg = Atlag(7,1.2,2.3,3.4,4.5,5.6,6.7,7.8);
cout << avg << endl;
}
II.1.3.2.8. A main() függvény paraméterei és visszatérési értéke
A main () függvény különlegességét nemcsak az adja, hogy a program végrehajtása azzal kezdődik, hanem az is, hogy többféle paraméterezéssel rendelkezik:
int main( ) int main( int argc) ( ) int main( int argc, char *argv[]) ( )
Az argv egy karakter mutatókat tartalmazó tömbre (vektorra) mutat, az argc pedig a tömbben található sztringek számát adja meg. (Az argc értéke legalább 1, mivel az argv[0] mindig a program nevét tartalmazó karaktersorozatra hivatkozik.)
A main () visszatérési értékét, amely a szabvány ajánlása alapján int típusú, a main () függvényen belüli return utasításban, vagy a program tetszőleges pontján elhelyezett exit () könyvtári függvény argumentumaként adhatjuk meg. Az cstdlib fejállomány szabványos konstansokat is tartalmaz,
#define EXIT_SUCCESS 0 #define EXIT_FAILURE 1
amelyeket kilépési kódként használva jelezhetjük a program sikeres, illetve sikertelen végrehajtását.
A main () sok mindenben különbözik a normál C++ függvényektől: nem deklarálhatjuk static vagy inline függvényként, nem kötelező benne a return használata, és nem lehet túlterhelni. A szabvány ajánlása alapján, a programon belülről nem hívható, és nem kérdezhető le a címe sem.
Az alábbi parancs1.cpp program kiírja a parancssor argumentumok számát, és megjeleníti az argumentumokat:
#include <iostream>
using namespace std;
int main(int argc, char *argv[]) {
cout << "az argumentumok szama: " << argc << endl;
for (int narg=0; narg < argc; narg++)
cout << narg << " " << argv[narg] << endl;
return 0;
}
A parancssor argumentumokat a konzol ablakban
C:\C++Konyv>parancs1 elso 2. harmadik
és a Visual Studio fejlesztői környezetben (II.5. ábra - Parancssor argumentumok megadása) egyaránt megadhatjuk.
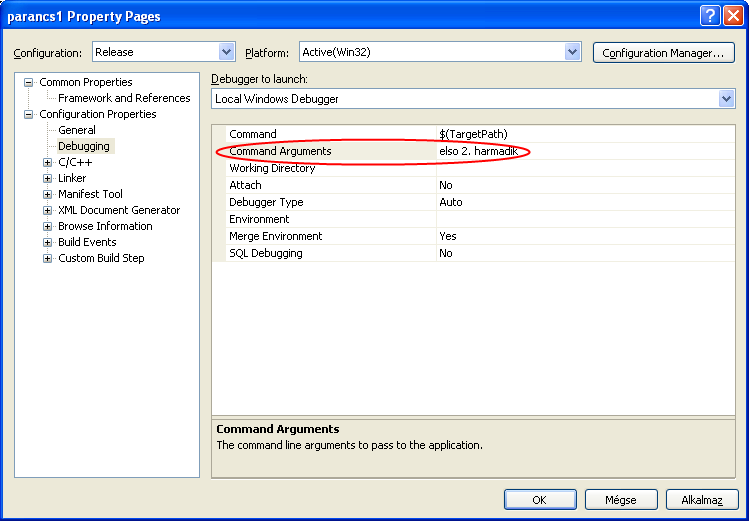
A parancs1.exe program futtatásának eredményei:
|
Konzol ablakban |
Fejlesztői környezetben |
|---|---|
C:\C++Konyv>parancs1 elso 2. harmadik az argumentumok szama: 4 0 parancs1 1 elso 2 2. 3 harmadik C:\C++Konyv> |
C:\C++Konyv>parancs1 elso 2. harmadik az argumentumok szama: 4 0 C:\C++Konyv\parancs1.exe 1 elso 2 2. 3 harmadik C:\C++Konyv> |
A következő példaprogram (parancs2.cpp) a segédprogramok írásánál jól felhasználható megoldást mutat be, az indítási argumentumok helyes megadásának tesztelésére. A program csak akkor indul el, ha pontosan két argumentummal indítjuk. Ellenkező esetben hibajelzést ad, és kiírja az indítási parancssor formáját bemutató üzenetet.
#include <iostream>
#include <cstdlib>
using namespace std;
int main(int argc, char *argv[]) {
if (argc !=3 ) {
cerr<<"Hibas parameterezes!"<<endl;
cerr<<"A program inditasa: parancs2 arg1 arg2"<<endl;
return EXIT_FAILURE;
}
cout<<"Helyes parameterezes:"<<endl;
cout<<"1. argumentum: "<<argv[1]<<endl;
cout<<"2. argumentum: "<<argv[2]<<endl;
return EXIT_SUCCESS;
}
A parancs2.exe program futtatásának eredményei:
|
Hibás indítás: parancs2 |
Helyes indítás: parancs2 alfa beta |
|---|---|
Hibas parameterezes! A program inditasa: parancs2 arg1 arg2 |
Helyes parameterezes: 1. argumentum: alfa 2. argumentum: beta |
II.1.4. Programozás függvényekkel
A procedurális programépítés során az egyes részfeladatok megoldására függvényeket készítünk, amelyek önállóan tesztelhetők. Az eredeti feladat megoldásához ezek után a már tesztelt függvények megfelelő hívásával jutunk el. Fontos kérdés a függvények közötti kommunikáció megszervezése. Mint láttuk egy-egy függvény példáján, a paraméterezés és függvényérték képezik a kapcsolatot a külvilággal. Több, egymással logikai kapcsolatban álló függvény esetén azonban más megoldások is szóba jöhetnek, növelve a megoldás hatékonyságát.
Vegyünk példaként egy mindenki által jól ismert feladatot, a síkbeli háromszög kerületének és területének meghatározását! A területszámítást Hérón képletének felhasználásával végezzük, amely alkalmazásának előfeltétele a háromszög-egyenlőtlenség teljesülése. Ez kimondja, hogy a háromszög minden oldalának hossza kisebb a másik két oldal hosszának összegénél.
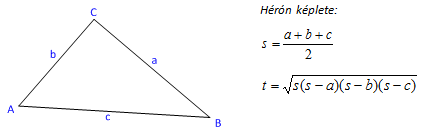
Az egyetlen main () függvényből álló megoldás könyvünk első néhány fejezetének áttanulmányozása után minden további nélkül elkészíthető:
#include <iostream>
#include <cmath>
using namespace std;
int main() {
double a, b, c;
do {
cout <<"a oldal: "; cin>>a;
cout <<"b oldal: "; cin>>b;
cout <<"c oldal: "; cin>>c;
} while(!((a<b+c) && (b<a+c) && (c<a+b)));
double k = a + b + c;
double s = k/2;
double t = sqrt(s*(s-a)*(s-b)*(s-c));
cout << "kerulet: " << k <<endl;
cout << "terulet: " << t <<endl;
}
A program igen egyszerű, azonban kívánnivalókat hagy maga után az áttekinthetősége és az újrafelhasználhatósága.
II.1.4.1. Függvények közötti adatcsere globális változókkal
A fenti probléma megoldását logikailag jól elkülöníthető részekre tagolhatjuk, nevezetesen:
a háromszög oldalhosszainak beolvasása,
a háromszög-egyenlőtlenség ellenőrzése,
a kerület kiszámítása,
a terület kiszámítása
és a számított adatok megjelenítése.
A felsorol tevékenységek közül az első négyet önálló függvények formájában valósítjuk meg, amelyek közös elérésű (globális) változókon keresztül kommunikálnak egymással és a main() függvénnyel. A globális változókat a függvényeken kívül, a függvények definíciója előtt kell megadnunk. (Ne feledkezzünk meg a prototípusok megadásáról sem!)
#include <iostream>
#include <cmath>
using namespace std;
// globális változók
double a, b, c;
// prototípusok
void AdatBeolvasas();
bool HaromszogEgyenlotlenseg();
double Kerulet();
double Terulet();
int main() {
AdatBeolvasas();
cout << "kerulet: " << Kerulet()<<endl;
cout << "terulet: " << Terulet()<<endl;
}
void AdatBeolvasas() {
do {
cout <<"a oldal: "; cin>>a;
cout <<"b oldal: "; cin>>b;
cout <<"c oldal: "; cin>>c;
} while(!HaromszogEgyenlotlenseg() );
}
bool HaromszogEgyenlotlenseg() {
if ((a<b+c) && (b<a+c) && (c<a+b))
return true;
else
return false;
}
double Kerulet() {
return a + b + c;
}
double Terulet() {
double s = Kerulet()/2;
return sqrt(s*(s-a)*(s-b)*(s-c));
}
A program jobb olvashatósága nem tagadható, azonban a széles körben való használhatósága akadályokba ütközik. Például, ha több háromszög adatait szeretnénk eltárolni, majd pedig a számításokban felhasználni, ügyelnünk kell a globális a, b és c változók értékének megfelelő beállítására.
int main() {
double a1, b1, c1, a2, b2, c2;
AdatBeolvasas();
a1 = a, b1 = b, c1 = c;
AdatBeolvasas();
a2 = a, b2 = b, c2 = c;
a = a1, b = b1, c = c1;
cout << "kerulet: " << Kerulet()<<endl;
cout << "terulet: " << Terulet()<<endl;
a = a2, b = b2, c = c2;
cout << "kerulet: " << Kerulet()<<endl;
cout << "terulet: " << Terulet()<<endl;
}
Ebből a szempontból jobb megoldáshoz jutunk, ha a háromszög oldalait paraméterként adjuk át az érintett függvényeknek.
II.1.4.2. Függvények közötti adatcsere paraméterekkel
Nem merülünk el a megoldás részletezésében, hiszen a szükséges ismereteket már az Olvasó elé tártuk az előző részekben.
#include <iostream>
#include <cmath>
using namespace std;
void AdatBeolvasas(double &a, double &b, double &c);
bool HaromszogEgyenlotlenseg(double a, double b, double c);
double Kerulet(double a, double b, double c);
double Terulet(double a, double b, double c);
int main() {
double x, y, z;
AdatBeolvasas(x , y , z);
cout << "kerulet: " << Kerulet(x, y, z) <<endl;
cout << "terulet: " << Terulet(x, y, z) <<endl;
}
void AdatBeolvasas(double &a, double &b, double &c) {
do {
cout <<"a oldal: "; cin>>a;
cout <<"b oldal: "; cin>>b;
cout <<"c oldal: "; cin>>c;
} while(!HaromszogEgyenlotlenseg(a, b, c) );
}
bool HaromszogEgyenlotlenseg(double a, double b, double c) {
if ((a<b+c) && (b<a+c) && (c<a+b))
return true;
else
return false;
}
double Kerulet(double a, double b, double c) {
return a + b + c;
}
double Terulet(double a, double b, double c) {
double s = Kerulet(a, b, c)/2;
return sqrt(s*(s-a)*(s-b)*(s-c));
}
Nézzük meg a main () függvényt, ha két háromszöget kívánunk kezelni!
int main() {
double a1, b1, c1, a2, b2, c2;
AdatBeolvasas(a1, b1, c1);
AdatBeolvasas(a2, b2, c2);
cout << "kerulet: " << Kerulet(a1, b1, c1)<<endl;
cout << "terulet: " << Terulet(a1, b1, c1)<<endl;
cout << "kerulet: " << Kerulet(a2, b2, c2)<<endl;
cout << "terulet: " << Terulet(a2, b2, c2)<<endl;
}
Összehasonlításképpen elmondhatjuk, hogy a globális változókkal hatékonyabb (gyorsabb) programkódot kapunk, hiszen elmarad az argumentumok hívás előtti verembe másolása. Láttuk a megoldás negatív következményeit is, melyek erősen korlátozzák a kód újrahasznosítását. Hogyan lehetne csökkenti a sok paraméterrel járó kényelmetlenségeket, és elkerülni a hosszú argumentumlistákat?
Az alábbi megoldás általánosan javasolt a globális változók használata helyett. A globális változókat, illetve a nekik megfelelő paramétereket struktúrába kell gyűjteni, melyet aztán referenciával, vagy konstans referenciával adunk át a függvényeknek.
#include <iostream>
#include <cmath>
using namespace std;
struct haromszog {
double a, b, c;
};
void AdatBeolvasas(haromszog &h);
bool HaromszogEgyenlotlenseg(const haromszog &h);
double Kerulet(const haromszog &h);
double Terulet(const haromszog &h);
int main() {
haromszog h1, h2;
AdatBeolvasas(h1);
AdatBeolvasas(h2);
cout << "kerulet: " << Kerulet(h1)<<endl;
cout << "terulet: " << Terulet(h1)<<endl;
cout << "kerulet: " << Kerulet(h2)<<endl;
cout << "terulet: " << Terulet(h2)<<endl;
}
void AdatBeolvasas(haromszog &h) {
do {
cout <<"a oldal: "; cin>>h.a;
cout <<"b oldal: "; cin>>h.b;
cout <<"c oldal: "; cin>>h.c;
} while(!HaromszogEgyenlotlenseg(h) );
}
bool HaromszogEgyenlotlenseg(const haromszog &h) {
if ((h.a<h.b+h.c) && (h.b<h.a+h.c) && (h.c<h.a+h.b))
return true;
else
return false;
}
double Kerulet(const haromszog &h) {
return h.a + h.b + h.c;
}
double Terulet(const haromszog &h) {
double s = Kerulet(h)/2;
return sqrt(s*(s-h.a)*(s-h.b)*(s-h.c));
}
II.1.4.3. Egyszerű menüvezérelt programstruktúra
A szöveges felületű programjaink vezérlését egyszerű menü segítségével kényelmesebbé tehetjük. A megoldáshoz a menüpontokat egy sztring tömbben tároljuk:
// A menü definíciója
char * menu[] = {"\n1. Oldalak",
"2. Kerulet",
"3. Terulet",
"----------",
"0. Kilep" , NULL };
Az előző példa main () függvényében pedig kezeljük a menüválasztásokat:
int main() {
haromszog h = {3,4,5};
char ch;
do {
// a menü kiírása
for (int i=0; menu[i]; i++)
cout<<menu[i]<< endl;
// A választás feldolgozása
cin>>ch; cin.get();
switch (ch) {
case '0': break;
case '1': AdatBeolvasas(h);
break;
case '2': cout << "kerulet: " << Kerulet(h)<<endl;
break;
case '3': cout << "terulet: " << Terulet(h)<<endl;
break;
default: cout<<'\a';
}
} while (ch != '0');
}
A program futásának ablaka
1. Oldalak 2. Kerulet 3. Terulet ---------- 0. Kilep 1 a oldal: 3 b oldal: 4 c oldal: 5 1. Oldalak 2. Kerulet 3. Terulet ---------- 0. Kilep 2 kerulet: 12 1. Oldalak 2. Kerulet 3. Terulet ---------- 0. Kilep 3 terulet: 6 |
II.1.4.4. Rekurzív függvények használata
A matematikában lehetőség van bizonyos adatok és állapotok rekurzív módon történő előállítására. Ekkor az adatot vagy az állapotot úgy definiáljuk, hogy megadjuk a kezdőállapoto(ka)t, majd pedig egy általános állapotot az előző(, véges számú állapot) segítségével határozunk meg.
Tekintsünk néhány jól ismert rekurzív definíciót!
faktoriális:
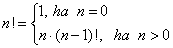
Fibonacci-számok:
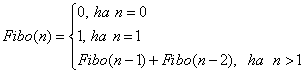
legnagyobb közös osztó (lnko):
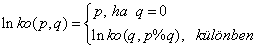
binomiális számok:
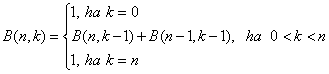
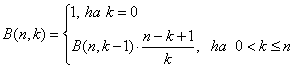
Programozás szempontjából rekurzív algoritmusnak azt tekintjük, ami közvetlenül (közvetlen rekurzió) vagy más függvények közbeiktatásával (közvetett rekurzió) hívja önmagát. Klasszikus példaként tekintsük először a faktoriális számítását!
A faktoriális számítás fenti, rekurzív definíciója alapján 5! meghatározásának lépései az alábbi szemléletes formában ábrázolhatók:
5! = 5 * 4!
4 * 3!
3 * 2!
2 * 1!
1 * 0!
1 = 5 * 4 * 3 * 2 * 1 * 1 = 120
A fenti számítási menetet megvalósító C++ függvény:
unsigned long long Faktorialis(int n)
{
if (n == 0)
return 1;
else
return n * Faktorialis(n-1);
}
A rekurzív függvények általában elegáns megoldást adnak a problémákra, azonban nem elég hatékonyak. A kezdőállapot eléréséig a függvények hívási láncolata által lefoglalt memóriaterület (veremterület) elég jelentős méretű is lehet, és a függvényhívási mechanizmus is igen sok időt vehet igénybe.
Ezért fontos az a megállapítás, hogy minden rekurzív problémának létezik iteratív (ciklust használó) megoldása is, amely általában nehezebben programozható, azonban hatékonyabban működik. Ennek fényében a faktoriális számítást végző nem rekurzív függvény:
unsigned long long Faktorialis(int n)
{
unsigned long long f=1;
while (n != 0)
f *= n--;
return f;
}
A következőkben tekintsük a Fibonacci számsorozat n-edik elemének meghatározását! A
0, 1, 1, 2, 3, 5, 8, 13, 21, ...
sorozat n-edik elemének számítására az alábbi rekurziós szabály alkalmazható:
|
a0 = 0 | |
|
a1 = 1 | |
|
an = an-1 + an-2, n = 2 ,3, 4,… |
A rekurziós szabály alapján elkészített függvény szerkezete teljes mértékben követi a matematikai definíciót:
unsigned long Fibonacci( int n ) {
if (n<2)
return n;
else
return Fibonacci(n-1) + Fibonacci(n-2);
}
A számítási idő és a memóriaigény jelentős mértéke miatt itt is az iteratív megoldás használatát javasoljuk:
unsigned long Fibonacci( int n ) {
unsigned long f0 = 0, f1 = 1, f2 = n;
while (n-- > 1) {
f2 = f0 + f1;
f0 = f1;
f1 = f2;
}
return f2;
}
Amíg az iteratív megoldás futásideje az n függvényében lineárisan nő, addig a rekurzív függvényhívás ideje hatványozottan növekszik (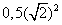 ).
).
Fejezetünk befejező részében a felvetett feladatoknak csak a rekurzív megoldását közöljük, az iteratív megközelítés programozását az Olvasóra bízzuk.
Két természetes szám legnagyobb közös osztóját rekurzív módon igen egyszerűen meghatározhatjuk:
int Lnko(int p, int q) {
if (q == 0)
return p;
else
return Lnko(q, p % q);
}
A binomiális együtthatók számításhoz kétféle rekurzív függvény közül is választhatunk:
int Binom1(int n, int k)
{
if (k == 0 || k == n)
return 1;
else
return Binom1(n-1,k-1) + Binom1(n-1,k);
}
int Binom2(int n, int k)
{
if (k==0)
return 1;
else
return Binom2(n, k-1) * (n-k+1) / k;
}
A két megoldás közül a Binom2() a hatékonyabb.
Az utolsó példában determináns kiszámításához használjuk a rekurziót. A megoldás lényege, hogy az N-ed rendű determináns meghatározását N darab (N-1)-ed rendű determináns számítására vezetjük vissza. Tesszük ezt mindaddig, míg el nem jutunk a másodrendű determinánsokig. A megoldás szép és áttekinthető, azonban nem elég hatékony. A számítás során a hívások fastruktúrában láncolódnak, ami sok futásidőt és memóriát igényel.
Például, a 4x4-es determináns számításakor 17-szer (1 darab 4x4-es, 4 darab 3x3-as és 4·3 darab 2x2-es mátrixszal) hívódik meg a Determinans() függvény, a hívások száma azonban az 5-öd rendű esetben 5·17+1 = 86-ra emelkedik. (Megjegyezzük, hogy 12x12-es mátrix esetén a Determinans() függvény, több mint 300 milliószor hívódik meg, ami perceket is igénybe vehet.)
#include <iostream>
#include <iomanip>
using namespace std;
typedef double Matrix[12][12];
double Determinans(Matrix m, int n);
void MatrixKiir(Matrix m, int n);
int main() {
Matrix m2 = {{1, 2},
{2, 3}};
Matrix m3 = {{1, 2, 3},
{2, 1, 1},
{1, 0, 1}};
Matrix m4 = {{ 2, 0, 4, 3},
{-1, 2, 6, 1},
{10, 3, 4,-2},
{ 2, 1, 4, 0}};
MatrixKiir(m2,2);
cout << "Determinans(m2) = " << Determinans(m2,2) << endl;
MatrixKiir(m3,3);
cout << "Determinans(m3) = " << Determinans(m3,3) << endl;
MatrixKiir(m4,4);
cout << "Determinans(m4) = " << Determinans(m4,4) << endl;
cin.get();
return 0;
}
void MatrixKiir(Matrix m, int n)
{
for (int i=0; i<n; i++) {
for (int j=0; j<n; j++) {
cout << setw(6) << setprecision(0) << fixed;
cout << m[i][j];
}
cout << endl;
}
}
double Determinans(Matrix m, int n)
{
int q;
Matrix x;
if (n==2)
return m[0][0]*m[1][1]-m[1][0]*m[0][1];
double s = 0;
for (int k=0; k<n; k++) // n darab aldetermináns
{
// az almátrixok létrehozása
for (int i=1; i<n; i++) // sorok
{
q = -1;
for (int j=0; j<n; j++) // oszlopok
if (j!=k)
x[i-1][++q] = m[i][j];
}
s+=(k % 2 ? -1 : 1) * m[0][k] * Determinans(x, n-1);
}
return s;
}
A program futásának eredménye:
1 2
2 3
Determinans(m2) = -1
1 2 3
2 1 1
1 0 1
Determinans(m3) = -4
2 0 4 3
-1 2 6 1
10 3 4 -2
2 1 4 0
Determinans(m4) = 144
|
II.2. A függvényekről magasabb szinten
Az előző fejezet elengedő ismeretet nyújt ahhoz, hogy programozási feladatainkat függvények segítségével oldjuk meg. Az áttekinthetőbb programszerkezet, a jobb tesztelhetőség sok programhiba keresésre fordított időt takaríthat nekünk.
A következőkben áttekintjük azokat a megoldásokat, amelyek a függvények használatát valamilyen szempont szerint hatékonyabbá tehetik. Ezek a szempontok a gyorsabb kódvégrehajtás, a kényelmesebb fejlesztés és algoritmizálás.
II.2.1. Beágyazott (inline) függvények
A függvényhívás a függvényben megadott algoritmus végrehatásán túlmenően további időt és memóriát igényel. Idő megy el a paraméterek átadására, a függvény kódjára való ugrásra és a függvényből való visszatérésre.
A C++ fordító az inline (beágyazott) kulcsszóval megjelölt függvények hívását azzal gyorsítja, hogy a hívás helyére befordítja a függvény utasításait. (Ez azt jelenti, hogy a fordító a paraméterátadás előkészítése, majd a függvény törzséből előállított, elkülönített kódra való ugrás helyett a függvény definíciójából és az argumentumaiból készített kódsorozattal helyettesíti függvényhívást a programunkban.)
Általában kisméretű, gyakran hívott függvények esetén ajánlott alkalmazni ezt a megoldást.
inline double Max(double a, double b) {
return a > b ? a : b;
}
inline char Kisbetu( char ch ) {
return ((ch >= 'A' && ch <= 'Z') ? ch + ('a'-'A') : ch );
}
Az beágyazott függvények használatának előnye a későbbiekben bemutatásra kerülő makrókkal szemben, hogy a függvényhívás során az argumentumok feldolgozása teljes körű típusellenőrzés mellett megy végbe. Az alábbi példában egy rendezett vektorban, bináris keresést végző függvényt jelöltünk meg az inline kulcsszóval:
#include <iostream>
using namespace std;
inline int BinarisKereses(int vektor[], int meret, int kulcs) {
int eredmeny = -1; // nem talált
int also = 0;
int felso = meret - 1, kozepso;
while (felso >= also) {
kozepso = (also + felso) / 2;
if (kulcs < vektor[kozepso])
felso = kozepso - 1;
else if (kulcs == vektor[kozepso]) {
eredmeny = kozepso;
break;
}
else
also = kozepso + 1;
} // while
return eredmeny;
}
int main() {
int v[8] = {2, 7, 10, 11, 12, 23, 29, 30};
cout << BinarisKereses(v, 8, 23)<< endl; // 5
cout << BinarisKereses(v, 8, 4)<< endl; // -1
}
Néhány további megjegyzés az beágyazott függvények használatával kapcsolatban:
Az inline megoldás általában kisméretű, nem bonyolult függvények esetén használható hatékonyan.
Az inline függvényeket fejállományba kell helyeznünk, amennyiben több fordítási egységben is hívjuk őket, azonban egyetlen forrásfájlba csak egyszer építhetők be.
A beágyazott függvények ugyan gyorsabb-, azonban legtöbbször nagyobb lefordított kódot eredményeznek, hosszabb fordítási folyamat során.
Az inline előírás csupán egy javaslat a fordítóprogram számára, amelyet az bizonyos feltételek esetén (de nem mindig!) figyelembe is vesz. A legtöbb fordító a ciklust vagy rekurzív függvényhívást tartalmazó függvények esetén figyelmen kívül hagyja az inline előírást.
II.2.2. Függvénynevek átdefiniálása (túlterhelése)
Első látásra úgy tűnhet, hogy a függvények széles körben való alkalmazásának útjában áll a paraméterek szigorú típusellenőrzése. Értékparaméterek esetén ez csak a mutatók, tömbök és a felhasználói típusok esetén akadály. Az alábbi abszolút értéket meghatározó függvény tetszőleges numerikus argumentummal hívható, azonban az eredményt mindig int típusúként adja vissza:
inline int Abszolut(int x) {
return x < 0 ? -x : x;
}
Néhány függvényhívás és visszaadott érték:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A fordító a 2. és 3. esetben figyelmeztet ugyan az adatvesztésre, azonban a futtatható program elkészíthető.
Nem konstans, referencia paraméterek esetén azonban sokkal erősebbek a megkötések, hiszen az Ertekadas() függvény hívásakor az első két paramétert int változóként kell megadnunk:
void Ertekadas(int & a, int & b, int c) {
a = b + c;
b = c;
}
Jogos az igény, hogy egy függvényben megvalósított algoritmust különböző típusú paraméterekkel tudjuk futatni, méghozzá ugyanazt a függvénynevet használva. A névazonossághoz azért ragaszkodunk, mert általában a függvénynév utal a függvényben megvalósított tevékenységre, algoritmusra. Ezt az igényünket a C++ nyelv a függvénynevek túlterhelésével (overloading) támogatja.
A függvénynevek túlterhelése azt jelenti, hogy azonos hatókörben (ennek pontos jelentését később tisztázzuk) azonos névvel, de eltérő paraméterlistával (paraméterszignatúrával) különböző függvényeket definiálhatunk. (A paraméterszignatúra alatt a paraméterek számát és és a peramétersor elemeinek típusait.)
Az elmondottakat figyelembe véve állítsuk elő az Abszolut() függvényünk két változatát!
#include <iostream>
using namespace std;
inline int Abszolut(int x) {
return x < 0 ? -x : x;
}
inline double Abszolut(double x) {
return x < 0 ? -x : x;
}
int main() {
cout << Abszolut(-7) << endl; // int
cout << Abszolut(-1.2) << endl; // double
cout << Abszolut(2.3F) << endl; // double
cout << Abszolut('I') << endl; // int
cout << Abszolut(L'\x807F') << endl; // int
}
Fordításkor nem jelentkezik az adatvesztésre utaló üzenet, tehát a lebegőpontos értékekkel a double típusú függvény aktivizálódik.
Ebben az esetben a függvény neve önmagában nem határozza meg egyértelműen, hogy melyik függvény fut. A fordítóprogram a hívási argumentumok szignatúráját sorban egyezteti az összes azonos nevű függvény paramétereinek szignatúrájával. Az egyeztetés eredményeként az alábbi esetek fordulhatnak elő:
Pontosan egy illeszkedőt talál, teljes típusegyezéssel – ekkor az ennek megfelelő függvény hívását fordítja be.
Pontosan egy illeszkedőt talál, automatikus konverziók utáni típusegyezéssel - ilyenkor is egyértelmű a megfelelő függvény kiválasztása.
Egyetlen illeszkedőt sem talál - hibajelzést ad.
Több egyformán illeszkedőt talál - hibajelzést ad.
Felhívjuk a figyelmet arra, hogy a megfelelő függvényváltozat kiválasztásában a függvény visszatérési értékének típusa nem játszik szerepet.
Amennyiben szükséges, például több egyformán illeszkedő függvény esetén, típuskonverziós előírással magunk is segíthetjük a megfelelő függvény kiválasztását:
int main() {
cout << Abszolut((double)-7) << endl; // double
cout << Abszolut(-1.2) << endl; // double
cout << Abszolut((int)2.3F) << endl; // int
cout << Abszolut((float)'I') << endl; // double
cout << Abszolut(L'\x807F') << endl; // int
}
A következő példában a VektorOsszeg() függvénynek két átdefiniált formája létezik, az unsigned int és a double típusú tömbök elemösszegének meghatározására:
#include <iostream>
using namespace std;
unsigned int VektorOsszeg(unsigned int a[], int n) {
int osszeg=0;
for (int i=0; i<n; i++)
osszeg += a[i];
return osszeg;
}
double VektorOsszeg(double a[], int n) {
double osszeg=0;
for (int i=0; i<n; i++)
osszeg += a[i];
return osszeg;
}
int main() {
unsigned int vu[]={1,1,2,3,5,8,13};
const int nu=sizeof(vu) / sizeof(vu[0]);
cout << "\nAz unsigned tomb elemosszege: "
<<VektorOsszeg(vu, nu);
double vd[]={1.2,2.3,3.4,4.5,5.6};
const int nd=sizeof(vd) / sizeof(vd[0]);
cout << "\nA double tomb elemosszege: "
<< VektorOsszeg(vd, nd);
}
A fordítóprogram az első híváskor a VektorOsszeg(unsigned int*, int), míg a második esetében VektorOsszeg(double*, int) szignatúrát találja illeszkedőnek. Más típusú (például int és float) tömbök esetén fordítási hibát kapunk, hiszen C++-ban erősen korlátozott a mutatók automatikus konverziója.
Felhívjuk a figyelmet arra, hogy a függvényekhez hasonló módon használható a műveletek átdefiniálásának mechanizmusa (operator overloading). Az operátorokat azonban csak felhasználó által definiált típusokkal (struct, class) lehet túlterhelni, ezért ezzel a lehetőséggel könyvünk következő részében foglalkozunk részletesen.
A fenti példákból látható, hogy további típusok bevezetése esetén szövegszerkesztési feladattá válik az újabb, ugyanazt az algoritmust megvalósító, függvényváltozatok elkészítése (blokkmásolás, szövegcsere). Ennek elkerülése érdekében az átdefiniált függvényváltozatok előállítását a C++ fordítóprogramra is rábízhatjuk, a függvénysablonok (function templates) bevezetésével.
II.2.3. Függvénysablonok
Az előző részekben megismerkedtünk a függvényekkel, amelyek segítenek abban, hogy biztonságosabb, jól karbantartható programokat készítsünk. Bár a függvények igen hatékony és rugalmas programépítést tesznek lehetővé, bizonyos esetekben nehézségekbe ütközünk, hiszen minden paraméterhez típust kell rendelnünk. Az előző alfejezetben bemutatott túlterheléses megoldás segít a típusoktól bizonyos mértékig függetleníteni a függvényeinek. Ott azonban csak véges számú típusban gondolkodhatunk, és fejlesztői szempontból igencsak nagy problémát jelent a megismételt forráskód javítása, naprakésszé tétele.
Jogosan merül fel az igény, hogy csak egyszer kelljen elkészíteni a függvényünket, azonban akárhányszor felhasználhassuk, tetszőleges típusú argumentumokkal. A legtöbb, napjainkban használatos programozási nyelv a generikus programozás eszközeivel ad megoldást a problémánkra.
A generikus (generic) programozás egy általános programozási modell. Maga a technika olyan programkód fejlesztését jelenti, amely nem függ a program típusaitól. A forráskódban úgynevezett általánosított vagy paraméterezett típusokat használunk. Ez az elv nagyban növeli az újrafelhasználás mértékét, hiszen típusoktól független tárolókat és algoritmusokat készíthetünk segítségével. A C++ nyelv a sablonok (templates) bevezetésével, fordítási időben valósítja meg a generikus programozást. Léteznek azonban olyan nyelvek és rendszerek is, amelyeknél ez futási időben történik (ilyenek például a Java és a С#).
II.2.3.1. Függvénysablonok készítése és használata
A sablonok deklarációja a template kulcsszóval indul, mely után a < és > jelek között adjuk meg a sablon paramétereit. Ezek a paraméterek elsősorban általánosított típusnevek azonban változók is szerepelhetnek közöttük. Az általánosított típusnevek előtt a class vagy a typename kulcsszavakat kell használnunk.
A függvénysablon előállításakor egy működő függvényből érdemes kiindulni, amelyben a lecserélendő típusokat általános típusokkal (TIPUS) helyettesítjük. Ezek után közölnünk kell a fordítóval, hogy mely típusokat kell majd lecserélni a függvénymintában (template<class TIPUS>). Tekintsük például az első a lépést az Abszolut() függvényünk esetén
inline TIPUS Abszolut(TIPUS x) {
return x < 0 ? -x : x;
}
majd pedig a végleges forma kétféleképpen megadva:
template <class TIPUS>
inline TIPUS Abszolut(TIPUS x) {
return x < 0 ? -x : x;
}
template <typename TIPUS>
inline TIPUS Abszolut(TIPUS x) {
return x < 0 ? -x : x;
}
Az elkészült függvénysablonból a fordító állítja elő a szükséges függvényváltozatot, amikor először találkozik egy hívással. Felhívjuk a figyelmet arra, hogy az Abszolut() sablon csak numerikus típusokkal használható, amelyek körében értelmezettek az kisebb és az előjelváltás műveletek.
A szokásos függvényhívás esetén a fordítóprogram az argumentum típusából dönti el, hogy az Abszolut() függvény mely változatát állítja elő, és fordítja le.
cout << Abszolut(123)<< endl; // TIPUS = int cout << Abszolut(123.45)<< endl; // TIPUS = double
Típus-átalakítás segítségével az automatikus típusválasztás eredményéről magunk is gondoskodhatunk:
cout << Abszolut((float)123.45)<< endl; // TIPUS = float cout << Abszolut((int)123.45)<< endl; // TIPUS = int
Ugyanerre az eredményre jutunk, ha a függvény neve után, a < és > jelek között megadjuk a típusnevet:
cout << Abszolut<float>(123.45)<< endl; // TIPUS = float cout << Abszolut<int>(123.45)<< endl; // TIPUS = int
A függvénysablonban természetesen több, azonos típus helyettesítése is megoldható, mint ahogy azt a következő példában láthatjuk:
template <typename T>
inline T Maximum(T a, T b) {
return (a>b ? a : b);
}
int main() {
int a = 12, b=23;
float c = 7.29, d = 10.2;
cout<<Maximum(a, b); // Maximum(int, int)
cout<<Maximum(c, d); // Maximum(float, float)
↯ cout<<Maximum(a, c); // nem található Maximum(int, float)
cout<<Maximum<int>(a,c);
// a Maximum(int, int) függvény hívódik meg konverzióval
}
A különböző típusok alkalmazásához több általánosított típust kell a sablonfejben megadnunk:
template <typename T1, typename T2>
inline T1 Maximum(T1 a, T2 b) {
return (a>b ? a : b);
}
int main() {
cout<<Maximum(5,4); // Maximum(int, int)
cout<<Maximum(5.6,4); // Maximum(double, int)
cout<<Maximum('A',66L); // Maximum(char, long)
cout<<Maximum<float, double>(5.6,4);
// Maximum(float, double)
cout<<Maximum<int, char>('A',66L);
// Maximum(int, char)
}
II.2.3.2. A függvénysablon példányosítása
Amikor a C++ fordítóprogram először találkozik egy függvénysablon hívásával, az adott típussal/típusokkal elkészíti a függvény egy példányát. Minden függvénypéldány az adott függvénysablon, adott típusokkal specializált változata. A lefordított programkódban minden felhasznált típushoz pontosan egy függvénypéldány tartozik. A fenti hívásokban erre az ún. implicit példányosításra láttunk példát.
A függvénysablont explicit módon is példányosíthatjuk, amennyiben a függvény fejlécét magában foglaló template sorban konkrét típusokat adunk meg:
template inline int Abszolut<int>(int); template inline float Abszolut(float); template inline double Maximum(double, long); template inline char Maximum<char, float>(char, float);
Fontos megjegyeznünk, hogy adott típus(ok)ra vonatkozó explicit példányosítás csak egyszer szerepelhet a programkódban.
Mivel a C++ fordító a függvénysablonokat fordítási időben dolgozza fel, a függvényváltozatok elkészítéséhez a sablonoknak forrásnyelven kell rendelkezésre állniuk. Ajánlott a függvénysablonokat a fejállományban elhelyezni, biztosítva azt, hogy a fejállományt csak egyszer lehessen beépíteni a C++ modulokba.
II.2.3.3. A függvénysablon specializálása
Vannak esetek, amikor az elkészített általános függvénysablonban definiált algoritmustól eltérő működésre van szükségünk bizonyos típusok vagy típuscsoportok esetén. Ebben az esetben magát a függvénysablont kell túlterhelnünk (specializálnunk) – explicit specializáció.
Az alábbi példában a Csere() függvénysablon a hivatkozással átadott argumentumok értékét felcseréli. Az első specializált változat a mutató argumentumok esetén nem a mutatókat, hanem a hivatkozott értékeket cseréli fel. A másik, tovább specializált változat kimondottan C-stílusú sztringek cseréjére használható.
#include <iostream>
#include <cstring>
using namespace std;
// Az alap sablon
template< typename T > void Csere(T& a, T& b) {
T c(a);
a = b;
b = c;
}
// A mutatókra specializált sablon
template<typename T> void Csere(T* a, T* b) {
T c(*a);
*a = *b;
*b = c;
}
// C-sztringekre specializált sablon
template<> void Csere(char *a, char *b) {
char puffer[123];
strcpy(puffer, a);
strcpy(a, b);
strcpy(b, puffer);
}
int main() {
int a=12, b=23;
Csere(a, b);
cout << a << "," << b << endl; // 23,12
Csere(&a, &b);
cout << a << "," << b << endl; // 12,23
char *px = new char[32]; strcpy(px, "Elso");
char *py = new char[32]; strcpy(py, "Masodik");
Csere(px, py);
cout << px << ", " << py << endl; // Masodik, Elso
delete px;
delete py;
}
Fordító a különböző specializált változatok közül mindig a leginkább specializált (konkrét) sablont alkalmazza először a függvényhívás fordításához.
II.2.3.4. Néhány további függvénysablon példa
A függvénysablonok összefoglalásaként nézzünk meg néhány összetettebb példát! Kezdjük a sort a II.2.2. szakasz - Függvénynevek átdefiniálása (túlterhelése) VektorOsszeg() függvényének általánosításával! A sablon segítségével tetszőleges típusú, egydimenziós, numerikus tömb elemösszegét meg tudjuk határozni:
#include <iostream>
using namespace std;
template<class TIPUS>
TIPUS VektorOsszeg(TIPUS a[], int n) {
TIPUS sum = 0;
for (int i=0; i<n; i++)
sum += a[i];
return sum;
}
int main() {
int ai[]={1,1,2,3,5,8,13};
const int ni=sizeof(ai) / sizeof(ai[0]);
cout << "\nAz int tomb elemosszege: "
<<VektorOsszeg(ai,ni);
double ad[]={1.2,2.3,3.4,4.5,5.6};
const int nd=sizeof(ad) / sizeof(ad[0]);
cout << "\nA double tomb elemosszege: "
<<VektorOsszeg(ad,nd);
float af[]={3, 2, 4, 5};
const int nf=sizeof(af) / sizeof(af[0]);
cout << "\nA float tomb elemosszege: "
<<VektorOsszeg(af,nf);
long al[]={1223, 19800729, 2004102};
const int nl=sizeof(al) / sizeof(al[0]);
cout << "\nA long tomb elemosszege: "
<<VektorOsszeg(al,nl);
}
A Rendez() függvénysablon egy Tip típusú és Meret méretű egydimenziós tömb elemeit rendezi növekvő sorrendbe. A függvény a tömbön belül mozgatja az elemeket, és az eredmény is ugyanabban a tömbben áll elő. Mivel ebben az esetben a típus paraméter (Tip) mellett egy egész értéket fogadó paraméter (Meret) is helyet kapott a deklarációban, a hívás bővített formáját kell használnunk:
Rendez<int, meret>(tomb);
A példaprogramban a Rendez() sablonból a Csere() sablont is hívjuk:
#include <iostream>
using namespace std;
template< typename T > void Csere(T& a, T& b) {
T c(a);
a = b;
b = c;
}
template<class Tip, int Meret> void Rendez(Tip vektor[]) {
int j;
for(int i = 1; i < Meret; i++){
j = i;
while(0 < j && vektor[j] < vektor[j-1]){
Csere<Tip>(vektor[j], vektor[j-1]);
j--;
}
}
}
int main() {
const int meret = 6;
int tomb[meret] = {12, 29, 23, 2, 10, 7};
Rendez<int, meret>(tomb);
for (int i = 0; i < meret; i++)
cout << tomb[i] << " ";
cout << endl;
}
Az utolsó példánkban a Fuggveny() különböző változatainak hívásakor megjelenítjük a fordító által használt függvényváltozatokat. A specializált változatokból az általános sablont aktivizáljuk, amely a Kiir() sablon segítségével megjelenti a teljes hívás elemeit. A típusok nevét a typeid operátor által visszaadott objektum name () tagja adja vissza. A Karakter() függvénysablonnal a megjeleníthető karaktereket aposztrófok között másoljuk a kiírt szövegbe. Ez a kis példa betekintést enged a függvénysablonok használatának boszorkánykonyhájába.
#include <iostream>
#include <sstream>
#include <string>
#include <typeinfo>
#include <cctype>
using namespace std;
template <typename T> T Karakter(T a) {
return a;
}
string Karakter(char c) {
stringstream ss;
if (isprint((unsigned char)c))
ss << "'" << c << "'";
else
ss << (int)c;
return ss.str();
}
template <typename TA, typename TB>
void Kiir(TA a, TB b){
cout << "Fuggveny<" << typeid(TA).name() << ","
<< typeid(TB).name();
cout << ">(" << Karakter(a) << ", " << Karakter(b)
<< ")\n";
}
template <typename TA, typename TB>
void Fuggveny(TA a = 0, TB b = 0){
Kiir<TA, TB>(a,b);
}
template <typename TA>
void Fuggveny(TA a = 0, double b = 0) {
Fuggveny<TA, double>(a, b);
}
void Fuggveny(int a = 12, int b = 23) {
Fuggveny<int, int>(a, b);
}
int main() {
Fuggveny(1, 'c');
Fuggveny(1.5);
Fuggveny<int>();
Fuggveny<int, char>();
Fuggveny('A', 'X');
Fuggveny();
}
A program futásának eredménye:
Fuggveny<int,char>(1, 'c')
Fuggveny<double,double>(1.5, 0)
Fuggveny<int,double>(0, 0)
Fuggveny<int,char>(0, 0)
Fuggveny<char,char>('A', 'X')
Fuggveny<int,int>(12, 23)
|
II.3. Névterek és tárolási osztályok
A C++ nyelvű program gyakran áttekinthetetlen. Ahhoz, hogy egy nagyobb program átlátható maradjon, több olyan szabályt is be kell tartanunk, amit ugyan a C++ nyelv szintaktikája nem követel meg, azonban a használhatóság igen. Az alkalmazott szabályok többsége a moduláris programozás területéről származik.
Az átláthatóság megtartásának egyik hatékony módja, ha a programunkat működési szempontból részekre bontjuk, és az egyes részeket különálló forrásfájlokban, modulokban (.cpp) valósítjuk meg (implementáljuk). A modulok közötti kapcsolatot interfész (deklarációs) állományok (.h) biztosítják. Minden modul esetén alkalmazzuk az adatrejtés elvét, mely szerint a modulokban definiált változók és függvények közül csak azokat osztjuk meg más modulokkal, amelyekre feltétlenül szükség van, míg a többi definíciót elrejtjük a külvilág elől.
A könyvünk második fejezetének célja a jól strukturált, moduláris programozást segítő C++ eszközök bemutatása. Egyik legfontosabb elemmel, a függvényekkel már megismerkedtünk, azonban még további megoldásokra is szükségünk van:
A tárolási osztályok minden C++ változó esetén egyértelműen meghatározzák a változó élettartamát, elérhetőségét és tárolási helyét a memóriában, míg függvények esetén a függvény láthatóságát más függvényekből.
A névterek (namespace) segítséget nyújtanak a több modulból felépülő programokban használt azonosító nevek biztonságos használatához.
II.3.1. A változók tárolási osztályai
Amikor létrehozunk egy változót a C++ programban, a típus mellett a tárolási osztályt is megadjuk. A tárolási osztály
definiálja a változó élettartamát (lifetime, storage duration), vagyis azt, hogy változó mikor jön létre és mikor törlődik a memóriából,
meghatározza, hogy a változó neve hol érhető el közvetlenül – láthatóság (visibility), hatókör (scope), valamint azt, hogy mely nevek jelölnek azonos változókat – kapcsolódás (linkage).
Mint ismeretes, a változókat csak a fordítási egységben (modulban) való deklarálásuk után használhatjuk. (Ne feledjük el, hogy a definíció egyben deklaráció is!) Fordítási egység alatt a C++ forrásállományt (.cpp) értjük, a beépített fejállományokkal együtt.
A tárolási osztályt (auto, register, static, extern) a változó-definíciók elején adhatjuk meg. Amennyiben onnan hiányzik, akkor maga a fordító határozza meg tárolási osztályt a definíció elhelyezkedése alapján.
Az alábbi, egész számot hexadecimális sztringgé alakító példában a tárolási osztályok használatát szemléltetjük:
#include <iostream> using namespace std; static int puffermutato; // modul szintű definíció // az n és elso blokk szintű definíciók void IntToHex(register unsigned n, auto bool elso = true) { extern char puffer[]; // program szintű deklaráció auto int szamjegy; // blokk szintű definíció // hex blokk szintű definíció static const char hex[] = "0123456789ABCDEF"; if (elso) puffermutato=0; if ((szamjegy = n / 16) != 0) IntToHex(szamjegy, false); // rekurzív hívás puffer[puffermutato++] = hex[n % 16]; } extern char puffer[]; // program szintű deklaráció int main() { auto unsigned n; // blokk szintű definíció for (n=0; n<123456; n+=9876) { IntToHex(n); puffer[puffermutato]=0; // sztring lezárása cout << puffer << endl; } } extern char puffer [123] = {0}; // program szintű definíció
Az blokkok szintjén alapértelmezés szerinti auto tárolási osztályt gyakorlatilag sohasem adjuk meg, ezért a példában is áthúzva szerepeltetjük. A függvényeken kívül definiált változók alapértelmezés szerint külső (external) tárolási osztályúak, azonban az extern kulcsszót csak a külső változók deklarálása (nem definíció!!) kell megadnunk.
II.3.1.1. A változók elérhetősége (hatóköre) és kapcsolódása
A tárolási osztállyal szoros kapcsolatban álló fogalom a változók elérhetősége, hatóköre (scope). Minden azonosító csak a hatókörén belül látható. A hatókörök több fajtáját különböztetjük meg: blokk szintű (lokális), fájl szintű és program szintű (globális) (II.7. ábra - A változók hatókörei).
A változók elérhetőségét alapértelmezés szerint a definíció programban elfoglalt helye határozza meg. Így csak blokk szintű és program szintű elérhetőséggel rendelkező változókat hozhatunk létre. A tárolási osztályok közvetlen megadásával árnyalhatjuk a képet.
A hatókör fogalma hasonló a kapcsolódás (linkage) fogalmához, azonban nem teljesen egyezik meg azzal. Azonos nevekkel különböző hatókörökben, különböző változókat jelölhetünk. Azonban a különböző hatókörben deklarált, illetve az azonos hatókörben egynél többször deklarált azonosítók a kapcsolódás felhasználásával ugyanarra a változóra hivatkozhatnak. A C++ nyelvben háromféle kapcsolódásról beszélhetünk: belső, külső, és amikor nincs kapcsolódás.
C++ programban a változók az alábbi hatókörök valamelyikével rendelkezhetnek:
|
blokk szintű |
A változó csak abban a blokkban (függvényblokkban) látható, amelyben definiáltuk, így elérése helyhez kötött, vagyis lokális. Amikor a program eléri a blokkot záró kapcsos zárójelet, a blokk szintű azonosító többé nem lesz elérhető. A blokk szintjén extern és static tárolási osztályok nélkül definiált változók nem rendelkeznek kapcsolódással. |
|
fájl szintű |
A változó csak abban a modulban látható, amely a deklarációját tartalmazza. Kizárólag a modul függvényeiből hivatkozhatunk az ilyen változókra, más modulokból nem. Azok az azonosítók rendelkeznek fájl szintű hatókörrel, amelyeket a modul függvényein kívül, belső kapcsolódással deklarálunk a static tárolási osztály segítségével. (Megjegyezzük, hogy a C++ szabvány a static kulcsszó ilyen módon történő felhasználását elavultnak nyilvánította, helyette a névtelen névterek alkalmazását javasolja a belső kapcsolódású azonosítók kijelölésére). |
|
program szintű |
A változó a program minden moduljának (fordítási egységének) függvényeiből elérhető. Azok az ún. globális azonosítók rendelkeznek program szintű hatókörrel, amelyeket a modulok függvényein kívül, külső kapcsolódással deklarálunk. Ehhez a globális változókat tárolási osztály nélkül vagy az extern tárolási osztállyal kell leírnunk. |
A fájl és a program szintű hatóköröket a később ismertetett névterek (namespace) tovább bontják a minősített azonosítók bevezetésével.
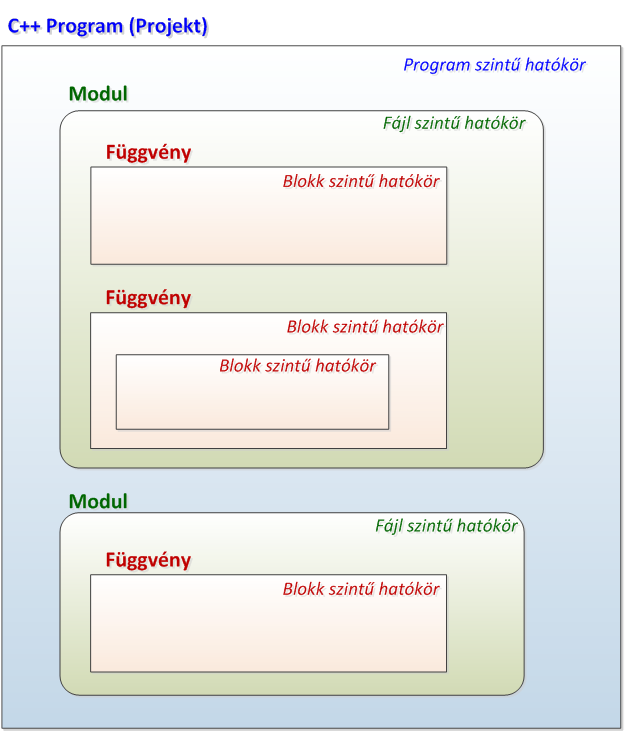
II.3.1.2. A változók élettartama
Az élettartam (lifetime) a program végrehajtásának azon időszaka, amelyben az adott változó létezik. Az élettartam szempontjából az azonosítókat három csoportra oszthatjuk: statikus, automatikus és dinamikus élettartamú nevek.
|
statikus élettartam |
Azok az azonosítók, amelyek a static vagy extern tárolási osztállyal rendelkeznek, statikus élettartamúak. A statikus élettartamú változók számára kijelölt memóriaterület (és a benne tárolt adat) a program futásának teljes időtartama alatt megmarad. Az ilyen változók inicializálása egyetlen egyszer, a program indításakor megy végbe. |
|
automatikus élettartam |
Blokkon belül a static tárolási osztály nélkül definiált változók és a függvények paraméterei automatikus (lokális) élettartammal rendelkeznek. Az automatikus élettartamú azonosítók memóriaterülete (és a benne tárolt adat) csak abban a blokkban létezik, amelyben az azonosítót definiáltuk. A lokális élettartamú változók a blokkba történő minden egyes belépéskor új területen jönnek létre, ami blokkból való kilépés során megszűnik (tartalma elvész). Amennyiben egy ilyen változót kezdőértékkel látunk el, akkor az inicializálás mindig újra megtörténik, amikor a változó létrejön. |
|
dinamikus élettartam |
A tárolási osztályoktól függetlenül dinamikus élettartammal rendelkeznek azok a memóriaterületek, amelyeket a new operátorral foglalunk le, illetve a delete operátorral szabadítunk fel. |
II.3.1.3. A blokk szintű változók tárolási osztályai
Azok a változók, amelyeket programblokkon/függvényblokkon belül, illetve a függvények paraméterlistájában definiálunk alapértelmezés szerint automatikus (auto) változók. Az auto kulcsszót általában nem használjuk, sőt a legújabb C++11 verzióban új értelmezéssel látták el a nyelv fejlesztői. A blokk szintű változókat gyakran lokális változóknak hívjuk.
II.3.1.3.1. Az automatikus változók
Az automatikus változók a blokkba való belépéskor jönnek létre, és blokkból való kilépés során megszűnnek.
A korábbi fejezetekben láttuk, hogy az összetett utasítások (a blokkok) egymásba is ágyazhatók. Mindegyik blokk tetszőleges sorrendben tartalmazhat definíciókat (deklarációkat) és utasításokat:
{
definíciók, deklarációk és
utasítások
}
Valamely automatikus azonosító ideiglenesen elérhetetlenné válik, ha egy belső blokkban ugyanolyan névvel egy másik változót definiálunk. Ez az elfedés a belső blokk végéig terjed, és nincs mód arra, hogy az elfedett (létező) változóra hivatkozzunk:
int main()
{
double hatar = 123.729;
// a double típusú hatar értéke 123.729
{
long hatar = 41002L;
// a long típusú hatar értéke 41002L
}
// a double típusú hatar értéke 123.729
}
Mivel az automatikus tárolók a blokkból kilépve megszűnnek, ezért nem szabad olyan függvényt írni, amely egy lokális változó címével vagy referenciájával tér vissza. Ha egy függvényen belül kívánunk helyet foglalni olyan tároló számára, amelyet a függvényen kívül használunk, akkor a dinamikus memóriafoglalás eszközeit kell alkalmaznunk.
A C++ szabvány szerint ugyancsak automatikus változó a for ciklus fejében definiált ciklusváltozó:
for (int i=12; i<23; i+=2) cout << i << endl; ↯ cout << i << endl; // fordítási hiba, nem definiált az i
Az automatikus változók inicializálása minden esetben végbemegy, amikor a vezérlés a blokkhoz kerül. Azonban csak azok a változók kapnak kezdőértéket, amelyek definíciójában szerepel kezdőértékadás. (A többi változó értéke határozatlan!).
II.3.1.3.2. A register tárolási osztály
A register tárolási osztály csak automatikus lokális változókhoz és függvényparaméterekhez használhatjuk. A register kulcsszó megadásával kérjük a fordítót, hogy az adott változót - lehetőség szerint - a processzor regiszterében hozza létre. Ily módon gyorsabb végrehajtható kódot fordíthatunk. Amennyiben nincs szabad felhasználható regiszter, a tároló automatikus változóként jön létre. Ugyancsak a memóriában jön létre a regiszter változó, ha a címe operátort (&) alkalmazzuk hozzá.
Fontos megjegyeznünk, hogy a regiszter tárolási osztály alkalmazása ellen szól, hogy a C++ fordítóprogramok képesek a kód optimalizálására, ami általában hatékonyabb kódot eredményez, mint amit mi a register előírással elérhetünk.
Az alábbi Csere() függvény a korábban bemutatott megoldásnál potenciálisan gyorsabb működésű. (A potenciális szót azért használjuk, mivel nem ismert, hogy a register előírások közül hányat érvényesít a fordító.)
void Csere(register int &a, register int &b) {
register int c = a;
a = b;
b = c;
}
A következő példa StrToLong() függvénye a sztringben tárolt decimális számot long típusú értékké alakítja:
long StrToLong(const string& str)
{
register int index = 0;
register long elojel = 1, szam = 0;
// a bevezető szóközök átlépése
for(index=0; index < str.size()
&& isspace(str[index]); ++index);
// előjel?
if( index < str.size()) {
if( str[index] == '+' ) { elojel = 1; ++index; }
if( str[index] == '-' ) { elojel = -1; ++index; }
}
// számjegyek
for(; index < str.size() && isdigit(str[index]); ++index)
szam = szam * 10 + (str[index] - '0');
return elojel * szam;
}
A register változók élettartama, láthatósága és inicializálásának módja megegyezik az automatikus tárolási osztályú változókéval.
II.3.1.3.3. Statikus élettartamú lokális változók
A static tárolási osztályt az auto helyett alkalmazva, statikus élettartamú, blokk szintű változókat hozhatunk létre. Az ilyen változók láthatósága a definíciót tartalmazó blokkra korlátozódik, azonban a változó a program indításától, a programból való kilépésig létezik. Mivel a statikus lokális változók inicializálása egyetlen egyszer, a változó létrehozásakor megy végbe, a változók a blokkból való kilépés után (a függvényhívások között) is megőrzik értéküket.
Az alábbi példában a Fibo() függvény a Fibonacci-számok soron következő elemét szolgáltatja a 3. elemtől kezdve. A függvényen belül a statikus lokális a0 és a1 változókban a kilépés után is megőrizzük az előző két elem értékét.
#include <iostream>
using namespace std;
unsigned Fibo() {
static unsigned a0 = 0, a1 = 1;
unsigned a2 = a0 + a1;
a0 = a1;
a1 = a2;
return a2;
}
int main() {
for (register int i=2; i<10; i++)
cout << Fibo() << endl;
}
II.3.1.4. A fájl szintű változók tárolási osztálya
A függvényeken kívül definiált változók automatikusan külső, vagyis program szintű hatókörrel rendelkeznek. Amikor több modulból (forrásfájlból) álló programot fejlesztünk, a moduláris programozás elveinek megvalósításához nem elegendő, hogy vannak globális változóink. Szükségünk lehet olyan modul szinten definiált változókra is, amelyek elérését a forrásállományra korlátozhatjuk (adatrejtés). Ezt a static tárolási osztály külső változók előtti megadásával érhetjük el. A függvényeken kívüli konstans definíciók alapértelmezés szerint szintén belső kapcsolódásúak.
Az alábbi Fibonacci-számokat előállító programban az a0 és a1 változókat modulszinten definiáltuk annak érdekében, hogy egy másik függvénnyel (FiboInit()) is elérjük a tartalmukat.
#include <iostream>
using namespace std;
const unsigned elso = 0, masodik = 1;
static unsigned a0 = elso, a1 = masodik;
void FiboInit() {
a0 = elso;
a1 = masodik;
}
unsigned Fibo() {
unsigned register a2 = a0 + a1;
a0 = a1;
a1 = a2;
return a2;
}
int main() {
for (register int i=2; i<5; i++)
cout << Fibo() << endl;
FiboInit();
for (register int i=2; i<8; i++)
cout << Fibo() << endl;
}
A statikus változók inicializálása a programba való belépés során egyszer megy végbe. Amennyiben nem adunk meg kezdőértéket a definícióban, úgy a fordító automatikusan 0-val inicializálja a változót (feltöltve annak területét nullás bájtokkal). C++-ban a statikus változók kezdőértékeként tetszőleges kifejezést használhatunk.
A C++ szabvány a statikus külső változók helyett a névtelen névterek használatát javasolja (lásd később).
II.3.1.5. A program szintű változók tárolási osztálya
A függvényeken kívül definiált változók, amelyeknél nem adunk meg tárolási osztályt, alapértelmezés szerint extern tárolási osztállyal rendelkeznek. (Természetesen az extern kulcsszó közvetlenül is megadható.)
Az extern (globális) változók élettartama a programba való belépéstől a program befejezésig terjed. Azonban a láthatósággal lehetnek problémák. Egy adott modulban definiált változó csak akkor érhető el egy másik modulból, ha abban szerepeltetjük a változó deklarációját (például deklarációs állomány beépítésével).
A program szintű globális változók használata esetén mindig tudnunk kell, hogy a változót definiáljuk , vagy deklaráljuk . Ha a függvényeken kívül tárolási osztály nélkül szerepeltetünk egy változót, akkor ez a változó definícióját jelenti (függetlenül attól, hogy adunk-e explicit kezdőértéket vagy sem). Ezzel szemben az extern explicit megadása kétféle eredményre vezethet: kezdőérték megadás nélkül a változót deklaráljuk , míg kezdőértékkel definiáljuk . Az elmondottakat jól szemléltetik az alábbi példák:
|
Azonos defíniciók (csak egyikük adható meg) |
Deklarációk |
|---|---|
|
double osszeg; double osszeg = 0; extern double osszeg = 0; |
extern double oszeg;
|
|
int vektor[12]; extern int vektor[12] = {0}; |
extern int vektor[]; extern int vektor[12]; |
|
extern const int meret = 7; |
extern const int meret; |
Felhívjuk a figyelmet arra, hogy a globális változók deklarációi a programon belül bárhova elhelyezhetők, azonban hatásuk a deklaráció helyétől az adott hatókör (blokk vagy modul) határáig terjed. Szokásos megoldás, hogy a deklarációkat modulonként fejállományokban tároljuk, és azt minden forrásfájl elején beépítjük a kódba.
A globális változók inicializálása a programba való belépés során egyszer megy végbe. Amennyiben nem adunk meg kezdőértéket, úgy a fordító automatikusan 0-val inicializálja a változót. C++-ban a globális változók kezdőértékeként tetszőleges kifejezést használhatunk.
Fontos megjegyeznünk, hogy a globális változókat csak indokolt esetben, átgondolt módon szabad használni. Egy nagyobb program esetén is csak néhány, központi extern változó alkalmazása a megengedett.
II.3.2. A függvények tárolási osztályai
Függvények esetén csupán két tárolási osztályt használhatunk. Függvényt nem definiálhatunk a blokk hatókörben, tehát függvény nem készíthető egy másik függvényen belül!
A függvények tárolási osztályai meghatározzák a függvények elérhetőségét. E szerint a tárolási osztály nélküli függvények, illetve az extern tárolási osztállyal definiáltak program szintű hatókörrel rendelkeznek. Ezzel szemben a static tárolási osztállyal rendelkező függvények állomány szintű hatókörűek.
A függvény definíciója alatt magát a függvényt értjük, míg a függvény deklarációja a prototípust jelenti. Az alábbi táblázatban két szám mértani közepét meghatározó függvény definícióit és deklarációit foglaltuk össze, mindkét tárolási osztály esetén.
|
Definíciók (csak egyikük adható meg) |
Prototípusok |
|---|---|
double Mertani(double a, double b)
{
return sqrt(a*b);
}
extern double Mertani(double a, double b)
{
return sqrt(a*b);
}
|
double Mertani(double, double); extern double Mertani(double, double); |
static double Mertani(double a, double b)
{
return sqrt(a*b);
}
|
static double Mertani(double, double); |
A prototípusokat a programon belül bárhova elhelyezhetjük, azonban hatásuk a megadás helyétől az adott hatókör (blokk vagy modul) határáig terjed. A prototípusokat is modulonként fejállományokban szokás tárolni, amit minden érintett forrásfájl elején be kell építeni a programba.
A fájl- és a program szintű deklarációk és definíciók alkalmazását szemlélteti a következő két modulból felépülő példaprogram. A matematikai modul biztosítja a program számára a matematikai állandókat, valamint egy „okos” Random() és egy fokokban számoló Sin() függvényt.
|
|
| |
#include <iostream>
using namespace std;
extern int Random(int);
double Sin(double);
int main() {
for (int i=0; i<5; i++)
cout << Random(12)<< endl;
cout << Sin(45) << endl;
extern const double e;
cout << e << endl;
}
|
#include <ctime>
#include <cstdlib>
#include <cmath>
using namespace std;
extern const double pi = asin(1)*2;
extern const double e = exp(1);
static double Fok2Radian(double);
static bool elsornd = true;
int Random(int n) {
if (elsornd) {
srand((unsigned)time(0));
elsornd = false;
}
return rand() % n;
}
double Sin(double fok) {
return sin(Fok2Radian(fok));
}
static double Fok2Radian(double fok) {
return fok/180*pi;
}
|
II.3.2.1. A lefordított C függvények elérése C++ programból
A C++ fordító a függvények általunk megadott nevét a tárgykódban kiegészíti a függvény paraméterlistáját leíró betűkkel. Ez a C++ kapcsolódásnak (linkage) hívott megoldás teszi lehetővé a fejezet korábbi részeiben bemutatott lehetőségeket (túlterhelés, függvénysablon).
A C++ nyelv születésekor a C nyelv már közel tízéves múltra tekintett vissza. Jogos volt az igény, hogy a C nyelvű programokhoz kifejlesztett, lefordított tárgymodulok és függvénykönyvtárak algoritmusait C++ programokból is elérjük. (A C forráskódú programok felhasználása - kisebb módosításokkal - megoldottnak volt tekinthető.) A C fordító a függvényneveket változtatás nélkül helyezi el a tárgykódban (C kapcsolódás), így azok az eddig megismert C++ deklarációkkal nem érhetők el.
A probléma leküzdésére a C++ nyelv tartalmazza az extern "C" típusmódosítót. Ha például a C nyelven megírt sqrt() függvényt szeretnénk használni a C++ programból, szükséges az
extern "C" double sqrt(double a);
deklaráció megadása. Ennek hatására a C++ fordító a szokásos C névképzést alkalmazza az sqrt() függvényre. Ebből persze az is következik, hogy a C függvényeket nem lehet átdefiniálni (túlterhelni)!
Amennyiben több C függvényt kívánunk elérni a C++ programból, akkor az extern "C" deklaráció csoportos formáját használhatjuk:
extern "C" {
double sin(double a);
double cos(double a);
}
Ha egy C-könyvtár függvényeinek leírását külön deklarációs állomány tartalmazza, akkor az alábbi megoldás a célravezető:
extern "C" {
#include <rs232.h>
}
Ugyancsak az extern "C" deklarációt kell alkalmaznunk akkor is, ha C++ nyelven megírt és lefordított függvényeket C programból kívánjuk elérni.
Megjegyezzük, hogy a main () fügvény szintén extern "C" kapcsolódású.
II.3.3. Több modulból felépülő C++ programok
Az előző rész példaprogramjának szerkezete sokkal áttekinthetőbbé válik, ha a MatModul.cpp fájlhoz elkészítjük a modul interfészét leíró MatModul.h fejállományt. Ugyancsak egyszerűbbé válik a konstansok alkalmazása, ha fájl szintű hatókörbe (static) helyezzük őket. Az elmondottak alapján a MatModul.h állomány tartalma:
// MatModul.h
#ifndef _MATMODUL_H_
#define _MATMODUL_H_
#include <cmath>
using namespace std;
// fájl szintű definíciók/deklarációk
const double pi = asin(1)*2;
const double e = exp(1);
static double Fok2Radian(double);
// program szintű deklarációk
int Random(int n);
double Sin(double fok);
#endif
A zöld színnel megvastagított sorok olyan előfeldolgozó utasításokat tartalmaznak, amelyek garantálják, hogy a MatModul.h állomány tartalma pontosan egyszer épül be az
#include "MatModul.h"
utasítást tartalmazó modulba. (A II.4. szakasz - A C++ előfeldolgozó utasításai további információkat tár az Olvasó elé az előfeldolgozó használatáról.)
A fejállomány alkalmazásával a C++ modulok tartalma is megváltozott:
|
|
| |
#include <iostream>
using namespace std;
#include "MatModul.h"
int main() {
for (int i=0; i<5; i++)
cout << Random(12)<< endl;
cout << Sin(45) << endl;
cout << e << endl;
}
|
#include <ctime>
#include <cstdlib>
using namespace std;
#include "MatModul.h"
static bool elsornd = true;
int Random(int n) {
if (elsornd) {
srand((unsigned)time(0));
elsornd = false;
}
return rand() % n;
}
double Sin(double fok) {
return sin(Fok2Radian(fok));
}
static double Fok2Radian(double fok) {
return fok/180*pi;
}
|
A C++ fordítóprogram minden programmodult önállóan fordít, külön tárgymodulokat előállítva. Ezért szükséges, hogy minden modulban szereplő azonosító ismert legyen a fordító számára. Ezt a deklarációk/prototípusok és a definíciók megfelelő elhelyezésével biztosíthatjuk. A fordítást követően a szerkesztőprogram feladata a tárgymodulok összeépítése egyetlen futtatható programmá, a külső kapcsolódások feloldásával magukból a tárgymodulokból vagy a szabványos könyvtárakból.
Az integrált fejlesztői környezetek projektek létrehozásával automatizálják a fordítás és a szerkesztés menetét. A programozó egyetlen feladata: a projekthez hozzáadni az elkészített C++ forrásfájlokat. Általában a Build menüparancs kiválasztásával a teljes fordítási folyamat végbe megy.
A
GNU C++
fordítót az alábbi parancssorral aktivizálhatjuk a fordítás és a szerkesztés elvégzésére, valamint a Projekt.exe futtatható állomány létrehozására:
g++ -o Projekt FoModul.cpp MatModul.cpp
II.3.4. Névterek
A C++ fordító a programban használt neveket (azok felhasználási módjától függően) különböző területeken (névtér, névterület – namespace) tárolja. Egy adott névtéren belül tárolt neveknek egyedieknek kell lenniük, azonban a különböző névterekben azonos nevek is szerepelhetnek. Két azonos név, amelyek azonos hatókörben helyezkednek el, de nincsenek azonos névterületen, különböző azonosítókat jelölnek. A C++ fordító az alábbi névterületeket különbözteti meg:
II.3.4.1. A C++ nyelv alapértelmezett névterei és a hatókör operátor
A C nyelven a fájl szinten definiált változók és függvények (a szabványos könyvtár függvényei is) egyetlen közös névtérben helyezkednek el. A C++ nyelv a szabványos könyvtár elemeit az std névtérbe zárja, míg a többi fájl szinten definiált elemet a globális névtér tartalmazza.
A névterek elemeire való hivatkozáshoz meg kell ismerkednünk a hatókör operátorral (::). A hatókör operátor többször is előfordul könyvünk további fejezeteiben, most csak kétféle alkalmazására mutatunk példát.
A :: operátor segítségével a program tetszőleges blokkjából hivatkozhatunk a fájl- és program szintű hatókörrel rendelkező nevekre, vagyis a globális névtér azonosítóira.
#include <iostream>
using namespace std;
long a = 12;
static int b = 23;
int main() {
double a = 3.14159265;
double b = 2.71828182;
{
long a = 7, b;
b = a * (::a + ::b);
// a b változó értéke 7*(12+23) = 245
::a = 7;
::b = 29;
}
}
Ugyancsak a hatókör operátort alkalmazzuk, ha az std névtérben definiált neveket közvetlenül kívánjuk elérni:
#include <iostream>
int main() {
std::cout<<"C++ nyelv"<<std::endl;
std::cin.get();
}
II.3.4.2. Saját névterek kialakítása és használata
A nagyobb C++ programokat általában több programozó fejleszti. A C++ nyelv eddig bemutatott eszközeivel elkerülhetetlen a globális (program szintű) nevek ütközése, keveredése. A saját névvel ellátott névterek bevezetése megoldást kínál az ilyen problémákra.
II.3.4.2.1. Névterek készítése
A névtereket a forrásfájlokban a függvényeken kívül, illetve a fejállományokban egyaránt létrehozhatjuk. Amennyiben a fordító több azonos nevű névteret talál, azok tartalmát egyesíti, mintegy kiterjesztve a már korábban definiált névteret. A névtér kijelöléséhez a namespace kulcsszót használjuk:
namespace nevter {
deklarációk és definíciók
}
Program szintű névterek tervezése során érdemes különválasztani a fejállományba helyezhető, csak deklarációkat tartalmazó névteret, a definíciók névterétől.
#include <iostream>
#include <string>
// deklarációk
namespace nspelda {
extern int ertek;
extern std::string nev;
void Beolvas(int & a, std::string & s);
void Kiir();
}
// definíciók
namespace nspelda {
int ertek;
std::string nev;
void Kiir() {
std::cout << nev << " = " << ertek << std::endl;
}
}
void nspelda::Beolvas(int & a, std::string & s) {
std::cout << "nev: "; getline(std::cin, s);
std::cout << "ertek: "; std::cin >> a;
}
Amennyiben egy névtérben deklarált függvényt a névtéren kívül hozunk létre, a függvény nevét minősíteni kell a névtér nevével (példánkban nspelda::).
II.3.4.2.2. Névtér azonosítóinak elérése
Az nspelda névtérben megadott azonosítók minden olyan modulból elérhetők, amelybe beépítjük a névtér deklarációkat tartalmazó változatát. A névtér azonosítóit többféleképpen is elérhetjük.
Közvetlenül a hatókör operátor felhasználásával:
int main() {
nspelda::nev = "Osszeg";
nspelda::ertek = 123;
nspelda::Kiir();
nspelda::Beolvas(nspelda::ertek, nspelda::nev);
nspelda::Kiir();
std::cin.get();
}
A using namespace direktíva alkalmazásával:
Természetesen sokkal kényelmesebb megoldáshoz jutunk, ha az összes nevet elérhetővé tesszük a programunk számára a using namespace direktívával:
using namespace nspelda;
int main() {
nev = "Osszeg";
ertek = 123;
Kiir();
Beolvas(ertek, nev);
Kiir();
std::cin.get();
}
A using deklarációk megadásával
A using deklarációk segítségével a névtér elemei közül csak a számunkra szükségeseket tesszük egyszerűen elérhetővé. Ezt a megoldást kell használnunk akkor is, ha a névtér bizonyos azonosítóval névütközés áll fent.
int Kiir() {
std::cout << "Nevutkozes" << std::endl;
return 1;
}
int main() {
using nspelda::nev;
using nspelda::ertek;
using nspelda::Beolvas;
nev = "Osszeg";
ertek = 123;
nspelda::Kiir();
Beolvas(ertek, nev);
Kiir();
std::cin.get();
}
II.3.4.2.3. Névterek egymásba ágyazása, névtér álnevek
A C++ lehetőséget ad arra, hogy a névterekben újabb névtereket hozzunk létre, vagyis egymásba ágyazzuk őket (nested namespaces). Ezzel a megoldással a globális neveinket strukturált rendszerbe szervezhetjük. Példaként tekintsük a Projekt névteret, amelyben processzorcsaládonként különböző függvényeket definiálunk!
namespace Projekt {
typedef unsigned char byte;
typedef unsigned short word;
namespace Intel {
word ToWord(byte lo, byte hi) {
return lo + (hi<<8);
}
}
namespace Motorola {
word ToWord(byte lo, byte hi) {
return hi + (lo<<8);
}
}
}
Az Projekt névtér elemeit többféleképpen is elérhetjük:
using namespace Projekt::Intel;
int main() {
cout << hex;
cout << ToWord(0xab,0x12)<< endl; // 12ab
}
// -------------------------------------------------------
int main() {
using Projekt::Motorola::ToWord;
cout << hex;
cout << ToWord(0xab,0x12)<< endl; // ab12
}
// -------------------------------------------------------
using namespace Projekt;
int main() {
cout << hex;
cout << Intel::ToWord(0xab,0x12)<< endl; // 12ab
cout << Motorola::ToWord(0xab,0x12)<< endl; // ab12
}
// -------------------------------------------------------
int main() {
cout<<hex;
cout<<Projekt::Intel::ToWord(0xab,0x12)<< endl; // 12ab
cout<<Projekt::Motorola::ToWord(0xab,0x12)<<endl; // ab12
}
A bonyolult, sokszorosan egymásba ágyazott névterek elemeinek elérésékor használt névtérnevek hatókör operátorral összekapcsolt láncolata igencsak rontja a forráskód olvashatóságát. Erre a problémára megoldást ad a névtér álnevek (alias) bevezetése:
namespace alnev =kulsoNS::belsoNS … ::legbelsoNS;
Az álnevek segítségével a fenti példa sokkal egyszerűbb formát ölt:
int main() {
namespace ProcI = Projekt::Intel;
namespace ProcM = Projekt::Motorola;
cout << hex;
cout << ProcI::ToWord(0xab,0x12)<< endl; // 12ab
cout << ProcM::ToWord(0xab,0x12)<< endl; // ab12
}
II.3.4.2.4. Névtelen névterek
A C++ szabvány sem a fájl szintű hatókörben, sem pedig a névterekben nem támogatja a static kulcsszó használatát. A modul szintű hatókörben a névtelen névterekben hozhatunk létre olyan változókat és függvényeket, amelyek a fordítási egységen kívülről nem érhetők el. Azonban a modulon belül minden korlátozás nélkül felhasználhatók névtelen névterek azonosítói.
Egyetlen modulon belül több névtelen névteret is megadhatunk:
#include <iostream>
#include <string>
using namespace std;
namespace {
string jelszo;
}
namespace {
bool JelszoCsere() {
bool sikeres = false;
string regi, uj1, uj2;
cout << "Regi jelszo: "; getline(cin, regi);
if (jelszo == regi) {
cout << "Uj jelszo: "; getline(cin, uj1);
cout << "Uj jelszo: "; getline(cin, uj2);
if (uj1==uj2) {
jelszo = uj1;
sikeres = true;
}
}
return sikeres;
} // JelszoCsere()
}
int main() {
jelszo = "qwerty";
if (JelszoCsere())
cout << "Sikeres jelszocsere!" << endl;
else
cout << "Sikertelen jelszocsere!" << endl;
}
II.4. A C++ előfeldolgozó utasításai
Minden C és C++ fordítóprogram szerves részét képezi az ún. előfeldolgozó (preprocessor), amely semmit nem tud a C++ nyelvről. Egyedüli feladata a program forrásállományaiból a tiszta C++ kódú programmodul előállítása szövegkezelési műveletekkel. Ebből következik, hogy a C++ fordító nem azt a forráskódot fordítja, amit mi előállítunk, hanem az előfeldolgozó működésének eredményeként megjelenő szöveget dolgozza fel (lásd II.8. ábra - A C++ fordítás folyamata). Könnyen beláthatjuk, hogy az előfeldolgozó utasításaiból származó C++ programhibák kiderítése nem egyszerű feladat.
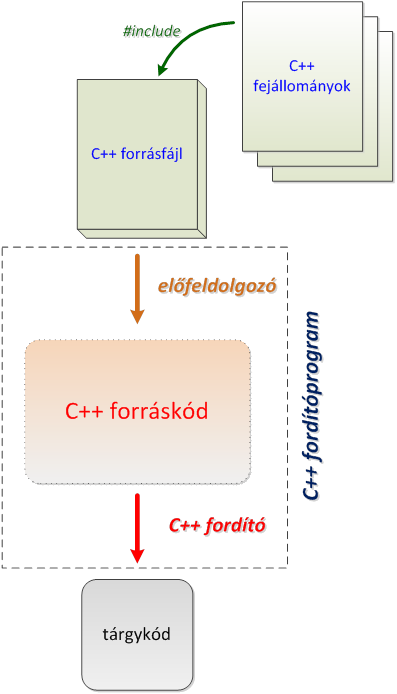
A C++ fordítóprogramok többségében az előfeldolgozás és a tényleges fordítás nem válik külön, azaz nem jelenik meg az előfordító kimenete valamilyen szöveges állományban. (Megjegyezzük, hogy GNU C++ nyelv g++ fordítója a –E kapcsoló hatására csak előfordítást végez.)
Az előfeldolgozó valójában egy makrónyelven programozható, sororientált szövegkezelő program, amelyre nem vonatkoznak a C++ nyelv szabályai:
az előfeldolgozó utasításait nem írhatjuk olyan kötetlen formában, mint a C++ utasításokat (tehát egy sorba csak egy utasítás kerülhet, és a parancsok nem csúszhatnak át másik sorba, hacsak nem jelölünk ki folytató sort),
az előfeldolgozó által elvégzett minden művelet egyszerű szövegkezelés (függetlenül attól, hogy a C++ nyelv kulcsszavai, kifejezései vagy változói szerepelnek benne).
A előfeldolgozó utasításai (direktívái) a sor elején kettős kereszt (#) karakterrel kezdődnek. A leggyakoribb műveletei a szöveghelyettesítés ( #define ), a szöveges állomány beépítése ( #include ) valamint a program részeinek feltételtől függő megtartása ( #if ).
A C++ nyelv teljes mértékben a C nyelv előfeldolgozási lehetőségeire támaszkodik. Mivel az előfeldolgozás kívül esik a szigorúan típusos C++ fordító hatáskörén, a C++ nyelv az újonnan bevezetett megoldásaival igyekszik minimálisra csökkenteni az előfeldolgozó használatának szükségességét. A C++ programban az előfeldolgozó bizonyos utasításait C++ megoldásokkal helyettesíthetjük: a #define konstansok helyett const állandókat használhatunk, a #define makrók helyett pedig inline függvénysablonokat készíthetünk.
II.4.1. Állományok beépítése
Az előfeldolgozó az #include direktíva hatására az utasításban szereplő szöveges fájl tartalmát beépíti (beszúrja) a programunkba, a direktíva helyére. Általában a deklarációkat és előfeldolgozó utasításokat tartalmazó fejállományokat (header fájlokat) szoktuk beépíteni a programunk elejére, azonban tetszőleges szöveges fájlra is alkalmazható a művelet.
#include <elérési út> #include "elérési út"
Az első formát a C++ rendszer szabványos fejállományainak beépítésére használjuk a fejlesztői környezet include mappájából:
#include <iostream> #include <cmath> #include <cstdlib> #include <ctime> using namespace std;
A második pedig a nem szabványos fájlok beépítését segíti a C++ modult tároló mappából, illetve a megadott helyről:
#include "Modul.h" #include "..\Kozos.h"
Az alábbi táblázatban összefoglaltuk azokat a nyelvi elemeket, amelyeket fejállományban szerepeltethetünk:
|
C++ nyelvi elem |
Példa |
|---|---|
|
Megjegyzések |
|
|
Feltételes fordítási direktívák |
|
|
Makró-definíciók |
|
|
#include direktívák |
|
|
Felsorolások |
|
|
Konstansdefiníciók |
|
|
Névvel ellátott névterületek |
|
|
Névdeklarációk |
|
|
Típusdefiníciók |
|
|
Változó-deklarációk |
|
|
Függvény prototípusok |
|
|
inline függvény-definíciók |
|
|
sablon deklarációk |
|
|
sablon definíciók |
|
Az alábbi nyelvi elemeket semmilyen körülmények között ne helyezzük include állományokba!
a nem inline függvények definícióját,
változó-definíciókat,
a névtelen névtér definícióját.
A fejállományba helyezhető nyelvi konstrukciók egy részét csak egyetlen egyszer szabad beépíteni a programunkba. Ennek érdekében minden header fájlban egy speciális előfeldolgozó szerkezetet kell kialakítunk, a feltételes fordítás eszköztárát használva:
// Modul.h
#ifndef _MODUL_H_
#define _MODUL_H_
a fejállomány tartalma
#endif
II.4.2. Feltételes fordítás
A feltételes fordítás lehetőségeinek alkalmazásával elérhetjük, hogy a forrásprogram bizonyos részei csak adott feltételek teljesülése esetén kerüljenek be az előfeldolgozó által előállított C++ programba. A feltételesen fordítandó programrészeket többféleképpen is kijelölhetjük, a különböző előfeldolgozó direktívák felhasználásával: #if, #ifdef, #ifndef, #elif, #else és #endif.
Az #if utasításban a feltétel megadására konstans kifejezést használunk, melyek nem nulla értéke jelöli az igaz, míg a 0 a hamis feltételt. A kifejezésben csak egész és karakter konstansok valamint a defined művelet szerepelhetnek.
#if 'O' + 29 == ERTEK
A feltételben a defined operátorral ellenőrizhetjük, hogy egy szimbólum definiált-e vagy sem. Az operátor 1 értékkel tér vissza, ha az operandusa létezik, ellenkező esetben 0-át ad:
#if defined szimbólum #if defined(szimbólum)
Mivel gyakran használunk ehhez hasonló vizsgálatokat, ezért valamely szimbólum létezésének tesztelésre külön előfeldolgozó utasítások állnak a rendelkezésünkre:
#ifdef szimbólum #if defined(szimbólum) #ifndef szimbólum #if !defined(szimbólum)
Az #if segítségével bonyolultabb feltételek is megfogalmazhatunk:
#if 'O' + 29 == ERTEK && (!defined(NEV) || defined(SZAM))
Az alábbi egyszerű szerkezettel az #if és az #endif sorok közé zárt programrész fordítási egységben való maradásáról dönthetünk:
#if konstans_kifejezés
programrész
#endif
Ez a szerkezet jól használható hibakeresést segítő információk beépítésére a programba. Ekkor egyetlen szimbólum (TESZT) 1 értékével elérhetjük a kiegészítő információkat megjelenítő programsorok befordítását a kódba, 0 értékkel pedig letilthatjuk azt:
#define TESZT 1
int main() {
const int meret = 5;
int tomb[meret] = { 12, 23, 34, 45, 56 };
int i;
for (int i = 0; i < meret; i++) {
tomb[i] *= 2;
#if TESZT != 0
cout << "i = " << i << endl;
cout << "\ttomb[i] = " << tomb[i] << endl;
#endif
}
}
A fenti szerkezet helyett szerencsésebb a TESZT szimbólum definiáltságát vizsgáló megoldást használni, melyhez a TESZT érték nélkül is definiálható, akár a kívülről, a fordítóprogram paramétereként megadva:
#define TESZT
int main() {
const int meret = 5;
int tomb[meret] = { 12, 23, 34, 45, 56 };
int i;
for (int i = 0; i < meret; i++) {
tomb[i] *= 2;
#if defined(TESZT)
cout << "i = " << i << endl;
cout << "\ttomb[i] = " << tomb[i] << endl;
#endif
}
}
Az alábbi vizsgálatok páronként ugyanazt az eredményt szolgáltatják:
#if defined(TESZT) ... // definiált #endif |
#ifdef TESZT ... // definiált #endif | |
#if !defined(TESZT) ... // nem definiált #endif |
#ifndef TESZT ... // nem definiált #endif |
A következő szerkezet segítségével két programrész közül választhatunk:
#if konstans_kifejezés
programrész1
#else
programrész2
#endif
A példában a tomb kétdimenziós tömböt a MERET szimbólum értékétől függően különbözőképpen hozzuk létre:
#define MERET 5
int main() {
#if MERET <= 2
int tomb[2][2];
const int meret = 2;
#else
int tomb[MERET][MERET];
const int meret = MERET;
#endif
}
Bonyolultabb szerkezetek kialakításához a többirányú elágaztatás megvalósító előfordító utasítást ajánlott használni
#if konstans_kifejezés1
programrész1
#elif konstans_kifejezés2
programrész2
#else
programrész3
#endif
Az alábbi példában a gyártótól függően építünk be deklarációs állományt a programunkba:
#define IBM 1
#define HP 2
#define ESZKOZ IBM
#if ESZKOZ == IBM
#define ESZKOZ_H "ibm.h"
#elif ESZKOZ == HP
#define ESZKOZ_H "hp.h"
#else
#define ESZKOZ_H "mas.h"
#endif
#include ESZKOZ_H
II.4.3. Makrók használata
Az előfordító használatának legvitatottabb területe a #define makrók alkalmazása a C++ programokban. Ennek oka, hogy a makrók feldolgozásának eredménye nem mindig találkozik a programozó elvárásaival. A makrókat igen széleskörűen alkalmazzák a C nyelven készült programokban, azonban C++ nyelven a jelentőségük csökkent. A C++ nyelv definíciója előnyben részesíti a const és az inline függvénysablonokat a makrókkal szemben. Az alábbi áttekintésben a biztonságos makró-használatot tartjuk szem előtt.
A #define direktívát arra használjuk, hogy azonosítókkal lássuk el a C++ konstans értékeket, a kulcsszavakat, illetve a gyakran használt utasításokat és kifejezéseket. Az előfordító számára definiált szimbólumokat makróknak nevezzük. A C++ forráskódban a makróneveket csupa nagybetűvel ajánlott írni, hogy jól elkülönüljenek a programban használt C++ nevektől.
Az előfeldolgozó soronként megvizsgálja a forrásprogramot, hogy azok tartalmaznak-e valamilyen korábban definiált makrónevet. Ha igen, akkor azt lecseréli a megfelelő helyettesítő szövegre, majd újból megvizsgálja a sort, további makrókat keresve, amit ismételt helyettesítés követhet. Ezt a folyamatot makróhelyettesítésnek vagy makrókifejtésnek nevezzük. A makrókat a #define utasítással hozzuk létre, és az #undef direktíva segítségével semmisítjük meg.
II.4.3.1. Szimbolikus konstansok
Szimbolikus konstansok készítéséhez a #define direktíva egyszerű alakját alkalmazzuk:
#define azonosító #define azonosító helyettesítő_szöveg
Nézzünk néhány példát a szimbolikus konstansok definiálására és használatára!
#define MERET 4
#define DEBUG
#define AND &&
#define VERZIO "v1.2.3"
#define BYTE unsigned char
#define EOS '\0'
int main() {
int v[MERET];
BYTE m = MERET;
if (m > 2 AND m < 5)
cout << "2 < m < 5" << endl;
#ifdef DEBUG
cout << VERZIO << endl;
#endif
}
Az előfeldolgozás (helyettesítések) eredményeként keletkező forrásfájl:
int main() {
int v[4];
unsigned char m = 4;
if (m > 2 && m < 5)
cout << "2 < m < 5" << endl;
cout << "v1.2.3" << endl;
}
C++-ban a fenti szimbolikus konstansok egy része helyett const és typedef azonosítókat is használhatunk:
#define DEBUG
#define AND &&
const int meret = 4;
const string verzio = "v1.2.3";
const char eos = '\0';
typedef unsigned char byte;
int main() {
int v[meret];
byte m = meret;
if (m > 2 AND m < 5)
cout << "2 < m < 5" << endl;
#ifdef DEBUG
cout << verzio << endl;
#endif
}
II.4.3.2. Paraméteres makrók
A makrók felhasználási területét lényegesen bővíti a makrók paraméterezésének lehetősége. A függvényszerű, paraméteres makrók definíciójának általános formája:
#define azonosító(paraméterlista) helyettesítő_szöveg
A makró használata (hívása):
azonosító(argumentumlista)
A makróhívásban szereplő argumentumok számának meg kell egyeznie a definícióban szereplő paraméterek számával.
Annak érdekében, hogy a paraméteres makróink biztonságosan működjenek, be kell tartanunk a következő két szabály:
A makró paramétereit a makró törzsében (a helyettesítő szövegben) mindig tegyük zárójelek közé!
Ne használjunk léptető (++, --) operátort a makró hívásakor az argumentumlistában!
Az alábbi példaprogramban bemutatunk néhány gyakran használt makró-definíciót és a hívásukat:
// x abszolút értékének meghatározása
#define ABS(x) ( (x) < 0 ? (-(x)) : (x) )
// a és b maximumának kiszámítása
#define MAX(a,b) ( (a) > (b) ? (a) : (b) )
// négyzetre emelés
#define SQR(X) ( (X) * (X) )
// véletlen szám a megadott intervallumban
#define RANDOM(min, max) \
((rand()%(int)(((max) + 1)-(min)))+ (min))
int main() {
int x = -5;
x = ABS(x);
cout << SQR(ABS(x));
int a = RANDOM(0,100);
cout << MAX(a, RANDOM(12,23));
}
A RANDOM() makró első sorának végén álló fordított perjel azt jelzi, hogy a makró-definíció a következő sorban folytatódik. A main () függvény tartalma az előfordítást követően egyáltalán nem nevezhető jól olvashatónak:
int main() {
int x = -5;
x = ( (x) < 0 ? (-(x)) : (x) );
cout << ( (( (x) < 0 ? (-(x)) : (x) )) *
(( (x) < 0 ? (-(x)) : (x) )) );
int a = ((rand()%(int)(((100) + 1)-(0)))+ (0));
cout << ( (a) > (((rand()%(int)(((23) + 1)-(12)))+ (12)))
? (a) : (((rand()%(int)(((23) + 1)-(12)))+ (12))) );
}
A C++ program olvashatóságának megtartásával elérhetjük a makróhasználat összes előnyét (típusfüggetlenség, gyorsabb kód), ha a makrók helyett inline függvényt/függvénysablont használunk:
template <class tip> inline tip Abs(tip x) {
return x < 0 ? -x : x;
}
template <class tip> inline tip Max(tip a, tip b) {
return a > b ? a : b;
}
template <class tip> inline tip Sqr(tip x) {
return x * x;
}
inline int Random(int min, int max) {
return rand() % (max + 1 - min) + min;
}
int main() {
int x = -5;
x = Abs(x);
cout << Sqr(Abs(x));
int a = Random(0,100);
cout << Max(a, Random(12,23));
}
II.4.3.3. Makrók törlése
Egy makró bármikor törölhető, illetve újra létrehozható akár más tartalommal is. A törléshez az #undef direktívát kell használnunk. Egy makró új tartalommal történő átdefiniálása előtt mindig meg kell szüntetnünk a régi definíciót. Az #undef utasítás nem jelez hibát, ha a törölni kívánt makró nem létezik:
#undef azonosító
Az alábbi példában nyomon követhetjük a #define és az #undef utasítások működését:
|
Eredeti forráskód |
Kifejtett programkód |
|---|---|
int main() {
#define MAKRO(x) (x) + 7
int a = MAKRO(12);
#undef MAKRO
a = MAKRO(12);
#define MAKRO 123
a = MAKRO
}
|
int main() {
int a = (12) + 7;
a = MAKRO(12);
a = 123
}
|
II.4.3.4. Makróoperátorok
Az eddigi példáinkban a helyettesítést csak különálló paraméterek esetén végezte el az előfeldolgozó. Vannak esetek, amikor a paraméter valamely azonosítónak a része, vagy az argumentum értékét sztringként kívánjuk felhasználni. Ha a helyettesítést ekkor is el kell végezni, akkor a ## , illetve a # makróoperátorokat kell használnunk.
A # karaktert a makróban a paraméter elé helyezve, a paraméter értéke idézőjelek között (sztringként) helyettesítődik be. Ezzel a megoldással sztringben is lehetséges a behelyettesítés, hisz a fordító az egymás mellett álló sztringliterálokat egyetlen sztring konstanssá kapcsolja össze. Az alábbi példában az INFO() makró segítségével tetszőleges változó neve és értéke megjeleníthető:
#include <iostream>
using namespace std;
#define INFO(valtozo) \
cout << #valtozo " = " << valtozo <<endl;
int main() {
unsigned x = 23;
double pi = 3.14259265;
string s = "C++ nyelv";
INFO(x);
INFO(s);
INFO(pi);
}
x = 23 s = C++ nyelv pi = 3.14259 |
A ## operátor megadásával két szintaktikai egységet (tokent) lehet összeforrasztani oly módon, hogy a makró törzsében a ## operátort helyezzük a paraméterek közé.
A alábbi példában szereplő SZEMELY() makró segít feltölteni a szemelyek tömb struktúra típusú elemeit:
#include <string>
using namespace std;
struct szemely {
string nev;
string info;
};
string Ivan_Info ="K. Ivan, Budapest, 9";
string Aliz_Info ="O. Aliz, Budapest, 33";
#define SZEMELY(NEV) { #NEV, NEV ## _Info }
int main(){
szemely szemelyek[] = {
SZEMELY (Ivan),
SZEMELY (Aliz)
};
}
A main () függvény tartalma az előfeldolgozás után:
int main(){
szemely szemelyek[] = {
{ "Ivan", Ivan_Info },
{ "Aliz", Aliz_Info }
};
}
Vannak esetek, amikor egyetlen makró megírásával nem érünk célt. Az alábbi példában a verziószámot sztringben rakjuk össze a megadott szimbolikus konstansokból:
#define FO 7 #define MELLEK 29 #define VERZIO(fo, mellek) VERZIO_SEGED(fo, mellek) #define VERZIO_SEGED(fo, mellek) #fo "." #mellek static char VERZIO1[]=VERZIO(FO,MELLEK); // "7.29" static char VERZIO2[]=VERZIO_SEGED(FO,MELLEK); // "FO.MELLEK"
II.4.3.5. Előre definiált makrók
Az ANSI C++ szabvány az alábbi, előre definiált makrókat tartalmazza. (Az azonosítók majd mindegyike két aláhúzás jellel kezdődik és végződik.) Az előre definiált makrók nevét nem lehet sem a #define sem pedig az #undef utasításokban szerepeltetni. Az előre definiált makrók értékét beépíthetjük a program szövegébe, de feltételes fordítás feltételeként is felhasználhatjuk.
|
Makró |
Leírás |
Példa |
|---|---|---|
|
|
A fordítás dátumát tartalmazó sztring konstans. |
|
|
|
A fordítás időpontját tartalmazó sztring konstans. |
|
|
|
A forrásfájl utolsó módosításának dátuma és ideje sztring konstansban" |
|
|
|
A forrásfájl nevét tartalmazó sztring konstans. |
|
|
|
A forrásállomány aktuális sorának sorszámát tartalmazó szám konstans (1-től sorszámoz). |
|
|
|
Az értéke 1, ha a fordító ANSI C++ fordítóként működik, különben nem definiált. | |
|
|
Az értéke 1, ha C++ forrásállományban teszteljük az értékét, különben nem definiált. |
II.4.4. A #line, az #error és a #pragma direktívák
Több olyan segédprogram is létezik, amely valamilyen speciális nyelven megírt programot C++ forrásállománnyá alakít át (programgenerátor).
A #line direktíva segítségével elérhető, hogy a C++ fordító ne a C++ forrásszövegben jelezze a hiba sorszámát, hanem az eredeti speciális nyelven megírt forrásfájlban. (A #line utasítással beállított sorszám és állománynév a __LINE__ illetve a __FILE__ szimbólumok értékében is megjelennek.)
#line kezdősorszám #line kezdősorszám "fájlnév"
Az #error direktívát a programba elhelyezve fordítási hibaüzenet jeleníthetünk meg, amely az utasításban megadott szöveget tartalmazza:
#error hibaüzenet
Az alábbi példában a fordítás hibaüzenettel zárul, ha nem C++ módban dolgozunk:
#if !defined(__cplusplus)
#error A fordítás csak C++ módban végezhető el!
#endif
A #pragma direktíva a fordítási folyamat implementációfüggő vezérlésére szolgál. (A direktívához nem kapcsolódik semmilyen szabványos megoldás.)
#pragma parancs
Ha a fordító valamilyen ismeretlen #pragma utasítást talál, akkor azt figyelmen kívül hagyja. Ennek következtében a programok hordozhatóságát nem veszélyezteti ez a direktíva. Például, a struktúratagok különböző határra igazítása, illetve a megadott sorszámú figyelmeztető fordítási üzenetek megjelenítésének tiltása az alábbi formában végezhető el:
#pragma pack(8) // 8 bájtos határra igazít #pragma pack(push, 1) // bájthatárra igazít #pragma pack(pop) // ismét 8 bájtos határra igazít #pragma warning( disable : 2312 79 )
Létezik még az üres direktíva is (#), amelynek semmilyen hatása sincs az előfeldolgozásra:
#
III. fejezet - Objektum-orientált programozás C++ nyelven
- III.1. Bevezetés az objektum-orientált világba
- III.2. Osztályok és objektumok
- III.2.1. A struktúráktól az osztályokig
- III.2.2. Az osztályokról bővebben
- III.2.3. Operátorok túlterhelése (operator overloading)
- III.3. Öröklés (származtatás)
- III.4. Polimorfizmus (többalakúság)
- III.5. Osztálysablonok (class templates)
Az objektum-orientált programozás (OOP) olyan modern programozási módszertan (paradigma), amely a program egészét egyedi jellemzőkkel rendelkező, önmagukban is működőképes, zárt programegységek (objektumok) halmazából építi fel. Az objektum-orientált programozás a klasszikus strukturált programozásnál jóval hatékonyabb megoldást nyújt a legtöbb problémára, és az absztrakt műveletvégző objektumok kialakításának és újrafelhasználásának támogatásával nagymértékben tudja csökkenteni a szoftverek fejlesztéséhez szükséges időt.
III.1. Bevezetés az objektum-orientált világba
Az objektum-orientált programozás a „dolgokat” („objektumokat”) és köztük fennálló kölcsönhatásokat használja alkalmazások és számítógépes programok tervezéséhez. Ez a módszertan olyan megoldásokat foglal magában, mint a bezárás (encapsulation), a modularitás (modularity), a többalakúság (polymorphism) valamint az öröklés (inheritance).
Felhívjuk a figyelmet arra, hogy az OOP nyelvek általában csak eszközöket és támogatást nyújtanak az objektum-orientáltság elveinek megvalósításához. Könyvünkben egy rövid áttekintés után, mi is csak az eszközök bemutatására szorítkozunk.
III.1.1. Alapelemek
Először ismerkedjünk meg az objektum-orientált témakör alapelemeivel! A megértéshez nem szükséges mély programozási ismeret megléte.
Osztály (class)
Az osztály (class) meghatározza egy dolog (objektum) elvont jellemzőit, beleértve a dolog jellemvonásait (attribútumok, mezők, tulajdonságok) és a dolog viselkedését (amit a dolog meg tud tenni, metódusok (módszerek), műveletek, funkciók).
Azt mondhatjuk, hogy az osztály egy tervrajz, amely leírja valaminek a természetét. Például, egy Teherautó osztálynak tartalmazni kell a teherautók közös jellemzőit (gyártó, motor, fékrendszer, maximális terhelés stb.), valamint a fékezés, a balra fordulás stb. képességeket (viselkedés).
Osztályok önmagukban biztosítják a modularitást és a strukturáltságot az objektum-orientált számítógépes programok számára. Az osztálynak értelmezhetőnek kell lennie a probléma területén jártas, nem programozó emberek számára is, vagyis az osztály jellemzőinek „beszédesnek” kell lenniük. Az osztály kódjának viszonylag önállónak kell lennie (bezárás – encapsulation). Az osztály beépített tulajdonságait és metódusait egyaránt az osztály tagjainak nevezzük (C++-ban adattag, tagfüggvény).
Objektum (object)
Az osztály az objektum mintája (példája). A Teherautó osztály segítségével minden lehetséges teherautót megadhatunk, a tulajdonságok és a viselkedési formák felsorolásával. Például, a Teherautó osztály rendelkezik fékrendszerrel, azonban az énAutóm (objektum) fékrendszere elektronikusvezérlésű (EBS) vagy egyszerű légfékes is lehet.
Példány (instance)
Az objektum szinonimájaként az osztály egy adott példányáról is szokás beszélni. A példány alatt a futásidőben létrejövő aktuális objektumot értjük. Így elmondhatjuk, hogy az énAutóm a Teherautó osztály egy példánya. Az aktuális objektum tulajdonságértékeinek halmazát az objektum állapotának (state) nevezzük. Ezáltal minden objektumot az osztályban definiált állapot és viselkedés jellemez.
Metódus (method)
Metódusok felelősek az objektumok képességeiért. A beszélt nyelvben az igéket hívhatjuk metódusoknak. Mivel az énAutóm egy Teherautó, rendelkezik a fékezés képességével, így a Fékez() ez énAutóm metódusainak egyike. Természetesen további metódusai is lehetnek, mint például az Indít(), a GáztAd(), a BalraFordul() vagy a JobbraFordul(). A programon belül egy metódus használata általában csak egy adott objektumra van hatással. Bár minden teherautó tud fékezni, a Fékez() metódus aktiválásával (hívásával) csak egy adott járművet szeretnénk lassítani. C++ nyelven a metódus szó helyett a tagfüggvény kifejezést használjuk.

Üzenetküldés (message passing)
Az üzenetküldés az a folyamat, amelynek során egy objektum adatokat küld egy másik objektumnak, vagy “megkéri” a másik objektumot valamely metódusának végrehajtására. Az üzenetküldés szerepét jobban megértjük, ha egy teherautó szimulációjára gondolunk. Ebben egy sofőr objektum a „fékezz” üzenet küldésével aktiválhatja az énAutóm Fékez() metódusát, lefékezve ezzel a járművet. Az üzenetküldés szintaxisa igen eltérő a különböző programozási nyelvekben. C++ nyelven a kódszintű üzenetküldést a metódushívás valósítja meg.
III.1.2. Alapvető elvek
Egy rendszer, egy programnyelv objektum-orientáltságát az alábbi elvek támogatásával lehet mérni. Amennyiben csak néhány elv valósul meg, objektum-alapú rendszerről beszélünk, míg mind a négy elv támogatása az objektum-orientált rendszerek sajátja.
III.1.2.1. Bezárás, adatrejtés (encapsulation , data hiding)
A fentiekben láttuk, hogy az osztályok alapvetően jellemzőkből (állapot) és metódusokból (viselkedés) épülnek fel. Azonban az objektumok állapotát és viselkedését két csoportba osztjuk. Lehetnek olyan jellemzők és metódusok, melyeket elfedünk más objektumok elől, mintegy belső, privát (private, védett - protected) állapotot és viselkedést létrehozva. Másokat azonban nyilvánossá (public) teszünk. Az OOP alapelveinek megfelelően az állapotjellemzőket privát eléréssel kell megadnunk, míg a metódusok többsége nyilvános lehet. Szükség esetén a privát jellemzők ellenőrzött elérésére nyilvános metódusokat készíthetünk.
Általában is elmondhatjuk, hogy egy objektum belső világának ismeretére nincs szüksége annak az objektumnak, amelyik üzenetet küld. Például, a Teherautó rendelkezik a Fékez() metódussal, amely pontosan definiálja, miként megy végbe a fékezés. Az énAutóm vezetőjének azonban nem kell ismernie, hogyan is fékez a kocsi.
Minden objektum egy jól meghatározott interfészt biztosít a külvilág számára, amely megadja, hogy kívülről mi érhető el az objektumból. Az interfész rögzítésével az objektumot használó, ügyfél alkalmazások számára semmilyen problémát sem jelent az osztály belső világának jövőbeni megváltoztatása. Így például egy interfészen keresztül biztosíthatjuk, hogy pótkocsikat csak a Kamion osztály objektumaihoz kapcsoljunk.
III.1.2.2. Öröklés (inheritance)
Öröklés során egy osztály specializált változatait hozzuk létre, amelyek öröklik a szülőosztály (alaposztály) jellemzőit és viselkedését, majd pedig sajátként használják azokat. Az így keletkező osztályokat szokás alosztályoknak (subclass), vagy származtatott (derived) osztályoknak hívni.
Például, a Teherautó osztályból származtathatjuk a Kisteherautó és a Kamion alosztályokat. Az énAutóm ezentúl legyen a Kamion osztály példánya! Tegyük fel továbbá, hogy a Teherautó osztály definiálja a Fékez() metódust és az fékrendszer tulajdonságot! Minden ebből származtatott osztály (Kisteherautó és a Kamion) örökli ezeket a tagokat, így a programozónak csak egyszer kell megírnia a hozzájuk tartozó kódot.
Az alosztályok meg is változtathatják az öröklött tulajdonságokat. Például, a Kisteherautó osztály előírhatja, hogy a maximális terhelése 20 tonna. A Kamion alosztály pedig az EBS fékezést teheti alapértelmezetté a Fékez() metódusa számára.
A származtatott osztályokat új tagokkal is bővíthetjük. A Kamion osztályhoz adhatunk egy Navigál() metódust. Az elmondottak alapján egy adott Kamion példány Fékez() metódusa EBS alapú fékezést alkalmaz, annak ellenére, hogy a Teherautó osztálytól egy hagyományos Fékez() metódust örökölt; rendelkezik továbbá egy új Navigál() metódussal, ami azonban nem található meg a Kisteherautó osztályban.
Az öröklés valójában „egy” (is-a) kapcsolat: az énAutóm egy Kamion, a Kamion pedig egy Teherautó. Így az énAutóm egyaránt rendelkezik a Kamion és a Teherautó metódusaival.
A fentiekben mindkét származtatott osztálynak pontosan egy közvetlen szülő ősosztálya volt, a Teherautó. Ezt az öröklési módot egyszeres öröklésnek (single inheritance) nevezzük, megkülönböztetve a többszörös örökléstől.
A többszörös öröklés (multiple inheritance) folyamán a származtatott osztály, több közvetlen ősosztály tagjait örökli. Például, egymástól teljesen független osztályokat definiálhatunk Teherautó és Hajó néven. Ezekből pedig örökléssel létrehozhatunk egy Kétéltű osztályt, amely egyaránt rendelkezik a teherautók és hajók jellemzőivel és viselkedésével. A legtöbb programozási nyelv (ObjectPascal, Java, C#) csak az egyszeres öröklést támogatja, azonban a C++-ban mindkét módszer alkalmazható.
III.1.2.3. Absztrakció (abstraction)
Az elvonatkoztatás a probléma megfelelő osztályokkal való modellezésével egyszerűsíti az összetett valóságot, valamint a probléma - adott szempontból - legmegfelelőbb öröklési szintjén fejti ki hatását. Például, az énAutóm az esetek nagy többségében Teherautóként kezelhető, azonban lehet Kamion is, ha szükségünk van a Kamion specifikus jellemzőkre és viselkedésre, de tekinthetünk rá Járműként is, ha egy flotta elemeként vesszük számba. (A Jármű a példában a Teherautó szülő osztálya.)
Az absztrakcióhoz a kompozíción keresztül is eljuthatunk. Például, egy Autó osztálynak tartalmaznia kell egy motor, sebességváltó, kormánymű és egy sor más komponenst. Ahhoz, hogy egy Autót felépítsünk, nem kell tudnunk, hogyan működnek a különböző komponensek, csak azt kell ismernünk, miként kapcsolódhatunk hozzájuk (interfész). Az interfész megmondja, miként küldhetünk nekik, illetve fogadhatunk tőlük üzenetet, valamint információt ad arról, hogy az osztályt alkotó komponensek milyen kölcsönhatásban vannak egymással.
III.1.2.4. Polimorfizmus (polymorphism)
A polimorfizmus lehetővé teszi, hogy az öröklés során bizonyos (elavult) viselkedési formákat (metódusokat) a származtatott osztályban új tartalommal valósítsunk meg, és az új, lecserélt metódusokat a szülő osztály tagjaiként kezeljük.
Példaként tegyük fel, hogy a Teherautó és a Kerekpár osztályok öröklik a Jármű osztály Gyorsít() metódusát. A Teherautó esetén a Gyorsít() parancs a GáztAd() műveletet jelenti, míg Kerekpár esetén a Pedáloz() metódus hívását. Ahhoz, hogy a gyorsítás helyesen működjön, a származtatott osztályok Gyorsít() metódusával felül kell bírálnunk (override) a Jármű osztálytól örökölt Gyorsít() metódust. Ez a felülbíráló polimorfizmus.
A legtöbb OOP nyelv a parametrikus polimorfizmust is támogatja, ahol a metódusokat típusoktól független módon, mintegy mintaként készítjük el a fordító számára. A C++ nyelven sablonok (templates) készítésével alkalmazhatjuk ezt a lehetőséget.
III.1.3. Objektum-orientált C++ programpélda
Végezetül nézzük meg az elmondottak alapján elkészített C++ programot! Most legfontosabb az első benyomás, hiszen a részletekkel csak a könyvünk további részeiben ismerkedik meg az Olvasó.
#include <iostream>
#include <string>
using namespace std;
class Teherauto {
protected:
string gyarto;
string motor;
string fekrendszer;
string maximalis_terheles;
public:
Teherauto(string gy, string m, string fek,
double teher) {
gyarto = gy;
motor = m;
fekrendszer = fek;
maximalis_terheles = teher;
}
void Indit() { }
void GaztAd() { }
virtual void Fekez() {
cout<<"A hagyomanyosan fekez."<< endl;
}
void BalraFordul() { }
void JobbraFordul() { }
};
class Kisteherauto : public Teherauto {
public:
Kisteherauto(string gy, string m, string fek)
: Teherauto(gy, m, fek, 20) { }
};
class Kamion : public Teherauto {
public:
Kamion(string gy, string m, string fek, double teher)
: Teherauto(gy, m, fek, teher) { }
void Fekez() { cout<<"A EBS-sel fekez."<< endl; }
void Navigal() {}
};
int main() {
Kisteherauto posta("ZIL", "Diesel", "légfék");
posta.Fekez(); // A hagyomanyosan fekez.
Kamion enAutom("Kamaz", "gázmotor", "EBS", 40);
enAutom.Fekez(); // A EBS-sel fekez.
}
A könyvünk további fejezeteiben bemutatjuk azokat a C++ nyelvi eszközöket, amelyekkel megvalósíthatjuk a fenti fogalmakkal jelölt megoldásokat. Ez az áttekintés azonban nem elegendő az objektum-orientált témakörben való jártasság megszerzéséhez, ez csak a belépő az OOP világába.
III.2. Osztályok és objektumok
Az objektum-orientált gondolkodásmód absztrakt adattípusának (ADT – abstract data type) elkészítésére kétféle megoldás is a rendelkezésünkre áll a C++ nyelvben. A C++ nyelv struct típusa a C nyelv struktúra típusának kiterjesztését tartalmazza, miáltal alkalmassá vált absztrakt adattípusok definiálására. A C++ nyelv az új class (osztály) típust is biztosítja számunkra.
A struct és a class típusok adattagokból (data member) és ezekhez kapcsolódó műveletekből (tagfüggvényekből – member function) épülnek fel. Mindkét adattípussal készíthetünk osztályokat, azonban a tagok alapértelmezés szerinti hozzáférésének következtében a class típus áll közelebb az objektum-orientált elvekhez. Alapértelmezés szerint a struct típus minden tagja nyilvános elérésű, míg a class típus tagjaihoz csak az osztály tagfüggvényeiből lehet hozzáférni.
Az osztálydeklaráció két részből áll. Az osztály feje a class/struct alapszó után az osztály nevét tartalmazza. Ezt követi az osztály törzse, amelyet kapcsos zárójelek fognak közre, és pontosvessző zár. A deklaráció az adattagokon és tagfüggvényeken kívül, a tagokhoz való hozzáférést szabályzó, később tárgyalásra kerülő public (nyilvános, publikált), private (saját, rejtett, privát) és protected (védett) kulcsszavakat is tartalmaz, kettősponttal zárva.
class OsztályNév {
public:
típus4 Függvény1(paraméterlista1) { }
típus5 Függvény2(paraméterlista2) { }
protected:
típus3 adat3;
private:
típus1 adat11, adat12;
típus2 adat2;
};
Az class és a struct osztályok deklarációját a C++ programban bárhol elhelyezhetjük, ahol deklaráció szerepelhet, azonban a modul szintű (fájl szintű) megadás felel meg leginkább a modern programtervezési módszereknek.
III.2.1. A struktúráktól az osztályokig
Ebben a fejezetben a már meglévő (struct típus) ismereteinkre építve lépésről-lépésre jutunk el az objektumok alkalmazásáig. Az alfejezetekben felvetődő problémákat először hagyományos módon oldjuk meg, majd pedig rátérünk az objektum-orientált gondolkodást követő megoldásra.
III.2.1.1. Egy kis ismétlés
Valamely feladat megoldásához szükséges adatokat már eddigi ismereteinkkel is össze tudjuk fogni a struktúra típus alkalmazásával, amennyiben az adatok tárolására a struktúra tagjait használjuk:
struct Alkalmazott{
int torzsszam;
string nev;
float fizetes;
};
Sőt műveleteket is definiálhatunk függvények formájában, amelyek argumentumként megkapják a struktúra típusú változót:
void BertEmel(Alkalmazott& a, float szazalek) {
a.ber *= (1 + szazalek/100);
}
A struktúra tagjait a pont, illetve a nyíl operátorok segítségével érhetjük el, attól függően, hogy a fordítóra bízzuk a változó létrehozását, vagy pedig magunk gondoskodunk a területfoglalásról:
int main() {
Alkalmazott mernok;
mernok.torzsszam = 1234;
mernok.nev = "Okos Antal";
mernok.ber = 2e5;
BertEmel(mernok,12);
cout << mernok.ber << endl;
Alkalmazott *pKonyvelo = new Alkalmazott;
pKonyvelo->torzsszam = 1235;
pKonyvelo->nev = "Gazdag Reka";
pKonyvelo->ber = 3e5;
BertEmel(*pKonyvelo,10);
cout << pKonyvelo->ber << endl;
delete pKonyvelo;
}
Természetesen a fent bemutatott módon is lehet strukturált felépítésű, hatékony programokat fejleszteni, azonban ebben a fejezetben mi tovább megyünk.
III.2.1.2. Adatok és műveletek egybeépítése
Első lépésként - a bezárás elvének (encapulation) megfelelően - az adatokat és a rajtuk elvégzendő műveleteket egyetlen programegysége foglaljuk, azonban ezt a programegységet már, bár struktúra osztálynak nevezzük.
struct Alkalmazott {
int torzsszam;
string nev;
float ber;
void BertEmel(float szazalek) {
ber *= (1 + szazalek/100);
}
};
Első látásra feltűnik, hogy a BertEmel() függvény nem kapja meg paraméterként az osztály típusú változót (objektumot), hiszen alapértelmezés szerint az objektumon végez műveletet. Az Alkalmazott típusú objektumok használatát bemutató main () függvény is valamelyest módosult, hiszen most már a változóhoz tartozó tagfüggvényt hívjuk:
int main() {
Alkalmazott mernok;
mernok.torzsszam = 1234;
mernok.nev = "Okos Antal";
mernok.ber = 2e5;
mernok.BertEmel(12);
cout << mernok.ber << endl;
Alkalmazott *pKonyvelo = new Alkalmazott;
pKonyvelo->torzsszam = 1235;
pKonyvelo->nev = "Gazdag Reka";
pKonyvelo->ber = 3e5;
pKonyvelo->BertEmel(10);
cout << pKonyvelo->ber << endl;
delete pKonyvelo;
}
III.2.1.3. Adatrejtés
Az osztály típusú változók (objektumok) adattagjainak közvetlen elérése ellentmond az adatrejtés elvének. Objektum-orientált megoldásoknál kívánatos, hogy az osztály adattagjait ne lehessen közvetlenül elérni az objektumon kívülről. A struct típus alaphelyzetben teljes elérhetőséget biztosít a tagjaihoz, míg a class típus teljesen elzárja a tagjait a külvilág elől, ami sokkal inkább megfelel az objektum-orientált elveknek. Felhívjuk a figyelmet arra, hogy az osztályelemek elérhetőségét a private, protected és public kulcsszavak segítségével magunk is szabályozhatjuk.
A public tagok bárhonnan elérhetők a programon belül, ahonnan maga az objektum elérhető. Ezzel szemben a private tagokhoz csak az osztály saját tagfüggvényeiből férhetünk hozzá. (A protected elérést a III.3. szakasz - Öröklés (származtatás) tárgyalt öröklés során alkalmazzuk.)
Az osztályon belül tetszőleges számú tagcsoportot kialakíthatunk az elérési kulcsszavak (private, protected, public) alkalmazásával, és a csoportok sorrendjére sincs semmilyen megkötés.
A fenti példánknál maradva, a korlátozott elérés miatt szükséges további tagfüggvényeket megadnunk, amelyekkel ellenőrzött módon beállíthatjuk (set), illetve lekérdezhetjük (get) az adattagok értékét. A beállító függvényekben a szükséges ellenőrzéseket is elvégezhetjük, így csak érvényes adat fog megjelenni az Alkalmazott típusú objektumokban. A lekérdező függvényeket általában konstansként adjuk meg, ami azt jelöli, hogy nem módosítjuk az adattagok értékét a tagfüggvényből. Konstans tagfüggvényben a függvény feje és törzse közé helyezzük a const foglalt szót. Példánkban a GetBer() konstans tagfüggvény.
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
public:
void BertEmel(float szazalek) {
ber *= (1 + szazalek/100);
}
void SetAdatok(int tsz, string n, float b) {
torzsszam = tsz;
nev = n;
ber = b;
}
float GetBer() const {
return ber;
}
};
int main() {
Alkalmazott mernok;
mernok.SetAdatok(1234, "Okos Antal", 2e5);
mernok.BertEmel(12);
cout << mernok.GetBer() << endl;
Alkalmazott *pKonyvelo = new Alkalmazott;
pKonyvelo->SetAdatok(1235, "Gazdag Reka", 3e5);
pKonyvelo->BertEmel(10);
cout << pKonyvelo->GetBer() << endl;
delete pKonyvelo;
}
Megjegyezzük, hogy a konstans tagfüggvényekből is megváltoztathatunk adattagokat, amennyiben azokat a mutable (változékony) kulcsszóval deklaráljuk, például:
mutable float ber;
Az ilyen megoldásokat azonban igen ritkán alkalmazzuk.
Megjegyezzük, ha egy osztály minden adattagja nyilvános elérésű, akkor az objektum inicializálására a struktúráknál bemutatott megoldást is használhatjuk, például:
Alkalmazott portas = {1122, "Biztos Janos", 1e5};
Mivel a későbbiek folyamán a fenti forma használhatóságát további megkötések korlátozzák (nem lehet származtatott osztály, nem lehetnek virtuális tagfüggvényei), ajánlott az inicializálást az osztályok speciális tagfüggvényeivel, az ún. konstruktorokkal elvégezni.
III.2.1.4. Konstruktorok
Az osztályokat használó programokban egyik leggyakoribb művelet az objektumok létrehozása. Az objektumok egy részét mi hozzuk részre statikus vagy dinamikus helyfoglalással (lásd fent), azonban vannak olyan esetek is, amikor a fordítóprogram készít ún. ideiglenes objektumpéldányokat. Hogyan gondoskodhatunk a megszülető objektumok adattagjainak kezdőértékkel való (automatikus) ellátásáról? A választ a konstruktornak nevezett tagfüggvények bevezetésével találjuk meg.
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
public:
Alkalmazott() { // default
torzsszam = 0;
nev = "";
ber = 0;
}
Alkalmazott(int tsz, string n, float b) { // paraméteres
torzsszam = tsz;
nev = n;
ber = b;
}
Alkalmazott(const Alkalmazott & a) { // másoló
torzsszam = a.torzsszam;
nev = a.nev;
ber = a.ber;
}
void BertEmel(float szazalek) {
ber *= (1 + szazalek/100);
}
void SetNev(string n) {
nev = n;
}
float GetBer() const {
return ber;
}
};
int main() {
Alkalmazott dolgozo;
dolgozo.SetNev("Kiss Pista");
Alkalmazott mernok(1234, "Okos Antal", 2e5);
mernok.BertEmel(12);
cout << mernok.GetBer() << endl;
Alkalmazott fomernok = mernok;
// vagy: Alkalmazott fomernok(mernok);
fomernok.BertEmel(50);
cout << fomernok.GetBer() << endl;
Alkalmazott *pDolgozo = new Alkalmazott;
pDolgozo->SetNev("Kiss Pista");
delete pDolgozo;
Alkalmazott *pKonyvelo;
pKonyvelo = new Alkalmazott(1235, "Gazdag Reka", 3e5);
pKonyvelo->BertEmel(10);
cout << pKonyvelo->GetBer() << endl;
delete pKonyvelo;
Alkalmazott *pFomernok=new Alkalmazott(mernok);
pFomernok->BertEmel(50);
cout << pFomernok->GetBer() << endl;
delete pFomernok;
}
A fenti példában – a függvénynevek túlterhelését alkalmazva - készítettünk egy paraméter nélküli, egy paraméteres és egy másoló konstruktort. Látható, hogy a konstruktor olyan tagfüggvény, amelynek neve megegyezik az osztály nevével, és nincs visszatérési típusa. Az osztály konstruktorát a fordító minden olyan esetben automatikusan meghívja, amikor az adott osztály objektuma létrejön. A konstruktor nem rendelkezik visszatérési értékkel, de különben ugyanúgy viselkedik, mint bármely más tagfüggvény. A konstruktor átdefiniálásával (túlterhelésével) többféleképpen is inicializálhatjuk az objektumokat.
A konstruktor nem foglal tárterületet a létrejövő objektum számára, feladata a már lefoglalt adatterület inicializálása. Ha azonban az objektum valamilyen mutatót tartalmaz, akkor a konstruktorból kell gondoskodnunk a mutató által kijelölt terület lefoglalásáról.
Egy osztály alapértelmezés szerint két konstruktorral rendelkezik: a paraméter nélküli (default) és a másoló konstruktorral. Ha valamilyen saját konstruktort készítünk, akkor a paraméter nélküli alapértelmezett (default) konstruktor nem érhető el, így azt is definiálnunk kell. Saját másoló konstruktort általában akkor használunk, ha valamilyen dinamikus tárterület tartozik az osztály példányaihoz.
A paraméter nélküli és a paraméteres konstruktort gyakran összevonjuk az alapértelmezés szerinti argumentumok bevezetésével:
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
public:
Alkalmazott(int tsz = 0, string n ="", float b=0) {
torzsszam = tsz;
nev = n;
ber = b;
}
…
}
III.2.1.4.1. Taginicializáló lista alkalmazása
A konstruktorokból az osztály tagjait kétféleképpen is elláthatjuk kezdőértékkel. A hagyományosnak tekinthető megoldást, a konstruktor törzsén belüli értékadást már jól ismerjük. Emellett a C++ nyelv lehetővé teszi az ún. taginicializáló lista alkalmazását. Az inicializáló listát közvetlenül a konstruktor feje után kettősponttal elválasztva adjuk meg. A vesszővel tagolt lista elemei az osztály adattagjai, melyeket zárójelben követnek a kezdőértékek. A taginicializáló lista bevezetésével a fenti példák konstruktorai üressé válnak:
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
public:
Alkalmazott(int tsz=0, string n="", float b=0)
: torzsszam(tsz), nev(n), ber(b) { }
Alkalmazott(const Alkalmazott & a)
: torzsszam(a.torzsszam), nev(a.nev),
ber(a.ber) { }
…
}
Szükséges megjegyeznünk, hogy a konstruktor hívásakor az inicializáló lista feldolgozása után következik a konstruktor törzsének végrehajtása.
III.2.1.4.2. Az objektumok explicit inicializálása
Egyparaméteres konstruktorok esetén a fordító – szükség esetén - implicit típus-átalakítást használ a megfelelő konstruktor kiválasztásához. Az explicit kulcsszó konstruktor előtti megadásával megakadályozhatjuk az ilyen konverziók alkalmazását a konstruktorhívás során.
Az alábbi példában az explicit kulcsszó segítségével különbséget tehetünk a kétféle (explicit és implicit) kezdőérték-adási forma között:
class Szam
{
private:
int n;
public:
explicit Szam( int x) {
n = x;
cout << "int: " << n << endl;
}
Szam( float x) {
n = x < 0 ? int(x-0.5) : int(x+0.5);
cout << "float: " << n << endl;
}
};
int main() {
Szam a(123); // explicit hívás
Szam b = 123; // implicit (nem explicit) hívás
}
Az a objektum létrehozásakor az explicit konstruktor hívódik meg, míg a b objektum esetén a float paraméterű. Az explicit szó elhagyásával mindkét esetben az első konstruktor aktiválódik.
III.2.1.5. Destruktor
Gyakran előfordul, hogy egy objektum létrehozása során erőforrásokat (memória, állomány stb.) foglalunk le, amelyeket az objektum megszűnésekor fel kell szabadítanunk. Ellenkező esetben ezek az erőforrások elvesznek a programunk számára.
A C++ nyelv biztosít egy speciális tagfüggvényt - a destruktort - amelyben gondoskodhatunk a lefoglalt erőforrások felszabadításáról. A destruktor nevét hullám karakterrel (~) egybeépített osztálynévként kell megadni. A destruktor, a konstruktorhoz hasonlóan nem rendelkezik visszatérési típussal.
Az alábbi példában egy 12-elemű, dinamikus helyfoglalású tömböt hozunk létre a konstruktorokban, az alkalmazottak havi munkaidejének tárolására. A tömb számára lefoglalt memóriát a destruktorban szabadítjuk fel.
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
int *pMunkaorak;
public:
Alkalmazott(int tsz = 0, string n ="", float b=0) {
torzsszam = tsz;
nev = n;
ber = b;
pMunkaorak = new int[12];
for (int i=0; i<12; i++) pMunkaorak[i]=0;
}
Alkalmazott(const Alkalmazott & a) {
torzsszam = a.torzsszam;
nev = a.nev;
ber = a.ber;
pMunkaorak = new int[12];
for (int i=0; i<12; i++)
pMunkaorak[i]=a.pMunkaorak[i];
}
~Alkalmazott() {
delete[] pMunkaorak;
cout << nev << " torolve" << endl;
}
void BertEmel(float szazalek) {
ber *= (1 + szazalek/100);
}
void SetMunkaora(int honap, int oraszam) {
if (honap >= 1 && honap <=12) {
pMunkaorak[honap-1]=oraszam;
}
}
float GetBer() const {
return ber;
}
};
int main() {
Alkalmazott mernok(1234, "Okos Antal", 2e5);
mernok.BertEmel(12);
mernok.SetMunkaora(3,192);
cout << mernok.GetBer() << endl;
Alkalmazott *pKonyvelo;
pKonyvelo = new Alkalmazott(1235, "Gazdag Reka", 3e5);
pKonyvelo->BertEmel(10);
pKonyvelo->SetMunkaora(1,160);
pKonyvelo->SetMunkaora(12,140);
cout << pKonyvelo->GetBer() << endl;
delete pKonyvelo;
}
A lefordított program minden olyan esetben meghívja az osztály destruktorát, amikor az objektum érvényessége megszűnik. Kivételt képeznek a new operátorral dinamikusan létrehozott objektumok, melyek esetén a destruktort csak a delete operátor segítségével aktivizálhatjuk. Fontos megjegyeznünk, hogy a destruktor nem magát az objektumot szűnteti meg, hanem automatikusan elvégez néhány általunk megadott „takarítási” műveletet.
A példaprogram futtatásakor az alábbi szöveg jelenik meg:
224000 330000 Gazdag Reka torolve Okos Antal torolve
Ebből láthatjuk, hogy először a *pKonyvelo objektum destruktora hívódik meg a delete operátor használatakor. Ezt követően a main () függvény törzsét záró kapcsos zárójel elérésekor automatikusan aktiválódik a mernok objektum destruktora.
Amennyiben nem adunk meg destruktort, a fordítóprogram automatikusan egy üres destruktorral látja el az osztályunkat.
III.2.1.6. Az osztály objektumai, a this mutató
Amikor az Alkalmazott osztálytípussal objektumokat (osztály típusú változókat) hozunk létre:
Alkalmazott mernok(1234, "Okos Antal", 2e5); Alkalmazott *pKonyvelo; pKonyvelo = new Alkalmazott(1235, "Gazdag Reka", 3e5);
minden objektum saját adattagokkal rendelkezik, azonban a tagfüggvények egyetlen példányát megosztva használják (III.4. ábra - Az Alkalmazott osztály és az objektumai).
mernok.BertEmel(12); pKonyvelo->BertEmel(10);
Felvetődik a kérdés, honnan tudja például a BertEmel() függvény, hogy a hívásakor mely adatterületet kell elérnie?
Erre a kérdésre a fordító nem látható tevékenysége adja meg a választ: minden tagfüggvény, még a paraméter nélküliek is, rendelkeznek egy nem látható paraméterrel (this), amelyben a hívás során az aktuális objektumra mutató pointer adódik át a függvénynek. A fentieken kívül minden adattag-hivatkozás automatikusan az alábbi formában kerül be a kódba:
this->adattag
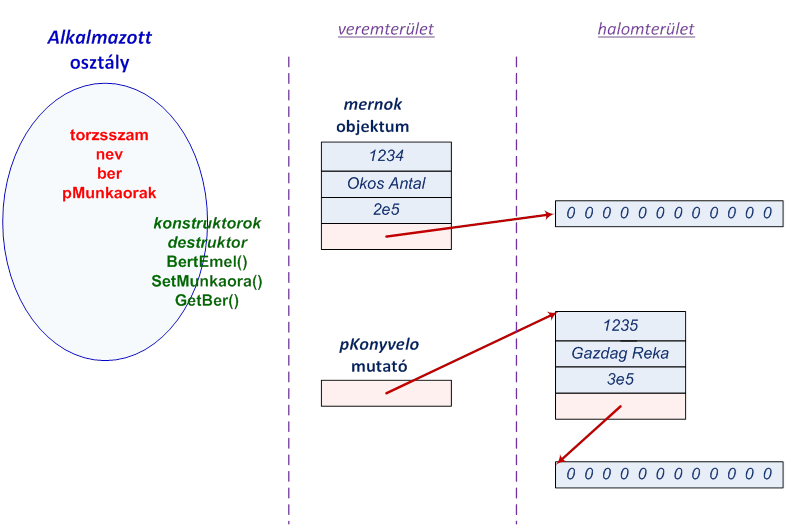
A this (ez) mutatót mi is felhasználhatjuk a tagfüggvényeken belül. Ez a lehetőség jól jön, amikor egy paraméter neve megegyezik valamely adattag nevével:
class Alkalmazott{
private:
int torzsszam;
string nev;
float ber;
public:
Alkalmazott(int torzsszam=0, string nev="", float ber=0){
this->torzsszam = torzsszam;
this->nev = nev;
this->ber = ber;
}
};
A this mutató deklarációja normál tagfüggvények esetén Osztálytípus* constthis, illetve const Osztálytípus*const this a konstans tagfüggvényekben.
III.2.2. Az osztályokról bővebben
Az előző alfejezetben eljutottunk a struktúráktól az osztályokig. Megismerkedtünk azokkal a megoldásokkal, amelyek jól használható osztályok kialakítását teszik lehetővé. Bátran hozzáfoghatunk a feladatok osztályok segítségével történő megoldásához.
Jelen fejezetben kicsit továbblépünk, és áttekintjük az osztályokkal kapcsolatos - kevésbé általános - tudnivalókat. A fejezet tartalmát akkor javasoljuk feldolgozni, ha az Olvasó már jártassággal rendelkezik az osztályok készítésében.
III.2.2.1. Statikus osztálytagok
C++ nyelven az osztályok adattagjai előtt megadhatjuk a static kulcsszót, jelezve azt, hogy ezeket a tagokat (a tagfüggvényekhez hasonlóan) megosztva használják az osztály objektumai. Az egyetlen példányban létrejövő statikus adattag közvetlenül az osztályhoz tartozik, így az akkor is elérhető, ha egyetlen objektuma sem létezik az osztálynak.
A statikus adattag inicializálását az osztályon kívül kell elvégezni (függetlenül az adattag elérhetőségétől). Kivételt képeznek a static const egész és felsorolás típusú adattagok, melyek kezdőértéke az osztályon belül is megadható.
Ha a statikus adattag nyilvános elérésű, akkor a programban bárhonnan felhasználhatjuk az osztály neve és a hatókör (::) operátor magadásával. Ellenkező esetben csak az osztály példányai érik el ezeket a tagokat.
Az alábbi példában a statikus tagok használatának bemutatásán túlmenően, a konstansok osztályban való elhelyezésének megoldásait (static const és enum) is szemléltetjük. Az általunk definiált matematikai osztály (Math) lehetővé teszi, hogy a Sin() és a Cos() tagfüggvényeket radián vagy fok mértékegységű adatokkal hívjuk:
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
class Math {
public:
enum Egyseg {fok, radian};
private:
static double dFok2Radian;
static Egyseg eMode;
public:
static const double Pi;
static double Sin(double x)
{return sin(eMode == radian ? x : dFok2Radian*x);}
static double Cos(double x)
{return cos(eMode == radian ? x : dFok2Radian*x);}
static void Mertekegyseg(Egyseg mode = radian) {
eMode = mode; }
void KiirPI() { cout.precision(18); cout<<Pi<<endl;}
};
// A statikus adattagok létrehozása és inicializálása
const double Math::Pi = M_PI;
double Math::dFok2Radian = Math::Pi/180;
Math::Egyseg Math::eMode = Math::radian;
A példában látható módon, az osztályon belül egy felsorolást is elhelyezhetünk. Az így elkészített Egyseg típusnévre és a felsorolt (fok, radian) konstansokra az osztálynévvel minősített név segítségével hivatkozhatunk. Ezek a nevek osztály hatókörrel rendelkeznek, függetlenül az enum kulcsszó után megadott típusnévtől (Math::Egyseg): Math::radian, Math::fok.
A statikus adattagok kezelésére általában statikus tagfüggvényeket használunk (Math::Sin(), Math::Cos(), Math::Mertekegyseg()). A statikus tagfüggvényekből azonban a normál adattagokhoz nem férhetünk hozzá, mivel a paramétereik között nem szerepel a this mutató. A nem statikus tagfüggvényekből az osztály statikus tagjait korlátozás nélkül elérhetjük.
A Math osztály lehetséges alkalmazását az alábbiakban láthatjuk:
int main() {
double y = Math::Sin(Math::Pi/6); // radiánban számol
Math::Mertekegyseg(Math::fok); // fokokban számol
y = Math::Sin(30);
Math::Mertekegyseg(Math::radian); // radiánban számol
y = Math::Sin(Math::Pi/6);
Math m; // oszálypéldány
m.Mertekegyseg(Math::fok); // vagy
m.Mertekegyseg(m.fok);
y = m.Sin(30);
m.Mertekegyseg(m.radian); // vagy
m.Mertekegyseg(Math::radian);
y = m.Sin(Math::Pi/6);
m.KiirPI();
}
III.2.2.2. Az osztályok kialakításának lehetőségei
A C++ nyelv szabályai többféle osztálykialakítási megoldást is lehetővé tesznek. Az alábbi példákban szigorúan elkülönítjük az egyes eseteket, azonban a programozási gyakorlatban ezeket vegyesen használjuk.
III.2.2.2.1. Implicit inline tagfüggvények alkalmazása
Az első esetben az osztály leírásában szerepeltetjük a tagfüggvények teljes definícióját. A fordító az ilyen tagfüggvényeket automatikusan inline függvénynek tekinti. A megoldás nagy előnye, hogy a teljes osztályt egyetlen fejállományban tárolhatjuk, és az osztály tagjait könnyen áttekinthetjük. Általában kisebb méretű osztályok esetén alkalmazható hatékonyan ez a megoldás.
Példaként tekintsük a síkbeli pontok kezelését segítő Pont osztályt!
class Pont {
private:
int x,y;
public:
Pont(int a = 0, int b = 0) { x = a; y = b; }
int GetX() const { return x; }
int GetY() const { return y; }
void SetX(int a) { x = a; }
void SetY(int a) { y = a; }
void Mozgat(int a, int b) { x = a; y = b; }
void Mozgat(const Pont& p) { x = p.x; y = p.y; }
void Kiir() const { cout<<"("<<x<<","<<y<<")\n"; }
};
III.2.2.2.2. Osztálystruktúra a C++/CLI alkalmazásokban
A fentiekhez hasonló megoldást követnek a Visual C++ a .NET projektekben, valamint a Java és a C# nyelvek. Szembeötlő különbség, hogy az osztálytagok elérhetőségek szerinti csoportosítása helyett, minden tag hozzáférését külön megadjuk.
class Pont {
private: int x,y;
public: Pont(int a = 0, int b = 0) { x = a; y = b; }
public: int GetX() const { return x; }
public: int GetY() const { return y; }
public: void SetX(int a) { x = a; }
public: void SetY(int a) { y = a; }
public: void Mozgat(int a, int b) { x = a; y = b; }
public: void Mozgat(const Pont& p) { x = p.x; y = p.y; }
public: void Kiir() const { cout<<"("<<x<<","<<y<<")\n"; }
};
III.2.2.2.3. A tagfüggvények tárolása külön modulban
Nagyobb méretű osztályok kezelését segíti, ha a tagfüggvényeket külön C++ modulban tároljuk. Ekkor az osztály deklarációjában az adattagok mellett a tagfüggvények prototípusát szerepeltetjük. Az osztály leírását tartalmazó fejállomány (.H), és a tagfüggvények definícióját tároló modul (.CPP) neve általában megegyezik, és utal az osztályra.
A Pont osztály leírása a Pont.h fejállományban az alábbiak szerint módosul:
#ifndef __PONT_H__
#define __PONT_H__
class Pont {
private:
int x,y;
public:
Pont(int a = 0, int b = 0);
int GetX() const;
int GetY() const;
void SetX(int a);
void SetY(int a);
void Mozgat(int a, int b);
void Mozgat(const Pont& p);
void Kiir() const;
};
#endif
A tagfüggvények nevét az osztály nevével kell minősíteni (::) a Pont.cpp állományban:
#include <iostream>
using namespace std;
#include "Pont.h"
Pont::Pont(int a, int b) {
x = a; y = b;
}
int Pont::GetX() const {
return x;
}
int Pont::GetY() const {
return y;
}
void Pont::SetX(int a) {
x = a;
}
void Pont::SetY(int a) {
y = a;
}
void Pont::Mozgat(int a, int b) {
x = a; y = b;
}
void Pont::Mozgat(const Pont& p) {
x = p.x; y = p.y;
}
void Pont::Kiir() const {
cout<<"("<<x<<","<<y<<")\n";
}
Természetesen explicit módon is alkalmazhatjuk az inline előírást a tagfüggvényekre, azonban ekkor az inline tagfüggvények definícióját a C++ modulból a fejállományba kell áthelyeznünk:
#ifndef __PONT_H__
#define __PONT_H__
class Pont {
private:
int x,y;
public:
Pont(int a = 0, int b = 0);
int GetX() const;
int GetY() const;
void SetX(int a);
void SetY(int a);
void Mozgat(int a, int b);
void Mozgat(const Pont& p);
inline void Kiir() const;
};
void Pont::Kiir() const {
cout<<"("<<x<<","<<y<<")\n";
}
#endif
III.2.2.3. Barát függvények és osztályok
Vannak esetek, amikor a C++ nyelv adatrejtés szabályai megakadályozzák, hogy hatékony programkódot készítsünk. A friend (barát) mechanizmus azonban lehetővé teszi, hogy egy osztály private és protected tagjait az osztályon kívüli függvényekből is elérjük.
A friend deklarációt az osztály leírásán belül, tetszőleges elérésű részben elhelyezhetjük. A „barát” lehet egy külső függvény, egy másik osztály adott tagfüggvénye, de akár egy egész osztály is (vagyis annak minden tagfüggvénye). Ennek megfelelően a friend deklarációban a függvények prototípusát, illetve az osztály nevét szerepeltetjük a class szóval bevezetve.
Felhívjuk a figyelmet arra, hogy barátosztály esetén a „baráti viszony” nem kölcsönös, vagyis csak a friend deklarációban szereplő osztály tagfüggvényei kapnak korlátlan elérést a leírást tartalmazó osztály tagjaihoz.
Az alábbi példában szereplő COsztaly minden tagját korlátozás nélkül eléri a külső Osszegez() függvény, a BOsztaly Szamlal() nyilvános tagfüggvénye valamint az AOsztaly minden tagfüggvénye:
class AOsztaly;
class BOsztaly {
public:
int Szamlal(int x) { return x++; }
};
class COsztaly {
friend long Osszegez(int a, int b);
friend int BOsztaly::Szamlal(int x);
friend class AOsztaly;
// ...
};
long Osszegez(int a, int b) {
return long(a) + b;
}
További példaként tekintsük a síkbeli pontok leírásához használható egyszerűsített Pont osztályunkat! Mivel a pontok távolságát számító művelet eredménye nem kapcsolható egyik ponthoz sem, így a távolság meghatározására külső függvényt készítünk, amely argumentumként kapja a két pontot. Az adattagok gyors eléréséhez azonban szükséges a közvetlen hozzáférés biztosítása, ami a „barát” mechanizmus révén meg is valósítható.
#include <iostream>
#include <cmath>
using namespace std;
class Pont {
friend double Tavolsag(const Pont & p1,
const Pont & p2);
private:
int x,y;
public:
Pont(int a = 0, int b = 0) { x = a; y = b; }
int GetX() const { return x; }
int GetY() const { return y; }
void SetX(int a) { x = a; }
void SetY(int a) { y = a; }
void Mozgat(int a, int b) { x = a; y = b; }
void Mozgat(const Pont& p) { x = p.x; y = p.y; }
void Kiir() const { cout<<"("<<x<<","<<y<<")\n"; }
};
double Tavolsag(const Pont & p1, const Pont & p2) {
return sqrt(pow(p1.x-p2.x,2.0)+pow(p1.y-p2.y,2.0));
}
int main() {
Pont p, q;
p.Mozgat(1,2);
q.Mozgat(4,6);
cout<<Tavolsag(p,q)<<endl;
}
III.2.2.4. Mi szerepelhet még az osztályokban?
Az osztályokkal történő eddigi ismerkedésünk során adatokat és függvényeket helyeztünk el az osztályokban. A statikus tagok esetén ezt a sort a statikus konstansokkal és az enum típussal bővítettük.
Az alábbiakban először megnézzük, miként helyezhetünk el az osztályunkban konstanst és hivatkozást, ezt követően pedig röviden áttekintjük az ún. egymásba ágyazott osztályok használatával kapcsolatos szabályokat.
III.2.2.4.1. Objektumok konstans adattagjai
Vannak esetek, amikor az objektumpéldányokhoz valamilyen egyedi konstans értéket szeretnénk kapcsolni, például egy nevet, egy azonosítószámot. Erre van lehetőség, ha az adattagot const előtaggal látjuk el, és felvesszük a konstruktorok taginicializáló listájára.
A következő példában felhasználó objektumokat készítünk, és a felhasználók nyilvános nevét konstansként használjuk:
class Felhasznalo {
string jelszo;
public:
const string nev;
Felhasznalo(string user, string psw="") : nev(user) {
jelszo=psw;
}
void SetJelszo(string newpsw) { jelszo = newpsw;}
};
int main() {
Felhasznalo nata("Lafenita");
Felhasznalo kertesz("Liza");
nata.SetJelszo("Atinefal1223");
kertesz.SetJelszo("Azil729");
cout<<nata.nev<<endl;
cout<<kertesz.nev<<endl;
Felhasznalo alias = nata;
// alias = kertesz; // hiba!
}
Felhívjuk a figyelmet arra, hogy az azonos típusú objektumok közötti szokásos tagonkénti másolás nem működik, amennyiben az objektumok konstans tagokat tartalmaznak.
III.2.2.4.2. Hivatkozás típusú adattagok
Mivel hivatkozást csak már létező változóhoz készíthetünk, az objektum konstruálása során a konstansokhoz hasonló módon kell eljárnunk. Az alábbi példában referencia segítségével kapcsoljuk a vezérlő objektumhoz a jeladó objektumot:
class Jelado {
private:
int adat;
public:
Jelado(int x) { adat = x; }
int Olvas() { return adat; }
};
class Vezerlo {
private:
Jelado& jelado;
public:
Vezerlo(Jelado& szenzor) : jelado(szenzor) {}
void AdatotFogad() { cout<<jelado.Olvas(); }
};
int main() {
Jelado sebesseg(0x17);
Vezerlo ABS(sebesseg);
ABS.AdatotFogad();
}
III.2.2.4.3. Adattag objektumok
Gyakran előfordul, hogy egy osztályban egy másik osztály objektumpéldányát helyezzük el adattagként. Fontos szabály, hogy az ilyen osztály objektumainak létrehozásakor a belső objektumok inicializálásáról is gondoskodni kell, amit a megfelelő konstruktorhívás taginicializáló listára való helyezésével érhetünk el.
A konstruktorhívástól eltekinthetünk, ha a tagobjektum osztálya rendelkezik paraméter nélküli (default) konstruktorral, ami automatikus is meghívódik.
A fenti vezérlő-jeladó példaprogramot úgy módosítjuk, hogy a jeladó objektumként jelenjen meg a vezérlő objektumban:
class Jelado {
private:
int adat;
public:
Jelado(int x) { adat = x; }
int Olvas() { return adat; }
};
class Vezerlo {
private:
Jelado jelado;
public:
Vezerlo() : jelado(0x17) {}
void AdatotFogad() { cout<<jelado.Olvas(); }
};
int main() {
Vezerlo ABS;
ABS.AdatotFogad();
}
III.2.2.5. Osztálytagokra mutató pointerek
C++-ban egy függvényre mutató pointer még akkor sem veheti fel valamely tagfüggvény címét, ha különben a típusuk és a paraméterlistájuk teljesen megegyezik. Ennek oka, hogy a (nem statikus) tagfüggvények az osztály példányain fejtik ki hatásukat. Ugyanez igaz az adattagokhoz rendelt mutatókra is. (További fontos eltérés a hagyományos mutatókhoz képest, hogy a virtuális tagfüggvények mutatón keresztüli hívása esetén is érvényesül a későbbiekben tárgyalt polimorfizmus.)
A mutatók helyes definiálásához az osztály nevét és a hatókör operátort is alkalmaznunk kell:
|
|
előrevetett osztálydeklaráció, |
|
|
p mutató egy int típusú adattagra, |
|
|
pfv egy olyan tagfüggvényre mutathat, amelyet int argumentummal hívunk, és nem ad vissza értéket. |
A következő példában bemutatjuk az osztálytagokra mutató pointerek használatát, melynek során mindkét osztálytagot mutatók segítségével érjük el. Az ilyen mutatók alkalmazása esetén a tagokra a szokásos operátorok helyett a .* (pont csillag), illetve a ->* (nyíl csillag) operátorokkal hivatkozhatunk. Az adattagok és tagfüggvények címének lekérdezéséhez pedig egyaránt a címe (&) operátort kell használnunk.
#include <iostream>
using namespace std;
class Osztaly {
public:
int a;
void f(int b) { a += b;}
};
int main() {
// mutató az Osztaly int típusú adattagjára
int Osztaly::*intptr = &Osztaly::a;
// mutató az Osztaly void típusú, int paraméterű
// tagfüggvényére
void (Osztaly::* fvptr)(int) = &Osztaly::f;
// az objektupéldányok létrehozása
Osztaly objektum;
Osztaly * pobjektum = new Osztaly();
// az a adattag elérése mutató segítségével
objektum.*intptr = 10;
pobjektum->*intptr = 100;
// az f() tagfüggvény hívása pointer felhasználásával
(objektum.*fvptr)(20);
(pobjektum->*fvptr)(200);
cout << objektum.a << endl; // 30
cout << pobjektum->a << endl; // 300
delete pobjektum;
}
A typedef alkalmazásával egyszerűbbé tehetjük a pointeres kifejezésekkel való munkát:
typedef int Osztaly::*mutato_int; typedef void (Osztaly::*mutato_fv)(int); … mutato_int intptr = &Osztaly::a; mutato_fv fvptr = &Osztaly::f;
III.2.3. Operátorok túlterhelése (operator overloading)
Az eddigiek során az osztályhoz tartozó műveleteket tagfüggvények formájában valósítottuk meg. A műveletek elvégzése pedig tagfüggvények hívását jelentette. Sokkal olvashatóbb programokhoz juthatunk, ha a függvényhívások helyett valamilyen hasonló tartalmú műveleti jelet alkalmazhatunk.
A C++ nyelv biztosítja annak a lehetőségét, hogy valamely, programozó által definiált függvényt szabványos operátorhoz kapcsoljunk, kibővítve ezzel az operátor működését. Ez a függvény automatikusan meghívódik, amikor az operátort egy meghatározott szövegkörnyezetben használjuk.
Operátorfüggvényt azonban csak akkor készíthetünk, ha annak legalább egyik paramétere osztály (class, struct) típusú. Ez azt jelenti, hogy a paraméter nélküli függvények, illetve a csak alap adattípusú argumentumokat használó függvények nem lehetnek operátorfüggvények. Az operátorfüggvény deklarációjának formája:
típus operator op(paraméterlista);
ahol az op helyén az alábbi C++ operátorok valamelyike állhat:
|
[] |
() |
. |
-> |
++ |
-- |
& |
new |
|
* |
+ |
- |
~ |
! |
/ |
% |
new[] |
|
<< |
>> |
< |
> |
<= |
>= |
== |
delete |
|
!= |
^ |
| |
&& |
|| |
= |
*= |
delete[] |
|
/= |
%= |
+= |
-= |
<<= |
>>= |
&= | |
|
^= |
|= |
, |
->* |
Az operátorfüggvény típus-átalakítás esetén az alábbi alakot ölti:
operator típus();
Nem definiálhatók át a tagkiválasztás (.), az indirekt tagkiválasztás (.*), a hatókör (::) , a feltételes (?:), a sizeof és a typeid operátorok, mivel ezek túlterhelése nemkívánatos mellékhatásokkal járna.
Az értékadó (=), a címe (&) és a vessző (,) műveletek túlterhelés nélkül is alkalmazhatók az objektumokra.
Felhívjuk a figyelmet arra, hogy az operátorok túlterhelésével nem változtatható meg az operátorok elsőbbsége (precedenciája) és csoportosítása (asszociativitása), valamint nincs mód új műveletek bevezetésére sem.
III.2.3.1. Operátorfüggvények készítése
Az operátorok túlterhelését megvalósító operátorfüggvények kialakítása nagymértékben függ a kiválasztott műveleti jeltől. Az alábbi táblázatban összefoglaltuk a lehetőségeket. Az operátorfüggvények többségének visszatérési értéke és típusa szabadon megadható.
|
Kifejezés |
Operátor( ♣ ) |
Tagfüggvény |
Külső függvény |
|---|---|---|---|
|
♣a |
+ - * & ! ~ ++ -- |
|
|
|
a♣ |
++ -- |
|
|
|
a♣b |
+ - * / % ^ & | < > == != <= >= << >> && || , |
|
|
|
a♣b |
= += -= *= /= %= ^= &= |= <<= >>= [] |
|
- |
|
a(b, c...) |
() |
|
- |
|
a->b |
-> |
|
- |
Az operátorfüggvényeket általában osztályon belül adjuk meg, a felhasználói típus lehetőségeinek kiterjesztése céljából. Az =, (), [] és -> operátorokat azonban csak nem statikus tagfüggvénnyel lehet átdefiniálni. A new és a delete operátorok esetén a túlterhelés statikus tagfüggvénnyel történik. Minden más operátorfüggvény elkészíthető tagfüggvényként vagy külső (általában friend) függvényként.
Az elmondottakat jól szemlélteti a fenti táblázat, ahol csoportokba rendeztük a C++ nyelv átdefiniálható műveleteit, a dinamikus memóriakezelés operátorainak elhagyásával. A táblázatban a ♣ karakter a műveleti jelet helyettesíti, míg az a, b és c valamely A, B és C osztály objektumai.
A túlterhelhető C++ műveleti jelek többségét az operandusok száma alapján két csoportra oszthatjuk. Erre a két esetre az alábbi táblázatban összefoglaltuk az operátorfüggvények hívásának formáit.
Kétoperandusú operátorok esetén:
|
Megvalósítás |
Szintaxis |
Aktuális hívás |
|---|---|---|
|
tagfüggvény |
|
|
|
külső függvény |
|
|
Egyoperandusú operátorok esetén:
|
Megvalósítás |
Szintaxis |
Aktuális hívás |
|---|---|---|
|
tagfüggvény |
|
|
|
tagfüggvény |
|
|
|
külső függvény |
|
|
|
külső függvény |
|
|
Bizonyos műveleteket átdefiniálása során a szokásostól eltérő megfontolásokra is szükség van. Ezen operátorokat a fejezet további részeiben ismertetjük.
Példaként tekintsük az egész számok tárolására alkalmas Vektor osztályt, amelyben túlterheltük az indexelés ([]), az értékadás (=) és az összeadás (+, +=) műveleteit! Az értékadás megvalósítására a tömb elemeinek másolása érdekében volt szükség. A + operátort barátfüggvénnyel valósítjuk meg, mivel a keletkező vektor logikailag egyik operandushoz sem tartozik. Ezzel szemben a += művelet megvalósításához tagfüggvényt használunk, hiszen a művelet során a bal oldali operandus elemei módosulnak. Az osztály teljes deklarációját (inline függvényekkel) a Vektor.h állomány tartalmazza.
#ifndef __VektorH__
#define __VektorH__
class Vektor {
inline friend Vektor operator+ (const Vektor& v1,
const Vektor& v2);
private:
int meret, *p;
public:
// ----- Konstruktorok -----
// Adott méretű vektor inicilaizálása
Vektor(int n=10) {
p = new int[meret=n];
for (int i = 0; i < meret; ++i)
p[i] = 0; // az elemek nullázása
}
// Inicializálás másik vektorral - másoló konstruktor
Vektor(const Vektor& v) {
p = new int[meret=v.meret];
for (int i = 0; i < meret; ++i)
p[i] = v.p[i]; // az elemek átmásolása
}
// Inicializálás hagyományos n-elemu vektorral
Vektor(const int a[], int n) {
p = new int[meret=n];
for (int i = 0; i < meret; ++i)
p[i] = a[i];
}
// ----- Destruktor -----
~Vektor() {delete[] p; }
// ----- Meretlekérdező tagfüggvény -----
int GetMeret() const { return meret; }
// ----- Operátorfüggvények -----
int& operator [] (int i) {
if (i < 0 || i > meret-1) // indexhatár-ellenőrzés
throw i;
return p[i];
}
const int& operator [] (int i) const {
return p[i];
}
Vektor operator = (const Vektor& v) {
delete[] p;
p=new int [meret=v.meret];
for (int i = 0; i < meret; ++i)
p[i] = v.p[i];
return *this;
}
Vektor operator += (const Vektor& v) {
int m = (meret < v.meret) ? meret : v.meret;
for (int i = 0; i < m; ++i)
p[i] += v.p[i];
return *this;
}
};
// ----- Külső függvény -----
inline Vektor operator+(const Vektor& v1, const Vektor& v2) {
Vektor osszeg(v1);
osszeg+=v2;
return osszeg;
}
#endif
A példaprogram megértéséhez néhány megjegyzést kell fűznünk a programkódhoz.
Az indexelés műveletéhez két operátorfüggvény is készítettünk, a másodikat a konstans vektorokkal használja a fordító. A két operator[]() függvény egymás túlterhelt változatai, bár a paramétersoruk azonos. Ez azért lehetséges, mivel a C++ fordító a függvény const voltát is eltárolja a függvény lenyomatában.
A this pointer az objektumra mutat, azonban a *this kifejezés magát az objektumot jelenti. Azok a Vektor típusú függvények, amelyek a *this értékkel térnek vissza, valójában az aktuális objektum másolatát adják függvényértékül. (Megjegyezzük, hogy Vektor& típusú függvények a return *this; utasítás hatására az aktuális objektum hivatkozását szolgáltatják.)
A Vektor osztály felhasználását az alábbi programrészlet szemlélteti:
#include <iostream>
using namespace std;
#include "Vektor.h"
void show(const Vektor& v) {
for (int i=0; i<v.GetMeret(); i++)
cout<<v[i]<<'\t';
cout<<endl;
}
int main() {
int a[5]={7, 12}, b[7]={2, 7, 12, 23, 29};
Vektor x(a,5); // x: 7 12 0 0 0
Vektor y(b,7); // y: 2 7 12 23 29 0 0
Vektor z; // z: 0 0 0 0 0 0 0 0 0 0
try {
x = y; // x: 2 7 12 23 29 0 0
x = Vektor(a,5);// x: 7 12 0 0 0
x += y; // x: 9 19 12 23 29
z = x + y; // z: 11 26 24 46 58
z[0] = 102;
show(z); // z:102 26 24 46 58
}
catch (int n) {
cout<<"Hibas tombindex: "<<n<<endl;
}
const Vektor v(z);
show(v); // v:102 26 24 46 58
// v[0] = v[1]+5; // error: assignment of read-only…
}
III.2.3.2. Típus-átalakító operátorfüggvények használata
A C++ nyelv támogatja, hogy osztályainkhoz típuskonverziókat rendeljünk. A felhasználó által definiált típus-átalakítást végző operátorfüggvény deklarációja:
operator típus();
A függvény visszatérési értékének típusa megegyezik a függvény nevében szereplő típussal. A típuskonverziós operátorfüggvény csak visszatérési típus és argumentumlista nélküli tagfüggvény lehet.
Az alábbi példában a Komplex típust osztályként valósítjuk meg. Az egyetlen nem Komplex típusú argumentummal rendelkező konstruktor elvégzi a más típusról – a példában double – Komplex típusra történő konverziót. A fordított irányú átalakításhoz double nevű konverziós operátort készítünk.
#include <cmath>
#include <iostream>
using namespace std;
class Komplex {
public:
Komplex () { re=im=0; }
Komplex(double a) : re(a), im(0) { }
// konverziós konstruktor
Komplex(double a, double b) : re(a), im(b) { }
// konverziós operátor
operator double() {return sqrt(re*re+im*im);}
Komplex operator *= (const Komplex & k) {
Komplex t;
t.re=(k.re*re)-(k.im*im);
t.im=(k.re*im)+(re*k.im);
return *this = t;
}
void Kiir() const { cout << re << "+" << im << "i"; }
private:
double re, im;
friend Komplex operator*(const Komplex&, const Komplex&);
};
Komplex operator*(const Komplex& k1, const Komplex& k2) {
Komplex k=k1;
k*= k2;
return k;
}
int main() {
Komplex k1(7), k2(3,4), k3(k2);
cout << double(k3)<< endl; // a kiírt érték: 5
cout <<double(Komplex(10))<< endl; // a kiírt érték: 10
Komplex x(2,-1), y(3,4);
x*=y;
x.Kiir(); // 10+5i
}
Felhívjuk a figyelmet, hogy a Komplex osztály három konstruktora egyetlen konstruktorral helyettesíthető, amelyben alapértelmezett argumentumokat használunk:
Komplex(double a=0, double b=0) : re(a), im(b) {}
III.2.3.3. Az osztályok bővítése input/output műveletekkel
A C++ nyelv lehetővé teszi, hogy az osztályokon alapuló I/O adatfolyamoknak „megtanítsuk” a saját készítésű osztályok objektumainak kezelését. Az adatfolyam osztályok közül az istream az adatbevitelért, míg az ostream az adatkivitelért felelős.
Az input/output műveletek végzéséhez a >> és a << operátorok túlterhelt változatait használjuk. A szükséges működés eléréséhez friend operátorfüggvényként kell elkészítenünk a fenti műveletek saját változatait, mint ahogy ez a Komplex osztály bővített változatában látható:
#include <cmath>
#include <sstream>
#include <iostream>
using namespace std;
class Komplex {
public:
Komplex(double a=0, double b=0) : re(a), im(b) {}
operator double() {return sqrt(re*re+im*im);}
Komplex operator *= (const Komplex & k) {
Komplex t;
t.re=(k.re*re)-(k.im*im);
t.im=(k.re*im)+(re*k.im);
return *this = t;
}
private:
double re, im;
friend Komplex operator*(const Komplex&, const Komplex&);
friend istream & operator>>(istream &, Komplex &);
friend ostream & operator<<(ostream &, const Komplex &);
};
Komplex operator*(const Komplex& k1, const Komplex& k2) {
Komplex k=k1;
k*= k2;
return k;
}
// Az adatbevitel formátuma: 12.23+7.29i, illetve 12.23-7.29i
istream & operator>>(istream & is, Komplex & c) {
string s;
getline(is, s);
stringstream ss(s);
if (!(ss>>c.re>>c.im))
c=Komplex(0);
return is;
}
// Adatkiviteli formátum: 12.23+7.29i, illetve 12.23-7.29i
ostream & operator<<(ostream & os, const Komplex & c) {
os<<c.re<<(c.im<0? '-' : '+')<<fabs(c.im)<<'i';
return os;
}
int main() {
Komplex a, b;
cout<<"Kerek egy komlex szamot: "; cin >> a;
cout<<"Kerek egy komlex szamot: "; cin >> b;
cout<<"A komplex szamok szorzata: " << a*b <<endl;
}
III.3. Öröklés (származtatás)
Az előző fejezetekben megismertük, hogyan tudunk feladatokat egymástól független osztályokkal megoldani. Az objektum-orientált programozás több lehetőséget kínál. A problémák objektum-orientált feldolgozása során általában egy új programépítési módszert, a származtatást (öröklés, inheritance) alkalmazzuk. A származtatás lehetővé teszi, hogy már meglévő osztályok adatait és műveleteit új megközelítésben alkalmazzuk, illetve a feladat igényeinek megfelelően módosítsuk, bővítsük. A problémákat így nem egyetlen (nagy) osztállyal, hanem osztályok egymásra épülő rendszerével (általában hierarchiájával) oldjuk meg.
Az öröklés az objektum-orientált C++ nyelv egyik legfőbb sajátossága. Ez a mechanizmus lehetővé teszi, hogy meglévő osztály(ok)ból kiindulva, új osztályt hozzunk létre (származtassunk). A származtatás során az új osztály örökli a meglévő osztály(ok) nyilvános (public) és védett (protected) tulajdonságait (adattagjait) és viselkedését (tagfüggvényeit), amelyeket aztán a annak sajátjaként használhatunk. Azonban az új osztállyal bővíthetjük is a meglévő osztály(oka)t, új adattagokat és tagfüggvényeket definiálhatunk, illetve újraértelmezhetjük (lecserélhetjük) az öröklött, de működésükben elavult tagfüggvényeket (polimorfizmus, polymorphism).
A szakirodalom örökléssel kapcsolatos szóhasználata igen változatos, ezért röviden összefoglaljuk az magyar és angol nyelvű kifejezéseket, aláhúzással kiemelve a C++-ban alkalmazottakat.
|
|
A osztály, amiből származtatunk: alaposztály, ősosztály, szülőosztály ( base class , ancestor class , parent class, superclass) a művelet: öröklés, származtatás, bővítés ( inheritance , derivation , extending, subclassing) B osztály, a származtatás eredménye: utódosztály, származtatott osztály, bővített osztály, gyermekosztály, alosztály ( descendant class , derived class , extended class, child class, subclass) |
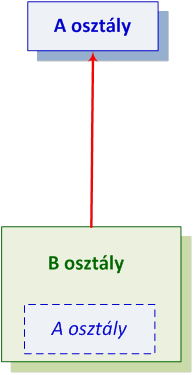
A fenti kapcsolatot megvalósító C++ programrészlet:
class AOsztaly {
// ...
};
class BOsztaly : public AOsztaly {
// ...
};
A szakirodalomban nem egyértelmű a fogalmak használata, például egy adott osztály alaposztálya vagy ősosztálya tetszőleges elődöt jelölhet, illetve az utódosztály vagy származtatott osztály minősítés bármely örökléssel létrehozott osztály esetén alkalmazható. Könyvünkben ezeket a fogalmakat a közvetlen ős, illetve közvetlen utód értelemben használjuk.
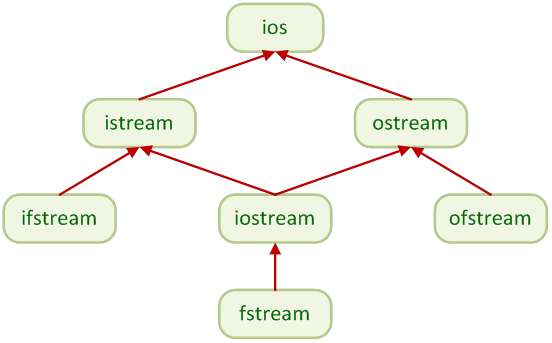
A C++ támogatja a többszörös öröklődést (multiple inheritance), melynek során valamely új osztályt több alaposztályból (közvetlen őstől) származtatunk (III.5. ábra - A C++ többszörös örölésű I/O osztályai). A többszörös örökléssel kialakított osztályszerkezet hálós szerkezetű, melynek értelmezése és kezelése is nehézségekbe ütközik. Ezért ezt a megoldást igen korlátozott módon használjuk, helyette - az esetek nagy többségében - az egyszeres öröklést (single inheritance) alkalmazzuk. Ebben az esetben valamely osztálynak legfeljebb egy közvetlen őse, és tetszőleges számú utódja lehet. Az öröklés több lépésben való alkalmazásával igazi fastruktúra (osztály-hierarchia) alakítható ki (III.6. ábra - Geometriai osztályok hierarchiája).
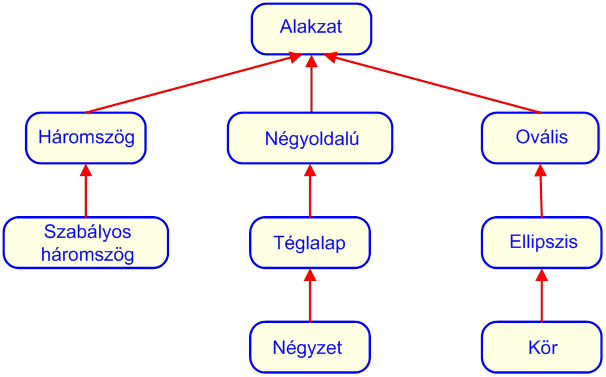
III.3.1. Osztályok származtatása
A származtatott osztály (utódosztály) olyan osztály, amely az adattagjait és a tagfüggvényeit egy vagy több előzőleg definiált osztálytól örökli. Azt az osztályt, amelytől a származtatott osztály örököl, alaposztálynak (ősosztály) nevezzük. A származtatott osztály szintén lehet alaposztálya további osztályoknak, lehetővé téve ezzel osztályhierarchia kialakítását.
A származtatott osztály az alaposztály minden tagját örökli, azonban az alaposztályból csak a public és protected (védett) tagokat éri el sajátjaként. A védett elérés kettős viselkedést takar. Privát hozzáférést jelent az adott osztály felhasználójának, aki objektumokat hoz létre vele, azonban nyilvános elérést biztosít az osztály továbbfejlesztőjének, aki új osztályt származtat belőle. A tagfüggvényeket általában public vagy protected hozzáféréssel adjuk meg, míg az adattagok esetén a protected vagy a private elérést alkalmazzuk. (A privát hozzáféréssel a származtatott osztály tagfüggvényei elől is elrejtjük a tagokat.) A származtatott osztályban az öröklött tagokat saját adattagokkal és tagfüggvényekkel is kiegészíthetjük.
A származtatás kijelölésére az osztály fejét használjuk, ahol az alaposztályok előtt megadhatjuk a származtatás módját (public, protected, private):
class Szarmaztatott : public Alap1, ...private AlapN
{
// az osztály törzse
};
Az alaposztálybeli elérhetőségüktől függetlenül nem öröklődnek a konstruktorok, a destruktor, az értékadó operátor valamint a friend viszonyok. Az esetek többségében nyilvános (public) öröklést használunk, mivel ekkor az utódobjektum minden kontextusban helyettesítheti az ősobjektumot.
Az alábbi – síkbeli és térbeli pontokat definiáló – példában bemutatjuk a származtatás alkalmazását. A kialakított osztály-hierarchia igen egyszerű (a piros nyíl a közvetlen alaposztályra mutat):
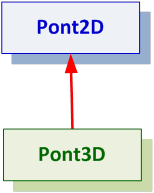
class Pont2D {
protected:
int x,y;
public:
Pont2D(int a = 0, int b = 0) { x = a; y = b; }
void GetPont2D(int& a, int& b) const { a=x; b=y;}
void Mozgat(int a=0, int b=0) { x = a; y = b; }
void Mozgat(const Pont2D& p) { x = p.x; y = p.y; }
void Kiir() const { cout<<'('<<x<<','<<y<<')'<<endl; }
};
class Pont3D : public Pont2D {
protected:
int z;
public:
Pont3D(int a=0, int b=0, int c=0):Pont2D(a,b),z(c) {}
Pont3D(Pont3D & p):Pont2D(p.x, p.y),z(p.z) {}
void GetPont3D(int& a, int& b, int& c) const {
a = x; b = y; c = z; }
void Mozgat(int a=0, int b=0, int c=0) {
x = a; y = b; z = c; }
void Mozgat(const Pont3D& p) {
Pont2D::x = p.x; y = p.y; z = p.z;}
void Kiir() const {
cout<<'('<<x<<','<<y<<','<<z<<')'<<endl;}
};
void Megjelenit(const Pont2D & p) {
p.Kiir();
}
int main() {
Pont2D p1(12,23), p2(p1), p3;
Pont3D q1(7,29,80), q2(q1), q3;
p1.Kiir(); // (12,23)
q1.Kiir(); // (7,29,80)
// q1 = p1; // ↯ - hiba!
q2.Mozgat(10,2,4);
p2 = q2;
p2.Kiir(); // (10,2)
q2.Kiir(); // (10,2,4)
q2.Pont2D::Kiir(); // (10,2)
Megjelenit(p2); // (10,2)
Megjelenit(q2); // (10,2)
}
A példában kék színnel kiemeltük az öröklés következtében alkalmazott programelemeket, melyekkel a fejezet további részeiben foglalkozunk.
Láthatjuk, hogy a public származtatással létrehozott osztály objektuma minden esetben (értékadás, függvényargumentum,...) helyettesítheti az alaposztály objektumát:
p2 = q2; Megjelenit(q2);
Ennek oka, hogy az öröklés során a származtatott osztály teljesen magában foglalja az alaposztályt. Fordítva azonban ez nem igaz, így az alábbi értékadás fordítási hibához vezet:
q1 = p1; // ↯
A származtatási listában megadott public, protected és private kulcsszavak az öröklött (nyilvános és védett) tagok új osztálybeli elérhetőségét szabályozzák, az alábbi táblázatban összefoglalt módon.
|
Az öröklés módja |
Alaposztálybeli elérés |
Hozzáférés a származtatott osztályban |
|---|---|---|
|
public |
public protected |
public protected |
|
protected |
public protected |
protected protected |
|
private |
public protected |
private private |
A public származtatás során az öröklött tagok megtartják az alaposztálybeli elérhetőségüket, míg a private származtatás során az öröklött tagok a származtatott osztály privát tagjaivá válnak, így elzárjuk azokat mind az új osztály felhasználói, mind pedig a továbbfejlesztői elől. Védett (protected) öröklés esetén az öröklött tagok védettek lesznek az új osztályban, így további öröklésük biztosított marad. (A class típusú alaposztályok esetén a privát, míg a struct típust használva a public az alapértelmezés szerinti származtatási mód.)
Ez az automatizmus az esetek nagy többségében megfelelő eredményt szolgáltat, és a származtatott osztályaink öröklött tagjaihoz megfelelő elérést biztosít. Szükség esetén azonban közvetlenül is beállíthatjuk bármely öröklött (az alaposztályban védett és nyilvános hozzáférésű) tag elérését. Ehhez a tagok alaposztállyal minősített nevét egyszerűen bele kell helyeznünk a megfelelő hozzáférésű csoportba. Arra azonban ügyelni kell, hogy az új elérhetőség nem adhat több hozzáférést, mint amilyen az ősosztályban volt. Például, ha egy ősbeli protected tagot privát módon öröklünk, az automatikusan private elérésű lesz a származtatott osztályban, mi azonban a védett csoportba is áthelyezhetjük (de a nyilvánosba nem!).
Példaként származtassuk privát örökléssel a Pont3D osztályt, azonban ennek ellenére alakítsunk ki hasonló elérhetőséget, mint amilyen a nyilvános származtatás esetén volt!
class Pont3D : private Pont2D {
protected:
int z;
Pont2D::x;
Pont2D::y;
public:
Pont3D(int a=0, int b=0, int c=0):Pont2D(a,b),z(c) {}
Pont3D(Pont3D & p):Pont2D(p.x, p.y),z(p.z) {}
void GetPont3D(int& a, int& b, int& c) const {
a = x; b = y; c = z; }
void Mozgat(int a=0, int b=0, int c=0) {
x = a; y = b; z = c; }
void Mozgat(const Pont3D& p) {
x = p.x; y = p.y; z = p.z;}
void Kiir() const {
cout<<'('<<x<<','<<y<<','<<z<<')'<<endl;}
Pont2D:: GetPont2D;
};
III.3.2. Az alaposztály(ok) inicializálása
Az alaposztály(ok) inicializálására a taginicializáló lista kibővített változatát használjuk, amelyben a tagok mellett a közvetlen ősök konstruktorhívásait is felsoroljuk.
class Pont3D : public Pont2D {
protected:
int z;
public:
Pont3D(int a=0, int b=0, int c=0):Pont2D(a,b),z(c) {}
Pont3D(Pont3D & p):Pont2D(p.x, p.y),z(p.z) {}
// …
};
A származtatott osztály példányosítása során a fordító az alábbi sorrendben hívja a konstruktorokat:
Végrehajtódnak az alaposztályok konstruktorai az származtatási lista szerinti sorrendben.
Meghívódnak a származtatott osztály tagobjektumainak konstruktorai, az objektumtagok megadásának sorrendjében (a példában nem szerepelnek).
Lefut a származtatott osztály konstruktora.
Az ősosztály konstruktorhívása elhagyható, amennyiben az alaposztály rendelkezik paraméter nélküli konstruktorral, amit ebben az esetben a fordító automatikusan meghív. Mivel példánkban ez a feltétel teljesül, a második konstruktort az alábbi formában is megvalósíthatjuk:
Pont3D(Pont3D & p) { *this = p;}
(A megoldás további feltétele a nyilvános öröklés, ami szintén teljesül.)
Osztályhierarchia fejlesztése során elegendő, ha minden osztály csupán a közvetlen őse(i) inicializálásáról gondoskodik. Ezáltal egy magasabb szinten (a gyökértől távolabb) található osztály példányának minden része automatikusan kezdőértéket kap, amikor az objektum létrejön.
A származtatott objektumpéldány megszűnésekor a destruktorok a fentiekkel ellentétes sorrendben hajtódnak végre.
Lefut a származtatott osztály destruktora.
Meghívódnak a származtatott osztály tagobjektumainak destruktorai, az objektumtagok megadásával ellentétes sorrendben
Végrehajtódnak az alaposztályok destruktorai, a származtatási lista osztálysorrendjével ellentétes sorrendben.
III.3.3. Az osztálytagok elérése öröklés esetén
Az III.2. szakasz - Osztályok és objektumok két csoportba soroltuk az osztályok tagjait az elérhetőség szempontjából: elérhető, nem érhető el. Ezt a két csoportot az öröklött és nem öröklött kategóriák csak tovább árnyalják. Az osztályok származtatását bemutató fejezetben (III.3.1. szakasz - Osztályok származtatása) megismerkedtünk az alapvető elérési mechanizmusok működésével. Most csupán áttekintünk néhány további megoldást, amelyek pontosítják az eddigi képünket az öröklésről.
III.3.3.1. Az öröklött tagok elérése
A származtatott osztály öröklött tagjai általában ugyanúgy érhetők el, mint a saját tagok. Ha azonban a származtatott osztályban az öröklött tag nevével azonos néven hozunk létre adattagot vagy tagfüggvényt, akkor az elfedi az ősosztály tagját. Ilyen esetekben a hatókör operátort kell használnunk a hivatkozáshoz:
Osztálynév::tagnév
A fordítóprogram a tagneveket az osztály hatókörrel együtt azonosítja, így minden tagnév felírható a fenti formában. A III.3.1. szakasz - Osztályok származtatása példaprogramjában látunk példákat az elmondottakra.
class Pont3D : public Pont2D {
protected:
int z;
public:
Pont3D(int a=0, int b=0, int c=0):Pont2D(a,b),z(c) {}
Pont3D(Pont3D & p):Pont2D(p.x, p.y),z(p.z) {}
// …
void Mozgat(const Pont3D& p) {
Pont2D::x = p.x; y = p.y; z = p.z;}
// …
};
int main() {
Pont2D p1(12,23), p2(p1), p3;
Pont3D q1(7,29,80), q2(q1), q3;
q2.Pont2D::Kiir();
q2.Pont2D::Mozgat(1,2); // Mozgatás a x-y síkban
q2.Pont2D::Mozgat(p1);
// …
}
Az alábbi táblázatban összefoglaltuk, hogy az említett példaprogram osztályai, milyen (általuk elérhető) tagokkal rendelkeznek. Elfedés esetén a tagok osztálynévvel minősített változatát adtuk meg:
|
A Pont2D alaposztály tagjai: |
A Pont3D származtatott osztály tagjai |
|---|---|
|
|
|
III.3.3.2. A friend viszony az öröklés során
Az alaposztály „barátja” (friend) a származtatott osztályban csak az alaposztályból öröklött tagokat érheti el. A származtatott osztály „barátja” az alaposztályból csak a nyilvános és a védett tagokat érheti el.
III.3.4. Virtuális alaposztályok a többszörös öröklésnél
A többszörös öröklés során problémát jelenthet, ha ugyanazon alaposztály több példányban jelenik meg a származtatott osztályban. A virtuális alaposztályok használatával az ilyen jellegű problémák kiküszöbölhetők (III.7. ábra - Virtuális alaposztályok alkalmazása).
class Alap {
int q;
public:
Alap(int v=0) : q(v) {};
int GetQ() { return q;}
void SetQ(int q) { this->q = q;}
};
// az Alap virtuális alaposztály
class Alap1 : virtual public Alap {
int x;
public:
Alap1(int i): x(i) {}
};
// az Alap virtuális alaposztály
class Alap2: public virtual Alap {
int y;
public:
Alap2(int i): y(i) {}
};
class Utod: public Alap1, public Alap2 {
int a,b;
public:
Utod(int i=0,int j=0): Alap1(i+j),Alap2(j*i),a(i),b(j) {}
};
int main() {
Utod utod;
utod.Alap1::SetQ(100);
cout << utod.GetQ()<<endl; // 100
cout << utod.Alap1::GetQ()<<endl; // 100
cout << utod.Alap2::GetQ()<<endl; // 100
utod.Alap1::SetQ(200);
cout << utod.GetQ()<<endl; // 200
cout << utod.Alap1::GetQ()<<endl; // 200
cout << utod.Alap2::GetQ()<<endl; // 200
}
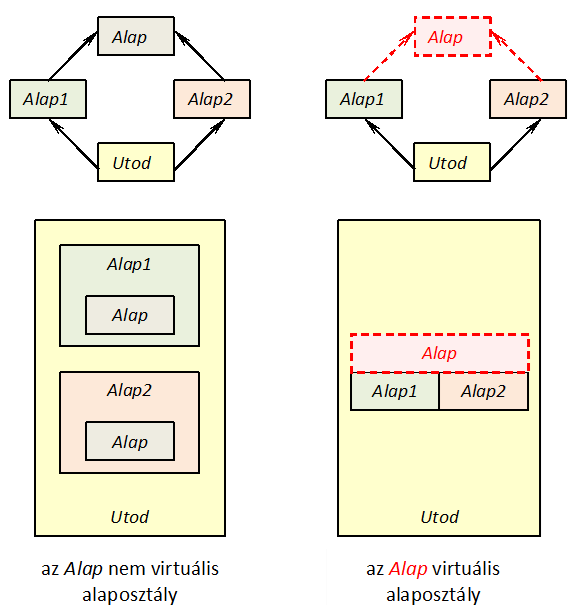
A virtuális alaposztály az öröklés során csak egyetlen példányban lesz jelen a származtatott osztályokban, függetlenül attól, hogy hányszor fordul elő az öröklődési láncban. A példában a virtuális alaposztály q adattagját egyaránt öröklik az Alap1 és az Alap2 alaposztályok. A virtualitás miatt az Alap osztály egyetlen példányban szerepel, így az Alap1::q és az Alap2::q ugyanarra az adattagra hivatkoznak. A virtual szó használata nélkül az Alap1::q és az Alap2::q különböző adattagokat jelölnek, ami fordítási hibához vezet, mivel fordító számára nem lesz egyértelmű az utod.GetQ() hivatkozás feloldása.
III.3.5. Öröklés és/vagy kompozíció?
A C++ programozási nyelv egyik nagy előnye a programkód újrafelhasználásának támogatása. Az újrafelhasználás azt jelenti, hogy az eredeti programkód módosítása nélkül készítünk új programkódot. C++ nyelv objektum-orientált eszközeit használva három megközelítés közül választhatunk:
Egy adott osztályban tárolt kód legegyszerűbb és leggyakoribb újrahasznosítása, amikor objektumpéldányt hozunk létre, vagy már létező objektumokat ( cin , cout , string , STL stb.) használunk a programunkban.
class X { // … }; int main() { X a, *pb; pb = new X(); cout<<"C++"<<endl; // … delete pb; }További lehetőséghez jutunk, ha a saját osztályunkban más osztályok objektumait helyezzük el tagobjektumként. Mivel ekkor az új osztályt már meglévő osztályok felhasználásával állítjuk össze, ezt a módszert kompozíciónak nevezzük. Kompozíció során az új és a beépített objektumok között egy tartalmazás (has-a) kapcsolat alakul ki. Amennyiben az új objektumba csupán más objektumok mutatója vagy hivatkozása kerül aggregációról beszélünk.
class X { // … }; class Y { X x; // kompozíció }; class Z { X& x; // aggregáció X *px; };Harmadik megoldás a fejezetünk témájával kapcsolatos. Amikor az új osztályunkat nyilvános származtatással hozzuk létre más osztályokból, akkor egy általánosítás/pontosítás (is-a) kapcsolat jön létre. Ez a kapcsolat azt jelenti, hogy a származtatott objektum minden szempontból úgy viselkedik, mint egy ősobjektum (azaz a leszármazott objektum egyben mindig ősobjektum is) - ez azonban fordítva nem áll fenn.
// alaposztály class X { // … }; // származtatott osztály class Y : public X { // … };
Valamely probléma objektum-orientált megoldása során mérlegelni kell, hogy az öröklés vagy a kompozíció segítségével jutunk-e pontosabb modellhez. A döntés általában nem egyszerű, de néhány szempont megfogalmazható:
Kezdetben ajánlott kiindulni a kompozícióból, majd ha kiderül, hogy az új osztály valójában egy speciális típusa egy másik osztálynak, akkor jöhet az öröklés.
Származtatásnak elsődlegesen akkor van létjogosultsága, ha szükséges az ősosztályra való típus-átalakítás. Ilyen eset például, ha egy geometriai rendszer összes elemét láncolt listában szeretnénk tárolni.
A túl sok származtatás, a mély osztály-hierarchia nehezen karbantartható kódot eredményezhet. Ezért egy nagyobb feladat megoldása során ajánlott az kompozíciót és az öröklést szerves egységben alkalmazni.
Az alábbi két példaprogramból jól láthatók a kompozíció és a származtatás közötti különbségek, illetve azonosságok. Minkét esetben a Pont.h állományban tárolt Pont osztályt hasznosítjuk újra.
#ifndef __PONT_H__
#define __PONT_H__
class Pont {
protected:
int x,y;
public:
Pont(int a = 0, int b = 0) : x(a), y(b) {}
Pont(const Pont& p) : x(p.x), y(p.y) {}
int GetX() const { return x; }
int GetY() const { return y; }
void SetX(int a) { x = a; }
void SetY(int a) { y = a; }
void Mozgat(int a, int b) { x = a; y = b; }
void Mozgat(const Pont& p) { x = p.x; y = p.y; }
void Kiir() const { cout<<'('<<x<<','<<y<<')'<< endl; }
};
#endif
III.3.5.1. Újrahasznosítás kompozícióval
A való életben az összetett objektumok gyakran kisebb, egyszerűbb objektumokból épülnek fel. Például, egy gépkocsi fémvázból, motorból, néhány abroncsból, sebességváltóból, kormányozható kerekekből és nagyszámú más részegységből állítható össze. Elvégezve az összeállítást mondhatjuk, hogy a kocsinak van egy (has-a) motorja, van egy sebességváltója stb.
A Kor példánkban a körnek van egy középpontja, amit a Pont típusú p tagobjektum tárol. Fontos megjegyeznünk, hogy a Kor osztály tagfüggvényiből csak a Pont osztály nyilvános tagjait érhetjük el.
#include "Pont.h"
class Kor {
protected:
int r;
public:
Pont p; // kompozció
Kor(int x=0, int y=0, int r=0)
: p(x, y), r(r) {}
Kor(const Pont& p, int r=0)
: p(p), r(r) {}
int GetR() {return r;}
void SetR(int a) { r = a; }
};
int main() {
Kor k1(100, 200, 10);
k1.p.Kiir();
cout<<k1.p.GetX()<<endl;
cout<<k1.GetR()<<endl;
}
III.3.5.2. Újrahasznosítás nyilvános örökléssel
A kompozícióhoz hasonlóan az öröklésre is számos példát találunk a való életben. Mindenki örököl géneket a szüleitől, a C++ nyelv is sok mindent örökölt a C nyelvtől, amely szintén örökölte a jellegzetességeinek egy részét az elődeitől. Származtatás során közvetlenül megkapjuk az ősobjektum(ok) attribútumait és viselkedését, és kibővítjük vagy pontosítjuk azokat.
A példánkban a Kor típusú objektum szerves részévé válik a Pont objektum, mint a kör középpontja, ami teljes mértékben megfelel a kör geometriai definíciójának. Ellentétben a kompozícióval a Kor osztály tagfüggvényiből a Pont osztály védett és nyilvános tagjait egyaránt elérhetjük.
#include "Pont.h"
class Kor : public Pont { // öröklés
protected:
int r;
public:
Kor(int x=0, int y=0, int r=0)
: Pont(x, y), r(r) {}
Kor(const Pont & p, int r=0)
: Pont(p), r(r) {}
int GetR() {return r;}
void SetR(int a) { r = a; }
};
int main() {
Kor k1(100, 200, 10);
k1.Kiir();
cout<<k1.GetX()<<endl;
cout<<k1.GetR()<<endl;
}
III.4. Polimorfizmus (többalakúság)
Amikor a C++ nyelvvel kapcsolatban szó esik a többalakúságról, általában arra gondolunk, amikor a származtatott osztály objektumát az alaposztály mutatóján, illetve hivatkozásán keresztül érjük el. Valójában ez az alosztály (subtype), illetve futásidejű (run-time) polimorfizmusnak vagy egyszerűen csak felüldefiniálásnak (overriding) hívott megoldás képezi fejezetünk tárgyát, mégis tekintsük át a C++ további „többalakú” megoldásait is!
A kényszerítés (coercion) polimorfizmus alatt az implicit és az explicit típus-átalakításokat értjük. Ekkor egy adott művelet többalakúságát a különböző típusok biztosítják, amelyek szükség esetén konvertálunk.
A kényszerítéssel ellentétes az ún. ad-hoc („erre a célra készült”) polimorfizmus, ismertebb nevén a függvénynevek túlterhelése (overloading). Ekkor a fordítóprogram a típusok alapján választja ki az elkészített függvényváltozatok közül a megfelelőt.
Ez utóbbi kiterjesztése a parametrikus vagy fordításidejű (compile-time) polimorfizmus, ami lehetővé teszi, hogy ugyanazt a kódot bármilyen típussal végre tudjuk hajtani. C++-ban a függvény- és az osztálysablonok (templates) segítségével valósul meg a parametrikus többalakúság. Sablonok használatával valójában újrahasznosítjuk a C++ forráskódot.
Korábban már láttuk, hogy az öröklés során a leszármazott osztály örökli az őse minden tulajdonságát és viselkedését (műveletét). Ezek az öröklött tagfüggvények minden további nélkül használhatók a származtatott osztály objektumaival is, hiszen magukban foglalják az őseiket. Mivel öröklés során gyakran specializáljuk az leszármazott osztályt, szükséges lehet, hogy bizonyos örökölt műveletek másképp működjenek. Ezt az igényt a virtuális (virtual) tagfüggvények bevezetésével teljesíthetjük. A futásidejű polimorfizmusnak köszönhetően egy objektum attól függően, hogy az osztály-hierarchia mely szintjén lévő osztály példánya, ugyanarra az üzenetre másképp reagál. Az pedig, hogy az üzenet hatására melyik tagfüggvény hívódik meg az öröklési láncból, csak a program futása közben derül ki (késői kötés).
III.4.1. Virtuális tagfüggvények
A virtuális függvény olyan public vagy protected tagfüggvénye az alaposztálynak, amelyet a származtatott osztályban újradefiniálhatunk az osztály „viselkedésének” megváltoztatása érdekében. A virtuális függvény általában a nyilvános alaposztály referenciáján vagy mutatóján keresztül hívódik meg, melynek aktuális értéke a program futása során alakul ki (dinamikus összerendelés, késői kötés).
Ahhoz, hogy egy tagfüggvény virtuális legyen, a virtual kulcsszót kell megadnunk az osztályban a függvény deklarációja előtt:
class Pelda {
public:
virtual int vf();
};
Nem szükséges, hogy az alaposztályban a virtuális függvénynek a definíciója is szerepeljen – helyette a függvény prototípusát az =0; kifejezéssel is lezárhatjuk Ebben az esetben ún. tisztán virtuális függvénnyel (pure virtual function) van dolgunk:
class Pelda {
public:
virtual int tvf() = 0;
};
Egy vagy több tisztán virtuális függvényt tartalmazó osztállyal (absztrakt osztállyal) nem készíthetünk objektumpéldányt. Az absztrakt osztály csak az öröklés kiinduló pontjaként, alaposztályaként használható.
Amennyiben egy tagfüggvény az osztály-hierarchia valamely pontján virtuálissá válik, akkor lecserélhetővé válik az öröklési lánc későbbi osztályaiban.
III.4.2. A virtuális függvények felüldefiniálása (redefine)
Ha egy függvényt az alaposztályban virtuálisként deklarálunk, akkor ezt a tulajdonságát megőrzi az öröklődés során. A származtatott osztályban a virtuális függvényt saját változattal újradefiniálhatjuk, de az öröklött verziót is használhatjuk. Saját új verzió definiálásakor nem szükséges a virtual szót megadnunk.
Ha egy származtatott osztály tiszta virtuális függvényt örököl, akkor ezt mindenképpen saját verzióval kell újradefiniálni, különben az új osztály is absztrakt osztály lesz. A származtatott osztály tartalmazhat olyan virtuális függvényeket is, amelyeket nem a közvetlen alaposztálytól örökölt.
A származtatott osztályban az újradefiniált virtuális függvény prototípusának pontosan (név, típus, paraméterlista) meg kell egyeznie az alaposztályban definiálttal. Ha a két deklaráció paraméterezése nem pontosan egyezik, akkor az újradefiniálás helyett a túlterhelés (overloading) mechanizmusa érvényesül.
|
Az alábbi példaprogramban mindegyik alakzat saját maga számolja ki a területét és a kerületét, azonban a megjelenítést az absztrakt alaposztály (Alakzat) végzi. Az osztályok hierarchiája az ábrán látható: |
|
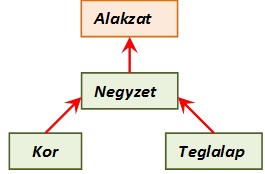
// Absztrakt alaposztály
class Alakzat {
protected:
int x, y;
public:
Alakzat(int x=0, int y=0) : x(x), y(y) {}
virtual double Terulet()=0;
virtual double Kerulet()=0;
void Megjelenit() {
cout<<'('<<x<<','<<y<<")\t";
cout<<"\tTerulet: "<< Terulet();
cout<<"\tKerulet: "<< Kerulet() <<endl;
}
};
class Negyzet : public Alakzat {
protected:
double a;
public:
Negyzet(int x=0, int y=0, double a=0)
: Alakzat(x,y), a(a) {}
double Terulet() {return a*a;}
double Kerulet() {return 4*a;}
};
class Teglalap : public Negyzet {
protected:
double b;
public:
Teglalap(int x=0, int y=0, double a=0, double b=0)
: Negyzet(x,y,a), b(b) {}
double Terulet() {return a*b;}
double Kerulet() {return 2*(a+b);}
};
class Kor : public Negyzet {
const double pi;
public:
Kor(int x=0, int y=0, double r=0)
: Negyzet(x,y,r), pi(3.14159265) {}
double Terulet() {return a*a*pi;}
double Kerulet() {return 2*a*pi;}
};
int main() {
Negyzet n(12,23,10);
cout<<"Negyzet: ";
n.Megjelenit();
Kor k(23,12,10);
cout<<"Kor: ";
k.Megjelenit();
Teglalap t(12,7,10,20);
cout<<"Teglalap: ";
t.Megjelenit();
Alakzat* alakzatok[3] = {&n, &k, &t} ;
for (int i=0; i<3; i++)
alakzatok[i]->Megjelenit();
}
A virtuális függvények használata és a nyilvános öröklés lehetővé teszi, hogy az osztály-hierarchia minden objektumával hívható külső függvényeket hozzunk létre:
void MindentMegjelenit(Alakzat& a) {
cout<<"Terulet: "<<a.Terulet()<<endl;
cout<<"Kerulet: "<<a.Kerulet()<<endl;
}
III.4.3. A korai és a késői kötés
A futásidejű többalakúság jobb megértése céljából, példák segítségével megvizsgáljuk a tagfüggvény-hívások fordítási időben (korai kötés – early binding) és a futási időben (késői kötés – late binding) történő feloldását.
A példaprogramokban két azonos prototípusú tagfüggvényt (GetNev(), GetErtek()) definiálunk az alaposztályban és a leszármazott osztályban. A main() függvényben pedig alaposztály típusú mutatóval (pA) és referenciával (rA) hivatkozunk a származtatott osztály példányára.
III.4.3.1. A statikus korai kötés
Korai kötés során a fordító a statikusan befordítja a kódba a közvetlen tagfüggvény-hívásokat. Az osztályok esetén ez az alapértelmezett működési mód, ami jól látható az alábbi példaprogram futásának eredményéből.
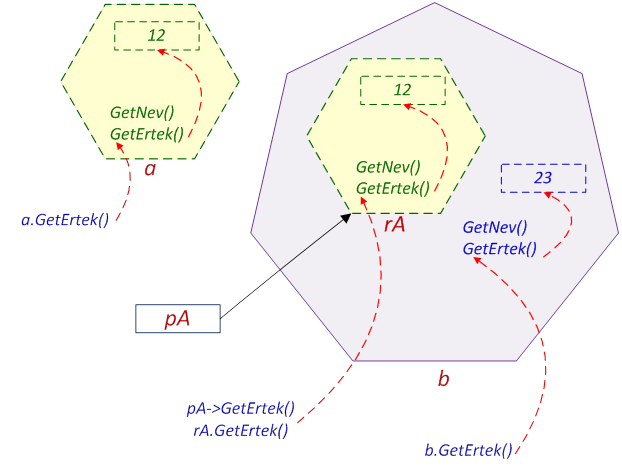
class Alap {
protected:
int ertek;
public:
Alap(int a=0) : ertek(a) { }
const char* GetNev() const { return "Alap"; }
int GetErtek() const { return ertek; }
};
class Szarmaztatott: public Alap {
protected:
int ertek;
public:
Szarmaztatott(int a=0, int b=0) : Alap(a), ertek(b) { }
const char* GetNev() const { return "Szarmaztatott"; }
int GetErtek() const { return ertek; }
};
int main() {
Alap a;
Szarmaztatott b(12, 23);
a = b;
Alap &rA = b;
Alap *pA = &b;
cout<<"a \t" << a.GetNev()<<"\t"<< a.GetErtek()<<endl;
cout<<"b \t" << b.GetNev()<<"\t"<< b.GetErtek()<<endl;
cout<<"rA\t" << rA.GetNev()<<"\t"<< rA.GetErtek()<<endl;
cout<<"pA\t" <<pA->GetNev()<<"\t"<<pA->GetErtek()<<endl;
}
A programban a GetErtek() tagfüggvény hívásait a III.8. ábra - Korai kötés példa szemlélteti. A program futásának eredménye:
a Alap 12 b Szarmaztatott 23 rA Alap 12 pA Alap 12
III.4.3.2. A dinamikus késői kötés
Alapvetően változik a helyzet (III.8. ábra - Korai kötés példa), ha az Alap osztályban a GetNev(), GetErtek() tagfüggvényeket virtuálissá tesszük.
class Alap {
protected:
int ertek;
public:
Alap(int a=0) : ertek(a) { }
virtual const char* GetNev() const { return "Alap"; }
virtual int GetErtek() const { return ertek; }
};
A példaprogram futásának eredménye is módosult:
a Alap 12 b Szarmaztatott 23 rA Szarmaztatott 23 pA Szarmaztatott 23
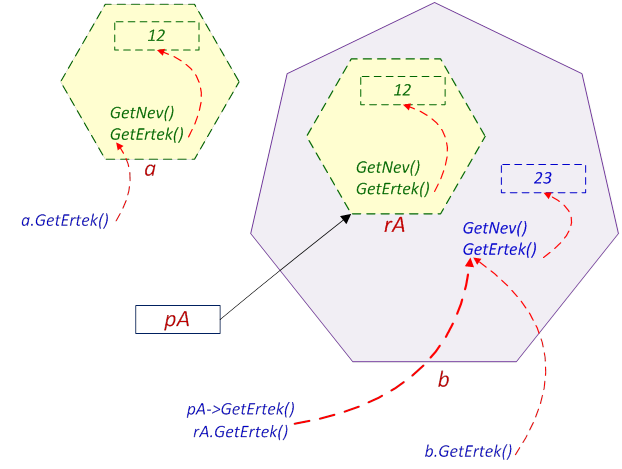
A virtuális függvények hívását közvetett módon, memóriában tárolt címre történő ugrással helyezi el a kódban a fordító. A címek tárolására használt virtuális metódustábla (VMT) a program futása során osztályonként, az osztály első példányosításakor jön létre. A VMT az aktuális, újradefiniált virtuális függvények címét tartalmazza. Az osztályhierarchiában található azonos nevű virtuális függvények azonos indexszel szerepelnek ezekben a táblákban, ami lehetővé teszi a virtuális tagfüggvények teljes lecserélését.
III.4.3.3. A virtuális metódustábla
Amennyiben egy osztály egy vagy több virtuális tagfüggvénnyel rendelkezik, a fordító kiegészíti az objektumot egy „virtuális mutatóval”, amely egy virtuális metódustáblának (VMT – Virtual Method Table) vagy virtuális függvénytáblának (VFTable – Virtual Function Table) hívott globális adattáblára mutat. A VMT függvénypointereket tartalmaz, amelyek az adott osztály, illetve az ősosztályok legutoljára újradefiniált virtuális tagfüggvényeire mutatnak (III.10. ábra - A példaprogram virtuális metódustáblái). Az azonos nevű virtuális függvények címe azonos indexszel szerepel ezekben a táblákban.
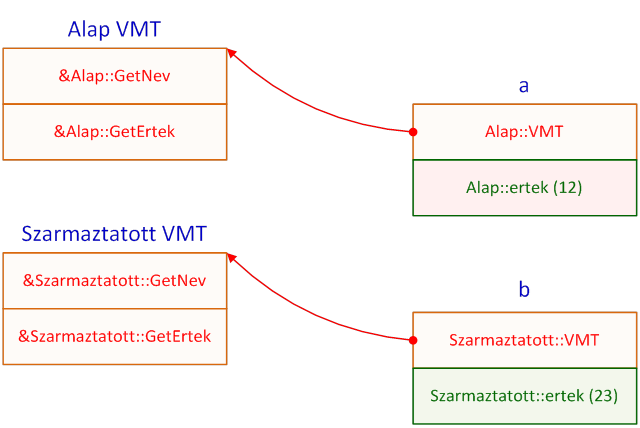
Az osztályonkénti VMT futás közben, az első konstruktorhíváskor jön létre. Ennek következtében a hívó és hívott tagfüggvény közötti kapcsolat szintén futás közben realizálódik. A fordító mindössze egy olyan hívást helyez a kódba, amely a VMT i. elemének felhasználásával megy végbe (call VMT[i]).
III.4.4. Virtuális destruktorok
A destruktort virtuális függvényként is definiálhatjuk. Ha az alaposztály destruktora virtuális, akkor minden ebből származtatott osztály destruktora is virtuális lesz. Ezáltal biztosak lehetünk abban, hogy a megfelelő destruktor hívódik meg, amikor az objektum megszűnik, még akkor is, ha valamelyik alaposztály típusú mutatóval vagy referenciával hivatkozunk a leszármazott osztály példányára.
A mechanizmus kiváltásához elegendő valahol az öröklési lánc kezdetén egy virtuális, üres destruktort, vagy egy tisztán virtuális destruktort elhelyeznünk egy osztályban:
class Alap {
protected:
int ertek;
public:
Alap(int a=0) : ertek(a) { }
virtual const char* GetNev() const { return "Alap"; }
virtual int GetErtek() const { return ertek; }
virtual ~Alap() {}
};
III.4.5. Absztrakt osztályok és interfészek
Mint korábban láttuk, az absztrakt osztályok jó kiinduló pontjául szolgálnak az öröklési láncoknak. C++-ban az absztrakt osztályok jelzésére semmilyen külön kulcsszót nem használunk, egyetlen ismérvük, hogy tartalmaznak-e tisztán virtuális függvényt, vagy sem. Amiért külön részben ismét foglalkozunk velük, az a más nyelvekben követett programozási gyakorlat, ami C++ nyelven is megvalósítható.
A Java, a C# és az Object Pascal programozási nyelvek csak az egyszeres öröklést támogatják, azonban lehetővé teszik tetszőleges számú interfész implementálását. C++ környezetben az interfész olyan absztrakt osztály, amely csak tisztán virtuális függvényeket tartalmaz. Az interfész egyetlen célja, hogy a benne nyilvánosan deklarált tagfüggvények létrehozására kényszerítse a fejlesztőt a származtatás során.
A többszörös öröklés buktatóit elkerülhetjük, ha az alaposztályaink között egy, az adattagokat is tartalmazó, „igazi” osztály, míg a többi interfész osztály. (Az interfész osztályok nevét általában nagy „I” betűvel kezdjük.)
Egy korábbi Pont osztályunk esetén különválasztjuk a geometriai adatok tárolására szolgáló osztályt és a mozgás képességét definiáló interfészt, hisz ez utóbbira nem mindig van szükség.
// a geometriai Pont osztály
class Pont {
protected:
int x, y;
public:
Pont(int a = 0, int b = 0) : x(a), y(b) {}
Pont(const Pont& p) : x(p.x), y(p.y) {}
int GetX() const { return x; }
int GetY() const { return y; }
void SetX(int a) { x = a; }
void SetY(int a) { y = a; }
void Kiir() const { cout<<'('<<x<<','<<y<<')'<< endl; }
};
// absztrakt osztály a mozgatáshoz - interfész
class IMozgat {
public:
virtual void Mozgat(int a, int b) = 0;
virtual void Mozgat(const Pont& p) = 0;
};
// Pont, amely képes mozogni
class MozgoPont : public Pont, public IMozgat {
public:
MozgoPont(int a=0, int b=0) : Pont(a,b) {}
void Mozgat(int a, int b) { x = a; y = b; }
void Mozgat(const Pont& p) {
x = p.GetX();
y = p.GetY();
}
};
int main() {
Pont fixPont(12, 23);
fixPont.Kiir(); // (12, 23)
MozgoPont mozgoPont;
mozgoPont.Kiir(); // (0, 0)
mozgoPont.Mozgat(fixPont);
mozgoPont.Kiir(); // (12, 23)
}
III.4.6. Futás közbeni típusinformációk osztályok esetén
A különböző vizuális fejlesztőrendszerek futás közbeni típusinformációkat (RunTime Type Information, RTTI) tárolnak az objektumpéldányok mellett. Ennek segítségével a futtató rendszerre bízhatjuk az objektumok típusának azonosítását, így nem kell nekünk erre a célra adattagokat bevezetnünk.
Az RTTI mechanizmus helyes működéséhez polimorf alaposztályt kell kialakítanunk, vagyis legalább egy virtuális tagfüggvényt el kell helyeznünk benne, és engedélyeznünk kell az RTTI tárolását. (Az engedélyezési lehetőséget általában a fordító beállításai között találjuk meg.) A mutatók és referenciák típusának azonosítására a dynamic_cast és a typeid műveleteket, míg a megfelelő típus-átalakítás elvégzésére a dynamic_cast operátort használjuk.
A typeid operátor egy const type_info típusú objektummal tér vissza, melynek tagjai információt szolgáltatnak az operandus típusáról. Az objektum name() tagfüggvénye által visszaadott karaktersorozat típusonként különböző tartalma fordítónként eltérő lehet. Az operátor használatához a typeinfo fejállományt kell a programunkba beépíteni.
#include <typeinfo>
#include <iostream>
using namespace std;
class Os {
public:
virtual void Vf(){} // e nélkül nem tárolódik RTTI
void FvOs() {cout<<"Os"<<endl;}
};
class Utod : public Os {
public:
void FvUtod() {cout<<"Utod"<<endl;}
};
int main() {
Utod * pUtod = new Utod;
Os * pOs = pUtod;
// a mutató type_info-ja:
const type_info& tiOs = typeid(pOs);
cout<< tiOs.name() <<endl;
// az Utod type_info-ja
const type_info& tiUtod = typeid(*pOs);
cout<< tiUtod.name() <<endl;
// az Utod-ra mutat?
if (typeid(*pOs) == typeid(Utod))
dynamic_cast<Utod *>(pOs)->FvUtod();
// az Utod-ra mutat?
if (dynamic_cast<Utod*>(pOs))
dynamic_cast<Utod*>(pOs)->FvUtod();
delete pUtod;
}
A következő példaprogramban a futás közbeni típusinformációkra akkor van szükségünk, amikor osztályonként különböző tagokat szeretnénk elérni.
#include <iostream>
#include <string>
#include <typeinfo>
using namespace std;
class Allat {
protected:
int labak;
public:
virtual const string Fajta() = 0;
Allat(int n) {labak=n;}
void Info() {
cout<<"A(z) "<<Fajta()<<"nak "
<<labak<<" laba van."<<endl;
}
};
class Hal : public Allat {
protected:
const string Fajta() {return "hal";}
public:
Hal(int n=0) : Allat(n) {}
void Uszik() {cout<<"uszik"<<endl;}
};
class Madar : public Allat {
protected:
const string Fajta() {return "madar";}
public:
Madar(int n=2) : Allat(n) {}
void Repul() {cout<<"repul"<<endl;}
};
class Emlos : public Allat {
protected:
const string Fajta() {return "emlos";}
public:
Emlos(int n=4) : Allat(n) {}
void Fut() {cout<<"fut"<<endl;}
};
int main() {
const int db=3;
Allat* p[db] = {new Madar, new Hal, new Emlos};
// RTTI nélkül is működő lekérdezés
for (int i=0; i<db; i++)
p[i]->Info();
// RTTI alapú feldolgozás
for (int i=0; i<db; i++)
if (dynamic_cast<Hal*>(p[i])) // Hal?
dynamic_cast<Hal*>(p[i])->Uszik();
else
if (typeid(*p[i])==typeid(Madar)) // Madár?
dynamic_cast<Madar*>(p[i])->Repul();
else
if (typeid(*p[i])==typeid(Emlos)) // Emlős?
dynamic_cast<Emlos*>(p[i])->Fut();
for (int i=0; i<db; i++)
delete p[i];
}
Az összehasonlítás kedvéért szerepeljen itt a fenti feladat futás közbeni típusinformációkat nem alkalmazó változata! Ekkor az Allat osztály Fajta() virtuális tagfüggvényének értékével azonosítjuk az osztályt, a típus-átalakításhoz pedig a static_cast operátort használjuk. Csupán a main() függvény tartalma módosult:
int main() {
const int db=3;
Allat* p[db] = {new Madar, new Hal, new Emlos};
for (int i=0; i<db; i++)
p[i]->Info();
for (int i=0; i<db; i++)
if (p[i]->Fajta()=="hal")
static_cast<Hal*>(p[i])->Uszik();
else
if (p[i]->Fajta()=="madar")
static_cast<Madar*>(p[i])->Repul();
else
if (p[i]->Fajta()=="emlos")
static_cast<Emlos*>(p[i])->Fut();
for (int i=0; i<db; i++)
delete p[i];
}
Mindkét programváltozat futásának eredménye:
A(z) madarnak 2 laba van. A(z) halnak 0 laba van. A(z) emlosnak 4 laba van. repul uszik fut
III.5. Osztálysablonok (class templates)
A legtöbb típusos nyelv megoldásai típusfüggők, vagyis ha elkészítünk egy hasznos függvényt vagy osztályt, az csak a benne rögzített típusú adatokkal működik helyesen. Amennyiben egy másik típussal is szükségünk van a megoldásra, újra meg kell írnunk azt, a típusok lecserélésével.
A C++ nyelv a függvény- és osztálysablonok (templates) bevezetésével megkíméli a fejlesztőket a „típuscserélgetős” programozási módszer alkalmazásától. A programozó egyetlen feladata elkészíteni a szükséges függvényt vagy osztályt, megjelölve a lecserélendő típusokat, és a többi már a C++ fordító dolga.
III.5.1. Osztálysablon lépésről-lépésre
A fejezet bevezetőjeként először lépésről-lépésre áttekintjük a sablonkészítés menetét és a sablonok felhasználását. Eközben azokra az ismeretekre építünk, melyeket az Olvasó elsajátíthatott a könyv korábbi fejezeteinek feldolgozása során.
Példaként tekintsük az egydimenziós, 32-elemű, egész tömbök egyszerűsített, indexhatár ellenőrzése mellett működő IntTomb osztályát!
#include <iostream>
#include <cassert>
#include <cstring>
using namespace std;
class IntTomb {
public:
IntTomb(bool nullaz = true) : meret(32) {
if (nullaz) memset(tar, 0, 32*sizeof(int));
}
int& operator [](int index);
const int meret;
private:
int tar[32];
};
int & IntTomb::operator [](int index) {
if (index<0 || index>=32) assert(0); // indexhiba
return tar[index]; // sikerült
}
Az osztály objektumai a 32 egész elem tárolása mellett az elemek elérésekor ellenőrzik az indexhatárokat. Az egyszerűség kedvéért hibás index esetén a program futása megszakad. A tömb (objektum) létrehozásakor minden elem lenullázódik,
IntTomb a;
kivéve, ha a konstruktort false argumentummal hívjuk.
IntTomb a(false);
A tömb a konstans meret adattagban tárolja az elemek számát, illetve átdefiniálja az indexelés operátorát. Ezek alapján a tömb elemeinek elérése:
int main() {
IntTomb a;
a[ 7] = 12;
a[29] = 23;
for (int i=0; i<a.meret; i++)
cout<<a[i]<<'\t';
}
Mi tegyünk, ha nem 32 elemet szeretnénk tárolni, vagy ha double típusú adatokra van szükségünk? A megoldást az osztálysablon adja, amelyet a fenti IntTomb osztály piros színnel kiemelt int típusainak általánosításával, és az elemszám (32) paraméterként való megadásával készítünk el.
#include <iostream>
#include <cassert>
#include <cstring>
using namespace std;
template <class tipus, int elemszam>
class Tomb {
public:
Tomb(bool nullaz=true): meret(elemszam) {
if (nullaz) memset(tar, 0, elemszam*sizeof(tipus)); }
tipus& operator [](int index);
const int meret;
private:
tipus tar[elemszam];
};
A külső tagfüggvény esetén az osztály nevét az általánosított típussal és a paraméterrel együtt kell szerepeltetni Tomb<tipus, elemszam>:
template <class tipus, int elemszam>
tipus & Tomb<tipus, elemszam>::operator [](int index) {
if (index<0 || index>=elemszam) assert(0); // indexhiba
return tar[index]; // sikerült
}
Felhívjuk a figyelmet, hogy az osztálysablon nem implicit inline tagfüggvényeit minden olyan forrásállományba be kell építenünk, amelyből azokat hívjuk. E nélkül a fordító nem tudja a függvény forráskódját előállítani. Több forrásmodulból álló projekt esetén az osztálysablon elemeit - az osztályon kívül definiált tagfüggvényekkel együtt - ajánlott fejállományba helyezni, melyet aztán minden forrásmodulba beilleszthetünk, anélkül hogy „többszörösen definiált szimbólum” hibajelzést kapnánk.
Az osztálysablon (általánosított osztály) lényege - a már bemutatott függvénysablonokhoz hasonlóan -, hogy a sablon alapján a fordító állítja elő a valóságos, típusfüggő osztályt, annak minden összetevőjével együtt. Az osztálysablont mindig paraméterezve használjuk az objektumok létrehozásakor:
Tomb<int, 32> av, bv(false);
Típus definiálásával
typedef Tomb<int, 32> IntTomb;
egyszerűbbé válik az objektumok előállítása:
IntTomb av, bv(false);
A sablondefinícióban szereplő meret egy konstans paraméter, melynek értékét a fordítás során használja fel a fordító. A sablon feldolgozása során, a paraméter helyén egy konstans értéket, vagy C++ konstanst (const) szerepeltethetünk. Természetesen konstans paraméter nélküli sablonokat is készíthetünk, mint ahogy ezt a fejezet további részeiben tesszük.
Mielőtt tovább mennénk, nézzük meg mit is nyújt számunkra az új osztálysablon! A legegyszerűbb alkalmazását már láttuk, így csak a teljesség kedvéért szerepeltetjük újra:
int main() {
Tomb<int, 32> a;
a[ 7] = 12;
a[29] = 23;
for (int i=0; i<a.meret; i++)
cout<<a[i]<<'\t';
}
Az elkészült sablon numerikus adatok mellett karaktersorozatok és objektumok tárolására is felhasználható.
const int ameret=8;
Tomb<char *, ameret> s1;
s1[2] = (char*)"C++";
s1[4] = (char*)"java";
s1[7] = (char*)"C#";
for (int i=0; i<s1.meret; i++)
if (s1[i]) cout<<s1[i]<<'\t';
Felhívjuk a figyelmet arra, hogy osztálytípusú tömbelemek esetén az általunk alkalmazott nullázási megoldás túl drasztikus, így ezt kerülnünk kell a Tomb osztály konstruktorának false értékkel való hívásával. (Ekkor először lefutnak a tömbelemek konstruktorai, majd pedig a Tomb<string, 8> osztály konstruktora következik, ami alaphelyzetben törli a már inicializált elemobjektumok területét.)
const int ameret=8;
Tomb<string, ameret> s2 (false);
s2[2] = "C++";
s2[4] = "java";
s2[7] = "C#";
for (int i=0; i<s2.meret; i++)
cout<<s2[i]<<'\t';
Természetesen dinamikusan is létrehozhatjuk a tömbobjektumot, ekkor azonban figyelnünk kell az indexelés helyes használatára és a meret adattag elérésre. A tömbobjektumot a (*dt), illetve dt[0] kifejezéssel érjük el, mely után következhet az indexelés operátorának megadása:
Tomb<double, 3> *dt;
dt = new Tomb<double, 3>;
(*dt)[0] =12.23;
dt[0][1]=34.45;
for (int i=0; i<dt->meret; i++)
cout<<(*dt)[i]<<'\t';
delete dt;
Dinamikus helyfoglalással egyszerűen létrehozhatjuk a Tomb<double, 3> típusú tömbobjektumok ötelemű vektorát. A double típusú adatelemek eléréséhez válasszuk a dupla indexelést! Az első index a dinamikus tömbön belül jelöli ki az elemet, míg a második Tomb<double, 3> típusú objektumon belül. Ezzel a megoldással – látszólag – egy kétdimenziós, double típusú tömböt kaptunk.
Tomb<double, 3> *dm;
dm = new Tomb<double, 3> [5];
dm[0][1] =12.23;
dm[4][2]=34.45;
for (int i=0; i<5; i++) {
for (int j=0; j<dm[0].meret; j++)
cout<<dm[i][j]<<'\t';
cout<<endl;
}
delete []dm;
Amennyiben az ötelemű, dinamikus helyfoglalás vektor helyett statikus tömböt készítünk, hasonló megoldáshoz jutunk:
Tomb<int, 3> m[5];
m[0][1] = 12;
m[4][2] = 23;
for (int i=0; i<5; i++) {
for (int j=0; j<m[0].meret; j++)
cout<<m[i][j]<<'\t';
cout<<endl;
}
Végezetül tekintsük az alábbi példányosítást, ahol olyan ötelemű objektumvektort hozunk létre, melynek mindegyik eleme Tomb<int,3> típusú! Az eredmény most is egyfajta, int típusú elemeket tartalmazó, kétdimenziós tömb.
Tomb< Tomb<int,3>, 5> p(false);
p[0][1] = 12;
p[4][2] = 23;
for (int i=0; i<p.meret; i++) {
for (int j=0; j<p[0].meret; j++)
cout<<p[i][j]<<'\t';
cout<<endl;
}
A példákból jól látható, hogy az osztálysablon hatékony programozási eszköz, melynek alkalmazása során azonban – sok esetben – a fordító „fejével” kell gondolkodni, és ismernünk kell a C++ nyelv teljes, objektum-orientált eszköztárának működését és lehetőségeit. Különösen igaz ez a megállapítás, ha osztálysablonok egymásra épülő rendszerét (hierarchiáját) kívánjuk megvalósítani. A következőkben rendszerezett, tematikus formában áttekintjük a sablonkészítés és a használat során felmerülő fogalmakat és technikákat.
Sajnos az elmondottak a C++ nyelv legnehezebb részeinek tekinthetők, mivel a nyelv tejes ismeretét feltételezik. Amennyiben az Olvasó egyelőre nem kíván saját osztálysablonokat fejleszteni, elegendő a fejezetet záró III.5.6. részét áttanulmányoznia, amely a Szabványos sablonkönyvtár használatához nyújt hathatós segítséget.
III.5.2. Általánosított osztály definiálása
A paraméterezett (általánosított) osztály (generic class), lehetővé teszi, hogy más osztályok definiálásához a paraméterezett osztályt, mint mintát használjuk. Ezáltal egy adott osztálydefiníció minden típus esetén alkalmazható.
Nézzük meg az osztálysablonok definiálásának általános formáját, ahol típus1,..típusN a típusparamétereket jelölik! A sablonfejben (template<>)a típusparaméterek kijelölésére a class és typename kulcsszavakat egyaránt használhatjuk:
template <class típus1, … class típusN>
class Osztálynév {
…
};
vagy
template <typename típus1, … typename típusN>
class Osztálynév {
…
};
Az osztály nem inline tagfüggvényeinek definícióját az alábbiak szerint kell megadni:
template <class típ1, … class típN >
fvtípus Osztálynév< típ1, … típN> :: FvNév(paraméterlista) {
…
}
vagy
template <typename típ1, … typename típN >
fvtípus Osztálynév< típ1, … típN> :: FvNév(paraméterlista) {
…
}
Példaként tekintsük a Pont osztályból készített általánosított osztályt, implicit inline tagfüggvényekkel!
template <typename tipus>
class Pont {
protected:
tipus x, y;
public:
Pont(tipus a = 0, tipus b = 0) : x(a), y(b) {}
Pont(const Pont& p) : x(p.x), y(p.y) {}
tipus GetX() const { return x; }
tipus GetY() const { return y; }
void SetX(tipus a) { x = a; }
void SetY(tipus a) { y = a; }
void Kiir() const { cout<<'('<<x<<','<<y<<')'<< endl; }
};
Ugyanez a Pont osztály jóval bonyolultabb formát ölt, ha a tagfüggvényeinek egy részét az osztályon kívül definiáljuk:
template <typename tipus>
class Pont {
protected:
tipus x, y;
public:
Pont(tipus a = 0, tipus b = 0) : x(a), y(b) {}
Pont(const Pont& p) : x(p.x), y(p.y) {}
tipus GetX() const;
tipus GetY() const { return y; }
void SetX(tipus a);
void SetY(tipus a) { y = a; }
void Kiir() const;
};
template <typename tipus>
tipus Pont<tipus>::GetX() const { return x; }
template <typename tipus>
void Pont<tipus>::SetX(tipus a) { x = a; }
template <typename tipus>
void Pont<tipus>::Kiir() const {
cout<<'('<<x<<','<<y<<')'<< endl;
}
A Pont minkét formájában egy általánosított osztály, vagy osztálysablon, amely csupán egy forrás nyelven rendelkezésre álló deklaráció, és amelyen a fordító csak a szintaxist ellenőrzi. A gépi kódra való fordítás akkor megy végbe, amikor a sablont konkrét típusargumentumokkal példányosítjuk, vagyis sablonosztályokat hozunk létre.
III.5.3. Példányosítás és specializáció
Az osztálysablon és a belőle létrehozott egyedi osztályok között hasonló a kapcsolat, mint egy normál osztály és az objektumai között. A normál osztály meghatározza, miként lehet objektumok csoportját létrehozni, míg a sablonosztály az egyedi osztályok csoportjának generálásához ad információkat.
A sablonokat különböző módon használhatjuk. Az implicit példányosítás során (instantiation) a típusparamétereket konkrét típusokkal helyettesítjük. Ekkor először létrejön az osztály adott típusú változata (ha még nem létezett), majd pedig az objektumpéldány:
Pont<double> p1(1.2, 2.3), p2(p1); Pont<int> *pp; // a Pont<int> osztály nem jön létre
Explicit példányosítás során arra kérjük a fordítót, hogy hozza létre az osztály példányát a megadott típusok felhasználásával, így az objektum készítésekor már kész osztállyal dolgozhatunk:
template class Pont<double>; … Pont<double> p1(1.2, 2.3), p2(p1);
Vannak esetek, amikor a sablon felhasználását megkönnyíti, ha az általános változatot valamilyen szempont szerint specializáljuk (explicit specialization). Az alábbi deklarációk közül az első az általános sablont, a második a mutatókhoz készített változatot, a harmadik pedig a void* mutatókra specializált változatot tartalmazza.
template <class tipus> class Pont {
// a fenti osztálysablon
};
template <class tipus> class Pont <tipus *> {
// el kell készíteni!
};
template <> class Pont <void *> {
// el kell készíteni!
};
A specializált változatokat az alábbi példányosítások során használhatjuk:
Pont<double> pa; Pont<int *> pp; Pont<void *> pv;
Vizsgáljuk meg a példányosítás és a specializáció működését kétparaméteres sablonok esetén! Ekkor az egyik sablonparaméter elhagyásával részleges specializációt is készíthetünk:
template <typename T1, typename T2>
class Adatfolyam {
public:
Adatfolyam() { cout << "Adatfolyam<T1,T2>"<<endl;}
// …
};
template < typename T1, typename T2> // Specializáció
class Adatfolyam<T1*, T2*> {
public:
Adatfolyam() { cout << "Adatfolyam<T1*,T2*>"<<endl;}
// …
};
template < typename T1> // Részleges specializáció
class Adatfolyam<T1, int> {
public:
Adatfolyam() { cout << "Adatfolyam<T1, int>"<<endl;}
// …
};
template <> // Teljes specializáció
class Adatfolyam<char, int> {
public:
Adatfolyam() { cout << "Adatfolyam<char, int>"<<endl;}
// …
} ;
int main() {
Adatfolyam<char, int> s4 ; // Teljes specializáció
Adatfolyam<int, double> s1 ;
Adatfolyam<double*, int*> s2; // Specializáció
Adatfolyam<double, int> s3 ; // Részleges specializáció
}
III.5.4. Érték- és alapértelmezett sablonparaméterek
A fejezet bevezető példájában az osztálysablont a típus paraméter mellett egy egész típusú értékparaméterrel is elláttuk. Ennek segítségével egy konstans értéket adtunk át a fordítónak a példányosítás során.
A C++ támogatja az alapértelmezett sablonparaméterek használatát. Lássuk el a Tomb osztálysablon paramétereit alapértelmezés szerinti értékekkel!
#include <iostream>
#include <cassert>
#include <cstring>
using namespace std;
template <typename tipus=int, int elemszam=32>
class Tomb {
public:
Tomb(bool nullaz=true): meret(elemszam) {
if (nullaz) memset(tar, 0, elemszam*sizeof(tipus)); }
tipus& operator [](int index) {
if (index<0 || index>=elemszam) assert(0);
return tar[index];
}
const int meret;
private:
tipus tar[elemszam];
};
Ebben az esetben az IntTomb típus létrehozásához argumentumok nélkül is specializálhatjuk az általánosított osztályunkat:
typedef Tomb<> IntTomb;
Az alábbi egyszerű példa bemutatja a verem (Stack) adatstruktúra osztálysablonként történő megvalósítását. A veremsablon paramétereit szintén alapértelmezett értékekkel láttuk el.
#include <iostream>
#include <string>
using namespace std;
template<typename Tipus=int, int MaxMeret=100>
class Stack {
Tipus tomb[MaxMeret];
int sp;
public:
Stack(void) { sp = 0; };
void Push(Tipus adat) {
if (sp < MaxMeret) tomb[sp++] = adat;
}
Tipus Pop(void) {
return tomb[sp > 0 ? --sp : sp];
}
bool Ures(void) const { return sp == 0; };
};
int main(void) {
Stack<double,1000> dVerem; // 1000 elemű double verem
Stack<string> sVerem; // 100 elemű string verem
Stack<> iVerem; // 100 elemű int verem
int a=102, b=729;
iVerem.Push(a);
iVerem.Push(b);
a=iVerem.Pop();
b=iVerem.Pop();
sVerem.Push("nyelv");
sVerem.Push("C++");
do {
cout << sVerem.Pop()<<endl;;
} while (!sVerem.Ures());
}
III.5.5. Az osztálysablon „barátai” és statikus adattagjai
Az osztálysablonnak is lehetnek barátai, melyek többféleképpen viselkedhetnek. Azok, amelyek nem tartalmaznak sablonelőírást, minden specializált osztály közös „barátai” lesznek. Ellenkező esetben a külső függvény csak az adott példányosított osztályváltozat friend függvényeként használható.
Az első példában a BOsztaly osztálysablon minden példányosítása barátosztálya lesz az AOsztaly-nak:
#include <iostream>
using namespace std;
class AOsztaly {
void Muvelet() { cout << "A muvelet elvegezve."<< endl; };
template<typename T> friend class BOsztaly;
};
template<class T> class BOsztaly {
public:
void Vegrehajt(AOsztaly& a) { a.Muvelet(); }
};
int main() {
BOsztaly<int> b;
BOsztaly<double> c;
AOsztaly a;
b.Vegrehajt(a);
c.Vegrehajt(a);
}
A második példánkban a definiált barátfüggvény (Fv) maga is sablon:
#include <iostream>
using namespace std;
// Előrevetett deklarációk
template <typename T> class Osztaly;
template <typename T> void Fv(Osztaly<T>&);
template <typename T> class Osztaly {
friend void Fv<T>(Osztaly<T>&);
public:
T GetAdat(){return adat;}
void SetAdat(T a){adat=a;}
private:
T adat;
};
template<typename T> void Fv(Osztaly<T>& x) {
cout<<"Eredmeny: "<<x.GetAdat()<<endl;
}
int main() {
Osztaly<int> obj1;
obj1.SetAdat(7);
Fv(obj1);
Osztaly<double> obj2;
obj2.SetAdat(7.29);
Fv(obj2);
}
Az általánosított osztályban definiált statikus adattagokat sablonosztályonként kell létrehoznunk:
#include <iostream>
using namespace std;
template<typename tipus> class Osztaly {
public:
static int ID;
static tipus adat;
Osztaly() { ID = adat = 0; }
};
// A statikus adattagok definíciói
template <typename tipus> int Osztaly<tipus>::ID = 23;
template <typename tipus> tipus Osztaly<tipus>::adat = 12.34;
int main() {
Osztaly <double> dObj1, dObj2;
cout << dObj1.ID++ << endl; // 23
cout << dObj1.adat-- << endl; // 12.34
cout << dObj2.ID << endl; // 24
cout << dObj2.adat << endl; // 11.34
cout <<Osztaly<double>::ID << endl; // 24
cout <<Osztaly<double>::adat << endl; // 11.34
}
III.5.6. A C++ nyelv szabványos sablonkönyvtára (STL)
A Standard Template Library (Szabványos Sablonkönyvtár - röviden STL) szoftverkönyvtár a C++ nyelv Szabványos Könyvtárának szerves részét képezi. Az STL konténerek (tárolók), algoritmusok és iterátorok gyűjteménye, valamint számos alapvető informatikai algoritmust és adatszerkezetet tartalmaz. Az STL elemei paraméterezhető osztályok és függvények, melyek használatához ajánlott megérteni a C++ nyelv sablonkezelésének alapjait.
Az alábbi áttekintés nem helyettesíti egy teljes STL leírás áttanulmányozást, azonban ahhoz elegendő információt tartalmaz, hogy az Olvasó bátran használja a programjaiban a könyvtár alapvető elemeit.
III.5.6.1. Az STL felépítése
A könyvtár elemei öt csoportba sorolhatók:
tárolók, konténerek (containers) – az adatok memóriában való tárolását biztosító adatstruktúrák (vector, list, map, set, deque, …)
adaptációk (adaptors) – a tárolókra épülő magasabb szintű adatstruktúrák (stack, queue, priority_queue)
algoritmusok (algorithm) - a konténerekben tárolt adatokon elvégezhető műveletek (sort, copy, search, min, max, …)
iterátorok (iterators) – általánosított mutatók, amely biztosítják a tárolók adatainak különböző módon történő elérését (iterator, const_iterator, ostream_iterator<>, … )
műveletobjektumok (function objects) – a műveleteket osztályok fedik le, más komponensek számára (divides, greater_equal, logical_and, …).
Az sablonkezelésnek megfelelően az egyes lehetőségek fejállományok beépítésével érhetők el. Az alábbi táblázatban összefoglaltuk az STL leggyakrabban használt deklarációs fájljait:
|
Rövid leírás |
Fejállomány |
|---|---|
|
Adatsorok kezelése, rendezése, keresés stb. |
<algorithm> |
|
Asszociatív tároló: bithalmaz |
<bitset> |
|
Asszociatív tároló: halmazok (elemismétlődéssel – multiset, illetve ismétlődés nélkül - set) |
<set> |
|
Asszociatív tároló: kulcs/érték adatpárok tárolása 1:1 (map), illetve 1:n (multiset) kapcsolatban (leképzések) |
<map> |
|
Előre definiált iterátorok, adatfolyam iterátorok |
<iterator> |
|
Tároló: dinamikus tömb |
<vector> |
|
Tároló: kettősvégű sor |
<deque> |
|
Tároló: lineáris lista |
<list> |
|
Tároló adaptáció: sor |
<queue> |
|
Tároló adaptáció: verem |
<stack> |
III.5.6.2. Az STL és C++ tömbök
Az STL algoritmusai valamint az adatfolyam iterátorai egydimenziós C++ tömbök esetén is használhatók. Ezt az teszi lehetővé, hogy a C++ mutatókhoz és az iterátorokhoz ugyanazokat a műveleteket használhatjuk: a mutatott adat (*), léptetés (++) stb. Továbbá, az algoritmus függvénysablonok többsége az adatsor kezdetét (begin) és az utolsó adat utáni pozícióját (end) kijelölő általánosított mutatókat vár argumentumként.
Az alábbi példában egy hételemű egész tömb elemein különböző műveleteket hajtunk végre az STL algoritmusainak segítségével. A bemutatottak alapján a több mint 60 algoritmus többségét eredményesen használhatjuk a hagyományos C++ programjainkban is.
#include <iostream>
#include <iterator>
#include <algorithm>
using namespace std;
void Kiir(const int x[], int n) {
static ostream_iterator<int> out(cout,"\t");
cout<< "\t";
copy(x, x+n, out);
cout<<endl;
}
void IntKiir(int a) {
cout << "\t" << a << endl;
}
int main() {
const int db = 7;
int adat[db]={2, 7, 10, 12, 23, 29, 80};
cout << "Eredeti tömb: " << endl;
Kiir(adat, db);
cout << "Következő permutació: " << endl;
next_permutation(adat,adat+db);
Kiir(adat, db);
cout << "Sorrend megfordítása: " << endl;
reverse(adat,adat+db);
Kiir(adat, db);
cout << "Véletlen keverés: " << endl;
for (int i=0; i<db; i++) {
random_shuffle(adat,adat+db);
Kiir(adat, db);
}
cout << "A legnagyobb elem: ";
cout << *max_element(adat,adat+db) << endl;
cout << "Elem keresése:";
int *p=find(adat,adat+db, 7);
if (p != adat+db)
cout << "\ttalált" <<endl;
else
cout << "\tnem talált" <<endl;
cout << "Rendezés: " << endl;
sort(adat,adat+db);
Kiir(adat, db);
cout << "Elemek kiírása egymás alá:"<< endl;
for_each(adat, adat+db, IntKiir);
Kiir(adat, db);
cout << "Csere: " << endl;
swap(adat[2],adat[4]);
Kiir(adat, db);
cout << "Feltöltés: " << endl;
fill(adat,adat+db, 123);
Kiir(adat, db);
}
Ugyancsak beszédes a program futásának eredménye:
Eredeti tömb:
2 7 10 12 23 29 80
Következő permutáció:
2 7 10 12 23 80 29
Sorrend megfordítása:
29 80 23 12 10 7 2
Véletlen keverés:
10 80 2 23 29 7 12
2 10 23 80 29 12 7
7 12 2 10 80 29 23
2 12 29 10 80 7 23
12 23 7 29 10 2 80
7 23 12 2 80 10 29
7 12 23 2 29 10 80
A legnagyobb elem: 80
Elem keresése: talált
Rendezés:
2 7 10 12 23 29 80
Elemek kiírása egymás alá:
2
7
10
12
23
29
80
2 7 10 12 23 29 80
Csere:
2 7 23 12 10 29 80
Feltöltes:
123 123 123 123 123 123 123
|
III.5.6.3. Az STL tárolók használata
A konténereket két fő csoportba sorolhatjuk: adatsorok (soros) és asszociatív tárolók. A soros tárolókra (vektor - vector, lista - list, kettősvégű sor - deque) jellemző, hogy elemek sorrendjét a programozó határozza meg. Az asszociatív tárolók (leképzés - map, halmaz – set, bithalmaz - bitset stb.) közös tulajdonsága, hogy az elemek sorrendét maga a konténer szabja meg, valamint az elemek egy kulcs alapján érhetők el. Mindegyik tároló dinamikusan kezeli a memóriát, tehát az adatok száma szabadon változtatható.
A tároló objektumok tagfüggvényei segítik az adatok kezelését és elérését. Mivel ez a függvénykészlet függ a konténer típusától, felhasználás előtt mindenképpen a szakirodalomban (Interneten) kell megnézni, hogy egy adott taroló esetén mik a lehetőségeink. Most csak néhány általános művelet áttekintésére vállalkozunk:
Elemet szúrhatunk be (insert()) vagy törölhetünk (erase()) egy iterátorral kijelölt pozcíóba/ból.
Elemet adhatunk (push) a soros tárolók elejére (front) vagy végére (back), illetve levehetünk (pop) egy elemet: push_back(), pop_front() stb.
Bizonyos konténereket indexelhetjük is a tömböknél használt módon ([]).
A begin() és az end() függvények az algoritmusoknál felhasználható iterátorokat adnak vissza, amelyek segítik az adatstruktúrák bejárását.
A következőkben egy vector tárolót használó programmal szemléltetjük az elmondottakat:
#include <vector>
#include <algorithm>
#include <iterator>
#include <iostream>
using namespace std;
double Osszeg(const vector<double>& dv) {
vector<double>::const_iterator p; // konstans iterátor
double s = 0;
for (p = dv.begin(); p != dv.end(); p++)
s += *p;
return s;
}
bool Paratlan (int n) {
return (n % 2) == 1;
}
int main() {
// kimeneti iterátor
ostream_iterator<double>out(cout, " ");
double adatok[] = {1.2, 2.3, 3.4, 4.5, 5.6};
// A vektor létrehozása az adatok tömb elemivel
vector<double> v(adatok, adatok+5);
// A vektor kiírása
copy(v.begin(), v.end(), out); cout << endl;
cout<<"Elemösszeg: "<<Osszeg(v)<<endl;
// A vektor bővítése elemekkel
for (int i=1; i<=5; i++)
v.push_back(i-i/10.0);
copy(v.begin(), v.end(), out); cout << endl;
// Minden elem növelése 4.5 értékkel
for (int i=0; i<v.size(); i++)
v[i] += 4.5;
copy(v.begin(), v.end(), out); cout << endl;
// Minden elem egésszé alakítása
vector<double>::iterator p;
for (p=v.begin(); p!=v.end(); p++)
*p = int(*p);
copy(v.begin(), v.end(), out); cout << endl;
// Minden második elem törlése
int index = v.size()-1;
for (p=v.end(); p!=v.begin(); p--)
if (index-- % 2 ==0)
v.erase(p);
copy(v.begin(), v.end(), out); cout << endl;
// A vektor elemeinek rendezése
sort(v.begin(), v.end() );
copy(v.begin(), v.end(), out); cout << endl;
// 7 keresése a vektorban
p = find(v.begin(), v.end(), 7);
if (p != v.end() )
cout << "talált"<< endl;
else
cout << "nem talált"<< endl;
// A páratlan elemek száma
cout<< count_if(v.begin(), v.end(), Paratlan)<< endl;
}
A program futásának eredménye:
1.2 2.3 3.4 4.5 5.6 Elemösszeg: 17 1.2 2.3 3.4 4.5 5.6 0.9 1.8 2.7 3.6 4.5 5.7 6.8 7.9 9 10.1 5.4 6.3 7.2 8.1 9 5 6 7 9 10 5 6 7 8 9 5 7 10 6 8 5 6 7 8 10 talált 2 |
III.5.6.4. Az STL tároló adaptációk alkalmazása
A konténer-adaptációk olyan tárolók, amelyek módosítják a fenti tároló osztályokat az alapműködéstől eltérő viselkedés biztosítása érdekében. A támogatott adaptációk a verem (stack), a sor (queue) és a prioritásos sor (priority_queue).
Az adaptációk viszonylag kevés tagfüggvénnyel rendelkeznek, és mögöttük különböző tárolók állhatnak. Példaként tekintsük a stack osztálysablont!
A „last-in, first-out” működésű verem egyaránt adaptálható a vector, a list és a deque tárolókból. Az adaptált stack-függvényeket táblázatban foglaltuk össze:
|
|
a bevitele a verembe, |
|
|
a verem felső elemének levétele, |
|
|
a verem felső elemének elérése, |
|
|
a verem felső elemének lekérdezése, |
|
|
true érték jelzi, ha a verem üres, |
|
|
a veremben lévő elemek száma, |
|
|
az egyenlőség és a kisebb művelet. |
Az alábbi példaprogramban adott számrendszerbe való átváltásra használjuk a vermet:
#include <iostream>
#include <stack>
#include <vector>
using namespace std;
int main() {
int szam=2013, alap=16;
stack<int, vector<int> > iverem;
do {
iverem.push(szam % alap);
szam /= alap;
} while (szam>0);
while (!iverem.empty()) {
szam = iverem.top();
iverem.pop();
cout<<(szam<10 ? char(szam+'0'): char(szam+'A'-10));
}
}
IV. fejezet - A Microsoft Windows programozása C++ nyelven
- IV.1. A CLI specialitásai, a szabványos C++ és a C++/CLI
- IV.1.1. A nativ kód fordítási és futtatási folyamata Windows alatt
- IV.1.2. Problémák a natív kódú programok fejlesztése és használata során.
- IV.1.3. Platformfüggetlenség
- IV.1.4. Az MSIL kód futtatása
- IV.1.5. Integrált fejlesztő környezet
- IV.1.6. A vezérlők, vizuális programozás
- IV.1.7. A .NET keretrendszer
- IV.1.8. C#
- IV.1.9. A C++ bővitése a CLI-hez
- IV.1.10. A C++/CLI bővitett adattípusai
- IV.1.11. Az előredefiniált referencia osztály: String
- IV.1.12. A System::Convert statikus osztály
- IV.1.13. A CLI array template-tel megvalósitott tömb referencia osztálya
- IV.1.14. C++/CLI: Gyakorlati megvalósitás pl. a Visual Studio 2008-as változatban
- IV.1.15. Az Intellisense beépitett segítség
- IV.1.16. A CLR-es program típusának beállitása.
- IV.2. Az ablakmodell és az alapvezérlők.
- IV.2.1. A Form alapvezérlő
- IV.2.2. A Form vezérlő gyakran használt tulajdonságai
- IV.2.3. A Form vezérlő eseményei
- IV.2.4. A vezérlők állapotának aktualizálása
- IV.2.5. Alapvezérlők: Label (címke) vezérlő
- IV.2.6. Alapvezérlők: TextBox (szövegmező) vezérlő
- IV.2.7. Alapvezérlők: a Button (nyomógomb) vezérlő
- IV.2.8. Logikai értékekhez használható vezérlők: a CheckBox (jelölő négyzet)
- IV.2.9. Logikai értékekhez használható vezérlők: a RadioButton (opciós gomb)
- IV.2.10. Konténerobjektum vezérlő: a GroupBox (csoport mező)
- IV.2.11. Diszkrét értékeket bevivő vezérlők: a HscrollBar (vízszintes csúszka) és a VscrollBar (függőleges csúszka)
- IV.2.12. Egész szám beviteli vezérlője: NumericUpDown
- IV.2.13. Több objektumból választásra képes vezérlők: ListBox és a ComboBox
- IV.2.14. Feldolgozás állapotát mutató vezérlő: ProgressBar
- IV.2.15. Pixelgrafikus képeket megjeleníteni képes vezérlő: a PictureBox (képmező)
- IV.2.16. Az ablakunk felső részén lévő menüsor: a MenuStrip (menüsor) vezérlő
- IV.2.17. Az alaphelyzetben nem látható ContextMenuStrip vezérlő
- IV.2.18. Az eszközkészlet menüsora: a ToolStrip vezérlő
- IV.2.19. Az ablak alsó sorában megjelenő állapotsor, a StatusStrip vezérlő
- IV.2.20. A fileok használatában segítő dialógusablakok: OpenFileDialog, SaveFileDialog és FolderBrowserDialog
- IV.2.21. Az előre definiált üzenetablak: MessageBox
- IV.2.22. Az időzítésre használt vezérlő: Timer
- IV.2.23. A SerialPort
- IV.3. Szöveges, bináris állományok, adatfolyamok.
- IV.3.1. Előkészületek a fájlkezeléshez
- IV.3.2. A statikus File osztály metódusai
- IV.3.3. A FileStream referencia osztály
- IV.3.4. A BinaryReader referencia osztály
- IV.3.5. A BinaryWriter referencia osztály
- IV.3.6. Szövegfájlok kezelése: StreamReader és StreamWriter referencia osztályok
- IV.3.7. A MemoryStream referencia osztály
- IV.4. A GDI+
- IV.4.1. A GDI+használata
- IV.4.2. A GDI rajzolási lehetőségei
- IV.4.3. A Graphics osztály
- IV.4.4. Koordináta-rendszerek
- IV.4.5. Koordináta-transzformáció
- IV.4.6. A GDI+ színkezelése (Color)
- IV.4.7. Geometriai adatok (Point, Size, Rectangle, GraphicsPath)
- IV.4.8. Régiók
- IV.4.9. Képek kezelése (Image, Bitmap, MetaFile, Icon)
- IV.4.10. Ecsetek
- IV.4.11. Tollak
- IV.4.12. Font, FontFamily
- IV.4.13. Rajzrutinok
- IV.4.14. Nyomtatás
- Irodalmak:
Ebben a fejezetben a C++ nyelv Windows-specifikus alkalmazását mutatjuk be.
IV.1. A CLI specialitásai, a szabványos C++ és a C++/CLI
A Windows operációs rendszert futtató számítógépre többféle módon fejleszthetünk alkalmazásokat:
Valamely fejlesztő környezet segítségével elkészítjük az alkalmazást, ami ebben a futtató környezetben fog működni. Az operációs rendszer által a file közvetlenül nem futtatható (pl. MatLab, LabView), mert nem a számítógép CPU-ja, hanem a futtató környezet számára tartalmaz parancsokat. Néha a fejlesztő környezet mellett tiszta futtató (run-time) környezet is rendelkezésre áll a kész alkalmazás használatához, vagy a fejlesztő készít a programunkból egy futtatható (exe) állományt, amelybe beleteszi a futtatáshoz szükséges run-time-ot is.
A fejlesztő környezet elkészít a forrásfilejainkból egy önállóan futtatható alkalmazás fájlt (exe), amely az adott operációs rendszeren és processzoron futtatható gépi kódú utasításokat tartalmazza (natív kód). A fejlesztés közbeni kipróbálás során is ezt a fájlt futtatjuk. Ilyen eszközök pl. a Borland Delphi és az iparban jellemzően használt Microsoft Visual Studio.
Mindkét fejlesztési mód jellemzője, hogy amennyiben grafikus felhasználói felülete lesz az alkalmazásunknak, a felhasznált elemeket grafikus editorral hozzuk létre, fejlesztés közben látható az elem működés közbeni állapota. Ezt az elvet RAD-nak (gyors alkalmazásfejlesztés) nevezzük. A C++ nyelven való fejlesztés a 2. csoportba tartozik, míg a C++/CLI-ben mindkét alkalmazásfejlesztési módszer megjelenik.
IV.1.1. A nativ kód fordítási és futtatási folyamata Windows alatt
Amennyiben Windows alatt úgynevezett konzolalkalmazást készítünk, a szabványos C++-nak megfelelő szintaktikát alkalmaz a Visual Studio. Így fordíthatóak le Unix, Mac vagy más rendszerre készített programok, programrészletek (pl. a WinSock a sockets programcsomagból, vagy a MySql adatbáziskezelő). Ekkor a következő a fordítás folyamata
A C++ forrás(ok)
.cppkiterjesztésű fájlokban, headerek.hkiterjesztésű állományokban tároltak. Ezekből több is lehet, ha a logikailag összetartozó részeket külön helyeztük el, vagy ha a programot többen fejlesztették.Előfeldolgozó (preprocesszor): #define definíciók feloldása, #include állományok beszúrása a forrásba
Előfeldolgozott C forrás: minden szükséges függvénydefiníciót tartalmaz.
C fordító: előfeldolgozott forrásokból relokálható
.OBJtárgymodult készít.OBJ fájlok: gépi kódú programrészleteket (ezek nevét publikussá téve – export) és külső (external) hivatkozásokat tartalmaznak más fájlokban lévő részletekre.
Linker: az OBJ fájlokból és az előre lefordított függvényeket (pl. printf()) tartalmazó
.LIBkiterjesztésű állományokból a hivatkozások feloldása, és a felesleges függvények kitakarítása, valamint a belépési pont (main() függvény) megadása után elkészül a futtatható.EXEkiterjesztésű fájl, ami az adott processzoron futtatható gépi kódú utasításokat tartalmazza.
IV.1.2. Problémák a natív kódú programok fejlesztése és használata során.
Mint azt az előző fejezetekben láttuk, a natív kódú programokban a programozó igény szerint használhat dinamikus memóriafoglalást az adatoknak/objektumoknak. Ezeknek a változóknak csak címük van, névvel nem hivatkozhatunk rájuk, csak pointerrel, a címüket a pointerbe töltve. Például, ilyen memóriafoglalás a malloc() függvény és a new operátor kimenete, amely lefoglal egy egybefüggő területet, és visszaadja annak címét, amit valamilyen pointerbe teszünk be értékadó utasítással. Ezután a változót (a pointeren keresztül) használhatjuk, sőt a területet fel is szabadíthatjuk. A pointer hatékony, de veszélyes eszköz: értéke pointeraritmetikával megváltoztatható, úgy, hogy már nem az általunk lefoglalt memóriaterületre mutat, hanem azon túl. Tipikus példa kezdők esetén a tömböknél fordul elő: készítenek egy 5 elemű tömböt (a definícióban 5 szerepel), majd hivatkoznak az 5 indexű elemre, amely jó esetben valahol a programjuk memóriaterületén található, csak nem a tömbben (az elemek indexei 0..4-ig értelmezhetőek). Értékadó utasítás használata esetén az adott érték szinte vakon bekerül a tömb mellé a memóriába, az ott lévő, másik változót „véletlenül” megváltoztatva. Ez a hiba lehet, hogy rejtve is marad előttünk, mert a másik változó értékének megváltozása fel sem tűnik, csak a „program néha furcsa eredményeket ad”. Könnyebb a hibát észrevenni, ha a pointer már nem a saját memóriaterületünkre mutat, hanem pl. az operációs rendszerére. Ekkor ugyanis hibaüzenet keletkezik, és az operációs rendszer a programunkat „kidobja” a memóriából.
Ha nagyon odafigyelünk a pointereinkre, a véletlenszerű megváltoztatást elkerüljük. Nem kerülhetjük el viszont a memória fragmentálódását. Ugyanis, amennyiben nem pontosan fordított sorrendben szabadítjuk fel a memóriablokkokat a foglaláshoz képest, a memóriában „lyukak” keletkeznek – két foglalt blokk közt egy szabad blokk. Többfeladatos operációs rendszer esetén a többi program is használja a memóriát, így pontosan fordított sorrendű felszabadítás esetén is keletkeznek lyukak. A foglalásnak mindig egybefüggőnek kell lennie, így ha nagyobb terület kell a felhasználónak, mint a szabad blokk, azt nem tudja lefoglalni, ott marad felhasználatlanul a kisméretű memóriablokk. Vagyis a memória „töredezik”. A jelenség ugyanaz, mint a háttértárolók töredezettsége az állományok törlése, felülírása után. A háttértárolóhoz van segédprogram, amely az állományokat egybefüggő területen helyezi el, viszonylag hosszú idő alatt, a natív kódú programok memóriájához nincs töredezettségmentesítő. Ugyanis nem tudhatja az operációs rendszer, hogy melyik memóriablokkunk címét melyik pointerünk tartalmazza, a blokk mozgatása esetén a pointerbe a blokk új címét kellene betöltenie.
Vagyis két igény fogalmazódik meg a memóriával kapcsolatban: egyik a változók véletlenszerű megváltozásának, illetve az operációs rendszer által leállított programok elkerülése (mindenki látott már kék képernyőt) a program változóinak menedzselésével, valamint a takarítás, rendrakás, szemétgyűjtés (garbage collection). Az alábbi, MSDN-ről származó ábra a garbage collection működését mutatja be, takarítás előtt (IV.1. ábra - Memória takarítás előtt) és takarítás (GC::Collect()) után (IV.2. ábra - Memória takarítás után)
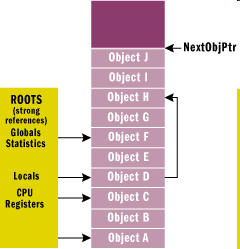
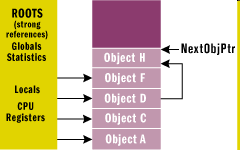
Látható, hogy azok a memóriaterületek (objektumok), amelyekre nem hivatkozik semmi, eltűntek, a hivatkozások az új címekre mutatnak, a szabad terület helyét kijelölő pointer alacsonyabb címre került (vagyis nagyobb lett a szabad egybefüggő memória).
IV.1.3. Platformfüggetlenség
A számítógépek egy része mára kiköltözött a kezdeti fémdobozból, mindenhova magunkkal visszük a zsebünkben, esetleg ruharabként vagy kiegészítőként viseljük. Ezeknél a számítógépeknél (nem is így hívjuk már őket: telefon, e-könyv olvasó, tablet, médialejátszó, szemüveg, autó) a viszonylag kisebb számítási teljesítmény mellett a fogyasztás minimalizálására törekednek a gyártók, ugyanis nem áll rendelkezésre a működtetéshez néhány 100 W-os teljesítmény. Az Intel (és másodgyártói) processzorok inkább a számítási teljesítményre összpontosítottak, így a mobil, telepes táplálású eszközökbe a többi gyártó (ARM, MIPS, stb) CPU-jai kerültek. A programfejlesztők dolga elbonyolódott: minden egyes CPU-ra (és platformra) el kellett (volna) készíteni az alkalmazást. Célszerűnek látszott egy futtató környezetet kialakítani platformonként, majd az alkalmazásokat csak egyszer elkészíteni, és lefordítani valamely köztes kódra, a szellemi termék védelme érdekében. Ezt jól ismerte fel a Sun Microsystems, amikor a C és C++ nyelvekből megalkotta az egyszerű objektummodellel rendelkező, pointermentes Java nyelvet. A Java nyelvről úgynevezett bájtkódra fordítják az alkalmazást, amelyet egy virtuális gépen (Java VM) futtatnak, azonban natív kóddá is alakítható, és futtatható. Manapság több ismert platform is használja a közben Oracle tulajdonba került nyelvet: pl. ilyen a Google által felkarolt Android operációs rendszer. Természetesen ahol védjegy, ott pereskedés is van: az Oracle nem engedélyezte a Java név használatát, mert „tudatosan megsértették a szellemi jogait.” Hasonlóan járt a Microsoft is a Windows-ba épített Java-val: a mai Windows-ban nincs Java támogatás, a JRE-t (a futtató környezet) vagy a JDK-t (a fejlesztő környezet) az Oracle oldaláról kell letölteni. A PC-s világban enélkül is fennáll még néhány évig egy átmeneti állapot: a 32-bites operációs rendszer 4 GB memóriát már nem tud kezelni. Az AMD kifejlesztette a 64-bites utasításkészlet bővítést, amit később az Intel is átvett. A Windows az XP óta két memóriakezeléssel kapható: 32-bites a régebbi, 4 GB alatti memóriájú PC-khez, és a 64-bites az újabb CPU-jú, 4 GB-ot vagy többet tartalmazó PC-khez. A 64-bites változat egy emuláció segítségével (WoW64 – Windows on Windows) futtatja a régebbi, 32-bites alkalmazásokat. Amikor egy programot lefordítunk 64-bites operációs rendszer alatt a Visual Studio 2005 vagy újabb (2008, 2010, 2013) változattal, kiválaszthatjuk az „x64” üzemmódot is, ekkor 64-bites alkalmazást kapunk. Adódott tehát az igény, hogy egy program fusson mindkét konfigurációjú (x86, x64) és az összes változatú (XP,Vista, 7,8) Windows operációs rendszeren is úgy, hogy a fordítás pillanatában még nem tudjuk, hogy milyen környezet lesz később, de nem szeretnénk több exe fájlt készíteni. Ez a követelmény, mint ahogy láttuk, csak egy közbenső futtató/fordító szint közbeiktatásával lehetséges. Szükséges lehet még nagyobb programok esetén, hogy többen is részt vegyenek a fejlesztésben, esetleg különböző programozási nyelvek ismeretével. A közbenső szint esetén erre is lehetőség van: minden nyelvi fordító (C++, C#, Basic, F# stb.) erre a közbenső (intermediate) nyelvre fordít, majd az alkalmazás erről fordul le futtathatóra. A közbenső nyelvet elnevezték MSIL-nek, amely egy gépi kódra hasonlító, veremorientált nyelv. Az MSIL elnevezést, amelynek első két betűje a gyártó cég nevét jelenti, később CIL-re változtatták, vagyis „Common Intermediate Language”, amelyet úgy is tekinthetjük, mint a Microsoft megoldását a Java alapötletére.
IV.1.4. Az MSIL kód futtatása
Az előző bekezdésben ismertetett CIL kód egy .EXE kiterjesztésű fájlba kerül, ahonnan futtatható. Azonban ez a kód nem a processzor natív kódja, így az operációs rendszernek fel kell ismernie, hogy még egy lépésre van szükség. Ez a lépés kétféle lehet, a Java rendszerben használt elveknek megfelelően:
az utasításokat egyenként értelmezve és lefuttatva. A módszert JIT (Just In Time) futtatásnak nevezzük. A forrásszöveg lépésenkénti futtatásánál és töréspontokat tartalmazó hibakeresésénél (debug) célszerű a használata.
az összes utasításból egyszerre natív kódot generálva és elindítva. A módszer neve AOT (Ahead of Time), és a Native Image Generator (NGEN) képes elkészíteni. Jól működő, letesztelt, kész programoknál (release) használjuk.
IV.1.5. Integrált fejlesztő környezet
Az eddig tárgyalt natív kód fejlesztési folyamatában még nem esett szó a felhasznált programeszközökről. Kezdetben minden lépést 1 vagy több (parancssoros) program látott el: a fejlesztő tetszőleges szövegszerkesztővel létrehozta/bővítette/javította a .C és .H forrásfájlokat, majd az előfeldolgozó és a C fordító, végül linkelő következett. Ha hibakereső (debug) módban futtatta az alkalmazást, ez egy újabb programot (a debugger-t) jelentette. Amennyiben a program több forrásfájlból állt, azok közül csak a módosítottakat kell újrafordítani. Ezt a célt szolgálta a make segédprogram. Ha a források közt keresni kellett (pl. melyik .H fileban található egy általunk készített függvény definíciója), akkor a grep segédprogramot használhattuk. A fordításhoz gyakran készültek batch fájlok is, amelyek a fordítót megfelelően felparaméterezték. Fordítási hiba esetén kiíródott a konzolra a hibás sor száma, a szövegszerkesztőt újra betöltöttük, odanavigáltunk a hibás sorra, kijavítottuk a hibás sort, majd újra fordítottunk. Ha lefordult, és elindult, néha hibás eredményt adott. Ekkor a debuggerrel futtattuk, majd a hibás programrészlet megtalálása után megint a szövegszerkesztő következett. Ez a folyamat a sok programindítgatás, információ kézi bevitel (sorszám) miatt nem volt hatékony. Azonban már a 70-es, 80-as években, a PC előtti korszakban készültek termékek, amelyek tartalmazták a szövegszerkesztőt, a fordítót és a futtatót is. Ezt az elvet nevezték integrált fejlesztő környezetnek (IDE). Ilyen IDE környezet volt a Borland által készített Turbo Pascal is, amely már a 8 bites számítógépeken egyetlen programban tartalmazott szövegszerkesztőt, fordítót, és futtatót (debuggert ekkor még nem). A programot egy bizonyos Anders Hejlsberg készítette, aki a később a Microsoftnál dolgozott, programozási nyelvek kifejlesztésén. Ilyen nyelvek például a J++ és a C#. A Microsoftnál is készült IDE eszköz karakteres képernyőre: a DOS-ban lévő BASIC-et felváltotta az editort és debuggert is tartalmazó Quick Basic.
IV.1.6. A vezérlők, vizuális programozás
A grafikus felületű (GUI) operációs rendszereken futtatható alkalmazások legalább két részből állnak: a program algoritmusát tartalmazó kódrészből és a felületet megvalósító felhasználói interfészből (UI). A két rész logikailag össze van kötve: a felhasználói interfészben történő események (event) kiváltják az algoritmus rész meghatározott alprogramjainak (C típusú nyelvekben ezeket függvénynek hívjuk) lefutását. Emiatt ezeket a függvényeket „eseménykezelő függvény”-nek hívjuk, és az operációs rendszer fejlesztő készletében (SDK) találhatunk is a megírásukhoz szükséges definíciókat fejállományokban. Kezdetben a felhasználói felülettel rendelkező programok tartalmazták az UI-hoz szükséges programrészleteket is: 50-100 soros C-nyelvű program képes volt egy üres ablakot megjeleníteni a Windows-ban, és az „ablak zárása” eseményt lekezelni (vagyis be lehetett csukni). Ekkor a fejlesztés nagy részét az UI elkészítése tette ki, az algoritmus programozása csak ezután jöhetett. Az UI programban minden koordináta pl. számként szerepelt, amelynek módosítása után a programot újra lefordítva megnézhettük, hogy a változtatás után miként néz ki a felület. A Microsoft első ilyen terméke (egyúttal a mai feljesztőeszköz névadója) a Visual Basic volt, amelynek első változatában előre legyártott vezérlőket tudtunk egy GUI-val az űrlapunkra (amely tulajdonképpen a készülő programunk felhasználói felülete) rátenni. A felhasználó által megrajzolt vezérlőkből szöveg formátumú kód készült, amely szükség esetén a beépített szövegszerkesztővel módosítható volt, majd a futtatás előtt lefordult. A futtatáshoz szükség volt egy könyvtárra, amely a vezérlők futtatható részét tartalmazta. Jellemzően emiatt kisméretű exe-fájlok készültek, de az elkészült programhoz mindig telepíteni kellett a run-time környezet azon verzióját, amelyben a program készült. A Visual Basic-et később a Visual C++ (VC++) és társai követték, majd – az office mintájára – a különálló termékek helyett egyetlen termékbe integrálták a fejlesztőeszközöket – ezt nevezték el Visual Studio-nak.
IV.1.7. A .NET keretrendszer
Az eddig tárgyalt elveket megvalósító programrészleteket a Microsoft egy közös, egyetlen fájlból telepíthető szoftvercsomaggá fogta össze, és elnevezte .net-nek. A fejlesztés során több verziója is megjelent, jelen könyv írásakor a 4.0 a stabil, és a 4.5 az előzetes teszt változat. A telepítéshez természetesen szükség van a Windows típusára is, minden Windows-hoz, minden CPU-ra valamint 32, 64 biten különböző változatokat kell telepíteni (lásd a "platformfüggetlenség" fejezetben.
A keretrendszer részei:
Common Language Infrastructure (CLI): ennek implementálásaként Common Language Runtime (CLR): a közös nyelvi fordító és futtató környezet. MSIL compilert, debuggert és run-timeot tartalmaz. Többek között képes a memóriában szemétgyűjtésre (Garbage Collection, GC) és a kivételek kezelésére (Exception Handling).
Base Class Library: az alaposztályok könyvtára. A GUI-k kényelmesen csak OOP-ben programozhatók, jól elkészített alaposztályokkal. Ezeket közvetlenül nem tudjuk példányosítani (legtöbbször nem is lehet: absztrakt osztályokról van szó). Például tartalmaz egy "Object" nevű interface osztályt (lásd IV.1.10. szakasz - A C++/CLI bővitett adattípusai).
WinForms: a Windows alkalmazások számára előre elkészített vezérlők, a Base Class Library-ból leszármaztatva. Ezeket rakjuk fel a formra fejlesztés közben, belőlük áll majd a programunk felülete. Nyelvfüggetlen vezérlők, minden alkalmazásból használhatjuk őket, az adott nyelv szintaktikájának megfelelően. Fontos megjegyezni, hogy a programunk nemcsak a fejlesztés alatt rárajzolt vezérlőket használhatja, hanem futás közben is létrehozhat ezek közül példányokat. Ugyanis, a rárajzolás közben is egy programkód-részlet keletkezik, ami a programunk indításakor lefut. A létrehozó kódrészlet általunk is megírható (odamásolható), és később is lefuttatható.
Egyéb részek: ide tartoznak például a webes alkalmazásfejlesztést támogató ASP.NET rendszer, az adatbázisok elérését lehetővé tevő ADO.NET, és a többprocesszoros rendszereket támogató Task Parallel Library. Ezekkel terjedelmi okok miatt nem foglalkozunk.
IV.1.8. C#
A .NET keretrendszert és a tisztán menedzselt kódot egyszerűen programozhatjuk C# nyelven. A nyelv készítője Anders Hejlsbergm aki a C++ és Pascal nyelvből származtatta, azok pozitívumait megtartotta, és leegyszerűsítette, a nehezebben használható elemeket (pl. pointerek) opcionálissá tette. Hobbistáknak és általában felsőoktatásban tanulóknak ajánlják (nem programozóknak – nekik a K&R C, valamint a C++ az univerzálisan használható eszközük). A .NET keretrendszer tartalmaz parancssoros C# fordítót, és ingyenesen letölthetünk Visual C# Express Edition-t a Microsofttól. Céljuk ezzel az, hogy a C# (és a .NET rendszer) terjedjen. Magyar nyelvű, ingyenes tankönyveket ugyancsak találhatunk az Interneten a C#-hoz.
IV.1.9. A C++ bővitése a CLI-hez
A Microsoft által készített C++ fordító, amennyiben natív Win32 alkalmazást fordítunk vele, szabványos C++-nak tekinthető. Azonban a CLI eléréséhez új adattípusokra és műveletekre volt szükség. A menedzselt kód (GC) kezeléséhez szükséges utasítások először a Visual Studio .NET 2002-es változatában jelentek meg, majd a 2005-ös változatban egyszerűsödtek. A definiált nyelv nem tekinthető C++-nak, mivel annak szabványos definíciójába (ISO/IEC 14882:2003) nem férnek bele a GC utasításai és adattípusai. A nyelvet C++/CLI-nek nevezték el, és szabványosították (ECMA-372). Megjegyezzük, hogy a szabványosítás célja általában az, hogy a többi gyártó is képes legyen kapcsolódó termékekkel a piacra lépni, esetünkben ez nem történt meg: a C++/CLI-t csak a Visual Studio képes lefordítani.
IV.1.10. A C++/CLI bővitett adattípusai
A menedzselt halmon lévő változókat máshogy kell deklarálnunk, mint a natív kód változóit. Azért nem automatikus a helyfoglalás, mert a fordító nem dönthet helyettünk: a natív és a menedzselt kód egy programon belül keverhető (erre csak a C++/CLI képes, a többi fordító mindig tisztán menedzselt kódot fordít, pl. C#-ban nincs natív int típus, az Int32 (aminek rövidítése az int) már egy osztály). A C++-ban a menedzselt halmon lévő osztályt referencia osztálynak (ref class) nevezzük. Ezzel a kulcsszóval kell deklarálni is, ugyanúgy, mint a natív osztályt. Pl. a .NET rendszer tartalmaz egy beépített "ref class String" típust, ékezetes karakterláncok tárolására és kezelésére. Ha "CLR/Windows Forms Application"-t készítünk a Visual Studio-val, a programunk ablaka (Form1) egy referencia osztály lesz. A referencia osztályon belül natív osztály nem definiálható. A referencia osztály a C++ osztályhoz képest máshogy viselkedik:
Statikus példány nem létezik belőle, csak dinamikus (vagyis programkódból kell létrehoznunk a példányát). Az alábbi deklaráció hibás: String szoveg;
Nem pointer mutat rá, hanem handle (kezelő), amelynek jele a ^. A handle-nek pointerszerű tulajdonságai vannak, például a tagfüggvényre hivatkozás jele a ->. Helyes deklaráció: String ^szoveg; - ekkor a szövegnek nincs még tartalma, ugyanis az alapértelmezett konstruktora üres, 0 hosszúságú sztringet (””) készít.
Létrehozásakor nem a new operátort használjuk, hanem a gcnew-t. Példa: szöveg= gcnew String(""); 0 hosszú string létrehozása konstruktorral. Ide már nem kell a ^ jel, használata hibás lenne.
A megszüntetése nem a delete operátorral történik, hanem a kezelő nullptr értékűvé tételével. Ekkor a garbage collector idővel automatikusan felszabadítja a felhasznált területet. Példa: szoveg=nullptr; A delete is használható, az lefuttatja a destruktort, de az objektum bent marad a memóriában.
Csak publikusan tud öröklődni és csak egy őstől (többszörös öröklődést interface osztállyal tudunk megvalósítani).
Készíthető úgynevezett interior pointer a referencia osztályra, amit a garbage collector aktualizál. Ezzel a menedzselt kód biztonsági előnyeit (pl. memória túlcímzés megakadályozása) elveszítjük.
A referencia osztálynak – a natívhoz hasonlóan – lehetnek adattagjai, metódusai, konstruktorai (túlterheléssel). Készíthetünk tulajdonságokat (property) is, amelyek vagy önmagukban tartalmazzák az adatot (triviális property), vagy függvények (skaláris property) az adat ellenőrzött eléréséhez (pl. az életkor nem állítható be negatív számnak). A property lehet virtuális is, valamint többdimenziós is, ekkor indexe is lesz. A property nagy előnye a natív C++ tagadat-elérő függvényéhez képest, hogy nincs zárójel utána. Példa: int hossz=szoveg -> Length; a Length a csak olvasható tulajdonság, a stringben lévő karakterek számát adja.
A destruktoron kívül, ami az osztály megszüntetésekor lefut (emiatt determinisztikusnak is hívhatjuk) tartalmazhat finalizer() metódust is, ami a GC (garbage collector) hív meg akkor, amikor a memóriából kitakarítja az objektumot. Nem tudjuk, hogy a GC mikor hívja meg a finalizert, emiatt nem-determinisztikusnak is hívhatjuk.
Az abstract és override kulcsszavakat minden esetben kötelező kiírni, ha virtuális metódust vagy adatot tartalmaz az ős.
Az összes adat és metódus, ha nem írunk elérési módosítót, private lesz.
Ha egy virtuális függvénynek nincs kifejtése, abstract-nak kell dekralálni: virtual típus függvénynév() abstract; vagy virtual típus függvénynév() =0; (az =0 a szabvány C++, az abstract =0-nak lett definiálva). Kötelező felüldefiniálni (override) az örökösben. Ha nem akarjuk felülírni a (nem tisztán) virtuális metódust, new kulcsszóval újat is készíthetünk belőle.
A referencia osztálynál megadható, hogy belőle ne lehessen öröklődéssel újabb osztályt létrehozni (a metódusok felülbírálásával), csak példányosíthatjuk. Ekkor az osztályt sealed-nek definiáljuk. Sok előre definiált osztályt tartalmaz a C++/CLI nyelv, amelyeket nem változtathatunk meg, ilyen pl. a már említett String osztály.
A többszörös öröklődéshez készíthetünk interface osztálytípust. Referencia helyett interface class/struct is írható (interface-nél ugyanaz a jelentésük). Az interface összes tagja (adattagok, metódusok, események, property-k) elérése automatikusan public. A metódusok, property-k nem kifejthetők (kötelezően abstract), az adatok pedig csak statikusak lehetnek. Konstruktor sem definiálható. Az interface nem példányosítható, csak ref/value class/struct hozható létre belőle, öröklődéssel. Az interfészből másik interface is örököltethető. Egy származtatott (derived) referencia osztálynak (ref class) akárhány interface lehet a szülő (base) osztálya. Az interface osztályt az osztályhierarchia elején szokás alkalmazni, például ilyen az Object nevű osztály, amelyet szinte mindenki örököl.
Adattároláshoz value class-t használhatunk. Erre nem kezelő hivatkozik, statikus osztálytípus (vagyis egy speciális jel nélküli változó). Csak interface osztályból származhat (vagy öröklődés nélküli, helyben lehet definiálni).
A függvénypointerek mellett egy referencia osztály metódusaihoz definiálhatunk delegate-t is, amely egy önállóan használható eljárásként jelenik meg. Az eljárás biztonságos, a natív kódú pointereknél lehetséges típuskeveredési hibák nem lépnek fel. A delegate-t alkalmazza a .NET rendszer a vezérlők eseményeihez (event) tartozó eseménykezelő metódusok meghívására és beállítására is.
Az alábbi táblázatban összefoglaltuk a memóriafoglalás és felszabadítás műveleteit:
|
Művelet |
K&R C |
C++ |
Managed C++ (VS 2002) (már nem használt) |
C++/CLI (VS 2005-) |
|---|---|---|---|---|
|
Memória foglalás az objektumnak (dinamikus változó) |
|
|
|
|
|
Memória felszabaditása |
|
|
Automatikus, |
<- mint a 2002-ben |
|
Hivatkozás az objektumra |
Mutató ( |
Mutató ( |
|
Mutató ( Kezelő ( |
IV.1.11. Az előredefiniált referencia osztály: String
A C++ string típus mintájára készült egy System::String osztály, szövegek tárolására. Definíciója: public sealed ref class String. A szöveget Unicode karakterek (wchar_t) sorozatával tárolja (ékezettel semmi probléma nincs, programszövegben az „L” betű kirakása a konstans elé nem kötelező, a fordító „odaképzeli”: L”cica” és ”cica” is használható). Alapértelmezett konstruktora 0 hosszú szöveget (””) hoz létre. Többi konstruktora lehetővé teszi, hogy char *-ból, natív string-ből, wchar_t *-ból, egy sztringeket tartalmazó tömbből hozzuk létre. Miután referencia osztály, handle-t (^) készítünk hozzá, és tulajdonságait, metódusait ->-lal érjük el. Gyakran használt tulajdonságok és metódusok:
String->Length hossz. Példa: s=”cicamica”; int i=s->Length; után i értéke 8 lesz.
String[hanyadik] karakter (0.. mint a tömböknél). Példa: s[1] értéke az ‘i’ karakter lesz.
String->Substring(hányadiktól, mennyit) részlet kiemelése. Példa: s->Substring(1,3) értéke ”ica” lesz.
String->Split(delimiter) : a sztringet szétszedi az elválasztóval (delimiter), a benne található szavak tömbjére. Példa: s=”12;34”; t=s->Split(‘;’); után t egy 2-elemű, sztringeket tartalmazó tömb lesz (deklarálni kell a sztringtömböt), 0. eleme ”12”, 1. eleme ”34”.
miben->IndexOf(mit) keresés. Egy számot kapunk vissza, a mit paraméter kezdő pozícióját a miben sztringben (0-val, mint tömbindexszel kezdve). Ha nem találta meg a részletet, -1-et ad vissza. Vigyázat, nem 0-t, mert a 0 érvényes karakterpozíció. Például (a „cicamica” értékű s-sel) s->IndexOf(“mi”) értéke 4 lesz, s->IndexOf(“kutya”) értéke -1.
Szabványos operátorok definiálva: ==, !=, +, +=. A natív (char *) sztringeknél az összehasonlító operátor a két pointer egyezését vizsgálta, és nem a tartalmak egyezőségét. A String típusnál operátor túlherheléssel a tartalmak egyezését vizsgálja az == operátor. Az összeadás operátor konkatenációt jelent. Például s+”, haj” értéke ”cicamica, haj” lesz.
String->ToString() is létezik, öröklés miatt. Gyakorlati jelentősége nincs, hiszen az eredeti stringet adja vissza. Viszont nincs natív C sztring-re (char *) konvertáló metódus. Lássunk egy példafüggvényt, amely ezt a konverziót elvégzi:
char * Managed2char(String ^s) { int i,hossz=s->Length; char *ered=(char *)malloc(hossz+1); // hely a konvertált stringnek memset(ered,0,hossz+1); // végjelekkel töltjük fel a konvertáltat. for (i=0; i<hossz;i++) // végigmegyünk a karaktereken ered[i]=(char)s[i]; //itt fogunk kapni egy warning-ot: s[i] //2 byteon tárolt unicode wchar_t típusú //karakter. Ebből ascii-t konvertálva az //ékezetek el fognak tűnni. return ered; // visszatérünk az eredményre mutató pointerrel. }
IV.1.12. A System::Convert statikus osztály
Adatainkat mindig célszerűen megválasztott típusú változókban tároljuk. Ha például meg kell számolni egy út adott pontján az óránként áthaladó járműveket, többnyire int típust alkalmazunk, még akkor is, ha tisztában vagyunk vele, hogy a változó értéke sosem lesz negatív. A negatív értéket (amely a változónak adható, hiszen előjeles) ebben a példában valamely kivétel (még nem volt mérés, hiba stb.) jelzésére használhatjuk. Az int (és a többi numerikus típus is) a memóriában binárisan tárolja a számokat, lehetővé téve az aritmetikai műveletek (például összeadás, kivonás elvégzését, a matematikai függvények (például sqrt, sin) hívását. Amikor felhasználói adatbevitel történik (a programunk bekér egy számot), a felhasználó karaktereket gépel be. A 10-es számot egy ‘1’ és egy ‘0‘ karakter begépelésével írja be, amiből egy sztring keletkezik: ”10”. Ha ehhez hozzá szeretnénk adni 20-at, és hasonlóan, sztringként vittük be, az eredmény ”1020” lesz, a String osztály „+” operátora ugyanis egymás után másolja a sztringeket. A natív Win32 kód scanf() függvénye, és a cin szabványos beviteli adatfolyam használatakor, ha numerikus típusba került az input, az olvasás közben létrejött a konverzió, a scanf paraméterében, vagy a cin >> operátora után lévő típusra. A windows-os előre elkészített bemeneti vezérlők esetében ez nincs így: azok kimenete mindig String típusú. Hasonlóan a kimenethez is mindig String típust kell előállítanunk, mert csak ezt tudjuk megjeleníteni a vezérlőkön. A programok közti kommunikációra (export/import) használt szöveges állományok is sztringekből állnak, amelyekben számok, vagy egyéb adattípusok (dátum, logikai, valuta) is lehetnek. A System névtér tartalmaz egy Convert nevű osztályt, amelynek statikus metódusai nagyszámú túlterheléssel (overload) segítik az adatkonverziós munkát. A leggyakoribb szöveg <-> szám konverzióhoz a Convert::ToString(NumerikusTipus) és a Convert::ToNumerikusTipus(String) metódusok definiáltak. Például, ha a fenti példában s1=”10” és s2=”20”, így adjuk őket össze egészként értelmezve:
int osszeg=Convert::ToInt32(s1)+Convert::ToInt32(s2);
Amennyiben s1, vagy s2 nem konvertálható számmá (például valamelyik 0 hosszú, vagy illegális karaktert tartalmaz), kivétel keletkezik. A kivétel egy try/catch blokkal lekezelhető. Valós számok esetében még egy dologra kell figyelni: ezek a nyelvi beállítások. Mint ismeretes, Magyarországon a számok tizedes részét vesszővel választjuk el az egész résztől: 1,5. Az angol nyelvterületen erre a célra a pontot használják: 1.5. A program szövegében mindig pontot használunk a valós számoknál. A Convert osztály viszont a nyelvi beállításoknak (CultureInfo) megfelelően végzi el a valós <-> sztring konverziót. A CultureInfo be is állítható az aktuális programhoz, ha például kaptunk egy szöveges állományt, amely angol valós számokat tartalmaz. Az alábbi programrészlet átállítja a saját kultúra információját, hogy jól tudja az ilyen file-t kezelni:
// egy kultúra típusú referencia osztály példánya.
System::Globalization::CultureInfo^ c;
// Mintha az USA-ban lennénk
c= gcnew System::Globalization::CultureInfo("en-US");
System::Threading::Thread::CurrentThread->CurrentCulture=c;
// innentől a programban a tizedesjel a pont, a lista elválasztó a vessző
A Convert osztály metódusai megjelenhetnek az adatosztály metódusai közt is. Például az Int32 osztállyal létrehozott példánynak is van ToString() metódusa a sztringgé konvertáláshoz, és Parse() metódusa a sztringből konvertáláshoz. Ezek a metódusok többféleképpen is paraméterezhetők. Gyakran használunk számítógép/hardverközeli programokban hexadecimális számokat. Az alábbi példa soros porton keresztül, hexadecimális számokat is tartalmazó sztringekkel kommunikál egy külső hardverrel:
if (checkBox7->Checked) c|=0x40;
if (checkBox8->Checked) c|=0x80;
sc="C"+String::Format("{0:X2}",c); // 2 jegyű hex szám lett a byte típusú
//c-ből. A C parancs, ha c értéke
//8 volt: „C08” fog kimenni, ha 255 volt //„CFF”.
serialPort1->Write(sc); // kiküldtük a hardvernek
s=serialPort1->ReadLine(); // visszajött a válasz
status= Int32::Parse(s,System::Globalization::NumberStyles::AllowHexSpecifier);
// konvertáljuk a választ egésszé.
IV.1.13. A CLI array template-tel megvalósitott tömb referencia osztálya
A tömb a programozásban gyakran előforduló adatszerkezet, algoritmuselemekkel. A .NET fejlesztői készítettek egy általános tömbdefiníciós osztálysablont(template), amiből a felhasználó, mint „gyártószerszámból” definiálhat referencia osztályt a neki szükséges adattípusból, a C++-ban bevezetett template jelölést használva (<>). Többdimenziós tömbökhöz is használható. A tömb elemeinek elérése a hagyományos szögletes zárójelek közé tett egész index-szel, a [ ] operátorral történik.
Deklaráció: cli::array<típus,dimenzió=1>^ tömbnév; a dimenzió elhagyható, ekkor értéke 1. A ^ a ref class jele, a cli:: elhagyható, ha a forrásfájlunk elején használjuk a using namespace cli; utasitást.
A tömbnek – miután referencia osztály, deklarációnál csak a handle készül el, de még nem hivatkozik sehova - helyet kell foglalni használat előtt a gcnew operátorral. A deklarációs utasításban is megtehetjük a helyfoglalást: a tömb elemeit felsorolva is megadhatjuk a C++-ban szokásos módon, {} jelek között.
Tulajdonsága: Length az egydimenziós tömb elemeinek száma, a függvénynek átadott tömbnél nem kell méret, mint az alap C-ben, a ciklusutasításban felhasználható, segítségével nem címzünk ki a tömbből :
for (i=0;i<tomb->Length;i++)….
Az alapvető tömbalgoritmusokra készítettek statikus metódusokat, ezeket a System::Array osztály tárolja:
Clear(tömb,honnan,mennyit) törlés. A tömbelemek értéke 0, false, null, nullptr lesz (a tömböt alkotó alaptípustól függően), vagyis töröljük a tömb elemeit.
Resize(tömb, új méret) átméretezés, bővülés esetén a régi elemek után a Clear()-nál használt értékekkel tölti fel a tömböt
Sort(tömb) a tömb elemeinek sorba rendezése. Alaphelyzetben numerikus adatok növekvő sorrendbe állításához használható fel. Megadhatunk kulcsokat és összehasonlító függvényt is, hogy tetszőleges típusú adatokat is sorba tudjunk rendezni.
CopyTo(céltömb,kezdőindex) elemek másolása. Vigyázat: az = operátor csak a referenciát duplikálja, ha a tömb adata megváltozik, a másik hivatkozás felől elérve is megváltozik a belső adat. Hasonlóan az == is azt jelzi, hogy a két referencia ugyanaz, és nem az elemeket hasonlítja össze.
Ha a típus, amiből a tömböt készítjük, egy másik referencia osztály (pl. String^), akkor azt kell megadnunk a definícióban. A tömb létrehozása után az elemeket is létre kell hozni egyesével, mert alaphelyzetben nullptr-eket tartalmaz. Példa: String^ mint tömbelem, kezdeti értékadással. Ha nem írjuk ki a nulla hosszúságú sztringeket, nullptr-ek lettek volna a tömbelemek
array<String^>^ sn= gcnew array<String^>(4){"","","",""};
A következő példában lottószámokat készítünk egy tömbbe, majd ellenőrizzük, hogy felhasználhatóak-e egy játékban: vagyis nincs köztük két azonos. Ehhez sorba rendezzük az elemeket, hogy csak a szomszédos elemeket kelljen vizsgálni, és emelkedő számsorrendben lehessen kiíratni az eredményt:
array<int>^ szamok; // managed tömb típus, referencia
Random ^r=gcnew Random();// véletlenszám generátor példány
int db=5,max=90,i; // beállítjuk, hány szám kell, és mennyiből a maximális szám. Inputként is megadható lenne, konverzió után.
szamok=gcnew array<int>(db); // managed heap-en lévő tömb legyártva.
for(i=0;i<szamok->Length;i++)
szamok[i]=r->Next(max)+1;// nyers véletlenszámok a tömbben vannak
Array::Sort(szamok); // a beépitett metódussal sorba rakjuk a számokat.
// ellenőrzés: két egyforma egymás mellett ?
bool joszam=true;
for (i=0;i<szamok->Length-1;i++)
if (szamok[i]==szamok[i+1]) joszam=false;
IV.1.14. C++/CLI: Gyakorlati megvalósitás pl. a Visual Studio 2008-as változatban
Ha CLR-es (vagyis .NET-es, ablakos) programot szeretnénk készíteni Visual Studio-val, az új elem varázslónál válasszuk a CLR kategória valamelyik „Application” elemét. A CLR console ugyanúgy fog kinézni, mint a „Win32 console app”, vagyis szöveges felülete lesz. Tehát ne a Console-t válasszuk, hanem a „Windows Forms Application”-t. Ekkor létrejön a programunk ablaka, a Form1 nevű konténerobjektum, amelynek kódja a Form1.h fejállományban lesz. Itt helyezi el a Form Designer a megrajzolt vezérlők kódját (és elé ír egy megjegyzést, hogy ne módosítsuk, de természetesen néha szükséges a módosítás). A mellékelt ábrán látható a kiválasztandó elem:
A választás után létrejön a projektünk könyvtárszerkezete, benne a szükséges fájlokkal, - ekkor már kezdhetünk vezérlőket elhelyezni a formon. A „Solution Explorer” ablakban megkereshetjük a forrásfájlokat, és mindegyiket módosíthatjuk is. Az alábbi ábrán egy éppen elkezdett projekt látható:
A Form1.h-ban található a programunk (form ikonja van, szokásos az stdafx.h-ba is kódot elhelyezni). A főprogramban (mea_1.cpp) számunkra nincs semmi változtatható. A „View” menü „Designer” menüpontjából a grafikus editort, „Code” menüpontjából a forrásprogramot választhatjuk ki. A „View/Designer” menüpont után így néz ki az ablakunk:
A „View/Code” után pedig így:
A „View/Designer” menüpontra állva szükségünk lesz még a Toolbox-ra, itt vannak a felrakható vezérlők (Az eszköztár csak designer állapotban tartalmaz felrakható elemeket). Ha esetleg nem lenne látható, a „View/Toolbox” menüponttal megjeleníthetjük. A toolbox esetérzékeny segítséget is tartalmaz: a vezérlők felett hagyva az egérmutatót, rövid összefoglalót kapunk a vezérlő működéséről, lásd az alábbi ábrát, ahol a label vezérlőt választottuk ki:
A vezérlő kiválasztása a szokásos bal egérgombbal lehetséges. Ezután a kiválasztott vezérlő befoglaló téglalapja a formra rajzolható, amennyiben látható vezérlőt választottunk. A nem látható vezérlők (pl. timer) külön sávban, a form alatt kapnak helyet. Megrajzolás után a formunkra kerül egy példány a vezérlőből, automatikus elnevezéssel. Az ábrán a „Label” vezérlőt (nagybetűs: típus) választottuk ki, amennyiben ebből a vezérlőből az elsőt rajzoljuk, „label1”-re (kisbetűs: példány) fogja a fejlesztő környezet elnevezni. A vezérlők megrajzolása után, amennyiben szükséges, beállíthatjuk a tulajdonságaikat, és az eseményeikhez tartozó függvényeket. A vezérlőt kijelölve, a jobb gomb benyomása után, a „Properties” menüpont által előhozott ablakban tehetjük ezt meg. Fontos megjegyezni, hogy az itteni beállítások csak az aktuális vezérlőre vonatkoznak, és az egyes vezérlők tulajdonság ablakai egymástól eltérőek. Az ábrán a label1 vezérlő ablakát kapcsoljuk be:
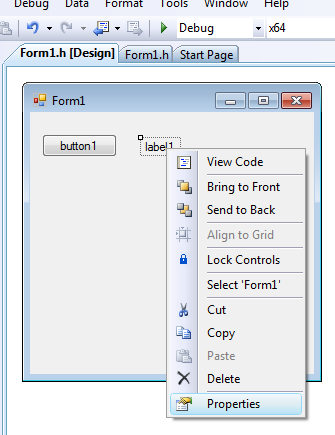
Ezután egy külön ablakban tudjuk megadni a tulajdonságok értékét:
Ugyanez az ablak szolgál az eseménykezelők kiválasztására is. Az eseménykezelők megadásához a villám ikonra ( ) kell kattintani. Ekkor az adott vezérlő összes eseményre adott válaszlehetősége megjelenik. Ahol a lista jobb oldala üres, arra az eseményre a vezérlő nem fog reagálni.
) kell kattintani. Ekkor az adott vezérlő összes eseményre adott válaszlehetősége megjelenik. Ahol a lista jobb oldala üres, arra az eseményre a vezérlő nem fog reagálni.
A példában a label1 vezérlő nem reagál, ha rákattintanak (a label1 vezérlő le tudja kezelni a Click eseményt, de nem szokás a vezérlőt ilyen módon használni). Kétféle módon kerülhet a listába függvény: ha meglévő függvényt szeretnénk a vezérlő eseményekor lefuttatni (és a paraméterei megegyeznek az esemény paramétereivel), akkor a legördülő listából kiválaszthatjuk, ha még nincs ilyen, az üres helyre történő dupla kattintással egy úgy függvény fejléce készül el, és a kódszerkesztőbe kerülünk. Minden vezérlőnek van egy alapértelmezett eseménye (például a button-nak a click), a tervező ablakban a vezérlőre kettőt kattintva, az esemény kódszerkesztőjébe kerülünk, ha még nincs ilyen függvény, a fejléce is létrejön és a hozzárendelés is. Vigyázat, a vezérlő a hozzárendelés nélkül nem működik! Tipikus hiba például, megírni a button1_Click függvényt, a paramétereket is helyesen megadva, összerendelés nélkül. Ekkor – hibátlan fordítás után – a gomb nem reagál a kattintásra. Csak akkor fog reagálni, ha az events ablakban a click sorban szerepel a button1_Click függvény neve.
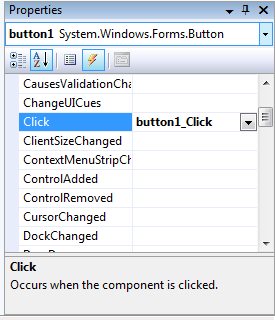
IV.1.15. Az Intellisense beépitett segítség
Mint az előző ábrán láttuk, egy vezérlőnek rengeteg tulajdonsága lehet. Ezeket a program szövegében használhatjuk, de mivel azonosítónak minősülnek, karakterről-karakterre egyezniük kell a definícióban szereplő tulajdonsággal, a kis- és nagybetűket figyelembe véve. A tulajdonságok neve gyakran hosszú (például UseCompatibleTextRendering). A programozónak ezeket kellene begépelnie hibátlanul. A szövegszerkesztő tartalmaz egy segítséget: az objektum neve (button1) után az adattagra utaló jelet (->) téve listát készít a lehetséges tulajdonságokból, egy kis menüben megjeleníti őket, a nyilakkal vagy egérrel kiválaszthatjuk a nekünk szükségeset, majd a tab billentyűvel beírja a programunk szövegébe. Akkor is előjön a segítő lista, ha elkezdjük gépelni a tulajdonság nevét. A Visual Studio ezeket a vezérlő-tulajdonságokat egy nagyméretű .NCB kiterjesztésű fájlban tárolja, és amennyiben letöröljük (pl. pen drive-on viszünk át egy forrásprogramot másik gépre), megnyitáskor újragenerálja. Az intellisense néhány esetben nem működik: ha a programunk szintaktikailag hibás, a kapcsos zárójelek száma nem egyezik, akkor megáll. Hasonlóan nem működik a Visual Studio 2010-es változatában sem, ha CLR kódot írunk. Az ábrán a label7->Text tulajdonságot szeretnénk megváltoztatni, a rengeteg tulajdonság miatt beírjuk a T betűt, majd az egérrel kiválasztjuk a Text-et.
IV.1.16. A CLR-es program típusának beállitása.
Mint ahogy azt az előzőekben már említettük, a C++/CLR képes a kevert módú (natív+menedzselt) programok készítésére. Amennyiben az előző pontban leírt beállításokat használjuk, a programunk tisztán menedzselt kódú lesz, a natív kód nem fordítható le. Kezdetben azonban mégis célszerű ezekkel a beállításokkal elindulni, mert így a programunk ablaka és a vezérlőink használhatók lesznek. A projekt tulajdonságaiban (kijelöljük a projektet, majd jobb gomb és „Properties”) tudjuk ezeket a beállításokat megtenni. Vigyázat, nem a legfelső szinten álló solution, hanem az alatta lévő projekt tulajdonságairól van szó!
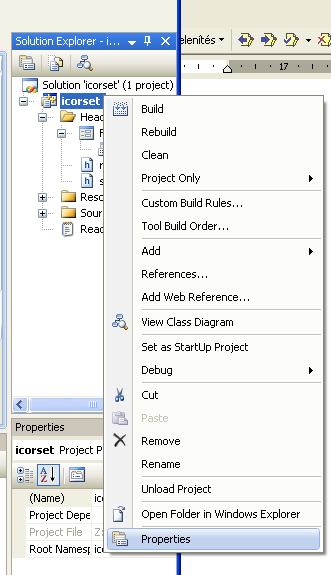
A "Property Pages" ablakban adható meg a natív/kevert/tisztán menedzselt kód beállítás, a "Common Language Runtime Support" sorban. Ötféle beállítás közül választhatunk:

Az egyes lehetőségek a következők:
"No common Language Runtime Support" – nincs menedzselt kód. Egyenértékű, ha Win32 konzolalkalmazást, vagy natív Win32-es projektet készítünk. Ebben a beállításban nem is képes a .NET-es rendszer elemeinek (handle-k, garbage collector, referencia osztályok, assembly-k) fordítására.
"Common Language Runtime Support" – van natív és menedzselt kódú fordítás is. Ezzel a beállítással kell a kevert módú programokat elkészíteni, vagyis amennyiben a programot az ablakos alapbeállításokkal kezdtük el fejleszteni, és szeretnénk natív kódú függvényeket használni, ezt a menüpontot kell kiválasztanunk.
"Pure MSIL Common Language Runtime Support" – tisztán menedzselt kódú fordítás. A "Windows Form Application" template-ből készített programok alapértelmezése. (A C# fordítónak csak ez az egy beállítása lehetséges.) Megjegyzés: ez a típusú kód C++-ban tartalmazhat natív kódú adatokat is, amelyeket menedzselt kódú programokkal érünk el.
"Safe MSIL Common Language Runtime Support" – mint az előző, csak natív kódú adatokat sem tartalmazhat, és engedélyezi a CRL kód biztonsági ellenőrzését, egy erre a célra készített eszközzel (
peverify.exe)."Common Language Runtime Support, Old Syntax" - ez is kevert kódú programot készít, de a Visual Studio 2002-es szintaktikával. (_gc new a gcnew helyett). A régebben készült programokkal való kompatibilitás miatt maradt meg ez a beállítás. Ne használjuk!
IV.2. Az ablakmodell és az alapvezérlők.
IV.2.1. A Form alapvezérlő
A Form nem rakható fel a toolbox-ból, az új projektnél létrejön. Alaphelyzetben üres, téglalap alakú ablakot hoz létre. A properties-ben találhatók a beállitásai, pl. Text a címsora, amibe alaphelyzetben a vezérlő neve (ha ez az első form, Form1) kerül bele. Ehhez hozzáférünk itt is és a programból is (this->Text=…), mert a Form1.h-ban használható a formunk referencia osztálya, ami a Form osztályból örököltetett példány, amire a programukon belül a this referenciával hivatkozhatunk. Lehet állítani a tulajdonságokat, és a beállításokból készült programrészletet felhasználni a programunk másik részén. Ugyanis az beállított tulajdonságokból (is) egy programrészlet lesz, a form1.h elején, egy külön szakaszban:
#pragma region Windows Form Designer generated code
/// <summary>
/// Required method for Designer support - do not modify
/// the contents of this method with the code editor.
/// </summary>
// button1
this->button1->Location = System::Drawing::Point(16, 214);
this->button1->Name = L"button1";
this->button1->Size = System::Drawing::Size(75, 23);
this->button1->TabIndex = 0;
this->button1->Text = L"button1";
this->button1->UseVisualStyleBackColor = true;
this->button1->Click += gcnew System::EventHandler(this, &Form1::button1_Click);
IV.2.2. A Form vezérlő gyakran használt tulajdonságai
Text – a form felirata. Ez a tulajdonság minden olyan vezérlőnél megtalálható, amely szöveget (is) tartalmaz.
Size – a form mérete, alaphelyzetben pixelben. Tartalmazza a Width (szélesség) és a Height (magasság) közvetlenül elérhető tulajdonságokat is. A látható vezérlőknek is vannak ilyen tulajdonságaik.
BackColor – háttér színe. Alaphelyzetben ugyanolyan színű, mint a rendszerben definiált vezérlők háttere (System::Drawing::SystemColors::Control). Ennek a beállításnak akkor lesz jelentősége, amikor a formon lévő grafikát le szeretnénk törölni, mert a törlés egy színnel való kitöltést jelent.
ControlBox – az ablak rendszermenüje (minimalizáló, maximalizáló gomb és a bal oldalon található windows menü) engedélyezhető (alapértelmezés) és letiltható
FormBorderStyle – itt adhatjuk meg, hogy az ablakunk átméretezhető vagy fix méretű legyen, esetleg még keretet sem tartalmazzon.
Locked – az ablak átméretezését és elmozgatását tilthatjuk le a segítségével.
AutoSize – az ablak képes változtatni a méretét, a benne lévő tartalomhoz igazodva.
StartPosition – a program indításkor hol jelenjen meg a windows asztalon. Alkalmazása: ha többmonitoros rendszert használunk, megadhatóak a második monitor x,y koordinátái, a programunk ott fog elindulni. Ezt a beállítást célszerű programból, feltételes utasítással megtenni, mert amennyiben csak egy monitoros rendszeren indítják el, nem fog látszani a program ablaka.
WindowState – itt adhatjuk meg, hogy a programunk ablaka legyen normál (Normal), a teljes képernyőn fusson (Maximized), vagy a háttérben fusson (Minimized). Természetesen, mint a tulajdonságok többsége, futási időben is elérhető, vagyis amennyiben a kis ablakban elindított program szeretné magát maximalizálni (mert például sok mindent meg szeretne mutatni), arra is van lehetőség: this->WindowState=FormWindowState::Maximized;
IV.2.3. A Form vezérlő eseményei
Load – a programunk elindulásakor, még a megjelenés előtt lefutó programrészlet. A Form vezérlő alapértelmezett eseménye, vagyis a címsorára kettőt kattintva a „Designer”-ben ennek a kezelőfüggvényébe kerül az editor. A függvény szokásosan – mivel a program indulásakor egyszer lefut, inicializáló szerepet tölthet be programunkban. Értékeket adhatunk a változóknak, legyárthatjuk a szükséges dinamikus változókat, és a többi vezérlőnkön (ha eddig nem tettük meg) feliratot cserélhetünk, a form méretét dinamikusan beállíthatjuk stb.
Példaként nézzük meg a másodfokú egyenlet programjának Load eseménykezelőjét!
private: System::Void Form1_Load(System::Object^ sender,
System::EventArgs^ e) {
this->Text = "masodfoku";
textBox1->Text = "1"; textBox2->Text = "-2"; textBox3->Text = "1";
label1->Text = "x^2+"; label2->Text = "x+"; label3->Text = "=0";
label4->Text = "x1="; label5->Text = "x2="; label6->Text = "";
label7->Text = ""; label8->Text = "";
button1->Text = "Oldd meg";
if (this->ClientRectangle.Width < label3->Left + label3->Width)
this->Width = label3->Left + label3->Width + 24;
// nem elég széles a form
if (this->ClientRectangle.Height < label8->Top + label8->Height)
this->Height = label8->Top + label8->Height + 48;
// nem elég magas
button1->Left = this->ClientRectangle.Width - button1->Width-10;
// pixel
button1->Top = this->ClientRectangle.Height - button1->Height - 10;
}
A fenti példában a kezdeti értékek beállítása után a feliratokat állítottuk be, majd a form méretét akkorára vettük, hogy a teljes egyenlet és az eredmények (label3 volt a jobb oldali szélső vezérlő és label8 a form alján lévő) is láthatóak legyenek.
Amennyiben ebben a függvényben azt állapítjuk meg, hogy a program futása értelmetlen (feldolgoznánk egy fájlt, de nem találjuk, kommunikálnánk egy hardverrel, de nem elérhető, Interneteznénk, de nincs kapcsolat stb.) egy hibaüzenet ablak megjelenítése után a programból ki is léphetünk. Itt látható egy hardveres példa:
if (!vezerlo_van) {
MessageBox::Show("No iCorset controller.",
"Error",MessageBoxButtons::OK);
Application::Exit();
} else {
// van vezérlő, vezérlő inicializálása.
}
Egy dologra azonban ügyeljünk: az Application::Exit() nem azonnal lép ki a programból, csak a Window üzenetsorba helyez be egy nekünk szóló kilépésre felszólító üzenetet. Vagyis az if… utáni programrészlet is le fog futni, sőt a programunk ablaka is megjelenik egy pillatatra a kilépés előtt. Ha a további részlet lefutását el szeretnénk kerülni (kommunikálnánk a nem létező hardverrel), akkor azt a fenti if utasítás else ágában tegyük meg, és az else ág a Load függvény végéig tartson. Így biztosíthatjuk, hogy az ilyenkor már valószínűleg hibát okozó programrészlet ne fusson le.
Resize – A formunk átméretezésekor (a minimalizálás, maximalizálás, normál méretre állítás is ennek számít) lefutó eseménykezelő. A betöltéskor is lefut, így a fenti példában lévő form méretnövelést ide is tehettük volna, ekkor a formot nem is lehetne kisebbre méretezni, a vezérlőink láthatósága miatt. Amennyiben ablakméretfüggő grafikát készítettünk, itt át lehet méretezni.
Paint – a formot újra kell festeni. Részletesen lásd a "GDI+ használata" című fejezetben, IV.4.1. szakasz - A GDI+használata.
MouseClick, MouseDoubleClick – a Formra egyet vagy kettőt kattintottunk az egérrel. Amennyiben vannak egyéb vezérlők is a formon, ez az esemény akkor fut le, ha egyik egyéb vezérlőre sem kattintottunk, csak az üres területre. Az eseménykezelő egyik paraméterében megkapjuk a
System::Windows::Forms::MouseEventArgs^ e
referencia osztályra mutató kezelőt, amely többek közt a kattintás koordinátáit (X,Y) is tartalmazza.
MouseDown, MouseUp – a Formon valamelyik egérgombot lenyomtuk vagy felengedtük. A paraméter tartalmazza a Button paraméterben is, hogy melyik gombot nyomtuk le, illetve engedtük fel. A következő programrészlet a kattintások koordinátáit egy fájlba menti, ezzel pl. egy egyszerű rajzolóprogramot készíthetünk:
// ha mentés bekapcsolva és bal gombot nyomtunk
if (toolStripMenuItem2->Checked && (e->Button == System::Windows::Forms::MouseButtons::Left)) {
// kiirjuk a fileba a két koordinátát, x-et és y-t, mint int32-t
bw->Write(e->X); // int32-t irunk,
bw->Write(e->Y); // vagyis 2*4 byte/pont
}
MouseMove: - az egér mozgatásakor lefutó függvény. Az egér gombjaitól függetlenül dolgozik, amennyiben az egerünk a form felett jár, a koordinátái kiolvashatók. A lenti programrészlet ezeket a koordinátákat az ablak fejlécében (vagyis a Text tulajdonságában) jeleníti meg, természetesen a szükséges konverziók után:
private: System::Void Form1_MouseMove(System::Object^ sender, System::Windows::Forms::MouseEventArgs^ e) {
// koordináták a fejlécbe, azt soha senki nem nézi meg
this->Text = "x:" + Convert::ToString(e->X) + " y=" + Convert::ToString(e->Y);
}
FormClosing – a programunk valamilyen okból kapott egy Terminate() Windows üzenetet. Az üzenet forrása bármi lehetett: saját maga az Application::Exit()-tel, a felhasználó az „ablak bezárása" kattintással vagy az alt-F4 billentyű kombinációval, az operációs rendszer leállítás előtt stb. A Form ezen függvény lefutása után bezáródik, ablaka eltűnik, az általa lefoglalt erőforrások felszabadulnak. Amennyiben a programunk úgy dönt, hogy még ez nem tehető meg, az eseménykezelő paraméterének Cancel nevű tagjának true értékre állításával a program leállítása megszüntethető, vagyis tovább fog futni. Az operációs rendszer természetesen, amennyiben a leállítását akarjuk ezzel megakadályozni, adott idő múlva becsukja a programunkat. A következő példában a program egy dialógusablakban történő kérdés után hagyja csak kiléptetni magát:
Void Form1_FormClosing(System::Object^ sender, System::Windows::Forms::FormClosingEventArgs^ e) {
System::Windows::Forms::DialogResult d;
d=MessageBox::Show("Biztos, hogy használni akarja a légzsákot ?”,
"Fontos biztonsági figyelmeztetés", MessageBoxButtons::YesNo);
if (d == System::Windows::Forms::DialogResult::No) e->Cancel=true;
}
FormClosed – a programunk már a kilépés utolsó lépésében jár, az ablak már nem létezik. Itt már nincs visszaút, ez az utolsó esemény.
IV.2.4. A vezérlők állapotának aktualizálása
Az eseménykezelők (Load, Click) lefutása után a rendszer aktualizálja a vezérlők állapotát, hogy a következő eseményre már az új állapotban legyenek. Azonban tekintsük a következő mintaprogramrészletet, amely a form címsorába növekvő számokat ír, elhelyezhető pl. a button_click eseménykezelőben:
int i;
for (i=0;i<100;i++)
{
this->Text=Convert::ToString(i);
}
A programrészlet lefutása alatt (leszámítva a sebességproblémát) semmit sem változik a form fejléce. A Text tulajdonságot átírtuk ugyan, de ettől a vezérlőn a régi felirat látszik. Csak akkor fog változni, ha véget ért az adott eseménykezelő függvény. Ekkor viszont a „99” fog a vezérlőre kerülni. Hosszabb műveletek esetén (képfeldolgozás, nagyméretű szövegfájlok) jó lenne valahogy jelezni a felhasználónak, hol tartunk, megjeleníteni az aktuális állapotot, ennek hiányában úgy is érezheti, hogy a programunk lefagyott. Ezt a célt szolgálja az Application::DoEvents() függvényhívás, amely a vezérlők aktuális állapotát aktualizálja: a példánkban lecseréli a form fejlécét. Ebből sajnos semmit sem látunk, csak akkor tudjuk elolvasni a számokat, ha egy várakozást (Sleep) is beépítünk a ciklusba:
int i;
for (i=0;i<100;i++)
{
this->Text=Convert::ToString(i);
Application::DoEvents();
Threading::Thread::Sleep(500);
}
A Sleep() függvény argumentuma ezredmásodpercben a várakozás ideje. Ezzel szimuláltuk a lassú műveletet. Ha adott időnként ismétlődő algoritmuselemekre van szükségünk, a Timer vezérlőt használjuk (lásd IV.2.22. szakasz - Az időzítésre használt vezérlő: Timer ).
IV.2.5. Alapvezérlők: Label (címke) vezérlő
A legegyszerűbb vezérlő a szöveg megjelenítésére szolgáló Label vezérlő. A „Text” nevű, String ^ típusú tulajdonsága tartalmazza a megjelenítendő szöveget. Alaphelyzetben a szélessége a megjelenítendő szöveghez igazodik (AutoSize=true). Amennyiben szöveget jelenítünk meg segítségével, eseményeit (pl. Click) nem szokás használni. A Label-nek nincs alaphelyzetben kerete (BorderStyle=None), de bekeretezhető (FixedSingle). A háttérszín a BackColor, a szöveg színe pedig a ForeColor tulajdonságban található. Ha a megjelenített szöveget el szeretnénk tüntetni, arra két lehetőségünk is van: vagy a Visible nevű, logikai típusú tulajdonságot false-ra állítjuk, ekkor a Text tulajdonság nem változik, de a vezérlő nem látszik, vagy a Text tulajdonságok állítjuk be egy üres, 0 hosszúságú sztringre (””). Visible tulajdonsága minden látható vezérlőnek van, a tulajdonság false-ra állításával a vezérlő eltűnik, majd true-ra állításával újra láthatóvá válik. Ha biztosak vagyunk benne, hogy a legközelebbi megjelenítéskor más lesz a vezérlő felirata, célszerű az üres sztringes megoldást választani, mert ebben az esetben az értékadáskor az új érték egyből meg is jelenik, míg a Visible-s megoldáskor egy újabb, engedélyező programsorra is szükség van.
IV.2.6. Alapvezérlők: TextBox (szövegmező) vezérlő
A TextBox vezérlő szöveg (String^) bevitelére használható (amennyiben szám bevitelére van szükség, akkor is ezt használjuk, csak a feldolgozás egy konverzióval kezdődik). A „Text” tulajdonsága tartalmazza a szövegét, amelyet programból is átírhatunk, és a felhasználó is átírhat a program futása közben. A már említett Visible tulajdonság itt is megjelenik, emellett egy „Enabled” tulajdonság is rendelkezésre áll. Az Enabled-et false-re állítva a vezérlő látszik a form-on, csak szürke színű, és a felhasználó által nem használható: megváltoztatni sem tudja és rákattintani sem tud. Ilyen állapotú telepítés közben a „Tovább” feliratú parancsgomb, amíg a felhasználói szerződést nem fogadtuk el. A TextBox-nak alapértelmezett eseménye is van: TextChanged, amely minden változtatás után (karakterenként) lefut. Többjegyű számoknál, egy karakternél hosszabb adatoknál, több input adat esetén (több szövegdobozban) nem szoktuk megírni, mert értelmetlen lenne. Például, a felhasználónak be kell írnia a nevét a TextBox-ba, a program pedig elrakja egy fájlba. Minden egyes karakternél felesleges lenne kiírni a fájlba az eddigi tartalmat, mert nem tudjuk, melyik lesz az utolsó karakter. Ehelyett megvárjuk, amíg véget ér a szerkesztés, kész az adatbevitel (esetleg több szövegmező is van a formunkon), és egy célszerűen elnevezett (kész, mentés, feldolgozás) parancsgomb megnyomásával jelezheti a felhasználó, hogy a szövegmezőkben benne vannak a program input adatai. Ellentétben a többi Text-et tartalmazó vezérlővel, amelynél a „Designer” beleírja a Text tulajdonságba a vezérlő nevét, itt ez nem történik meg, a Text tulajdonság üresen marad. A TextBox többsorosra is állítható a MultiLine tulajdonság true-ra kapcsolásával. Ekkor a Text-ben soremelések szerepelnek, és a Lines tulajdonság tartalmazza a sorokat, mint egy sztringekből készített tömb elemeit. Néhány programozó kimenetre is a szövegmező vezérlőt használja, a ReadOnly tulajdonság true-ra állításával. Amennyiben nem szeretnénk visszaírni a bevitt karaktereket, jelszó beviteli módba is kapcsolhatjuk a szövegmezőt a UseSystemPasswordChar tulajdonság true-ra állításával. A másodfokú egyenlet indításakor lefutó függvényt már láttuk, most nézzük meg a „számolós” részt. A felhasználó beírta az együtthatókat (a,b,c) a megfelelő szövegmezőkbe, és benyomta a „megold” gombot. Első dolgunk, hogy a szövegmezőkből kivesszük az adatokat, konverziót alkalmazva. Majd jöhet a számítás, és az eredmények kiíratása.
double a, b, c, d, x1, x2, e1, e2; // lokális változók
// valós megoldás lett ? legyünk optimisták
bool vmo = true;
// ha elfelejtenék értéket adni bármelyik változónak -> error
a = Convert::ToDouble(textBox1->Text); // String -> double
b = Convert::ToDouble(textBox2->Text);
c = Convert::ToDouble(textBox3->Text);
d = Math::Pow(b,2) - 4 * a * c; // hatványozás művelet is létezik
if (d >= 0) // valós gyökök
{
x1=(-b+Math::Sqrt(d))/(2*a);
x2=(-b-Math::Sqrt(d))/(2*a);
label4->Text = "x1=" + Convert::ToString(x1);
label5->Text = "x2=" + Convert::ToString(x2);
// ellenőrzés
e1 = a * x1 * x1 + b * x1 + c;// igy kevesebbet gépeltünk, mint a Pow-ban
e2 = a * x2 * x2 + b * x2 + c;
label6->Text = "...=" + Convert::ToString(e1);
label7->Text = "...=" + Convert::ToString(e2);
}
IV.2.7. Alapvezérlők: a Button (nyomógomb) vezérlő
A Button vezérlő egy parancsgombot jelöl, amely rákattintáskor „besüllyed”. Ha az aktuálisan kiválasztható funckiók száma alacsony, akkor alkalmazzuk a parancsgombo(ka)t. A funkció lehet bonyolult is, ekkor hosszú függvény tartozik hozzá. A látható vezérlők szokásos tulajdonságait tartalmazza: Text a felirata, Click az esemény, amely a gombra való kattintáskor lefut - ez az alapértelmezett, szokásosan használt eseménye. Az eseménykezelő paraméteréből nem derül ki a kattintás koordinátája. Az eseménykezelő váza:
private: System::Void button1_Click(System::Object^ sender, System::EventArgs^ e) {
}
A Button vezérlő lehetőséget ad arra is, hogy a manapság divatos parancsikonos üzemeltetést alkalmazzuk, feliratok helyett kis ábrákat felhasználva. Ehhez a következő lépésekre van szükség: betöltjük a kis ábrát egy Bitmap típusú változóba, beállítjuk a Button méreteit a bitmap méreteire, végül a gomb Image tulajdonságába betesszük a Bitmap típusú hivatkozást, mint ahogy az alábbi példában történt: a szerviz.png nevű kép a button2 parancsgombon jelenik meg.
Bitmap^ bm;
bm=gcnew Bitmap("szerviz.png");
button2->Width=bm->Width;
button2->Height=bm->Height;
button2->Image=bm;
IV.2.8. Logikai értékekhez használható vezérlők: a CheckBox (jelölő négyzet)
A CheckBox vezérlő egy kijelölő négyzet. Text tulajdonsága a melléírt szöveg (String^ típusú), logikai érték típusú tulajdonsága a Checked, amely true, ha a pipa bekapcsolt állapotban van. A CheckedState tulajdonság háromféle értéket vehet fel: a ki/bekapcsolton kívül létezik egy harmadik, közepes értéke is, amit futás közben csak programból állíthatunk be, viszont jelöltnek minősül. Amennyiben egy Formon több is van a CheckBoxból, ezek függetlenek egymástól: bármelyiket beállíthatjuk bármely logikai állapotúra. Eseménye: a CheckedChanged lefut, amikor a felhasználó a logikai értéket megváltoztatja. Az alábbi mintaprogram egy intervallumfelező program részlete: ha bekapcsoltuk a "Lépésenként" feliratú jelölő négyzetet, egy lépést hajt végre az algoritmusból, ha nincs bekapcsolva, egy ciklussal az eredményt szolgáltatja. Amennyiben lépésenként kezdtük el futtatni a programot, már nem lehet kikapcsolni a pipát: lépésenként kell a további számolást végrehajtani.
switch (checkBox1->Checked)
{
case true:
checkBox1->Enabled = false;
lepes();
break;
case false:
while (Math::Abs(f(xko)) > eps) lepes();
break;
}
kiir();
IV.2.9. Logikai értékekhez használható vezérlők: a RadioButton (opciós gomb)
A RadioButton kör alakú kijelölő. A CheckBox-hoz hasonló, de egy konténerobjektumon (ilyen például a Form is: más objektumokat teszünk bele) belül csak egy lehet aktív közülük. Nevét a régi, hullámváltót tartalmazó rádióról kapta: amikor az egyik gombot benyomtuk, a többi kiugrott. Amikor az egyikre odakerül a kijelölő kör (programból Checked = true, vagy a felhasználó kattintása által), az előzőről (és az összes többiről) lekerül (a Checked tulajdonsága false-ra változik). Text tulajdonságában a kör melletti szöveget tároljuk. Felvetődhet a kérdés, ha egyszerre két opciós listából is kell választani RadioButton-okkal, akkor hogyan oldjuk meg, hiszen csak egy lehet aktív ? A válasz egyszerű: konténerobjektumonként lehet egy aktív RadioButton, így el kell helyezni a formon néhány konténerobjektumot.
IV.2.10. Konténerobjektum vezérlő: a GroupBox (csoport mező)
A GroupBox egy téglalap alakú keret, a bal felső vonalon szöveggel (Text, String ^ típusú). Vezérlőket helyezhetünk el benne, amiket egy keretbe foglal. Ez egyrészt esztétikus, mert a logikailag összefüggő vezérlők keretben jelennek meg, másrészt hasznos a RadioButton típusú vezérlőknél, valamint az itt lévő vezérlők egy utasítással máshova mozgathatók, és eltüntethetők, a GroupBox megfelelő tulajdonságainak állításával. A következő példában osztályozás történik: kevés számú diszkrét elem bevitele és feldolgozása következik:
groupBox1->Text="Progterv-I"; radioButton1->Text="jeles"; radioButton2->Text="jó"; radioButton3->Text="közepes";// más jegyet nem is lehet itt szerezni … int jegy; if (radioButton1->Checked) jegy=5; if (radioButton2->Checked) jegy=4;

IV.2.11. Diszkrét értékeket bevivő vezérlők: a HscrollBar (vízszintes csúszka) és a VscrollBar (függőleges csúszka)
A két vezérlő, amit a magyar fordításokban csúszkának neveznek, csak irányában különbözik egymástól. Feliratuk nincs, amennyiben a véghelyzeteket vagy az aktuális állapotukat jelezni szeretnénk, külön címkék segítségével oldhatjuk meg. Az aktuális érték, ahol a csúszka áll, a Value tulajdonságban található egész numerikus érték, ez a Minimum és a Maximum tulajdonságok közé esik. A Minimum tulajdonságra beállítható a csúszka, ez a bal/felső oldali véghelyzete, a jobb/alsó oldali véghelyzetre viszont egy képlet van, amelyben szerepel a csúszka gyors változtatási egysége, a LargeChange tulajdonság (ennyit akkor változik az érték, amikor egérrel az üres részre kattintunk): Value_max=1+Maximum-LargeChange. LargeChange és SmallChange általunk beállított tulajdonságértékek. A csúszka mozgatásakor a Change esemény fut le, már az aktualizált Value értékkel. A példában 1 bájtos értékeket (0..255) szeretnénk előállitani 3, egyforma méretű vizszintes csúszkával. A csúszkákat beállító programrészlet a Form_Load eseménykezelőben:
int mx; mx=254 + hScrollBar1->LargeChange; // 255-öt szeretnénk a jobb oldali állásban hScrollBar1->Maximum = mx; // 1 bájt max hScrollBar2->Maximum = mx; hScrollBar3->Maximum = mx;
A csúszkák megváltozásakor az értéket kiolvassuk, és egy színt állítunk elő belőlük, és a csúszkák melletti címkékre ellenőrzésképpen kiírjuk az értéket:
System::Drawing::Color c; // szín típusú változó r = hScrollBar1->Value ; // 0..255-ig g = hScrollBar2->Value; b = hScrollBar3->Value; c = Color::FromArgb(Convert::ToByte(r),Convert::ToByte(g),Convert::ToByte(b)); label1->Text = "R=" + Convert::ToString(r); // ki is irathatjuk label2->Text = "G=" + Convert::ToString(g); label3->Text = "B=" + Convert::ToString(b);
IV.2.12. Egész szám beviteli vezérlője: NumericUpDown
A NumericUpDown vezérlővel egy egész számot vihetünk be, ami bekerül a Value tulajdonságba, a Minimum és Maximum értékek közt. A felhasználó egyesével lépkedhet az értékek közt a fel/le nyilakra kattintással. A Minimum és Maximum érték között minden egész szám megjelenik a választható értékek közt. Esemény: ValueChanged lefut, minden változtatás után.
IV.2.13. Több objektumból választásra képes vezérlők: ListBox és a ComboBox
A ListBox vezérlő felkínál egy tetszőlegesen feltölthető listát, amelyből a felhasználó választhat. A ComboBox a listán felül egy TextBox-ot is tartalmaz, amely felveheti a kijelölt elemet, illetve szabadon be is gépelhet a felhasználó egy szöveget, ez a Text tulajdonsága. A lista tulajdonságot Items-nek hívjuk, Add() metódussal bővíthető, és indexelve olvasható. Az aktuális elemre SelectedIndex mutat. Ha megváltozik a kijelölés, lefut a SelectedIndexChanged esemény. A ComboBox vezérlőt több, még bonyolultabb funkciót megvalósító vezérlő is használja: például az OpenFileDialog. A példában a ComboBox listáját feltöltjük elemekkel, amit a label4-ben jelenítünk meg, amennyiben a kijelölt elem megváltozik.
comboBox1->Items->Add("Jeles");
comboBox1->Items->Add("Jó");
comboBox1->Items->Add("Közepes");
comboBox1->Items->Add("Elégséges");
comboBox1->Items->Add("Elégtelen");
private: System::Void comboBox1_SelectedIndexChanged(System::Object^ sender, System::EventArgs^ e) {
if (comboBox1->SelectedIndex>=0)
label4->Text=comboBox1->Items[comboBox1->SelectedIndex]->ToString();
}
IV.2.14. Feldolgozás állapotát mutató vezérlő: ProgressBar
A ProgressBar vezérlővel lehet jelezni egy feldolgozás állapotát, még mennyi van hátra, nem fagyott le a program, dolgozik. Előre tudnunk kell, hogy mikor leszünk készen, mikor kell elérnie a maximumot. A HscrollBar-hoz hasonlóak a vezérlő tulajdonságai, azonban egérrel nem módosítható az érték. Egyes Windows verziók animálják a vezérlőt akkor is, ha konstans értéket mutat. A vezérlőt célszerűen a StatusStrip-ben (állapotsorban) az ablakunk bal alsó sarkában szokásos elhelyezni. Rákattintáskor ugyan lefut a Click eseménye, de ezt nem szokásos lekezelni.
IV.2.15. Pixelgrafikus képeket megjeleníteni képes vezérlő: a PictureBox (képmező)

A vezérlő képes egy képet megjeleníteni. Image tulajdonsága tartalmazza a megjelenitendő Bitmap referenciáját. A Height, Width tulajdonságai a méreteit, a Left, Top tulajdonságai az ablak bal szélétől és tetejétől mért távolságát pixelben tárolják. Célszerű, ha a PictureBox mérete akkora, mint a megjelenítendő bitkép (amelyet szinte bármilyen képfájlból képes betölteni), hogy ne legyen átméretezés. A SizeMode tulajdonság tartalmazza, hogy mit tegyen, ha át kell méretezni a képet: Normal értéknél nincs átméretezés, a bal felső sarokba teszi a képet, amennyiben a Bitmap nagyobb, azt a részt nem jeleníti meg. A StretchImage értéknél a bitképet akkorára méretezi, amekkora a PictureBox. Az AutoSize beállításnál a PictureBox méreteit állítja be a bitkép méreteinek megfelelően. Az alábbi programban egy, az idokep.hu-n található hőmérsékleti térképet jelenítünk meg PictureBox vezérlőben, a SizeMode tulajdonságot a Designer-ben előre beállítva, a képek méretparamétereit label-ben kiíratva:
Bitmap ^ bm=gcnew Bitmap("mo.png");
label1->Text="PictureBox:"+Convert::ToString(pictureBox1->Width)+"x"+
Convert::ToString(pictureBox1->Height)+" Bitmap:"+
Convert::ToString(bm->Width)+"x"+Convert::ToString(bm->Height);
pictureBox1->Image=bm;
A fenti programrészlet futásának eredménye SizeMode=Normal-nál:
SizeMode=StretchImage beállítással. Az arányok sem egyeznek: a térkép téglalap alakú, a PictureBox pedig négyzet:
SizeMode=AutoSize a PictureBox megnőtt, de a Form nem. A formot kézzel kellett átméretezni ekkorára:
SizeMode=CenterImage beállitás: átméretezés nincs, a Bitmap közepe került a PictureBox-ba:
SizeMode=Zoom a bitkép arányait megtartva méretezi át úgy, hogy beférjen az PictureBox-ba:
IV.2.16. Az ablakunk felső részén lévő menüsor: a MenuStrip (menüsor) vezérlő
Amennyiben a programunk annyi funkciót valósít meg, hogy elindításukhoz nagyszámú parancsgombra lenne szükség, célszerű a funkciókat hierarchikusan csoportosítani, és menübe rendezni. Képzeljük csak el, hogy pl. a Visual Studió összes funkcióját parancsgombokkal lehetne működtetni, el sem férne a szerkesztő ablak a sok gombtól. A menü a főmenüből indul, ez mindig látszik a program ablakának tetején, és minden menüelemnek lehet almenüje. A hagyományos menü feliratokat (Text) tartalmaz, de az újabb menüelemek bitképet is meg tudnak mutatni, vagy lehetnek szerkesztésre használható TextBox-ok, ComboBox-ok is. A (nem főmenüben lévő) menüelemek közé elválasztó vonal (separator) tehető, valamint a menüelemek elé kijelölő pipa is kerülhet. A menüelemek a parancsgombokhoz hasonlóan egyedi azonosítót kapnak. Az azonosító lehet általunk begépelt, vagy – a többi vezérlőhöz hasonlóan automatikusan létrehozott. A MenuStrip vezérlő a form alatt jelenik meg, de közben a programunk felső sorában már írhatjuk a menüelem nevét, vagy kiválaszthatjuk a „MenuItem” felirattal az automatikus elnevezést. Az ábrán a menüszerkesztés kezdete látszik, amikor beraktuk a MenuStrip-et:
Válasszunk ki a fenti menübe egy menüelemet!
A főmenüben lévő menüelem neve toolStripMenuItem1 lett. A mellette lévő menüelem (a főmenüben) helyére gépeljük be: Súgó!
Az új menüelem neve súgóToolStripMenuItem lett, viszont a Text tulajdonságát már nem kell beállítani: az már megtörtént. Készítsünk a toolStripMenuItem1 alá három almenüelemet, a harmadik előtt elválasztót használva!
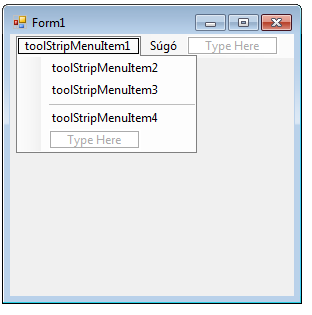
Innentől a programozás ugyanúgy történik, mint a gombok esetén: a form_load függvényben megadjuk a feliratukat (text), majd a szerkesztőben rákattintva megírjuk a Click eseménykezelő függvényt:
private: System::Void toolStripMenuItem2_Click(System::Object^ sender, System::EventArgs^ e) {
// ide kell beírni, hogy mi történjen, ha a menüelemet kiválasztottuk.
}
IV.2.17. Az alaphelyzetben nem látható ContextMenuStrip vezérlő
A MenuStrip vezérlő főmenüje mindig látható. A ContextMenuStrip csak tervezés közben látható, futás közben csak akkor, ha programból megjelenítjük. Célszerű alkalmazása a jobb egérgomb lenyomására az egérmutatónál megjelenő helyi menü. A tervezőben elkészítjük a menü elemeit, a szerkesztőben megírjuk a menüelemek Click eseménykezelőjét, majd a Form MouseDown vagy MouseClick eseménykezelőjében (nekik van koordináta paraméterük) megjelenítjük a ContextMenu-t.
Az alábbi ablak egy ContextMenu-t tartalmaz, három menüelemmel:
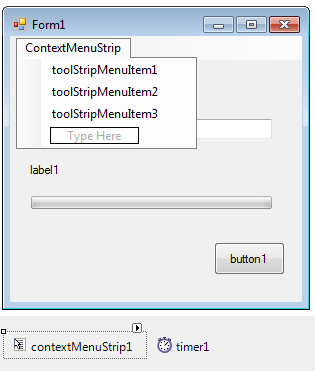
A Form_MouseClick eseménykezelő a következőképpen néz ki:
private: System::Void Form1_MouseClick(System::Object^ sender, System::Windows::Forms::MouseEventArgs^ e) {
if (e->Button == Windows::Forms::MouseButtons::Right)
contextMenuStrip1->Show(this->ActiveForm, e->X, e->Y);
// csak a jobb egérgombra
// mutatjuk a menüt a form-hoz képest.
}
IV.2.18. Az eszközkészlet menüsora: a ToolStrip vezérlő
Az eszközkészlet egymás mellett elhelyezkedő grafikus nyomógombokat tartalmaz. A gombok Image tulajdonsága hivatkozik a megjelenített képre. Miután nyomógombokról van szó, a Click eseményt futtatja le kattintás esetén. Az alábbi ábrán az eszközkészlet elemválasztéka látható, legfelül a képet tartalmazó gomb, amelynek automatikus neve „toolStripButton”-nal kezdődő lesz:
IV.2.19. Az ablak alsó sorában megjelenő állapotsor, a StatusStrip vezérlő
Az állapotsor állapotinformációk megjelenítésére szolgál, emiatt célszerű, ha címkét, és progressbart készítünk hozzá. A ráhelyezett címke neve „toolStripLabel”-lel, a progressbar „toolStripProgressBar”–ral fog kezdődni. Nem szokás kattintani rajta, így nem írjuk meg a Click eseménykezelőket.
IV.2.20. A fileok használatában segítő dialógusablakok: OpenFileDialog, SaveFileDialog és FolderBrowserDialog

Szinte minden program, amelyben a munkánkat el lehet menteni, tartalmaz fájlmegnyitás, -mentés funkciókat. A fájl kijelölése mentésre, vagy beolvasásra minden programban ugyanolyan ablakkal történik. Ugyanis a .NET készítői ezeket a szokásos ablakokat megvalósították vezérlő szintjén. A vezérlőket a tervezési fázisban elhelyezzük a formunk alatt, de a program futása közben csak akkor látszanak, ha programból aktivizáljuk őket. Az aktivizálás a vezérlőobjektum egy metódusával (függvény) történik, a kimenet a dialógus eredménye (DialogResult: OK, Cancel stb). Az alábbi programrészletben kiválasztunk egy .CSV kiterjesztésű fájlt, és megnyitjuk az OpenFileDialog vezérlő segítségével, amennyiben a felhasználó nem a Cancel gombot nyomta le az Open helyett:
System::Windows::Forms::DialogResult dr;
openFileDialog1->FileName = "";
openFileDialog1->Filter = "CSV fileok (*.csv)|*.csv";
dr=openFileDialog1->ShowDialog(); // egy open ablak, csv fájlra
filenev = openFileDialog1->FileName; // kiszedjük a fájl nevét.
if (dr==System::Windows::Forms::DialogResult::OK ) // ha nem cancel-t nyomott
{
sr = gcnew StreamReader(filenev); // olvasásra nyitjuk
A SaveFileDialog használata ugyanilyen, csak azt új fájl mentésére is használhatjuk. A FolderBrowserDialog-gal egy könyvtárat választhatunk ki, amelyben például az összes képet feldolgozhatjuk.
IV.2.21. Az előre definiált üzenetablak: MessageBox
A MessageBox egy üzenetet tartalmazó ablak, amit számunkra a Windows biztosít. Az üzenetablakban a felhasználó választhat egyet a parancsgombok közül. A gombok kombinációi előre definiált konstansok, és az ablak megjelenítésekor argumentumként adjuk meg. A vezérlőt ne keressük a ToolBoxban, nem kell a Formra rajzolni! Ugyanis statikus osztályként lett definiálva, a megjelenítése úgy történik, hogy meghívjuk a Show() metódusát, aminek visszatérési értéke az a gomb, amit a felhasználó megnyomott. Amennyiben biztosak vagyunk benne, hogy csak egy gombot választhat (mert csak az OK gombot tartalmazza a MessageBox), a metódus hívható utasításként is. A programunk futását a MessageBox felfüggeszti: vezérlői nem működnek, az aktuális eseménykezelő nem fut tovább, amíg valamit ki nem választunk a parancsgombok közül. A hívás szintaktikája: eredmény=MessageBox::Show(ablakban található üzenet, ablak fejléce, gombok);, ahol az egyes elemek adattípusai a következők:
eredmény: System::Windows::Forms::DialogResult típusú változó
ablakban található üzenet és az ablak fejléce: String^ tipusú adat
gombok: MessageBoxButtons felsorolás osztály valamelyik eleme, az alábbiak közül:
A MessageBox meghívható egyetlen szöveg argumentummal is, ekkor fejléce nem lesz, és egyetlen „OK” gomb jelenik meg. Nem nevezhető szép megoldásnak.
Az alábbi példát már láttuk, most már értelmezni is tudjuk:
System::Windows::Forms::DialogResult d;
d=MessageBox::Show("Biztos, hogy használni akarja a légzsákot ?”,
"Fontos biztonsági figyelmeztetés",MessageBoxButtons::YesNo);
if (d == System::Windows::Forms::DialogResult::No) e->Cancel=true;
A programrészlet futásának eredménye:
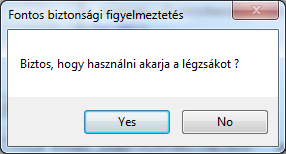
IV.2.22. Az időzítésre használt vezérlő: Timer
A Timer vezérlő programrészlet periodikus futtatását teszi lehetővé, adott időközönként. A form alá rajzoljuk meg a tervezőben, mert futás közben nem látható. Interval tulajdonsága tartalmazza az időközt ezredmásodpercben, míg az Enabled tulajdonságának false-re állításával az időzítő letiltható. Amennyiben engedélyezve van, és az Interval használható értéket tartalmaz (>=20 ms), a Timer lefuttatja a Tick alapértelmezett eseménykezelőjét. A programozónak ügyelnie kell arra, hogy a programrészlet gyorsabban lefusson, mint a következő esemény érkezése (vagyis az idő lejárta). Az alábbi programrészlet felprogramozza a Timer1-et másodpercenkénti futásra:
timer1->Interval=1000; // másodpercenként timer1->Enabled=true; // indulj !
A következő pedig az előbb felprogramozott időzítővel minden másodpercben kiírja az aktuális időt a form fejlécébe:
DateTime^ most=gcnew DateTime(); // idő típusú változó. most=most->Now; // most mennyi idő van ? this->Text=Convert::ToString(most); // form fejlécébe írjuk.
Ez a programrészlet továbbfejleszthető úgy, hogy ha (most->Minute==0) && (most->Second == 0), játssza le a kakukk.wav, 1sec-nél hosszabb hangfájt. Amennyiben úgy érezzük, hogy nem kell többször futnia, a Tick eseményben is kiadható az Enabled=false, ekkor a mostani esemény volt az utolsó.
IV.2.23. A SerialPort
A SerialPort vezérlő az rs-232-es szabványú soros port és a rákapcsolt periféria (modem, SOC, mikrokontroller, Bluetooth eszköz) közti kommunikációt teszi lehetővé. A portot fel kell paraméterezni, majd kinyitni. Ezután szöveges információkat (Write,WriteLine,Read,ReadLine) , valamint bináris adatokat (WriteByte, ReadByte) küldhetünk és fogadhatunk. Eseménykezelő függvény is rendelkezésre áll: amennyiben adat érkezik, a DataReceived esemény fut le. Az alábbi programrészlet végignézi az összes fellelhető soros portot, az "iCorset" nevű hardvert keresve, a "?" karakter kiküldésével. Ha nem találja meg, hibaüzenettel kilép. A virtuális soros portoknál (USB) a BaudRate paraméter értéke tetszőleges.
array<String^>^ portnevek;
bool vezerlo_van=false;
int i;
portnevek=Ports::SerialPort::GetPortNames();
i=0;
while (i<portnevek->Length && (!vezerlo_van))
{
if (serialPort1->IsOpen) serialPort1->Close();
serialPort1->PortName=portnevek[i];
serialPort1->BaudRate=9600;
serialPort1->DataBits=8;
serialPort1->StopBits=Ports::StopBits::One;
serialPort1->Parity = Ports::Parity::None;
serialPort1->Handshake = Ports::Handshake::None;
serialPort1->RtsEnable = true;
serialPort1->DtrEnable = false;
serialPort1->ReadTimeout=200; // 0.2 s
serialPort1->NewLine="\r\n";
try {
serialPort1->Open();
serialPort1->DiscardInBuffer();// usb !
serialPort1->Write("?");
s=serialPort1->ReadLine();
serialPort1->Close();
} catch (Exception^ ex) {
s="Timeout";
}
if (s=="iCorset") vezerlo_van=true;
i++;
}
if (! vezerlo_van) {
MessageBox::Show("No iCorset Controller.",
"Error",MessageBoxButtons::OK);
Application::Exit();
}
IV.3. Szöveges, bináris állományok, adatfolyamok.
Számítógépünk operatív tára kisméretű (a tárolni kívánt adatmennyiséghez képest), és könnyen felejt: ki sem kell kapcsolni a számítógépet, elég kilépni a programból, és a memóriában tárolt változók értéke máris elvész. Emiatt már az első számítógépek, amelyek a ferritgyűrűs tárolók után készültek, háttértárat alkalmaztak, amelyen az éppen nem használt programokat, és az éppen nem használt adatokat tárolták. A tárolási egység a lemezfájl, amely logikailag összefüggő adatok összessége. A logikai fájl a lemez fizikai szervezésével való összekapcsolása, a programok számára az elérés biztosítása, a fájlrendszer kialakítása és kezelése az operációs rendszer feladata. Az alkalmazói programok a lemezfájlokra nevükkel hivatkoznak. A műveletek elkülönülnek aszerint, hogy kezeljük-e a fájl tartalmát, vagy sem. Például, egy fájl átnevezéséhez, vagy letörléséhez nem szükséges a tartalmának kezelése, elég a neve. A fájl neve tartalmazhatja az elérési utat is, ha nem tartalmazza, fejlesztés alatt a projektünk könyvtára az alapértelmezett, míg a lefordított program futtatásakor az exe fájl könyvtára az alapértelmezett.
IV.3.1. Előkészületek a fájlkezeléshez
Ellentétben a grafikával vagy a vezérlőkkel, a fájlkezelő névtér nem kerül be a formunkba, az új projekt készítésekor. Ezt nekünk kell megadni, a form1.h azon részében, ahol a többi névteret:
using namespace System::IO;
További teendő eldönteni, hogy mit tartalmaz a kezelendő fájl, és mit szeretnénk vele tenni:
Csak törölni, átnevezni, másolni szeretnénk, megvizsgálni a létezését.
Bájtonként (bájtokat tartalmazó blokként) szeretnénk kezelni, ha „buherátorok” vagyunk: vírusfelismerés, karakterkódolás stb.
Bináris fájl ismert, állandó hosszúságú rekordszerkezettel.
Szövegfájl, változó hosszúságú szövegsorokból, a sorok végén soremeléssel.
A fájl neve is kétféleképpen adható meg:
Beírjuk a programunkba a fájlnevet, „bedrótozzuk”. Ha csak saját magunknak készítjük mindig ugyanazt a fájlt használva, akkor egyszerű és gyors módszer a névmegadásra.
OpenFileDialog-ot vagy SaveFileDialog-ot használva (lásd IV.2.20. szakasz - A fileok használatában segítő dialógusablakok: OpenFileDialog, SaveFileDialog és FolderBrowserDialog) a felhasználó kijelölheti a fájlt, amelyet kezelünk. Ilyenkor a fájl nevét a dialógusablakok FileName tulajdonsága tárolja.
IV.3.2. A statikus File osztály metódusai
bool File::Exists(String^ fájlnév) A fájlnévben megadott állomány létezését vizsgálja, amennyiben létezik, true a kimenet, amennyiben nem, false. Használatával elejét vehetjük néhány hibának: nem létező fájl megnyitása, fontos adatfájl véletlen felülírása.
void File::Delete(String^ fájlnév) Törli a megadott nevű állományt. A mai operációs rendszerekkel ellentétben a törlés nem egy „kuka”-ba való mozgatást jelent, hanem tényleges törlést.
void File::Move(String^ réginév, String^ újnév) A réginév-vel megadott lemezfájlt átnevezi az újnévre. Amennyiben a nevekben különböző elérési út található, az állomány másik könyvtárba kerül.
void File::Copy(String^ forrásfájl, String^ célfájl) A Move-hoz hasonló metódus, azzal a különbséggel, hogy a forrásfájl nem tűnik el, hanem megduplázódik. A lemezen egy új fájl jön létre, a forrásfájl tartalmával.
FileStream^ File::Open(String^ fájlnév,FileMode üzemmód) A fájlnév nevű állomány megnyitása. A FileStream^ nem gcnew-val kap értéket, hanem ezzel a metódussal. A szövegfájlnál nem kell használni, de az összes többi fájlnál (a bájtokat tartalmazó és a rekordokat tartalmazó bináris) is ezt kell alkalmazni. Az üzemmód értékei:
FileMode::Appenda szövegfájl végére állunk, és írás üzemmódot kapcsolunk be. Ha a fájl nem létezik, új fájl készül.FileMode::Createez a mód új fájlt készít. Ha a fájl már létezik, felülíródik. Az elérési út könyvtárában az aktuális felhasználónak írási joggal kell rendelkeznie.FileMode::CreateNewez a mód is új fájlt készít, de ha a fájl már létezik, nem írja felül, hanem kivételt kapunk.FileMode::Openlétező fájl megnyitása, írásra/olvasásra. Általában, ha már a fájl készítésen túl vagyunk, pl. a FileOpenDialog után ezt az üzemmódot használjuk.FileMode::OpenOrCreatea létező fájlt megnyitjuk, ha nem létezik, készítünk egy adott nevű fájlt.FileMode::Truncatemegnyitjuk a létező fájlt, és a tartalmát töröljük. A fájl hossza 0 bájt lesz.
IV.3.3. A FileStream referencia osztály
Amennyiben a fájlokat bájtonként, vagy binárisként kezeljük, deklaráljunk egy a fájl eléréséhez egy FileStream-et. A FileStream típusú osztálypéldányt nem gcnew-val hozzuk létre, hanem File::Open()-nel, ezáltal a fizikai lemezfájl és a FileStream összerendelődnek. A FileStream segítségével a lemezfile aktuális filepozíciója elérhető, és mozgatható. A pozíció és a mozgatás mértékegysége a bájt, adattípusa 64-bites egész, hogy 2 gigabájtosnál nagyobb fájlokat is kezelni tudjon. Gyakran használt tulajdonságai és metódusai:
Length: olvasható tulajdonság, fájl aktuális mérete bájtban.
Name: a lemezfájl neve, amit megnyitottunk.
Position: írható/olvasható tulajdonság, az aktuális fájlpozíció bájtban. A következő írási művelet erre a pozícióra fog írni, a következő olvasás innen fog olvasni.
Seek(mennyit, mihez képest) metódus a fájlpozíció mozgatására. A Position tulajdonsághoz képest megadható, hogy honnan értelmezzük az eltolást: a fájl elejétől (
SeekOrigin::Begin), az aktuális pozíciótól (SeekOrigin::Current) , a fájl végétől (SeekOrigin::End). Ezt a műveletet kell akkor is használni, ha a FileStream-re BinaryReader-t vagy BinaryWriter-t kapcsolunk, azoknak nincsSeek()metódusa.int ReadByte(),WriteByte(unsigned char)egy bájtnyi adatot olvasó, illetve író metódusok. Az irás/olvasás az aktuális pozícióban történik. Az operációs rendszer szintjén a fájlolvasás egy bájt típusú tömbbe történik, mert ezek a függvények egy egyelemű, bájtokat tartalmazó tömb olvasásaként vannak megvalósítva.int Read(array<unsigned char>,eltolás,darab): bájt típusú tömb beolvasó metódus. Az olvasott adatok az eltolás indexű elemnél kezdődnek, és darab számú lesz belőlük. Visszatérő értéke, hogy hány bájtot sikerült olvasni.Write(array<unsigned char>,eltolás,darab): bájt típusú tömböt kiíró metódus. Az írást az eltolás indexű elemnél kezdi, és darab számú elemet ír ki.Flush(void): a buffereket aktualizálja, ha még a memóriában voltak adatok, kiírja a lemezre.Close():a FileStream bezárása. A fájlokat használat után mindig be kell csukni, hogy elkerüljük az adatvesztést és az erőforrások kifogyását.
IV.3.4. A BinaryReader referencia osztály
Amennyiben nem bájt típusú bináris adatokat szeretnénk fájlból olvasni, a megnyitott FileStream-et argumentumként megadva a konstruktorban BinaryReader-t használunk. A BinaryReader-t a szabványos gcnew operátorral hozzuk létre. Fontos megjegyezni, hogy a BinaryReader nem képes megnyitni a lemezfájlt, és hozzárendelni a FileStream-hez. A BinaryReader az alapvető adattípusokhoz tartalmaz metódusokat: ReadBool() , ReadChar(), ReadDouble(), ReadInt16(), ReadInt32(), ReadInt64(), ReadUInt16(), ReadString(), ReadSingle() stb. A file pozíció az olvasott adat hosszával inkrementálódik. A BinaryReader-t is be kell csukni használat után a Close() metódusával, a FileStream bezárása előtt.
IV.3.5. A BinaryWriter referencia osztály
Amennyiben bináris adatokat szeretnénk kiírni a FileStream-be, a BinaryWriter-t használjuk. Létrehozása a BinaryReader-hez hasonlóan, gcnew operátorral történik. A különbség annyi, hogy míg a Reader adott visszatérő adattípusú metódusokat tartalmaz, a Writer adott paraméterű, visszatérő érték nélküli metódust tartalmaz, nagyszámú túlterhelt változatot. A metódus neve Write, és többféle adattípussal hívható, bonyolultsági sorrendben a Bool-tól a cli::Array^ -ig. A bináris fájlkezelés összefoglaló ábrája az alábbiakban látható:
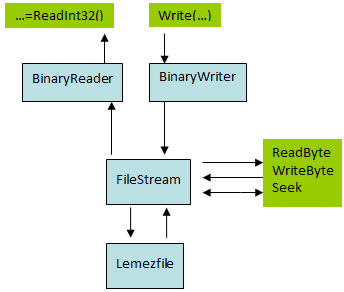
IV.3.6. Szövegfájlok kezelése: StreamReader és StreamWriter referencia osztályok
Az előzőekben tárgyalt bináris fájlok állandó hosszúságú rekordokból állnak, így a programunk egy egyszerű szorzás művelettel ki tudja számítani, hogy hányadik bájton kezdődik a keresett adat a fájlban, és a seek() művelettel oda tud állni. Például 32-bites egész típusú adat tárolásánál, amely 4 bájtot foglal, a 10-es indexű adat (igazából a 11. adat) a 10*4=40-edik bájton kezdődik. Ekkor – mivel a filemutatót bárhova mozgathatjuk – tetszőleges (random) elérésről beszélünk. A bináris fájlokat csak az a program tudja feldolgozni, aki ismeri a rekordszerkezetét, vagyis általában az a program, ami létrehozta.
A szövegfájlok változó hosszúságú, ember által is olvasható sorokból állnak. A fájlban a karakterek ASCII, Unicode, UTF-8 stb. kódolással tárolódnak, a szöveges állomány egy sora a fordító String^ adattípusának felel meg. A sorok végén CR/LF (két karakter) található DOS/Windows alapú rendszereknél. A változó sorhossz miatt a szövegfájlok csak szekvenciálisan kezelhetők: a 10. sor beolvasása úgy történik, hogy a fájl elejéről beolvasunk 9 sort, majd a nekünk kellő 10-ediket. A fájl megnyitása után nem tudjuk megmondani, hogy a fájlban hányadik bájton kezdődik a 10. sor, csak végigolvasás után.
A szöveges állományok fontos alkalmazása a különböző programok közti kommunikáció. Mivel olvashatók például Jegyzettömbbel, képesek vagyunk feldolgozni egy másik program által készített szövegfájlt. A szövegfájlokat használják például az adatbáziskezelők mentésre (ott dumpnak hívják a szövegfájlt, ami SQL utasításokat tartalmaz, amik a lementett adatbázist egy üres rendszeren létrehozzák), az Excellel való kommunikációra (a vesszővel vagy tabulátorral elválasztott fájl-ok CSV kiterjesztéssel), valamint az e-mailek is szövegfájlként mennek a küldő és a fogadó szerver között. A mérőberendezések is gyakran készítenek a mérésből valamilyen szöveges fájlt, amelyben soronként egy mérési adat szerepel, hogy tetszőleges programmal (akár Excellel) a mérést végző felhasználó feldolgozhassa, kirajzolhassa az eredményeket.
A szövegfájlok kezelését a StreamReader és a StreamWriter típusú referencia változókkal oldhatjuk meg. A gcnew operátor után a konstruktorban a fájl nevét adhatjuk meg, nem kell FileStreamet definiálnunk. Ennek oka, hogy a StreamReader és a StreamWriter kizárólagosan használja a lemezfájlt, emiatt elkészítheti magának a saját FileStreamjét (BaseStream), amivel a programozónak nem kell foglalkoznia. A StreamReader leggyakrabban használt metódusa a ReadLine(), amely a szövegfájl következő sorát olvassa be, és leggyakrabban használt tulajdonsága az EndOfStream, amely a fájl végén igazzá válik. Vigyázat: az EndOfStream az utolsó olvasás állapotát mutatja, a fájl végén a ReadLine() nulla hosszúságú sztringgel tér vissza, és az EndOfStream értéke true lesz! Vagyis a szokásos elöltesztelt ciklus használható (while (! StreamReader->EndOfStream) …), csak a beolvasás után meg kell vizsgálni, hogy a beolvasott sztring hossza nagyobb-e, mint 0. A StreamWriter leggyakrabban használt metódusa a WriteLine(String), amely a paraméterként megkapott sztringet és egy soremelést kiír a textfájlba. Létezik még Write(String) is, amely nem ír soremelést. A soremelés (CR,LF,CR/LF) beállítható a NewLine tulajdonsággal.
Az alábbi, önállóan, segédfüggvények és inicializáló rész nélkül nem működő programrészlet egy CSV kiterjesztésű, pontosvesszőkkel elválasztott sorokból álló szövegfájlt dolgoz fel. A felhasználóval kijelölteti a feldolgozandó fájlt, beolvassa az adatokat soronként, valamit kiszámol az adatokból, majd a beolvasott sor végére írja az eredményt. A feldolgozás végén számol egy összesített eredményt is. Az összes kimenetet egy átmeneti fájlba írja, hiszen az eredeti szövegfájl olvasásra van nyitva. Ha kész a feldolgozás, az eredeti fájlt letörli, és az átmeneti fájlt átnevezi az eredeti nevére. Eredmény: az eredeti szövegfájlba belekerültek a számítás eredményei.
private: System::Void button1_Click(System::Object^ sender, System::EventArgs^ e) {
int m, kp, jegy, ok = 0, oj = 0;
System::Windows::Forms::DialogResult dr;
String^ targy, ^sor, ^kiir = "";
openFileDialog1->FileName = "";
openFileDialog1->Filter = "CSV fileok (*.csv)|*.csv";
dr=openFileDialog1->ShowDialog(); // egy open ablak, csv file-ra
filenev = openFileDialog1->FileName; // kiszedjük a fájl nevét.
if (dr==System::Windows::Forms::DialogResult::OK ) // ha nem cancel-t nyomott
{
sr = gcnew StreamReader(filenev); // olvasásra
sw = gcnew StreamWriter(tmpnev); // írásra nyitom meg
while (!sr->EndOfStream) // mindig elöltesztelttel
{
sor = sr->ReadLine(); // beolvasunk egy sort.
if ((sor->Substring(0,1) != csk) && (sor->Length > 0))
// ha nem elválasztó : feldolgozzuk
{
m = 0; // minden sort az első karaktertől nézzük
targy = ujadat(sor, m); // szétszedjük a sorokat
kp = Convert::ToInt32(ujadat(sor, m)); // 3 részre
jegy = Convert::ToInt32(ujadat(sor, m));
// kiiratást készítünk címkébe
kiir = kiir + "tárgy:"+targy + " kredit:" +
Convert::ToString(kp) +" jegy:" +
Convert::ToString(jegy) + "\n";
// és súlyozott átlagot számolunk
ok = ok + kp;
oj = oj + kp * jegy;
sw->WriteLine(sor+csk+Convert::ToString(kp*jegy));
} else { // nem dolgozzuk fel, de visszaírjuk.
sw->WriteLine(sor);
} // if
} // while
sr->Close(); // ne felejtsük el bezárni
sa = (double) oj / ok; // különben az eredmény egész.
// az előző végén \n volt, új sorba írjuk az eredményt
kiir = kiir + "súlyozott átlag:" + Convert::ToString(sa);
label1->Text = kiir; // ékezetből baj lenne. utf-8
sw->WriteLine(csk + "sulyozott atlag"+ csk+Convert::ToString(sa));
sw->Close(); // a kimenetit is bezárom,
File::Delete(filenev); // a régi adatfile-t letörlöm
// és az átmenetit átnevezem az adatfile nevére.
File::Move(tmpnev, filenev);
}
}
IV.3.7. A MemoryStream referencia osztály
Készíthetünk olyan szekvenciális, bájtokból álló fájlt, amely nem a lemezen található, hanem a memóriában. A memóriában létrehozott adatfolyamnak nagy előnye a sebessége (a memória legalább egy nagyságrenddel gyorsabb, mint a háttértár), hátránya a kisebb méret, és az a tulajdonság, hogy a programból való kilépéskor tartalma elvész. A MemoryStream-nek ugyanazok a metódusai, mint a FileStream-nek: egy bájtot vagy bájtokból álló tömböt írhatunk/olvashatunk a segítségével. Létrehozása a gcnew operátorral történik, megadható paraméteres konstruktor, ekkor beállíthatjuk a MemoryStream maximális méretét. Amennyiben nem adtunk meg paramétert, a MemoryStream dinamikusan foglal memóriát az írás műveletnél. Az osztály használatának két előnye van a tömbhöz képest: az automatikus helyfoglalás, valamint ha kinőnénk a memóriát, a MemoryStream könnyen FileStream-mé alakítható át, a gcnew helyett File::Open() utasítással.
IV.4. A GDI+
A GDI Graphics Device Interface a Windows rendszerek eszközfüggetlen, 2D-s grafika készítéséhez és megjelenítéséhez (nyomtatón, képernyőn) használt modulja (gdi.dll, gdi32.dll). A GDI+ ennek a modulnak a továbbfejlesztett – először a Windows XP és a Windows Server 2003 operációs rendszerekben megjelent – szintén 2D-s változata (GdiPlus.dll). Az újabb Windows rendszerek biztosítják a kompatibilitást a régebbi verzióhoz készült programokkal, a programozók azonban a GDI+ optimalizált, örökölt és új funkcióit is használhatják.
IV.4.1. A GDI+használata
A GDI+ objktum-orientált szemlélettel készült, azaz egy olyan 32/64 bites grafikai programozási felület, mely C++ osztályokat kínál a rajzoláshoz akár menedzselt (.NET), akár nem menedzselt (natív) programokban. A GDI nem közvetlenül a grafikus hardverrel, hanem annak meghajtó-programjával tartja a kapcsolatot. A GDI egyaránt alkalmas 2D-s vektorgrafikus ábrák rajzolására, képek kezelésére és kiadványok szöveges információinak rugalmas megjelenítésére:
A 2D-s vektorgrafika. A rajzok készítésekor koordináta-rendszerekben megadott pontok által meghatározott egyeneseket, görbéket és ezek által határolt alakzatokat rajzolhatunk tollakkal és festhetünk ki ecsetekkel.
Képek tárolására és megjelenítése. A rugalmas képtárolási és képkezelési lehetőségek mellett többféle képformátum (BMP, GIF, JPEG, Exif, PNG, TIFF, ICON, WMF, EMFll) beolvasására és mentésére van lehetőség.
Szövegek megjelenítése. A rengeteg betűtípus megjelenítése képernyőn és nyomtatón a GDI+ rendszer feladata.
A GDI+ alapfunkcióit a System::Drawing névtér tartalmazza. A 2D-s rajzolás további lehetőségeit elérhetjük a
System::Drawing::Drawing2D
névtér elemeivel. A képek haladószintű kezeléséhez tartalmaz osztályokat a
System::Drawing::Imaging
, míg a
System::Drawing::Text
névtér a szöveges megjelenítés speciális lehetőségeit biztosítja.
[4.1.]
IV.4.2. A GDI rajzolási lehetőségei
Ahhoz, hogy programunkban elérjük a GDI+ alapfunkcióit használjuk a System::Drawing névteret! (Ennek eléréséhez a referenciák között – Project / Properties / References: - szerepelnie kell a System.Drawing DLL állománynak.).
using namespace System::Drawing;
A System::Drawing névtér tartalmazza a rajzoláshoz szükséges osztályokat (IV.30. ábra - A GDI+ osztályai ). Kiemelést érdemel a Graphicsosztály, amelyik – mint egy rajzlap – a rajzolási felületet modellezi. A rajzlapon való rajzoláshoz szükséges néhány adatstruktúra, amelyeket a szintén System::Drawing névtér definiál. A rajzlapon megadhatjuk, hogy milyen koordináta-rendszert használunk. A GDI+ színmodellje az alfa-r-g-b modell (a Color struktúra), ami azt jelenti, hogy színeket nemcsak a hagyományos piros, zöld, kék színből keverhetünk, hanem a szín átlátszóságát is beállíthatjuk az alfa paraméterrel. Pontok egész típusú x és y koordinátáit tárolhatjuk a Point típusú struktúrákban, valós (float) kordináták esetében a PointF használható. A pontokhoz hasonlóan típusfüggően használhatjuk a Rectangle és RectangleF struktúrákat a téglalapok átellenes sarokpontjainak többféle módon való elérésére és tárolására. Alakzatok vízszintes és függőleges méreteinek tárolását segítik a Size és SizeF struktúrák. Az igazi rajzeszközöket osztályok modellezik. Alapvető rajzeszközünk a toll (nem örököltethető Pen osztály) melynek beállíthatjuk a színét, a vastagságát és a mintázatát. A síkbeli alakzatok kifestésének eszköze az ecset (Brush ősosztály). A Brush leszármazottai az egyszínű festékbe „mártható” ecset modellje a SolidBrush és a bitkép mintázatú nyomot hagyó TextureBrush. A HatchBrush sraffozott mintát fest, míg a színjátszó festéknyomot hagynak a LinearGradientBrush és a PathGradientBrush. Utóbbi osztályok használatához a
System::Drawing::Drawing2D
névtér is szükséges. A leszármazott ecseteket nem örököltethetjük tovább. Az Image absztrakt osztály bitképek és metafájlok tárolására, kezelésére szolgáló adattagokkal és tagfüggvényekkel rendelkezik. A Font osztály tartalmazza a karakterek különböző megjelenítési formáit, a betűtípusokat. A FontFamily a betűtípuscsaládok modellje. Sem a Font, sem a FontFamily nem örököltethető tovább. A Region (nem örököltethető) osztály a grafikus eszköz téglalapok oldalaival és törtvonalak által határolt területét modellezi. Az Icon osztály a Windows ikonok (kisméretű bitképek) kezelésére szolgáló osztály.

IV.4.3. A Graphics osztály
Mielőtt közelebbről megismerkednénk a Graphics osztállyal, néhány szót kell ejteni a vezérlők Paint eseményéről. Az ablakokban megjelenő grafikus objektumokat gyakran újra kell rajzolni, például újrafestéskor. Ez úgy történik, hogy az újrarajzoláshoz a Windows automatikusan érvényteleníti az újrafesteni kívánt területet, és meghívja az objektumok Paint eseményének kezelő függvényét. Ha tehát azt szeretnénk, hogy az általunk készített rajz a takarásból előbukkanó objektumokon frissüljön, akkor a Graphics osztály rajzoló metódusait a Paint esemény kezelőjében kell elhelyeznünk. A Paint eseménykezelőknek van egy PaintEventArgs típusú referencia-paramétere, amit a Windows a híváskor definiál
[4.2.]
;
private: System::Void Form1_Paint(
System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e){ }
A PaintEventArgs osztály két tulajdonsága a Rectangle típusú ClipRectangle, amely az újrafestendő terület befoglaló adatait tartalmazza, és a Graphics típusú csak olvasható Graphics, amelyik az újrafestés során rajzeszközként használható rajzlapot azonosítja.
A későbbiekben részletesebben is megmutatjuk azt, hogy a rajzoláshoz Pen típusú tollat kell létrehoznunk a gcnew operátorral, mely a konstruktorának paramétereként megadható a toll színe a System::Drawing névtér Color::Red konstansával. Ha már van tollunk, akkor azzal a Graphics osztály Line() metódusa vonalat rajzol (IV.31. ábra - A rajzolt vonal minden átméretezés után automatikusan megjelenik).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e){
Pen ^ p= gcnew Pen(Color::Red);
e->Graphics->DrawLine(p,10,10,100,100);
}
A programban bárhol kezdeményezhetjük mi is az ablakok és a vezérlők újrafestését. A Control osztály Invalidate(), Invalidate(Rectangle) és Invalidate(Region) metódusai érvénytelenítik az egész ablakot / vezérlőt, illetve annak kijelölt területét, és aktiválják a Paint eseményt. A Control osztály Refresh() metódusa érvényteleníti az ablak / vezérlő területét, és azonnali újrafestést kezdeményez.
Az ablakra bárhonnan rajzolhatunk a programból, ha magunk készítünk rajzlappéldányt a Graphics osztályból a tartalmazó vezérlő / ablak CreateGraphics() metódusával. Ekkor azonban csak egyszer jelenik meg a kék tollal rajzolt a vonal, és takarás után eltűnik.
Pen ^ p= gcnew Pen(Color::Blue);
Graphics ^ g=this->CreateGraphics();
g->DrawLine(p,100,10,10,100);
Az adott rajzlapot a megadott háttérszínnel törölhetjük a Graphics osztály
Clear(Color & Color);
metódusával
IV.4.4. Koordináta-rendszerek
A GDI+ segítségével három koordináta-rendszerben is gondolkodhatunk. A világ koordináta-rendszer az, amiben elkészíthetjük modellünket, amit 2D-ben szeretnénk lerajzolni. Olyan leképezést célszerű használni, melyben a rajzoló metódusoknak ezeket a világkoordinátákat tudjuk átadni. Mivel a Graphics osztály rajzoló metódusai egész számok (int) és lebegőpontos valós (float) számokat képesek paraméterként fogadni, ezért célszerű a világkoordinátákat is int vagy float típussal tárolni. A 3D-s világ síkba való leképezéséről magunknak kell gondoskodnunk. A lap koordináta-rendszer az, amit a Graphics típusú referencia által modellezett rajzlap használ, legyen az form, képtároló, vagy akár nyomtató. Az eszköz koordináta-rendszere az, amit az adott eszköz használ (például a képernyő bal felső sarka az origó, és a pixelek az egységek). Rajzoláskor tehát két leképezés is végbemegy:
világ_koordináta → lap_koordináta → eszköz_koordináta
Az első leképezést magunknak kell elkészíteni. Erre több lehetőségünk is van. Térbeli pontokat két alapvető módon vetíthetünk síkba párhuzamos és centrális vetítősugarakkal.
A párhuzamos sugarakkal való vetítést axonometriának hívjuk. A vetítés matematikai modelljét úgy állíthatjuk fel, hogy az x-y-z térbeli koordináta-rendszer párhuzamosan vetített képét berajzoljuk a ξ-η koordináta-rendszerrel bíró síkbeli lapra. Feltételezzük, hogy a térbeli koordináta-rendszer origójának képe a síkbeli koordináta-rendszer origója. Az (IV.33. ábra - Az általános axonometria) ábrán az az x-y-z térbeli koordináta-rendszer képe szaggatott vonallal látszik a folytonos vonallal rajzolt ξ-η koordináta-rendszerben. Jelöljük az IV.33. ábra - Az általános axonometria szerint a ξ-tengely és az x-tengely által bezárt szöget α-val, a ξ-tengely és az y-tengely által bezárt szöget β-val valamint az η-tengely és a z-tengely által bezárt szöget γ-val! Mivel az x-y-z koordináta-tengelyek nem párhuzamosak a ξ-η síkkal, a koordináta-egységek képe a síkon rövidebbnek látszik. Az x-irányú egység q x (≤1)-nek, az y-irányú egység q y (≤1) és a z-irányú egység q z (≤1) hosszúnak látszik.
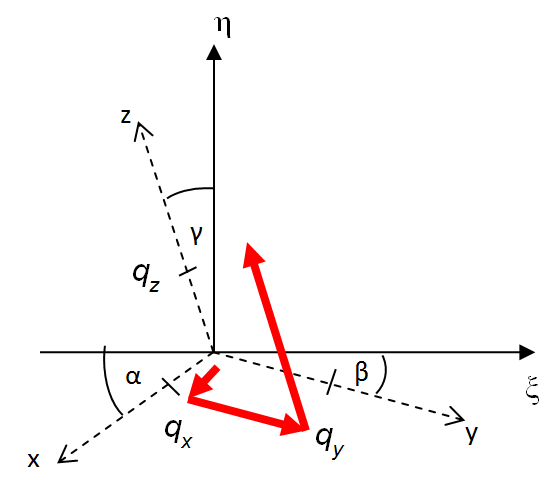
Ha tehát egy (x,y,z) koordinátájú pontjának keressük a (ξ,η) síkbeli, leképzett koordinátáit, akkor a leképezést megvalósító függvénypár az (f ξ , f η ) (IV.4.1) szerint.
|
|
(IV.4.1) |
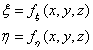
A leképezést egyszerűen felírhatjuk, ha arra gondolunk, hogy az origóból indulva a koordináta-tengelyek képeivel párhuzamosan, a rövidüléseknek megfelelően haladunk x, y és z egységnyit, akkor az (x, y, z) pont (ξ, η) képébe jutunk (IV.33. ábra - Az általános axonometria). Ebből következik, hogy a piros nyíllal ξ és az η irányú vetületeit összegezve az alábbi (IV.4.2) módon adódnak a koordináták.
|
|
(IV.4.2) |
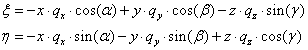
Az axonometria speciális esete az izometrikus axonometria, amikor az x-y-z koordináta-tengelyek egymással 120°-os szöget zárnak be, a z-tengely képe az η-tengellyel esik egybe (α=30, β=30, γ=0) és a rövidülések q x =q y =q z =1 (IV.34. ábra - Az izometrikus axonometria)
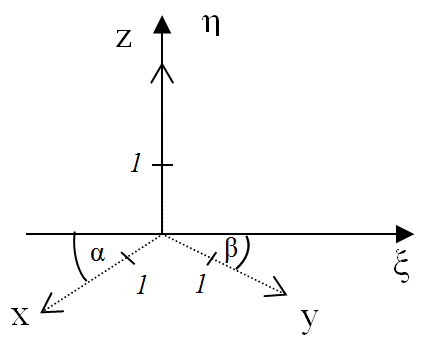
Másik elterjed axonometria a Cavalier-féle, vagy katonai axonometria, ahol a vízszintes y-tengely, a ξ-tengellyel esik egybe a függőleges z-tengely, az η-tengellyel esik egybe, az x-tengely pedig a másik kettővel 135°-os szöget zár be (α=45, β=0, γ=0). A rövidülések: q x =0,5, q y =q z =1.
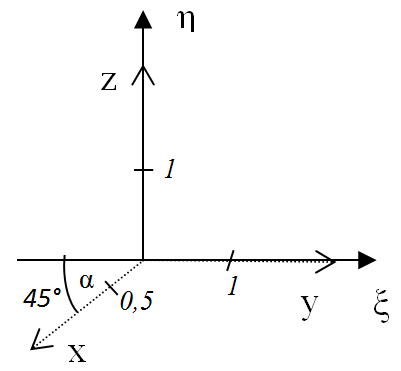
Alaphelyzetben a lap 2D-s koordináta-rendszerének origója – form esetében – a form aktív területének bal felső sarkában van, az x-tengely jobbra, az y-tengely pedig lefelé mutat, és mindkét tengelyen pixelek az egységek (IV.36. ábra - A 2D-s koordinátarendszer).
Tehát amíg másképpen nem intézkedünk, a Graphics osztály már megismert DrawLine() metódusának paraméterei ebben a koordináta-rendszerben megadott értékek.
Példaként készítsük el a Cavalier-féle axonometria leképezését elkészítő függvényt! Ennek bemenő paraméterei a térbeli koordináták (x, y, z), a (IV.4.2) képlettel a Cavalier axonometria konstansait behelyettesítve a leképezés PointF típusú lappontot ad vissza.
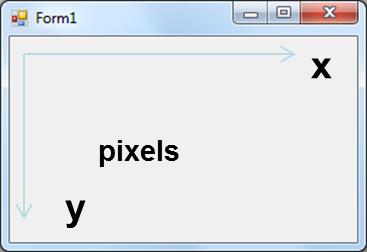
PointF Cavalier(float x, float y, float z) {
float X = 0;
float Y = 0;
X=(-x*(float)Math::Sqrt(2)/2/2+y);
Y=(-x*(float)Math::Sqrt(2)/2/2+z);
return PointF(X, Y);
}
Példaként, a Cavalier függvényt és a Graphics osztály DrawLine() metódusát alkalmazva, rajzoljunk a Paint eseményben egy (250,250,250) középpontú 100 oldalú kockát axonometriában ábrázolva!
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
// a középpont és a fél oldal
float ox=250;
float oy=250;
float oz=250;
float d=50;
// A piros toll
Pen ^p=gcnew Pen(Color::Red);
// A felső lap
e->Graphics->DrawLine(p,Cavalier(ox-d,oy-d,oz-d),
Cavalier(ox+d,oy-d,oz-d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy-d,oz-d),
Cavalier(ox+d,oy+d,oz-d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy+d,oz-d),
Cavalier(ox-d,oy+d,oz-d));
e->Graphics->DrawLine(p,Cavalier(ox-d,oy+d,oz-d),
Cavalier(ox-d,oy-d,oz-d));
// Az alsó lap
e->Graphics->DrawLine(p,Cavalier(ox-d,oy-d,oz+d),
Cavalier(ox+d,oy-d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy-d,oz+d),
Cavalier(ox+d,oy+d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy+d,oz+d),
Cavalier(ox-d,oy+d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox-d,oy+d,oz+d),
Cavalier(ox-d,oy-d,oz+d));
// Az oldalélek
e->Graphics->DrawLine(p,Cavalier(ox-d,oy-d,oz-d),
Cavalier(ox-d,oy-d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy-d,oz-d),
Cavalier(ox+d,oy-d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox+d,oy+d,oz-d),
Cavalier(ox+d,oy+d,oz+d));
e->Graphics->DrawLine(p,Cavalier(ox-d,oy+d,oz-d),
Cavalier(ox-d,oy+d,oz+d));
}
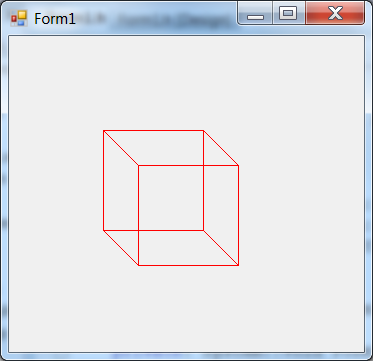
Az ábrán (IV.37. ábra - Kocka axonometriában) jól látható, hogy az axonometrikus leképzés adott koordinátairányban távolságtartó. Ezért a kocka hátsó éle ugyanolyan hosszúnak látszik, mint az első él. A szemünkkel azonban nem ilyen képet kapunk. A szemünk centrálisan vetít.
Centrális vetítés egy pontba érkező sugarakkal vetíti a képsíkra a térbeli pontokat. Ahhoz, hogy a centrális vetítés egyszerű képleteit megkapjuk, tegyük fel, hogy a térbeli x-y-z koordináta-rendszer pontjait az x-y síkkal párhuzamos S képsíkra vetítjük! Jelöljük a térbeli x-y-z koordináta-rendszer kezdőpontját C-vel! C lesz a vetítés centruma. Az S síkon lévő ξ-η koordináta-rendszer kezdőpontja O, legyen olyan, hogy a térbeli rendszer z-tengelyén d távolságra van C-től! A S sík ξ-η koordináta-rendszerének tengelyei párhuzamosak az x- és y-tengelyekkel (IV.38. ábra - Centrális vetítés). Keressük a centrális vetítés (IV.4.1)-nek megfelelő leképezését.

Az ábrán látható módon legyen az origó centrum távolság d! Legyenek egy térbeli P pont koordinátái x, y, z és ennek legyen P * a képe a síkon ξ, η koordinátákkal. A P pont vetülete az x-z síkra P xz (ennek a z tengelytől mért távolsága éppen x koordináta), az y-z síkra P yz (ennek pedig a z tengelytől mért távolsága éppen y koordináta). P xz képe az S síkon P * ξ, és ennek a síkbeli koordináta-rendszer kezdőpontjától való távolsága éppen a ξ koordináta, Pyz képe az S síkon P * η és ennek a síkbeli koordináta-rendszer kezdőpontjától való távolsága éppen a η koordináta! Mivel COP * ξ háromszög hasonló CTP xz háromszöghöz, így
|
|
(IV.4.3) |
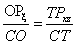
azaz
|
|
(IV.4.4) |
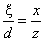
Hasonlóan, az yz síkban a CTP yz háromszög hasonló a COP η háromszöghöz, így
|
|
(IV.4.5) |
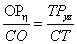
azaz
|
|
(IV.4.6) |
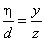
Ezzel létrehoztuk a (IV.4.1) leképezést, hiszen átrendezés után
|
|
(IV.4.7) |
adódik. A (IV.4.7) képletekkel az a probléma, hogy a leképezés nem lineáris. Azonban lineárissá tehetjük úgy, hogy megnöveljük a dimenziószámot (kettőről háromra), és bevezetjük a homogén koordinátákat. Tekintsük a [x, y,z] térbeli pont helyett a négydimenziós [x, y, z, 1] pontot! Azaz az [x, y, z, w] négydimenziós térben a w=1 háromdimenziós altérben gondolkodunk. Ebben a térben a (IV.4.7) leképezés
|
|
(IV.4.8) |
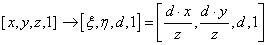
ami lineáris, hiszen átírható (IV.4.9) alakban.
|
|
(IV.4.9) |
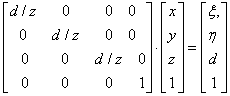
Példaként készítsük el a centrális vetítés leképezését végző Perspektiv függvényt! A bemenő paraméterek a térbeli koordináták (x, y, z), a (IV.4.4, IV.4.6) képlettel a d fókusztávolságot megadva, a leképezés egy PointF típusú lappontot ad vissza.
PointF Perspektiv(float d, float x, float y, float z) {
float X = 0;
float Y = 0;
X = d * x / z;
Y = d * y / z;
return PointF(X, Y);
}
Példaként, a Perspektiv() függvényt és a Graphics osztály már ismert DrawLine() metódusát alkalmazva, rajzoljunk a Paint eseményben egy (150,150,150) középpontú 100 oldalú kockát f=150, f=450 és f=1050 fókusztávolságú axonometriában ábrázolva (IV.39. ábra - A kocka perspektív nézetei)!
private: System::Void Form1_Paint(
System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
// a középpont és a fél oldal
float ox=150;
float oy=150;
float oz=150;
float d=50;
float f=350;
// A piros toll
Pen ^p=gcnew Pen(Color::Red);
// A felső lap
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy-d,oz-d),
Perspektiv(f,ox+d,oy-d,oz-d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy-d,oz-d),
Perspektiv(f,ox+d,oy+d,oz-d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy+d,oz-d),
Perspektiv(f,ox-d,oy+d,oz-d));
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy+d,oz-d),
Perspektiv(f,ox-d,oy-d,oz-d));
// Az alsó lap
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy-d,oz+d),
Perspektiv(f,ox+d,oy-d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy-d,oz+d),
Perspektiv(f,ox+d,oy+d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy+d,oz+d),
Perspektiv(f,ox-d,oy+d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy+d,oz+d),
Perspektiv(f,ox-d,oy-d,oz+d));
// Az oldalélek
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy-d,oz-d),
Perspektiv(f,ox-d,oy-d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy-d,oz-d),
Perspektiv(f,ox+d,oy-d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox+d,oy+d,oz-d),
Perspektiv(f,ox+d,oy+d,oz+d));
e->Graphics->DrawLine(p,Perspektiv(f,ox-d,oy+d,oz-d),
Perspektiv(f,ox-d,oy+d,oz+d));
}
Láthatjuk a fókusztávolság hatását, pontosan úgy viselkedik a fókusztávolság-váltás, mint a kamerák objektívje. Kis fókusztávolság esetén nagy a látószög, erős a perspektíva, nagy fókusztáv esetén kicsi látószög, gyenge perspektíva.
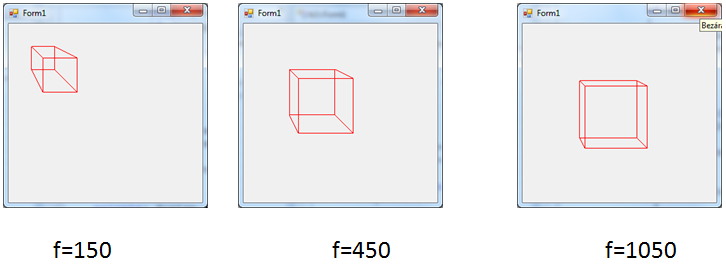
A fenti példákban minden esetben gondoskodtunk arról, hogy a térbeli koordinátákat síkba vetítsük, és olyan centrumot valamint méretet választottunk a kockának, hogy az az ábrára kerüljön. A kocka adatai lehetnek akár mm, akár m akár km egységben is megadva. Azzal, hogy kirajzoltuk a formra a középpontok és az élek hosszát egyaránt pixelben adtuk meg, azonban ezzel hallgatólagosan egy nagyítást kicsinyítést alkalmaztunk (mm->pixel, m->pixel, vagy km->pixel). A megjeleníteni kívánt geometria és az ablakméretek alapján ezt minden esetben meg kellene határoznunk (Window-Viewport transzformáció
[4.3.]
). A GDI+ a Graphics osztály Transform tulajdonságát koordináta-transzformáció létrehozására használhatjuk, és ezzel könnyen megvalósíthatjuk a Window-Viewport transzformációt is.
IV.4.5. Koordináta-transzformáció
Mint láttuk a lap koordináta-rendszer kezdőpontja az ablak aktív területének bal felső sarka, az x-tengely jobbra, az y-lefelé mutat, és az egységek a képpontok (IV.36. ábra - A 2D-s koordinátarendszer). A Graphics osztály Transform tulajdonsága egy Matrix osztály példányára hívatkozó mutató. A Matrix osztály a System::Drawing::Drawing2D névtéren definiált.
A Mátrix osztály a 2D-s sík 3x3 elemet tartalmazó, homogén koordinátás transzformációs mátrixának modellje, melynek harmadik oszlopa [0,0,1]T, és m
11
, m
12
, m
21
, m
22
a koordináta-transzformáció forgatását és tengelyek menti nagyítását, a d
x
, d
y
pedig az eltolást jelenti (IV.4.10).
|
|
(IV.4.10) |
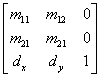
A transzformácós mátrixok geometriai transzformációkat testesítenek meg
[4.4]
[.]
. A geometriai transzformációk egymás után történő elvégzése egyetlen geometriai transzformációt eredményez. Ennek transzformációs mátrixa az első transzformációs mátrix szorozva balról a második transzformációs mátrixszal. A geometriai transzformációk egymás után történő alkalmazása nem felcserélhető művelet ugyanúgy ahogy a mátrixszorzás sem kommutatív. Erre a Transform tulajdonság megadásakor ügyelnünk kel. A transzformáció megadáskor használhatjuk a Matrix osztály metódusait.
A Mátrix osztály konstruktoraival létrehozhatunk transzformációs mátrix példányt. A paraméter nélkül aktivizált konstruktor
Matrix()
a háromdimenziós egységmátrioxot hoz létre. Például, ha készítünk egy E egységmátrixot, és azt megadjuk a Graphics->Trasform tulajdonságnak, az meghagyja a (IV.36. ábra - A 2D-s koordinátarendszer) ábrán látható koordináta-rendszert.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Matrix ^ E=Matrix();
e->Graphics->Transform=E;
Pen ^ p= gcnew Pen(Color::Red);
e->Graphics->DrawLine(p,10,10,100,100);
}
Ugyanezt az eredményt érjük el a Matrix osztály void típusú
Reset()
metódusával.
Matrix ^ E=Matrix(); E->Reset();
Tetszőleges – homogén koordinátákban lineáris – transzformációt megadhatunk, ha valamelyik paraméteres konstruktort alkalmazzuk. A transzformáció definíciójaként egy téglalapot torzíthatunk paralelogrammává úgy, hogy közben el is toljuk (IV.40. ábra - A torzítás megadása). Ennek érdekében a transzformációt az alábbi paraméteres konstruktorral hozhatjuk létre:
Matrix(Rectangle rect, array<Point>^ pontok)
A konstruktor olyan geometriai transzformációt hoz létre, amelyik a paraméterként megadott rect téglalapot paralelogrammává torzítja. (IV.40. ábra - A torzítás megadása) A pontok tömb három pontot tartalmaz. A paralelogramma bal felső sarokpontja (bf) az első, a paralelogramma jobb felső sarokpontja (jf) a második és a bal alsó sarok (ba) a harmadik elem (a negyedik sarok helye adódik).
A Graphics osztály DrawRectangle() metódusa a toll, a kezdőpont-koordináták, a szélesség és a magasság megadásával téglalapot rajzol a formra. Az alábbi példában megrajzoljuk a (10,10) kezdőpontú 100 széles, 100 magas téglalapot pirossal. A transzformáció megadásakor úgy módosítottuk a téglalapot, hogy az a (20,20) kezdőpontba kerüljön, 200 magas legyen, és 45 fokkal legyen döntve. Ezután kirajzoltuk ugyanazt a téglalapot kékkel, látható, hogy az eltolás, a nagyítás és a nyírás is érvényesül.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Pen ^ pen= gcnew Pen(Color::Red);
e->Graphics->DrawRectangle(pen,10,10,100,100);
array< PointF >^ p = {PointF(120,220), PointF(220,220),
PointF(20,20)};
Matrix ^ m = gcnew Matrix(RectangleF(10,10,100,100),p);
e->Graphics->Transform=m;
pen= gcnew Pen(Color::Blue);
e->Graphics->DrawRectangle(pen,10,10,100,100);
}
A transzformációs mátrix megadható koordinátánként is a (IV.4.7 képlet) alapján, a másik paraméteres konstruktorral.
Matrix(float m11, float m12, float m21, float m22, float dx, float dy);
Az alábbi példa 10,10 eltolást, x-irányban kétszeres, y-irányban pedig másfészeres nagyítást készít.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Pen ^ pen= gcnew Pen(Color::Red);
e->Graphics->DrawRectangle(pen,0,0,100,100);
Matrix ^ m = gcnew Matrix(2,0,0,1.5,50,50);
e->Graphics->Transform=m;
pen= gcnew Pen(Color::Blue);
e->Graphics->DrawRectangle(pen,0,0,100,100);
}
Természetesen le is kérdezhetjük a mátrix elemeit a Matrix osztály Elements, Array<float> típusú, csak olvasható tulajdonságával.
Szerencsére nemcsak a mátrix koordinátáinak megadásával készíthetünk transzformációt, hanem a Matrix osztály transzformációs metódusaival is. A Matrix osztály példányaira úgy alkalmazhatjuk a transzformációs függvényeket, mintha az aktuális példány mátrixát jobbról, vagy balról szoroznánk a transzformációs metódus mátrixával. Ennek szabályozását segíti a MatrixOrder típusú felsorolás, melynek tagjai MatrixOrder::Prepend (0, jobbról) és MatrixOrder::Append (1, balról).
Közvetlenül szorozhatjuk a matrixot tartalmazó osztály példányát a megadott Matrix transzformációs mátrixszal a
void Multiply(Matrix matrix [,MatrixOrder order])
metódussal. A szögletes zárójel azt jelenti, hogy az order MatrixOrder típusú paramétert nem kötelező megadni. Az alapértelmezett érték a MatrixOrder::Prepend. Ennek ismételt magyarázatát a következő metódusok esetén elhagyjuk.
Eltolást definiálhatunk, és alkalmazhatunk a mátrix példányon a
void Translate(float offsetX, float offsetY
[,MatrixOrder order]);
metódussal.
Forgatási transzformációt is végrehajthatunk a koordináta-rendszer origója körül alfa szöggel
void Rotate(float alfa [, MatrixOrder order])
vagy egy megadott pont körül alfa – fokban megadott (!) – szöggel;
void RotateAt(float alfa, PointF pont [,MatrixOrder order]);
A következő példa a form közepe körül forgat egy egyenest. Ehhez tudnunk kell, hogy a form Size típusú ClientSize tulajdonsága tartalmazza a kliensterület méreteit.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Matrix ^ m = gcnew Matrix();
Pen ^ p = gcnew Pen(Color::Red);
float x=this->ClientSize.Width/2;
float y=this->ClientSize.Width/2;
for (int i=0; i<360; i+=5) {
m->Reset();
m->Translate(x,y);
m->Rotate(i);
e->Graphics->Transform=m;
e->Graphics->DrawLine(p,0.0F,0.0F,
(float)Math::Min(this->ClientSize.Width/2,
this->ClientSize.Height/2),0.0F);
}
}
Hasonló függvénnyel vehető igénybe a koordináta-tengelyek irányában a skálázás (scaleX, scaleY)
void Scale(float scaleX, float scaleY[, MatrixOrder order]);
A nyírás egy koordináta-irány mentén azt jelenti, hogy a tengely helyben marad, és ahogy távolodunk a tengelytől a pontok a fix tengellyel párhuzamos eltolása arányos a tengelytől való távolsággal.
A nyírás homogén koordinátás transzformációs mátrixa:
|
|
(IV.4.11) |
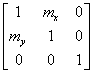
A nyírás megadásához is van függvényünk, ahol a mátrix nyírási koordinátáit lehet megadni:
void Shear(float mX, float mY, [, MatrixOrder order]);
Az alábbi példában eltolunk, és mindkét irányban nyírunk egy téglalapot.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Pen ^ pen= gcnew Pen(Color::Red);
e->Graphics->DrawRectangle(pen,0,0,100,100);
Matrix ^m=gcnew Matrix();
m->Translate(10,10);
m->Shear(2,1.5);
e->Graphics->Transform=m;
pen= gcnew Pen(Color::Blue);
e->Graphics->DrawRectangle(pen,0,0,100,100);
}
Kiszámíthatjuk a transzformációs mátrix inverzét is a Matrix osztály void típusú
Invert();
metódusával.
Ha nem akarjuk a Graphics osztály Transform tulajdonságát alkalmazni, akkor használhatjuk közvetlenül a Graphics osztály
void ResetTransform()
void MultiplyTransform(Matrix m, [, MatrixOrder order]);
void RotateTransform(float szog , [, MatrixOrder order])
void ScaleTransform(float sx, float sy[, MatrixOrder order])
void TranslateTransform Method(float dx, float dy
[, MatrixOrder order])
metódusait, melyek közvetlenül állítják a Graphics osztály Transform tulajdonságát.
A lapokat az eszközre leképező laptranszformáció használhatja a Graphics osztály PageUnit és PageScale tulajdonságait a leképezés megadásához. A PageUnit tulajdonság a System::Drawing::GraphicsUnit felsorolás elemeit veheti fel (UnitPixel=2, UnitInch=4, UnitMillimeter=6…).
Példaként a milliméter lapegységet állítjuk be, akkor a 20 mm oldalhosszú négyzet a képernyőn is körülbelül 20 mm oldalhosszú lesz. Ha beállítjuk a Graphics osztály PageScale float típusú tulajdonságát, akkor az skálázza léptékünket. Például, ha a PageScale = 0.5, akkor a 20 mm oldalú négyzet 10 mm oldalú lesz (IV.42. ábra - Eltolás nyújtás mátrix-szal).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
e->Graphics->PageUnit=GraphicsUnit::Millimeter;
Pen ^ pen= gcnew Pen(Color::Red);
e->Graphics->DrawRectangle(pen,10,10,30,30);
e->Graphics->PageScale=0.5;
pen= gcnew Pen(Color::Blue);
e->Graphics->DrawRectangle(pen,10,10,30,30);
}
A GDI+ a meghajtó-programtól kapja a képernyőfelbontás információt, innen tudja a leképezés adatait beállítani. A DpiX és DpiY csak olvasható tulajdonság tartalmazza az adott eszközre vonatkozó dot/inch felbontásokat.
IV.4.6. A GDI+ színkezelése (Color)
A GDI+ színek tárolására a Color struktúrát használjuk. Ez nem más, mint egy 32-bites egész, melynek minden egyes bájtja jelentéssel bír (szemben a hagyományos GDI színekkel, ahol a 32 bitből csak 24 kódolt színt). A 32-bites információt ARGB színnek hívjuk, a felső byte (Alpha) az áttetszőséget a maradék 24 bit pedig a GDI-nek megfelelő Red, Green, és Blue intenzitás-összetevőket kódolja. (Alpha=0 a teljesen átlátszó, 255 a nem átlátszó, a színösszetevőknél az érték az adott összetevő intenzitását jelöli.) Színleíró struktúrát hozhatunk létre a System::Drawing::Color struktúra FromArgb() metódusával. Több túlterhelt lehetőség között egész paraméterekkel megadhatjuk az r, g és b összetevőket, vagy négy egésszel az a, r, g és b összetevőket. Használhatunk több előre definiált színt is Color::Red, Color::Blue stb. A rendszerszíneket is elérhetjük SystemColors::Control, SystemColors::ControlText stb.
Az ablak háttérszínét beállító klasszikus alkalmazás jól mutatja az RGB színek alkalmazhatóságát. Az ablak háttérszíne csak RGB szín lehet. Helyezzünk fel három függőleges csúszkát a formra! A nevek (Name) legyenek rendre piros, zold és kek! Állítsuk be mindegyik maximumát 255-re (nem törődve azzal, hogy ilyenkor a csúszka nem tud 255-ig csúszni)! Mindegyik Scroll eseménye legyen a piros kezelője, ahogy ez a Designer generálta kódból látszik!
//
// piros
//
this->piros->Location = System::Drawing::Point(68, 30);
this->piros->Maximum = 255;
this->piros->Name = L"piros";
this->piros->Size = System::Drawing::Size(48, 247);
this->piros->TabIndex = 0;
this->piros->Scroll += gcnew
System::Windows::Forms::ScrollEventHandler(
this, &Form1::piros_Scroll);
//
// zold
//
this->zold->Location = System::Drawing::Point(187, 30);
this->zold->Maximum = 255;
this->zold->Name = L"zold";
this->zold->Size = System::Drawing::Size(48, 247);
this->zold->TabIndex = 1;
this->zold->Scroll += gcnew
System::Windows::Forms::ScrollEventHandler(
this, &Form1::piros_Scroll);
//
// kek
//
this->kek->Location = System::Drawing::Point(303, 30);
this->kek->Maximum = 255;
this->kek->Name = L"kek";
this->kek->Size = System::Drawing::Size(48, 247);
this->kek->TabIndex = 2;
this->kek->Scroll += gcnew
System::Windows::Forms::ScrollEventHandler(
this, &Form1::piros_Scroll);
A piros Scroll eseménykezelője pedig a háttérszín állításhoz felhasználja mindhárom csúszka pozícióját (Value tulajdonság):
private: System::Void piros_Scroll(System::Object^ sender,
System::Windows::Forms::ScrollEventArgs^ e) {
this->BackColor = Color::FromArgb(
piros->Value, zold->Value, kek->Value);
}
Az áttetsző színek használatával a toll és az ecset rajzeszközöknél ismerkedünk meg. A Color struktúra csak olvasható R, G és B (Byte típusú) tulajdonságai a színösszetevőket tartalmazzák.
Byte r = this->BackColor.R;
IV.4.7. Geometriai adatok (Point, Size, Rectangle, GraphicsPath)
Geometriai objektumokat hozhatunk létre a Point, PointF és a Rectangle, RectangleF struktúrákkal, illetve a téglalapok méretét tárolhatjuk a Size, SizeF típusú struktúrákban. A záró F betű a struktúra adattagjainak float típusára utal. Ha nincs F, akkor az adattagok int típusúak.
IV.4.7.1. Méretek tárolása
Size struktúrát létrehozhatunk a
Size(Int32,Int32)
Size(Point)
SizeF(float,float)
SizeF(PointF)
konstruktorokkal. A Size és a SizeF struktúrák (int, illetve float) tulajdonságai a Height és a Width, melyek a téglalapok magasságát és szélességét tartalmazzák. Az IsEmpty logikai típusú tulajdonság arról informál, hogy mindkét méret értéke 0-e (true), vagy sem (false).
A méretadatokkal műveleteket is végezhetünk a Size(F) struktúrák statikus metódusaival. Az Add() metódus összeadja a Size típusú paraméterek Width és Height értékekeit. A Subtract() kivonja őket egymásból.
static Size Add(Size sz1, Size sz2);
static Size Subtract(Size sz1, Size sz2);
Két méret típusú struktúra egyenlőségét vizsgálhatjuk a
bool Equals(Object^ obj)
A fenti metódusoknak megfelelően definiáltak a Size(F) struktúrára túlterhelt operátorai a +, a – és az ==.
SizeF típusú értékeket felfelé kerekít Size típusúra a Ceiling(), míg a szokásos módon kerekít a Round() metódus.
static Size Ceiling(SizeF value);
static Size Round(SizeF value);
A ToString() metódus {Width=xxx, Height=yyy} formájú stringre konvertálja a Size(F) struktúra tagjait.
Fontos megjegyezni, hogy mivel a formoknak van Size tulajdonságuk, ezért a Size típusú struktúrát csak a névtér megadásával használjuk. Az alábbi példa a form címsorára írja a létrehozott Size méreteit.
System::Drawing::Size ^ x= gcnew System::Drawing::Size(100,100); this->Text=x->ToString();
IV.4.7.2. Síkbeli pontok tárolása
A Point, PointF struktúrák a Size jellegű struktúrákhoz nagyban hasonlítanak, céljuk azonban nem méretek megadása. Pontokat lehet létrehozni a
Point(int dw);
Point(Size sz);
Point(int x, int y);
PointF(float x, float y);
konstruktorokkal. Az első esetben a paraméter alsó 16 bitje definiálja az x-, a felső az y-koordinátát. A második esetben a Size paraméter Width értéke lesz az x-, és a Height pedig az y-koordina. A pont struktúrák alapvető tulajdonságai az X, az Y koordinátaértékek és az IsEmpty vizsgálat.
A pontokkal műveleteket is végezhetünk a Point(F) struktúrák metódusaival. Az Add() metódus a paraméterként kapott Point koordinátáihoz hozzáadja a szintén paraméterként kapott Size struktúra Width és Height értékeit A Subtract() kivonja őket egymásból.
static Point Add(Point pt, Size sz);
static Size Subtract(Point pt, Size sz);
Két pont típusú struktúra egyenlőségét vizsgálhatjuk a
virtual bool Equals(Object^ obj) override
A fenti metódusoknak megfelelően a Point(F) struktúrák túlterhelt operátorai a +, a – és az ==.
PointF típusú értékeket felfelé kerekít Point típusra a Ceiling(), míg a szokásos módon kerekít a Round() metódus.
static Size Ceiling(SizeF value);
static Size Round(SizeF value);
A ToString() metódus {X=xxx, Y=yyy} formájú stringre konvertálja a Point(F) struktúra adatait.
IV.4.7.3. Síkbeli téglalapok tárolása
A Rectangle és a RectangleF struktúrák téglalapok adatainak tárolására szolgálnak. Téglalapokat lehet létrehozni a
Rectangle(Point pt, Size sz);
Rectangle(Int32 x, Int32 y, Int32 width, Int32 height);
RectangleF (PointF pt, SizeF sz);
RectangleF(Single x, Single y, Single width, Single height);
konstruktorokkal. Az X és Y, a Left és Top, illetve a Location tulajdonságok a Rectangle(F) bal-felső sarkának koordinátáit tartalmazzák. A Height, Width és Size a téglalapok szélességi és magassági méretei, a Right és Bottom tulajdonságok pedig a jobb-alsó sarok koordinátái. Az IsEmpty arról informál valódi téglalappal van-e dolgunk. Az Empty egy nem definiált adatokkal bíró téglalap.
Rectagle Empty;
Empty.X=12;
A bal-felső és a jobb-alsó sarok koordinátáival hozhatunk létre téglalapot (Rectangle, RectanleF) az alábbi metódusokkal
static Rectangle FromLTRB(int left,int top,
int right,int bottom);
static RectangleF FromLTRB(float left, float top,
float right, float bottom)
A Rectangle struktúra rengeteg metódust kínál használatra. A RectanleF struktúrából felfelé kerekítéssel Rectangle struktúrát készít a Ceiling() metódus, szokásos kerekítéssel a Round() metódus, a tizedes rész levágásával pedig a Truncate() metódus.
Eldönthetjük, hogy a téglalap tartalmaz-e egy pontot, illetve téglalapot. a Rectangle struktúra
bool Contains(Point p);
bool Contains(Rectangle r);
bool Contains(int x, int y);
metódusaival, illetve RectangleF struktúra
bool Contains(PointF p);
bool Contains(RectangleF r);
bool Contains(single x, single y);
metódusaival.
Megnövelhetjük az aktuális Rectangle(F) területét a szélesség magasság adatokkal
void Inflate(Size size);
void Inflate(SizeF size);
void Inflate(int width, int height);
void Inflate(single width, single height);
A
static Rectangle Inflate(Rectangle rect, int x, int y);
static RectangleF Inflate(RectangleF rect, single x, single y);
metódusok meglévő téglalapokból készítenek új, megnövelt Rectangle(F) példányokat.
Elmozdíthatjuk a téglalapok bal-felső sarkát az
void Offset(Point pos);
void Offset(PointF pos);
void Offset(int x, int y);
void Offset(single x, single y);
metódusokkal.
Az
void Intersect(Rectangle rect);
void Intersect(RectangleF rect);
metódusok az aktuális példány paraméterrel való metszetét számítják. Az alábbi statikus metódusok a paraméterként megadott Rectangle(F) elemek metszetéből készítenek új példányt.
static Rectangle Intersect(Rectangle a, Rectangle b);
static RectangleF Intersect(RectangleF a, RectangleF b);
Meg is vizsgálhatjuk, hogy a téglalapot metszi-e egy másik a
bool IntersectsWith(Rectangle rect);
bool IntersectsWith(RectangleF rect);
metódusokkal.
A paraméterként megadott Rectangle(F) elemek úniójaként létrejövő téglalapot készítenek el a
static Rectangle Union(Rectangle a, Rectangle b);
static RectangleF Union(RectangleF a, RectangleF b);
metódusok.
Téglalapokra is működnek az
virtual bool Equals(Object^ obj) override
virtual String^ ToString() override
A Rectangle(F) típusú elemek között az == és a != operátorok is definiáltak.
IV.4.7.4. Geometriai alakzatok
Vonalak, görbék, szövegek láncolatából álló nyílt vagy zárt geometriai alakzatot (figurát) modelleznek a nem örököltethető System::Drawing::Drawing2D::GraphicsPath osztály példányai. A GraphicsPath objektumok összekapcsolt grafikus elemekből, akár GraphicsPath objektumokból állhatnak. A figuráknak van kezdőpontjuk (az első pont), végpontjuk (az utolsó pont) és jellemző az irányításuk. A figurák nem zárt görbék még akkor sem, ha a kezdő és a végpontok egybeesnek. Azonban készíthetünk zárt alakzatot is a CloseFigure() metódussal. Ki is festhetünk alakzatokat a Graphics osztály FillPath() metódusával. Ilyenkor a kezdő- és végpontokat összekötő egyenes zárja le az esetlegesen nem zárt alakzatokat. A kifestés módja az önmagukat metsző alakzatoknál beállítható. Többféle módon hozhatunk létre alakzatokat a GraphicsPath osztály konstruktoraival. Üres figurát hoz létre a
GraphicsPath()
konstruktor. Intézkedhetünk a majdani kifestés módjáról a
GraphicsPath(FillMode fillMode)
konstruktorral. A System::Drawing::Drawing2D::FillMode felsorolt típusú változó értékei Alternate és Winding az ábrának (IV.47. ábra - Alternate és Winding görbelánc) megfelelően. Az alapértelmezett Alternate a zárt alakzat minden egyes újra átlapolásánál vált, míg a Winding nem.

Point(F) tömb (pts) által definiált figura is definiálható a
GraphicsPath(array<Point>^ pts, array<unsigned char>^ types
[,FillMode fillmode]);
GraphicsPath(array<PointF>^ pts, array<unsigned char>^ types
[,FillMode fillmode]);
konstruktorokkal. A types tömb PathPointType típusú elemek tömbje, ami minden egyes pts ponthoz görbetípust definiál. Lehetséges értékei például Start, Line, Bezier, Bezier3, DashMode.
A GraphicsPath osztály tulajdonságai a PathPoints, PathType tömbök, a PointCounts elemszám, a FillMode kitöltéstípus. A PathData osztály a PathPoints, PathType, tömbök egységbezárása, melynek tulajdonságai a Points és a Types.
Vonalszakaszokat, vonalszakaszok tömbjét is integrálhatjuk a figurába az
void AddLine(Point pt1, Point pt2);
void AddLine(PointF pt1, PointF pt2);
void AddLine(int x1, int y1, int x2, int y2);
void AddLine(float x1, float y1, float x2, float y2);
void AddLines(array<Point>^ points);
void AddLines(array<PointF>^ points);
metódusokkal.
Point(F) tömbök által meghatározott poligon csatlakozhat a figurához a
void AddPolygon(array<Point>^ points);
void AddPolygon(array<PointF>^ points);
metódusokkal.
Téglalapokat, illetve téglalapok tömbjét adhatjuk a figurához a
void AddRectangle(Rectangle rect);
void AddRectangle(RectangleF rect);
void AddRectangles(array<Rectangle>^ rects);
void AddRectangles(array<RectangleF>^ rects);
metódusokkal.
Ellipsziseket adhatunk a figurához a befoglaló téglalapjaik adataival.
void AddEllipse(Rectangle rect);
void AddEllipse( RectangleF rect);
void AddEllipse(int x, int y, int width, int height);
void AddEllipse(float x, float y, float width, float height);
Ellipszisíveket, illetve ellipszisívek tömbjét adhatjuk a figurákhoz az
void AddArc(Rectangle rect, float startAngle, float sweepAngle);
void AddArc(RectangleF rect,
float startAngle, float sweepAngle);
void AddArc(int x, int y, int width, int height,
float startAngle, float sweepAngle);
void AddArc(float x, float y, float width, float height,
float startAngle, float sweepAngle);
metódusokkal. Az ellipszisív mindig a befoglaló téglalappal, a kezdőszöggel és a bezárt szöggel definiált.
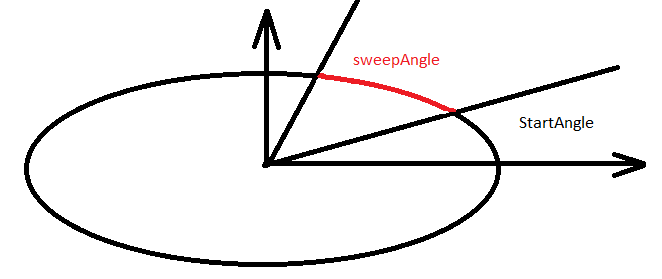
A Pie egy ellipszisívvel és két középpontból az ív szélső pontjaiig húzott egyenessel definiált alakzat. Ilyenek is csatlakoztathatók a figurához az
void AddPie(Rectangle rect, float startAngle, float sweepAngle);
void AddPie(int x, int y, int width, int height,
float startAngle, float sweepAngle);
void AddPie(float x, float y, float width, float height,
float startAngle, float sweepAngle);
metódusokkal.
Bezier görbéket is illeszthetünk a figurába. A harmadfokú Bezier-görbét a síkban négy pont határozza meg. A kezdőpont az első, a végpont pedig a negyedik. A kezdő érintőt az első és második pont határozza meg, a záró érintőt a harmadik és a negyedik pont definiálja úgy, hogy a pontok közti vektor éppen a derivált háromszorosa (IV.49. ábra - A harmadfokú Bezier-görbe). A görbe paraméteres leírását a (IV.4.12) paraméteres egyenletek tartalmazzák [4.4.]
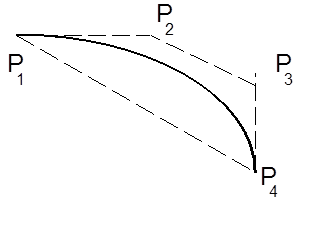
|
|
(IV.4.12) |
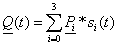
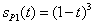
Bezier-görbék beillesztésére szolgálnak az alábbi metódusok:
void AddBezier(Point pt1, Point pt2, Point pt3, Point pt4);
void AddBezier(PointF pt1, PointF pt2, PointF pt3, PointF pt4);
void AddBezier(int x1, int y1, int x2, int y2,
int x3, int y3, int x4, int y4);
void AddBezier(float x1, float y1, float x2, float y2,
float x3, float y3, float x4, float y4);
Egymáshoz csatlakozó Bezier görbéket illesztenek a figurába a
void AddBeziers(array<Point>^ points);
void AddBeziers(array<PointF>^ points);
metódusok. A points tömbök tartalmazzák a végpontokat és a vezérlő pontokat úgy, hogy az első görbe az első négy ponttal meghatározott (IV.49. ábra - A harmadfokú Bezier-görbe, IV.4.12 egyenletek), minden további görbe három további ponttal definiált. Az aktuális görbe előtt elhelyezkedő görbe végpontja a kezdőpont. A két vezérlő pont és egy végpont az aktuális görbéhez tartozó három pont. Ha más görbe volt az előző görbe, akkor annak végpontja is lehet az első pont (0. rendben folytonos illesztés). A Graphics osztály DrawPath() metódusa kirajzolja a figurát (IV.50. ábra - A harmadfokú Bezier-görbék folytonosan illesztve).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
array<Point>^ pontok = {Point(20,100), Point(40,75),
Point(60,125), Point(80,100),
Point(100,150), Point(120,250),
Point(140,200)};
GraphicsPath^ bPath = gcnew GraphicsPath;
bPath->AddBeziers( pontok );
Pen^ bToll = gcnew Pen( Color::Red);
e->Graphics->DrawPath( bToll, bPath );
}
Amennyiben a pontok sorozatára interpolációs görbét fektethetünk úgy, hogy az átmegy a pontokon és, minden pontban a görbe érintője arányos a két szomszédos pont által meghatározott vektorral, akkor azt a görbét kardinális spline-nak nevezzük. Ha a görbe idő szerinti paraméteres leírását tekintjük, akkor azt mondhatjuk, hogy a t k . időpontban a görbe éppen a P k ponton halad keresztül (IV.51. ábra - A kardinális spline). A görbe érintője a t k . időpontban V k , akkor az érintőt a (IV.4.13) egyenlet határozza meg.
|
|
(IV.4.13) |
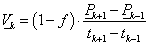
ahol f(<1) a görbe feszítése. Ha f=0, akkor az éppen a Catmull-Rom spline [4.4.] .
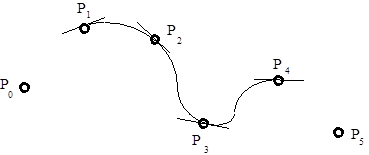
A kardinális spline paraméteres leírását a (IV.4.14) egyenletek tartalmazzák.
|
|
(IV.4.14) |
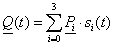
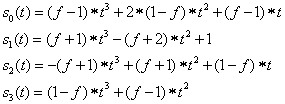
Szokás a széleken az egyoldalas differeciával számítani az érintőt, és ilyenkor a görbe minden ponton átmegy. A kardinális spline-ok használatának előnye az, hogy nincs szükség egyenletrendszer megoldására, és a görbe minden ponton átmegy. Hátránya az, hogy csak egyszer deriválhatók folytonosan.
Az
void AddCurve(array<Point>^ points,
[[int offset, int numberOfSegments],
float tension]);
void AddCurve(array<PointF>^ points,
[[int offset, int numberOfSegments],
float tension]);
metódusok kardinális spline-t adnak a figurához. A points tömb tartalmazza a tartópontokat. Az elhagyható tension paraméter a feszítést definiálja, míg az elhagyható offset paraméterrel megadhatjuk, hogy hányadik ponttól kezdve vesszük figyelembe a ponts tömb pontjait, ekkor a numberOfSegments paraméterrel megadhatjuk azt is, hogy hány görbeszakaszt szeretnénk (meddig vegyük figyelembe a points tömb elemeit). A tension paraméter elhagyásával vagy 0 értékével a Catmull-Rom görbét definiálhatjuk.
Zárt kardinális spline kerül a figurába az
void AddClosedCurve(array<Point>^ points, float tension); void AddClosedCurve(array<PointF>^ points, float tension);
metódusokkal.
Az alábbi program az előző példa pontjaira fektet kardinális (Catmull-Rom) spline-t (IV.52. ábra - Catmull-Rom spline)
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
array<Point>^ pontok = {Point(20,100), Point(40,75),
Point(60,125), Point(80,100),
Point(100,150), Point(120,250),
Point(140,200)};
GraphicsPath^ cPath = gcnew GraphicsPath;
cPath->AddCurve( pontok);
Pen^ cToll = gcnew Pen( Color::Blue );
e->Graphics->DrawPath( cToll, cPath );
}
Szöveget illeszthetünk a figurába az
void AddString(String^ s, FontFamily^ family, int style,
float emSize, Point origin, StringFormat^ format);
void AddString(String^ s, FontFamily^ family, int style,
float emSize, PointF origin, StringFormat^ format);
void AddString(String^ s, FontFamily^ family, int style,
float emSize, Rectangle layoutRect,
StringFormat^ format);
void AddString(String^ s, FontFamily^ family, int style,
float emSize, RectangleF layoutRect,
StringFormat^ format);
metódusokkal. Az s a kiírandó szöveget tároló objektum referenciája. A betűk, betűtípusok lehetőségeivel még foglalkozunk, most csak annyit mondunk el, amennyi az aktuális példához szükséges. A family referencia a kiírás fontcsaládját tartalmazza. Ilyet létrehozhatunk például a egy meglévő fontcsalád nevével (lásd a példát). A style paraméter a FontStyle felsorolás egy eleme (FontStyle::Italic, FontStyle::Bold …), míg az emSize a betű befoglaló téglalapjának függőleges mérete. Meghatározhatjuk a kiírás helyét a Point(F) típusú origin paraméterrel, vagy a Rectangle(F) layoutRect paraméterrel. A format paraméter a StringFormat típusú objektum referencia példánya, használhatjuk a StringFormat::GenericDefault tulajdonságot.
Az alábbi példa egy figurába illeszti és figuraként kirajzolja a GDI+ és a rajzolás szavakat.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
GraphicsPath^ sPath = gcnew GraphicsPath;
FontFamily^ family = gcnew FontFamily( "Arial" );
sPath->AddString("GDI+", family, (int)FontStyle::Italic,
20, Point(100,100),
StringFormat::GenericDefault);
sPath->AddString("rajzolás", family, (int)FontStyle::Italic,
20, Point(160,100),
StringFormat::GenericDefault);
Pen^ cToll = gcnew Pen( Color::Blue );
e->Graphics->DrawPath( cToll, sPath );
}
Figurát (addingPath) adhatunk az aktuális figura példányhoz az
void AddPath(GraphicsPath^ addingPath, bool connect);
metódussal. A connect változó arról gondoskodik, hogy összekötött legyen-e a két elem. A alábbi példa két éket köt össze.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
array<Point>^ tomb1 = {Point(100,100), Point(200,200),
Point(300,100)};
GraphicsPath^ Path1 = gcnew GraphicsPath;
Path1->AddLines( tomb1 );
array<Point>^ Tomb2 = {Point(400,100), Point(500,200),
Point(600,100)};
GraphicsPath^ Path2 = gcnew GraphicsPath;
Path2->AddLines( Tomb2 );
Path1->AddPath( Path2, true ); // false
Pen^ Toll = gcnew Pen( Color::Green);
e->Graphics->DrawPath( Toll, Path1 );
}
A figurát úgy lehet vastagítani, hogy a figura vonalaival (a sztring karaktereinek vonalaival is) párhuzamosan – esetleg adott távolságra és adott geometriai transzformáció után – rövid vonalszakaszokat húzunk. A
void Widen(Pen^ pen[, Matrix^ matrix[, float flatness]]);
metódussal. A pen paraméter vastagsága adja a párhuzamos vonalak eredeti vonaltól mért távolságát, az opcionális matrix paraméter által definiált transzformációval a párhuzamos húzás előtt eltolhatjuk a figurát. A flatness paraméter azt adja meg, hogy milyen hosszúak legyenek a párhuzamos szakaszok (a körből sokszög lesz). Az alábbi példa két kört eltolva szélesít (IV.55. ábra - Szélesített figura).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
GraphicsPath^ Path = gcnew GraphicsPath;
Path->AddEllipse( 0, 0, 100, 100 );
Path->AddEllipse( 100, 0, 100, 100 );
e->Graphics->DrawPath( gcnew Pen(Color::Black), Path );
Pen^ widenPen = gcnew Pen( Color::Black,10.0f );
Matrix^ widenMatrix = gcnew Matrix;
widenMatrix->Translate( 50, 50 );
Path->Widen( widenPen, widenMatrix, 10.0f );
e->Graphics->DrawPath( gcnew Pen( Color::Red ), Path );
}
Ha nem párhuzamos görbét szeretnénk, hanem csak a figurát egymáshoz csatlakoztatott egyenes szakaszok halmazával kívánjuk helyettesíteni, akkor használhatjuk a
void Flatten([Matrix^ matrix[, float flatness]]);
metódust, a paraméterek értelmezése megegyezik a Widen() metódusnál elmondottakkal.
Transzformációkat is alkalmazhatunk az aktuális figurára a
void Transform(Matrix^ matrix);
metódussal.
Torzíthatjuk is a figurát a
void Warp(array<PointF>^ destPoints, RectangleF srcRect[,
Matrix^ matrix[, WarpMode warpMode[,
float flatness]]]);
metódussal. Ekkor a transzformáció az srcRect téglalapot a destPoints ponttömb által meghatározott négyszögre transzformálja, mintha a síklap gumiból lenne. A matrix opcionális paraméterrel ezen túlmenően még tetszőleges geometriai transzformációt is alkalmazhatunk. A warpMode opcionális paraméter lehet WarpMode::Perspective (ez az alapértelmezett) és WarpMode::Bilinear a IV.4.15 egyenleteknek megfelelően. A szakaszokra bontás pontosságát is definiálhatjuk a flatness opcionális paraméterrel.
|
|
(IV.4.15) |
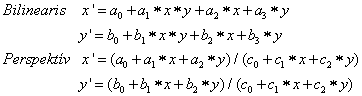
Az alábbi példa egy szöveget torzít a megfelelő téglalap(fekete) és négyszög (piros) által definiált, perspektív módon és eltolva.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
GraphicsPath^ myPath = gcnew GraphicsPath;
RectangleF srcRect = RectangleF(10,10,100,200);
myPath->AddRectangle( srcRect );
FontFamily^ family = gcnew FontFamily( "Arial" );
myPath->AddString("Torzítás", family, (int)FontStyle::Italic,
30,Point(100,100),StringFormat::GenericDefault);
e->Graphics->DrawPath( Pens::Black, myPath );
PointF point1 = PointF(200,200);
PointF point2 = PointF(400,250);
PointF point3 = PointF(220,400);
PointF point4 = PointF(500,350);
array<PointF>^ destPoints = {point1,point2,point3,point4};
Matrix^ translateMatrix = gcnew Matrix;
translateMatrix->Translate( 20, 0 );
myPath->Warp(destPoints, srcRect, translateMatrix,
WarpMode::Perspective, 0.5f );
e->Graphics->DrawPath( gcnew Pen( Color::Red ), myPath );
}
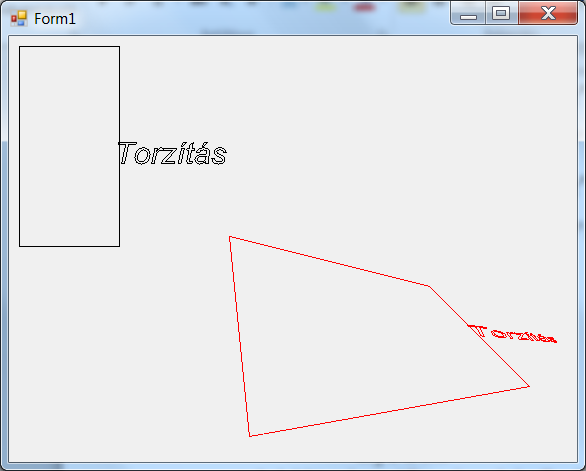
A GraphicsPathIterator osztály segítségével végigjárhatjuk a figura pontjait, jelölőket helyezhetünk el a SetMarker() metódussal, és a NextMarker() metódussal szeleteket készíthetünk a figurából. A ClearMarker() metódus törli a jelölőket.
Egy figurán belül több alfigura is megadható. Ezeket megnyithatjuk a
void StartFigure();
metódussal.
Zárttá tehetjük a figurát az utolsó pont és az első pont egyenessel való összekötésével a
void CloseFigure();
metódussal. Minden aktuálisan megnyitott figurát lezár a
void CloseAllFigures();
metódus. Az utóbbi két metódus automatikusan új alfigurát nyit.
A
RectangleF GetBounds([Matrix^ matrix[, Pen^ pen]]);
metódus visszaadja a figura befoglaló téglalapját. Ha használjuk az opcionális mátrix paramétert, akkor annyival eltolva, az elhagyható pen paraméter vastagsága minden oldalon megnöveli a befoglaló téglalap méreteit.
A
bool IsVisible(Point point[, Graphics ^ graph]);
bool IsVisible(PointF point[, Graphics ^ graph]);
bool IsVisible(int x, int y[, Graphics ^ graph]);
bool IsVisible(float x, float y[, Graphics ^ graph]);
metódusok igaz értékkel térnek vissza, ha az x, y koordinátájú pont, illetve a point paraméter által definiált pont benne van a figurában. Az opcionális graph paraméter egy rajzlapot jelöl, aminek az aktuális körbevágásában (a ClipRegion fogalommal a következő fejezet foglalkozik) vizsgálódunk.
A
bool IsOutlineVisible(Point point, Pen^ pen);
bool IsOutlineVisible(PointF point, Pen^ pen);
bool IsOutlineVisible(int x, int y, Pen^ pen);
bool IsOutlineVisible(float x, float y, Pen^ pen);
bool IsOutlineVisible(Point point, Pen^ pen
[, Graphics ^ graph]);
bool IsOutlineVisible(PointF point, Pen^ pen
[, Graphics ^ graph]);
bool IsOutlineVisible(int x, int y, Pen^ pen
[, Graphics ^ graph]);
bool IsOutlineVisible(float x, float y, Pen^ pen
[, Graphics ^ graph]);
metódusok igaz értékkel térnek vissza, ha az x, y koordinátájú pont, illetve a point paraméter által definiált pont benne van a figura befoglaló téglalapjában, feltéve, hogy pen paraméternek megfelelő tollal rajzoltuk őket. Az opcionális graph paraméter egy rajzlapot jelöl, aminek az aktuális körbevágásában vizsgálódunk.
A
void Reverse();
metódus megfordítja a figura pontjainak sorrendjét (a PathPoints tömb tulajdonságban).
A
void Reset();
metódus a figura minden adatát törli.
IV.4.8. Régiók
A régió osztály (System::Drawing::Region) téglalapokból és zárt körvonalakból létrehozott területet modellez, így a régió területe bonyolult alakú is lehet.
A régió példányát a konstruktorok valamelyikével hozhatjuk létre:
Region();
Region(GraphicsPath^ path);
Region(Rectangle rect);
Region(RectangleF rect);
Region(RegionData^ rgnData);
Ha nem adunk meg paramétert, akkor üres régió keletkezik. A path, illetve a rect paraméterek a régió kezdeti alakját definiálják.
A régióval is körbevághatjuk a rajzunkat - a Graphics osztály
void SetClip(Graphics^ g[, CombineMode combineMode]);
void SetClip(GraphicsPath^ path[, CombineMode combineMode]);
void SetClip(Rectangle rect[, CombineMode combineMode]);
void SetClip(RectangleF rect[, CombineMode combineMode]);
void SetClip(Region^ region, CombineMode combineMode);
metódusaival, így mint speciális képkeretet használhatjuk. A képkeret geometriáját egy másik rajzlap (g paraméter) képkerete, figura (path), téglalap (rect), vagy régió (region) is definiálhatja. A combineMode paraméter a CombineMode felsorolás értékeit veheti fel.
A
Replace(a megadott elem a paraméter geometria G),Intersect(az aktuális képkeret – R – metszete a megadott elemmel – G – ),
),Union(unió a megadott elemmel ),
),Xor(szimmetrikus differencia a megadott elemmel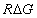 ),
),Exclude(az eredeti és a megadott régió különbsége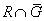 ) és
) ésComplement(a megadott régió és az eredeti különbsége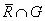 ).
).
A Windows a rajz frissítésére is használhat régiót.
A RegionData osztály tartalmaz egy régió adatait leíró bájt tömböt a Data tulajdonságában. A
RegionData^ GetRegionData()
metódussal lekérhetjük a RegionData egy példányát az aktuális regióra vonatkozóan. A
array<RectangleF>^ GetRegionScans(Matrix^ matrix)
metódus téglalapok egy tömbjével írja le az aktuális régiót. A matrix paraméter egy előzetes transzformáció mátrixát tartalmazza.
A
void MakeEmpty()
metódus üres régóvá teszi az aktuális régiót, míg a
void MakeInfinite()
metódus végtelen régiót készít az aktuális régióból.
A régiókkal is műveleteket végezhetünk. A
void Complement(Region^ region);
void Complement(RectangleF rect);
void Complement(Rectangle rect);
void Complement(GraphicsPath^ path);
metódusok hívásának eredményeként az argumentumként megadott geometria és az aktuális régió komplementerének metszete lesz az aktuális régió. Azaz az aktuális régió a paraméter-geometria és az aktuális régió különbsége lesz (Legyen R az aktuális régió pontjainak halmaza, G a megadott paraméter-geometria pontjainak halmaza, akkor a művelet leírása 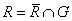 !).
!).
Az
void Exclude(Region^ region);
void Exclude(RectangleF rect);
void Exclude(Rectangle rect);
void Exclude(GraphicsPath^ path);
metódusokkal az aktuális régió önmaga és az argumentumként megadott alakzat komplementerének metszete lesz, azaz az eredmény az aktuális régió és a paraméter-geometria különbsége ( ).
).
Az
void Intersect(Region^ region);
void Intersect(RectangleF rect);
void Intersect(Rectangle rect);
void Intersect(GraphicsPath^ path);
metódusokkal az aktuális régió önmaga és az argumentumként megadott geometria metszete lesz ( ).
).
Az
void Union(Region^ region);
void Union(RectangleF rect);
void Union(Rectangle rect);
void Union(GraphicsPath^ path);
metódusokkal az aktuális régió önmaga és az argumentumként megadott geometria uniója lesz ( ).
).
A
void Xor(Region^ region);
void Xor(RectangleF rect);
void Xor(Rectangle rect);
void Xor(GraphicsPath^ path);
metódusokkal az aktuális régió csak azokat a pontokat fogja tartalmazni, amelyek csak az egyik geometria elemei voltak előzőleg. Az a geometria lesz, ami az aktuális régió és a megadott geometria uniójából levonjuk az aktuális régió és a megadott geometria metszetét (szimmetrikus differencia  ).
).
Transzformációs mátrixszal vagy megadott eltolás-koordinátákkal transzformálhatjuk a régiót:
void Transform(Matrix^ matrix);
void Translate(int dx, int dy);
void Translate(float dx, float dy);
Megvizsgálhatjuk, hogy a pont benne van-e az aktuális régióban:
bool IsVisible(Point point[, Graphics gr]);
bool IsVisible(PointF point[, Graphics gr]);
bool IsVisible(float x, float y);
bool IsVisible(int x, int y[, Graphics gr]);
Téglalapokról eldönthetjük van-e közös metszetük az aktuális régióval:
bool IsVisible(Rectangle rect[, Graphics gr]);
bool IsVisible(RectangleF rect[, Graphics gr]);
bool IsVisible(int x, int y, int width, int height
[, Graphics gr]);
bool IsVisible(float x, float y, float width, float height
[, Graphics gr]);
Mindkét esetben - a Graphics típusú elhagyható paraméterrel - a rajzlapot is kijelölhetjük
Az
bool IsEmpty(Graphics^ g);
metódus eldönti, hogy az aktuális régió üres-e. az
bool IsInfinite(Graphics^ g);
pedig azt hogy végtelen-e.
Az alábbi példa szöveggel figurát készít, és mielőtt kirajzolná, egy vágórégiót definiál
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
GraphicsPath^ sPath = gcnew GraphicsPath;
FontFamily^ family = gcnew FontFamily( "Arial" );
sPath->AddString("Szöveg körbevágva", family, (int)FontStyle::Italic,
40,Point(0,0),StringFormat::GenericDefault);
System::Drawing::Region ^ vag = gcnew System::Drawing::Region(
Rectangle(20,20,340,15));
e->Graphics->SetClip(vag, CombineMode::Replace);
e->Graphics->DrawPath( gcnew Pen(Color::Red), sPath );
}
IV.4.9. Képek kezelése (Image, Bitmap, MetaFile, Icon)
Képek tárolására két alapvető stratégia létezik. Az egyik eset, amikor a kép olyan mintha ceruzával rajzolnánk. Ilyenkor a kép adatainak tárolása úgy történik, hogy tároljuk a kép rajzolásához szükséges vonaldarabok (vektorok) adatait, és ennek alapján megrajzolhatjuk a képet. Az ilyen tárolási módot vektoros képtárolásnak hívjuk. A IV.58. ábra - Vektoros A egy nagy A rajzolatát mutatja vektorosan.

Lehetőségünk van arra is, hogy a képet képpontokra (raszterpontokra) osszuk és minden egyes pontról tároljuk annak színét. Ezt a raszteres képet a térképhez való hasonlatossága miatt bitképnek hívjuk. A IV.59. ábra - Raszteres A egy ilyen fekete-fehér bitképét mutatja egy A betűnek.
Az Image egy absztrakt képtároló osztály mely, őse Windows rajzokat tartalmazó raszteres System::Drawing::Bitmap és vektoros System::Drawing::Imaging::MetaFile osztályoknak. Image objektumok létrehozására az Image osztály statikus metódusait használjuk, melyekkel a megadott (filename) állományból tölthetünk be képet.
static Image^ FromFile(String^ filename
[, bool useEmbeddedColorManagement]);
static Image^ FromStream(Stream^ stream
[, bool useEmbeddedColorManagement
[, bool validateImageData]]);
Ha a useEmbeddedColorManagement logikai változó igaz, akkor az állományban lévő színkezelési információkat használja a metódus, egyébként nem (az alapértelmezett az igaz érték). Adatfolyam esetén a validateImageData logikai változó a kép adatellenőrzéséről intézkedik. Alaphelyzetben van ellenőrzés. Használhatjuk a régi GDI bitképeket is a FromHbitmap() metódussal.
A betöltött bitképeket kirajzolhatjuk a Graphics::DrawImage(Image,Point) metódussal. Az alábbi példa a Visual Stúdió fejlesztői környezetének képét tölti a formra (IV.60. ábra - Image a formon).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Image^ kep = Image::FromFile( "C:\\VC++.png" );
e->Graphics->DrawImage( kep, Point(10,10) );
}
Az Image osztály tulajdonságai tárolják a kép adatait. Az int típusú Width és Height csak olvasható tulajdonságok a kép szélességét és magasságát adják meg pixelben. A Size struktúra típusú Size csak olvasható tulajdonság is a méreteket tárolja. A float típusú HorizontalResolution és VerticalResolution tulajdonságok a kép felbontását adják meg pixel/inch dimenzióban. A SizeF struktúra típusú PhisicalDimension csak olvasható tulajdonság a kép valódi méreteit adja bitkép esetén pixelben, metafile kép esetén 0,01 mm egységekben.
Az ImageFormat osztály típusú RawFormat tulajdonsággal kép fájlformátumot specifikálhatunk, amit aztán a kép tárolásánál felhasználhatunk. Az
ImageFormat
Bmp tulajdonsága bitképet, az Emf továbbfejlesztett metafilet, az Exif pedig cserélhető képet (Exchangeable Image File) specifikál. A Gif tulajdonságot a szabványos képformátumhoz használhatjuk (Graphics Interchange Format). A Guid tulajdonság a Microsoft által alkalmazott, globális objektumazonosítót választja ki. Az Icon tulajdonságot a Windows Iconhoz használhatjuk. A Jpeg a szabványos (Joint Photographic Experts Group) formátumhoz, a MemoryBmp memória bitképhez, a Png a W3C (World Wide Web Consortium
[4.5.]
) grafikus elemek hálózati átviteléhez (Portable Network Graphics) való tulajdonság. A Tiff a szabványos TIFF formátumhoz (Tagged Image File Format), a Wmf a Windows metafilehoz tartozó formátumot specifikálja.
A Flags int típusú tulajdonság bitjei a kép jellegzetességeit (színkezelés, átlátszóság, nagyítás stb.) szabályozzák. Néhány jellegzetes bitállásnak megfelelő konstans az ImageFlagsNone (0), az ImageFlagsScalable (1), az ImageFlagsHasAlpha (2) ,valamint az ImageFlagsColorSpaceRGB (16).
A képek tárolhatják színeiket a képhez csatlakozó színpalettában. A ColorPaletteClass típusú Palette tulajdonság nem más mint egy színtömb (array<Color>^ Entries) ami a színeket tartalmazza. A ColorPaletteClass osztálynak is van Flags tulajdonsága, melynek bitenkénti értelmezése: a szín tartalmaz alpha információt(1), a szín szürkeskálát rögzít (2), a szín ún. halftone
[4.6.]
információt ad meg, amikor az emberi szemnek szürkeskálának tűnő színeket fekete-fehér elemekből építjük fel (IV.61. ábra - Halftone ábrázolás).
A kép méreteit a megadott grafikus egységben szolgáltatja a
RectangleF GetBounds(GraphicsUnit pageUnit);
metódus.
A
static int GetPixelFormatSize(PixelFormat pixfmt);
megadja, milyen módon tárolt a kép – ez lehet egy paletta index, vagy maga a szín értéke. Néhány lehetséges érték: Gdi – a pixel GDI színkódot tartalmaz (rgb). Alpha - a pixel tartalmaz attetszőséget is, Format8bppIndexed – index, 8 bit per pixel (256) szín.
Lekérdezhetjük, hogy a kép áttetsző-e:
static bool IsAlphaPixelFormat(PixelFormat pixfmt);
hogy a kép pixelformátuma 32 bites-e:
static bool IsCanonicalPixelFormat(PixelFormat pixfmt);
hogy a kép pixelformátuma 64 bites-e:
static bool IsExtendedPixelFormat(PixelFormat pixfmt);
A
void RotateFlip(RotateFlipType rotateFlipType);
metódussal forgatni és tükrözni lehet a képeket a RotateFlipType felsorolás elemeinek megfelelően (pl. Rotate90FlipNone 90 fokkal forgat nem tükröz, RotateNoneFlipX y-tengelyre tükröz, Rotate90FlipXY 90 fokkal forgat és középpontosan tükröz.
Az alábbi példa az y-tengelyre tükrözve teszi ki IV.60. ábra - Image a formon form képét.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Image^ kep = Image::FromFile( "C:\\VC++.png" );
kep->RotateFlip(RotateFlipType::RotateNoneFlipX);
e->Graphics->DrawImage( kep, Point(10,10) );
}
A képeket fájlba menthetjük a
void Save(String^ filename[,ImageFormat^ format]);
metódussal. A filename paraméter a fájl nevét tartalmazza, a kiterjesztés a filename kiterjesztésétől függ. Az opcionális format paraméterrel definiálhatjuk a mentés formátumát. Ha nincs kódoló információ a fájlformátumokhoz (mint pl a Wmf), akkor a metódus Png formátumba ment. Adatfolyamba is menthetjük a kép adatait a
void Save(Stream^ stream, ImageFormat^ format);
metódussal.
A Bitmap az Image leszármazottja, így az Image összes tulajdonságát és funkcióját örökli, azonban a Bitmap adatstruktúrája megfelel a memóriában való tárolásnak, így egy sor speciális metódus használatára is lehetőség nyílik. A Bitmap osztálynak vannak konstruktorai, melyek segítségével bitképet hozhatunk létre Image-ből Stream-ból, fájlból, sőt akármilyen grafikából, illetve memóriában tárolt pixel-információkból.
Üres – adott méretű (width, height paraméterek) – bitképet készít a
Bitmap(int width, int height[,, PixelFormat format]);
konstruktor. Amennyiben használjuk a PixelFormat típusú format paramétert, akkor a szímmélységet is szabályozhatjuk, mint azt láttuk az Image::GepPixelFormatSize() metódusnál . A
Bitmap(Image^ original);
Bitmap(Image^ original, Size newSize);
Bitmap(Image^ original, int width, int height);
konstruktorok a paraméterként megadott Image-ből készítenek bitképet. Ha megadjuk a newSize paramétert, vagy a width és height paramétereket, akkor a bitkép az Image képének az új méretekre való átskálázásával jön létre. A
Bitmap(Stream^ stream[, bool useIcm]);
túlterhelt konstruktorral stream-ből készíthetünk bitképet, a
Bitmap(String^ filename[, bool useIcm]);
túlterhelt konstruktorral fájlból. A useIcm logikai paraméterrel azt szabályozhatjuk, hogy használjunk-e színkorrekciót vagy sem. Bármilyen Graphics példányról, pl. a képernyőről készíthetünk bitképet a
Bitmap(int width, int height, Graphics^ g);
konstruktorral. A width és height egészek a méreteket definiálják, a g paraméter a rajzlappéldány, ennek DpiX és DpiY tulajdonsága, ami a bitmap felbontását adja. A scan0 egészre mutató pointer által kijelölt memóriából is gyárthatunk bitképet, ha megadjuk a width szélességét, a height magasságát és a stride értéket, vagyis két bitképsor közti különbséget bájtban
Bitmap(int width, int height, int stride,
PixelFormat format, IntPtr scan0);
Egy újonnan létrahozott bitkép felbontását beállíthatjuk a
void SetResolution(float xDpi, float yDpi);
metódussal. A paramétereket dot per inch mértékegységben kell megadni.
Néhány, nem az Image osztálytól örökölt metódus egészíti ki a bitképek lehetőségeit. Közvetlen módon hozzáférünk a bitkép egy pontjához. A megadott képpont (x, y) színét adja vissza a
Color GetPixel(int x, int y);
metódus. Átszínezhetjük a bitkép pontjait a
void SetPixel(int x, int y, Color color);
metódussal a color paraméter segítségével.
A
void MakeTransparent([Color transparentColor]);
függvény átlátszóvá teszi a bitképen beállított átlátszó színt. Ha a transparenColor paramétert is megadjuk, akkor az válik átlátszóvá.
Az alábbi példa beolvas egy bitképet, és kirajzolja azt, majd a fehér színhez közeli színű pontjait zöldre festi, és az így módosított bitképet kirajzolja. A következő lépésben a zöld színt átlátszóvá teszi és félig eltolva újra kirajzolja a bitképet (IV.63. ábra - Bitkép színezés).
private: System::Void Form1_Click(System::Object^ sender,
System::EventArgs^ e) {
Bitmap ^ bm = gcnew Bitmap("C:\\D\\X.png");
Graphics ^ g = this->CreateGraphics();
g->DrawImage( bm, Point(0,0) );
Color c;
for (int i=0; i<bm->Width; i++) {
for (int j=0; j<bm->Height; j++) {
Color c=bm->GetPixel(i,j);
if ((c.R>200)&&(c.G>200)&&(c.B>200))
bm->SetPixel(i,j,Color::Green);
}
}
g->DrawImage( bm, Point(bm->Width,bm->Height) );
}
A GetPixel() és SetPixel () metódusokkal való bitkép kezelés nem elég hatékony. Lehetőségünk van arra, hogy a bitkép bitjeit memóriába töltsük, és azokat módosítsuk, majd visszapumpáljuk a biteket a bitképbe. Ilyenkor gondoskodnunk kell arról, hogy az operációs rendszer ne zavarja műveleteinket. A bitképek memóriában való rögzítésére használhatjuk a
BitmapData^ LockBits(Rectangle rect, ImageLockMode flags,
PixelFormat format[, BitmapData^ bitmapData]);
void UnlockBits(BitmapData^ bitmapdata);
függvényt. A rect paraméter a bitkép rögzíteni kívánt részét jelöli ki, a felsorolás típusú ImageLockMode flags (ReadOnly, WriteOnly, ReadWrite, UserInputBuffer) az adatok kezelésének módját. A PixelFormat felsorolással már többször találkoztunk, a bitmapdata elhagyható paraméter BitmapData osztály típusú, melynek tulajdonságai a Height és Width a bitkép méretei, a Stride a scanline szélessége, a scan0 az első pixel címe. A visszatérési érték is BitmapData referencia osztály példányában tartalmazza a bitkép adatait.
A függvény hívása után a bitmapdata rögzítve van, így azt kezelhetjük a Marshal osztály metódusaival. A
System::Runtime::InteropServices
::Marshal osztály metódusaival nem menedzselt memóriát foglalhatunk, másolhatjuk a nem menedzselt memóriadarabokat, illetve menedzselt memóriaobjektumokat másolhatunk nem menedzselt memóriaterületre. Például, a Marshal osztály
static void Copy(IntPtr source,
array<unsigned char>^ destination,
int startIndex, int length);
metódusa a source pointer által jelölt területről a destination menedzselt tömbbe másol a kezdő indextől length darab bájtot
static void Copy(array<unsigned char>^ source,
int startIndex,
IntPtr destination, int length);
metódus visszafelé, a source menedzselt tömbből a startindex indextől másol a destination nem menedzselt területre length db byte-ot.
Ha kimásoltuk a bitkébből a változtatni kívánt részleteket, majd megváltoztattuk és visszamásoltuk, akkor a memóriarögzítés feloldását az
v oid UnlockBits(BitmapData^ bitmapdata);
metódussal végezhetjük el.
Az alábbi példa a formon kattintásra egy memóriába olvasott menedzselt bitképet kirajzol, majd rögzít, kiemeli kép bájtjait, a kép középső harmadát törli, visszaolvassa az adatokat a bitképbe, és elengedi a rögzítést és kirajzolja.
private: System::Void Form1_Click(System::Object^ sender,
System::EventArgs^ e) {
Bitmap ^ bm = gcnew Bitmap("C:\\D\\X.png");
Graphics ^ g = this->CreateGraphics();
g->DrawImage( bm, Point(0,0) );
Rectangle rect = Rectangle(0,0,bm->Width,bm->Height);
System::Drawing::Imaging::BitmapData^ bmpData = bm- >LockBits(
rect, System::Drawing::Imaging::ImageLockMode::ReadWrite,
bm->PixelFormat );
IntPtr ptr = bmpData->Scan0;
int bytes = Math::Abs(bmpData->Stride) * bm->Height;
array<Byte>^Values = gcnew array<Byte>(bytes);
System::Runtime::InteropServices::Marshal::Copy( ptr, Values,
0, bytes );
for ( int counter = Values->Length/3;
counter < 2*Values->Length/3; counter ++ ) {
Values[ counter ] = 255;
}
System::Runtime::InteropServices::Marshal::Copy( Values, 0,
ptr, bytes );
bm->UnlockBits( bmpData );
g->DrawImage( bm, bm->Width, 0 );
}
Metafájlokkal is dolgozhatunk, hiszen használhatjuk az Image osztály metódusait. Az alábbi példa beolvas egy Png állományt egy bitképbe és azt Wmf metafileként tárolja:
private: System::Void Form1_Click(System::Object^ sender,
System::EventArgs^ e) {
Bitmap ^ bm = gcnew Bitmap("C:\\D\\X.png");
Graphics ^ g = this->CreateGraphics();
g->DrawImage( bm, bm->Width, 0 );
bm->Save("C:\\D\\X.wmf");
}
IV.4.10. Ecsetek
Területek kifestésére ecseteket használhatunk a GDI+-ban
[4.1.]
[4.2.]
. Az összes ecsettípus a System::Drawing::Brush osztály leszármazottja (IV.30. ábra - A GDI+ osztályai ). A legegyszerűbb ecset az egyszínű (SolidBrush). Ennek konstruktora egy megadott színből hoz létre ecsetet. Ennek megfelelően az osztály Color tulajdonsága felveszi az ecset színét.
SolidBrush(Color color);
Az alábbi példa egy piros téglalapot (a Graphics osztály FillRectangle() metódusával) fest ki a formon (IV.65. ábra - Ecsetek).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
SolidBrush ^ sb = gcnew SolidBrush(Color::Red);
e->Graphics->FillRectangle(sb,200,20,150,50);
}
Az mintázott ecset HatchBrush szintén a Brush osztály leszármazottja és a System::Drawing::Drawing2D névtérben definiált, ezért szükséges azt beépíteni.
using namespace System::Drawing::Drawing2D;
A mintázott ecset konstruktora definiálja az ecset mintázatát, a mintázat színét és a háttérszínt. Ha az utolsó paramétert elhagyjuk (a szögletes zárójel jelzi az elhagyható paramétert), akkor a háttérszín fekete lesz.
HatchBrush(HatchStyle hatchstyle, Color foreColor,
[Color backColor])
A Drawing2D névtér HatchStyle felsorolása rengeteg előre definiált mintázatot tartalmaz. HatchStyle::Horizontal a vízszintes, Vertical a függőleges, ForwardDiagonal átlós (balra dől) stb. Az alábbi példa piros sraffozott ecsettel fest ki sárga téglalapot (IV.65. ábra - Ecsetek).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
HatchBrush ^ hb = gcnew HatchBrush(HatchStyle::ForwardDiagonal,
Color::Red,Color::Yellow);
e->Graphics->FillRectangle(hb,200,80,150,50);
}
A mintázott ecsetek jellemző tulajdonságai a BackGroundColor a hátérszín, ForegroundColor az előtér szín és a HatchStyle a mintázat.
A TextureBrush osztály példányaival képekkel festő ecseteket hozhatunk létre. A konstruktorok
TextureBrush(Image^ image);
TextureBrush(Image^ image, WrapMode wrapMode);
TextureBrush(Image^ image, Rectangle dstRect);
TextureBrush(Image^ image, RectangleF dstRect);
TextureBrush(Image^ image, WrapMode wrapMode,
Rectangle dstRect);
TextureBrush(Image^ image, WrapMode wrapMode,
RectangleF dstRect);
TextureBrush(Image^ image, Rectangle dstRect,
ImageAttributes^ imageAttr);
TextureBrush(Image^ image, RectangleF dstRect,
ImageAttributes^ imageAttr);
Az image a kifestéshez használt képet, a dstRect a kép kifestéskori torzítását adja meg, a wrapMode a képeknél megismert módon a kifestő képek elrendezésére utal (WrapMode felsorolás elemei Tile – mintha téglákból lenne kirakva, TileFlipX – y tengelyre tükrözött téglákból kirakva, TileFlipY - x tengelyre tükrözött téglákból kirakva, TileFlipXY középpontosan tükrözött téglákból kirakva, Clamped nem téglákból kirakott a textúra). Az imageAttr paraméter a kép manipulációjáról intézkedik (színek, színkorrekciók, kifestési módok stb.).
A TextureBrush osztály Image^ típusú Image tulajdonsága a kifestő grafikát adja meg a Transform ^ típusú Transform tulajdonsága és annak metódusai a transzformációknál megismert módon használható. A WrapMode tulajdonság az elrendezést tartalmazza.
Az alábbi példa képekkel fest ki egy téglalapot (IV.65. ábra - Ecsetek).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Image ^ im = Image::FromFile("c:\\M\\mogi.png");
TextureBrush ^ tb = gcnew TextureBrush(im);
Matrix ^ m= gcnew Matrix();
m->Translate(5,5);
tb->Transform->Reset();
tb->Transform=m;
Graphics ^ g = this->CreateGraphics();
g->FillRectangle(tb, 200, 140, 150, 50);
}
A Drawing2D névtér tartalmazza a LinearGradientBrush osztályt, melynek konstruktoraival színjátszó ecseteket készíthetünk. A különböző konstruktorokkal más és más színátmeneteket állíthatunk be. System::Windows::Media::BrushMappingMode felsorolás a színjátszáshoz határoz meg koordináta-rendszert. E felsorolás értékei Absolute a pontok az aktuális koordináta-rendszerben értelmezettek. A RelativeToBoudingBox beállítás esetén az adott kifestés befoglaló téglalapjának bal felső sarka=(0,0), jobb alsó sarka (1,1).
A
LinearGradientBrush(Rectangle rect,
Color startColor, Color endColor,
double angle, [isAgleScaleable]);
LinearGradientBrush(RectangleF rect,
Color startColor, Color endColor,
double angle, [isAgleScaleable]);
LinearGradientBrush(Point startPoint, Point endPoint,
Color startColor, Color endColor);
LinearGradientBrush(PointF startPoint, PointF endPoint,
Color startColor, Color endColor);
LinearGradientBrush(Rectangle rect,
Color startColor, Color endColor
LinearGradientMode lgm);
LinearGradientBrush(RectangleF rect,
Color startColor, Color endColor,
LinearGradientMode lgm);
konstruktorok lineáris gradiens ecsetet hoznak létre, a kezdő szín (startColor)és a végső szín (endColor) felhasználásával. A RelativeToBoudingBox ecsetkoordináta-rendszerben a gradiens irányszögét az angle paraméterrel adjuk meg fokban (0 – vízszintes gradiens, 90 – függőleges) vagy startPoint és az endPoint pontokkal, illetve a rect sarkaival, a % mértékegységben. A LinearGradientMode felsorolás elemei Horizontal, Vertical, ForwardDiagonal, BackwardDiagonal a színváltozás irányt adják meg.
A
PathGradientBrush(GraphicsPath path);
PathGradientBrush(Point[] points);
PathGradientBrush(PointF[] points);
PathGradientBrush(Point[] points, WrapMode wrapMode);
konstruktorokkal létrehozhatunk egy vonal mentén változó színű ecsetet. A vonalat a path, illetve points paraméterekkel definiálhatjuk. A wrapMode WrapMode típusú paraméterrel már találkoztunk a textúra ecseteknél.
Mindkét gradiens ecset rendelkezik a kifestés ismétlésének módját definiáló WrapMode tulajdonsággal, a lokális transzformációt tartalmazó Transform tulajdonsággal. Mindkét gradiens ecset tartalmaz Blend osztály típusú Blend tulajdonságot. A Blend osztály Factors és Positions tulajdonságai float tömbök 0 és 1 közötti értékkel, melyek megadják a százalékos színintenzitást és a százalékos hosszpozíciót adják meg. Mindkét gradiens ecsetnek van InterpolationColors (ColorBlend osztály típusú) tulajdonsága is, ahol a százalékos pozíciók mellett az intenzítás helyett a színeket adhatjuk meg. Mindkét gradiens ecsetnek van határoló Rectangle tulajdonsága.
A PathGradientBrush SurroundColors színtömb tulajdonsága tartalmazza a felhasznált színeket.
Lehet az ecset áttetsző is az ARGB színhasználattal. Az alábbi példa a különbözően kifestett téglalapok fölé áttetsző téglalapot rajzol.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
SolidBrush ^ sb = gcnew SolidBrush(Color::Red);
e->Graphics->FillRectangle(sb,200,20,150,50);
HatchBrush ^ hb = gcnew HatchBrush(
HatchStyle::ForwardDiagonal,
Color::Red,Color::Yellow);
e->Graphics->FillRectangle(hb,200,80,150,50);
Image ^ im = Image::FromFile("c:\\M\\mogi.png");
TextureBrush ^ tb = gcnew TextureBrush(im);
Matrix ^ m= gcnew Matrix();
m->Translate(5,5);
tb->Transform->Reset();
tb->Transform=m;
e->Graphics->FillRectangle(tb, 200, 140, 150, 50);
LinearGradientBrush ^ lgb = gcnew LinearGradientBrush(
PointF(0,0), PointF(100,100), Color::Blue, Color::Red);
e->Graphics->FillRectangle(lgb, 200, 200, 150, 50);
SolidBrush ^ at = gcnew SolidBrush(
Color::FromArgb(127,Color::Red));
e->Graphics->FillRectangle(at, 250, 10, 200, 270);
}
IV.4.11. Tollak
Vonalas ábrákat tollal rajzolhatunk. A tollaknak van színük, és vastagságuk.
Pen(Brush brush [, float width]);
Pen(Color color [, float width]);
A Pen osztály konstruktoraival color színnel vagy brush ecsettel definiált tollat hozhatunk létre. A width paraméterrel a toll vastagságát is definiálhatjuk.
A Brush a Color és a Width tulajdonságok tárolhatják a toll ecsetét, színét és vastagságát.
A DashStyle tulajdonság a DashStyle felsorolás (
System::Drawing::Drawing2D
névtér) egy értékét veheti fel, beállítva ezzel a toll mintázatát (Solid – folytonos, Dash – szaggatott, Dot – pontokból rajzolt vonal, DashDot – pontvonal, DashDotDot pontvolnal dupla ponttal, illetve Custom). Az utolsó vonalstílus esetén magunk definiálhatjuk a mintázatot a DashPattern float tömb egymást követő számai a vonal- és a szünet hosszakat definiálják.
A float típusú DashOffset tulajdonsággal a vonal kezdőpontja és a szaggatás kezdete közti távolságot adhatjuk meg. Szaggatott vonalak esetén a DashCap (
System::Drawing::Drawing2D
) azt is megadhatjuk milyen végei legyenek a vonalaknak. A DashCap felsorolás értékei Flat – sima, Round lekerekített, Triangle – háromszögű.
Az Alignment tulajdonság a PenAligment típusú felsorolás egyik értéke lehet (
System::Drawing::Drawing2D
névtér), és arról intézkedik az alakzat éléhez képest hova kerül a vonal (Center – felező, Inset – zárt alakzat belseje, OutSet – zárt alakzaton kívül, Left – a vonal „bal partjára”, Right – a vonal „jobb partjára”).
Figurák vonalainak csatlakozási geometriájára használhatjuk a LineJoin felsorolás típusú LineJoin tulajdonságot (Bevel – szögben letört sarok, Round – lekerekített, a Miter és a MiterClipped szintén letört csatlakozás, ha a letörés hossza nagyobb, mint az float típusú MiterLimit határérték).
A vonalvégek rajzolatának szabályozására a StartCap és az EndCap
System::Drawing::Drawing2D::LineCap
felsorolás típusú tulajdonság szolgál (Flat – sima, Square - négyzet, Round – lekerekített – ArrowAnchor – nyíl vég, RoundAnchor – körlap-vég stb.). Érdekes lehet a CustomStartCap és a CustomEndCap tulajdonság, melyek a CustomLineCap osztály példányai. A példány a
CustomLineCap(GraphicsPath fillPath, GraphicsPath strokePath
[, LineCap baseCap[, float baseInset]]);
konstruktorral hozható létre. Figurával definiálhatjuk a kitöltést (fillPath) és a körvonalat (strokePath). Kiindulhatunk egy meglévő vonalvégből (baseCap), illetve beállíthatjuk a rést a vonal és a vége alakzat között (baseInset). A CustomLineCap BaseCap tulajdonsága az ős vonalvéget azonosítja a BaseInset a rést. Definiálhatjuk a vonalak csatlakozási módját (StrokeJoin), illetve beállíthatunk egy vastagsági skálázást (WidthScale tulajdonság). Alaphelyzetben ez a vonal vastagsága.
A Pen osztály PenType csak olvasható PenType felsorolás típusú tulajdonságából megtudhatjuk, milyen típusú a toll (SolidColor, HatchFill, TextureFill, LinearGradient, PathGradient)
Természetesen a tollak is rendelkeznek Transform – lokális transzformációt definiáló – tulajdonságuk.
Az alábbi példa piros, folytonos vonallal, majd lineáris gradiens-ecsettel definiált tollal húz vonalat. Ezt követően vonalat húz az egyik oldalon nyíllal, a másik oldalon kerek véggel. Ezek után két szaggatott vonal következik, az egyik előre definiált mintával, a másik mintatömbbel. Ezt két téglalap figura követi az egyik letört és az alapértelmezett OutSet Alignment tulajdonsággal, a másik InSet tulajdonsággal, letörés nélkül (IV.66. ábra - Tollak).
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Pen ^ ps = gcnew Pen(Color::Red,5);
e->Graphics->DrawLine(ps,10,25,100,25);
LinearGradientBrush ^ gb = gcnew LinearGradientBrush(
PointF(10, 10), PointF(110, 10),
Color::Red, Color::Blue);
Pen ^ pg = gcnew Pen(gb,5);
e->Graphics->DrawLine(pg,10,50,100,50);
ps->StartCap=LineCap::ArrowAnchor;
pg->EndCap=LineCap::Round;
e->Graphics->DrawLine(pg,10,75,100,75);
pg->DashStyle=DashStyle::DashDot;
e->Graphics->DrawLine(pg,10,100,100,100);
array <float> ^ dp= {1.0f,0.1f,2.0f,0.2f,3.0f,0.3f};
pg->DashPattern=dp;
e->Graphics->DrawLine(pg, 10, 125, 100, 125);
GraphicsPath^ mp = gcnew GraphicsPath;
RectangleF srcRect = RectangleF(10,150,100,20);
mp->AddRectangle( srcRect );
ps->LineJoin=LineJoin::Bevel;
e->Graphics->DrawPath( ps , mp );
Matrix ^ em = gcnew Matrix();
em->Reset();
em->Translate(0,25);
mp->Transform(em);
pg->Alignment=PenAlignment::Inset;
e->Graphics->DrawPath( pg , mp );
}
IV.4.12. Font, FontFamily
A Windows-ban a karakterkészletek három alapvető típusát különböztethetjük meg. Az egyik esetben a karakter megjelenítéséhez szükséges információt bitkép tárolja. A második esetben a vektoros tárolású fontok azt rögzítik, hogy milyen vonalakat kell meghúzni egy karakter megrajzolásához. A harmadik eset az ún. TrueType karakterkészlet esete, amikor a karakterek definíciója pontok és speciális algoritmusok halmaza, amelyek mindenféle felbontáshoz képesek definiálni a karaktereket. Amikor TrueType karakterkészletet használunk, akkor az ún. TrueType raszterizáló a pontokból és az algoritmusokból elkészíti az adott igényeknek megfelelő bittérképes karakterkészletet. Ennek eredménye, ha egy kiadványszerkesztőben megtervezzük a kinyomtatandó lapot, akkor az nyomtatáskor ugyanolyan lesz, mint azt a képernyőn láttuk (WYSIWYG - What You See Is What You Get). A TrueType fontok használatának jogát a Microsoft az Apple Computer-től [4.] [8] [.] vette meg. Nyilvánvaló az első két karakterábrázolásnak van előnye és hátránya. A vektoros fontok tetszőleges mértékben kicsinyíthetők, nagyíthatók, azonban megjelenítésük sok esetben nem elég esztétikus és nem olvasható. A bitképes fontok általában jól olvashatók, azonban nem deformálhatók szabadon. A TrueType típusú karakterkészlet használata biztosítja a fenti előnyöket, és egyúttal kiküszöböli a hátrányokat.
Ismerkedjünk meg néhány fogalommal, melyek segítenek eligazodni a fontok világában! Alapvető kérdés a karakterek megjelenítésekor a betű vonalának módosíthatósága. Lehet-e vékonyabb, illetve vastagabb betűrajzolatot használni? A betű vonalát az angol irodalom "stroke" névvel illeti.
Több karakterkészlet létezik, amelyben a betű megrajzolásakor használt vonalakat kis keresztvonalakkal zárják. A betűknek kis talpa, illetve kalapja lesz. Ezt a kis keresztvonalat az angol "serif"-nek hívja. Így az a karakterkészlet, melyben nincsenek ilyen kis záró "serif"-ek a "sanserif" azaz serif néküli.
Karaktercellának hívjuk azt a téglalap alakú területet, mely a karaktert befoglalja. Ennek méretét jellemezhetjük az emSize paraméterrel, amely a karakter méretét pontokban (1/72 inch) tárolja. Az em előtag a M betű kiejtéséből adódik, mert ezt használják a betűtípus méretezésére. A karakterek nem teljesen töltik ki a cellát. A cellára jellemző a szélessége, magassága és a kezdőpontja, amely általában a bal felső sarok. A karaktercellát egy vízszintes vonal osztja két részre. Erre a vonalra - a bázis vonalra - vannak ráültetve a karakterek. A karaktercella bázisvonal feletti részét "ascent" névvel, a bázisvonal alatti részét "descent" névvel illeti az angol. Két egymás alá helyezett karaktercella bázisvonalainak távolsága a "leading". A bázisvonalra írt nagybetűk sem érik el a karaktercella tetejét.
A karaktercella felső széle és a nagybetűk felső széle közti rész a belső "leading". Ha a két egymás alá helyezett karaktercella felső és alsó éle nem érintkezik, akkor a kettő közti távolság a külső leading.

Egy karaktertípus adott méretét nevezik betűtípusnak (typeface). A Windows az adott méretben torzítással képes betűtípusokat létrehozni. A dőlt betűket (italic) egyszerűen úgy hozza létre, hogy a karakter pontjai a bázisvonalon változatlanok maradnak, míg a karakter többi része a bázisvonaltól való távolság függvényében elcsúszik (a karakter megdől). A kövér betűk (bold) egyszerűen a stroke megvastagításából származtathatók. Nyilvánvaló, hogy egyszerűen létrehozhatók aláhúzott (underlined) és áthúzott (strikeout) karakterek, a megfelelő helyre húzott vízszintes vonallal. Használatos még a "pitch" fogalma, amely azt specifikálja, hogy egy adott fontból hány karaktert kell egymás mellé írni, hogy a kiírt szöveg szélessége egy inch (~2.54 cm) legyen. Érdemes megjegyezni, hogy a képernyőn való megjelenítéshez a logikai inch-et használjuk. A logikai inch nagysága úgy van meghatározva, hogy a képernyőn is ugyanolyan jól olvasható legyen a szöveg, mint a papíron. Két alapvető font típus létezik. Az egyik a nem proporcionális - fix méretű -, amelyben minden karakter azonos szélességű cellában van elhelyezve, legyen az akár "i" akár "m". Újabban az ilyen betűtípusokat monospace fontoknak hívják. A másik a proporcionális (azaz arányos) - ebben az esetben a cella szélessége függ az adott betűtől. Az utóbbi esetben csak az átlagos karakterszélességek, az átlagos és a maximális pitch méretek használhatók.
Érdemes foglalkozni a karakterek oldalarányaival is, hiszen nem minden font lenne megjeleníthető mindenféle output eszközön (pl. mátrixnyomtató). A Windows képes oldalarány-konverziót végrehajtani, a megjelenítés érdekében. A Windows karakterkészlet családokat használ attól függően, hogy milyen a karakterek megjelenése.
A hagyományos karakterkészletek a karakterek méreteinek jellemzésére az ábrán (IV.68. ábra - Hagyományos karakter szélességek) megjelenő adatokat használják. A TrueType karakterkészletek a fenti hagyományos értelmezés helyett az ún. ABC adatokat használják. Mint ahogy az az ábrán (IV.69. ábra - ABC karakterszélességek) látszik, az A és a C értékek lehetnek negatívok is.
A fontcsaládok hasonló jellegzetességgel bíró betűtípusokat tartalmaznak. A fontcsaládok modellezésére a .Net a nem örököltethető FontFamily osztályt definiálja. A FontFamily példányt a
FontFamily(GenericFontFamilies genericFamily);
FontFamily(String^ name[, FontCollection^ fontCollection]);
konstruktorokkal hozhatunk létre. A genericFamily paraméter értékét a GenericFontFamilies felsorolás elemei közül választhatjuk ki a család létrehozásához. A felsorolás lehetséges értékei (Serif, SansSerif és Monospace) már ismert fogalmakat takarnak. A name paraméter az új fontcsalád nevét tartalmazza. Lehet üres sztring, vagy a gépre nem telepített fontcsalád neve, vagy egy nem TrueType font neve. A fontcsaládokból gyűjteményeket is készíthetünk. A fontCollection paraméterrel megadhatjuk a gyűjteményt, amibe behelyezhetjük az új fontcsaládot.
A FontFamily osztály tulajdonságaival tájékozódhatunk lehetőségeinkről. A statikus Families tulajdonsággal lekérdezhetjük az aktuális rajzlap fontcsaládjait egy FontFamily típusú tömbbe. A FontFamily típusú statikus GenericMonospace, GenericSansSerif és GenericSerif tulajdonsgok egy nem proporcionális, egy sansserif, illetve egy serif fontcsaláddal térnek vissza. A Name string tulajdonság a fontcsalád nevét tartalmazza.
A statikus
static FontFamily[] GetFamilies(Graphics graphics);
metódus visszatér az adott rajzlapon található összes fontcsalád nevével.
Az alábbi példa a formon való kattintásra egy listaablakba olvassa a rajzlap összes fontcsaládjának nevét.
private: System::Void Form1_Click(System::Object^ sender,
System::EventArgs^ e) {
Graphics ^ g = this->CreateGraphics();
array <FontFamily ^> ^ f = gcnew array<FontFamily^>(100);
f=FontFamily::GetFamilies(g);
for (int i=0; i<f->GetLength(0); i++) {
listBox1->Items->Add(f[i]->Name);
}
}
A
int GetCellAscent(FontStyle style);
int GetCellDescent(FontStyle style);
int GetEmHeight(FontStyle style);
int GetLineSpacing(FontStyle style);
String^ GetName(int language);
metódusok az adott fontcsalád style paraméterrel megadott adatait kérdezik le. A
bool IsStyleAvailable(FontStyle style);
metódus azt vizsgálja, hogy az adott fontcsaládnak van-e style stílusa.
FontStyle felsorolás értékei: Bold, Italic, Underline és Strikeout.
A GDI+ a betűtípusok modellezésére a Font osztályt használja. Az osztály példányait a
Font(FontFamily^ family, float emSize[, FontStyle style
[, GraphicsUnit unit [, unsigned char gdiCharSet
[, bool gdiVerticalFont]]]]);
Font(FontFamily^ family, float emSize, GraphicsUnit unit);
Font(String^ familyName, float emSize[, FontStyle style
[, GraphicsUnit unit[, unsigned char gdiCharSet
[, bool gdiVerticalFont]]]]);
Font(String^ familyName, float emSize, GraphicsUnit unit);
Font(Font^ prototype, FontStyle newStyle);
konstruktorokkal hozhatjuk létre. A family paraméter az új font családját, a familyName a család nevét adja meg. Az emSize a font mérete pontban, a style a betűstílusa (dőlt, kövér stb.). A unit paraméter a font által használt egységeket (Pixel, Inch, Millimeter stb.) adja meg. A gdiCharset a GDI+ által biztosított karakterkészleteket azonosítja. A gdiVerticalFont a függőleges írást szabályozza. Új fontot is definiálhatunk a prototype prototípussal, és az új newStyle stílussal.
A Font osztály tulajdonságai csak olvashatók. Ha valamit meg szeretnénk változtatni, akkor új fontot kell létrehoznunk. FontFamily^ típusú FontFamily tulajdonság a fontcsaládot azonosítja. A Name sztring a font nevét, az OriginalFontName sztring pedig a font eredeti nevét adja. Ha az IsSystemFont logikai tulajdonság igaz, rendszerfonttal van dolgunk – ilyenkor a SystemFontName sztring tulajdonság a rendszerfont nevét adja. A GdiVerticalFont logikai tulajdonság megadja, hogy a font függőleges-e. A GdiCharSet bájt típusú tulajdonság a GDI karakterkészlet azonosítója. A Size (emSize) és SizeInPonts a fontméretet szolgáltatják pontban kifejezve. A Style tulajdonság a FontStyle felsorolás elemeivel (Italic, Bold, Underline és Strikeout) logikai tulajdonságként azonosítják a font stílusát. A Unit megadja a GraphicsUnit mértékegységét.
A
float GetHeight();
metódus a sorok közt mérhető távolságot adja pixelben. A
float GetHeight(Graphics^ graphics);
metódus a sorok közt mérhető távolságot adja GraphicsUnit-ban. A
float GetHeight(float dpi);
metódus a sorok közt mérhető font távolságot adja pixelben az adott dpi (dot per inch – pont per inch) felbontású eszközön.
Az alábbi példa a Tipus gomb megnyomására választott font torzítását szemlélteti a Bold, Italic és Underline opciógombokkal (IV.71. ábra - Font torzítások).
IV.4.13. Rajzrutinok
A Graphics osztály egy sor rajzrutint kínál. Letörölhetjük a teljes rajzlapot az adott színnel (color)
void Clear(Color color);
A következő rajzrutinokban a pen a rajzolás tollát azonosítja. Egyenes vonalszakaszokat húzhatunk a
void DrawLine(Pen^ pen, Point pt1, Point pt2);
void DrawLine(Pen^ pen, PointF pt1, PointF pt2);
void DrawLine(Pen^ pen, int x1, int y1, int x2, int y2);
void DrawLine(Pen^ pen, float x1, float y1, float x2, float y2);
metódusokkal. A pt1, pt2, (x1,y1) és (x2,y2) a végpontok .
Törtvonalakat rajzolnak a
void DrawLines(Pen^ pen, array<Point>^ points);
void DrawLines(Pen^ pen, array<PointF>^ points);
metódusok. A points a sarokpontokat határozza meg.
Téglalapokat rajzolhatunk a
void DrawRectangle(Pen^ pen, Rectangle rect);
void DrawRectangle(Pen^ pen, int x, int y,
int width, int height);
void DrawRectangle(Pen^ pen, float x, float y,
float width, float height);
metódusok segítségével. A téglalap adatait a rect struktúra, vagy az (x,y) bal felső sarok, width szélesség és height magasság határozzák meg.
Egy sor, a rects tömbbel meghatározott téglalapot rajzolhatunk egyszerre a
void DrawRectangles(Pen^ pen, array<Rectangle>^ rects);
void DrawRectangles(Pen^ pen, array<RectangleF>^ rects);
metódussal.
A points struktúratömbbel meghatározott sokszöget rajzolnak az alábbi metódusok:
void DrawPolygon(Pen^ pen, array<Point>^ points);
void DrawPolygon(Pen^ pen, array<PointF>^ points);
A rect struktúra, vagy az (x,y) és (height, width) adatok által meghatározott befoglaló téglalappal rendelkező ellipszist rajzolnak a
void DrawEllipse(Pen^ pen, Rectangle rect);
void DrawEllipse(Pen^ pen, RectangleF rect);
void DrawEllipse(Pen^ pen, int x, int y, int width, int height);
void DrawEllipse(Pen^ pen, float x, float y,
float width, float height);
metódusok.
Az (IV.48. ábra - Ellipszisív) ábrának megfelelő ellipszisívet rajzolhatunk a
void DrawArc(Pen^ pen, Rectangle rect,
float startAngle, float sweepAngle);
void DrawArc(Pen^ pen, RectangleF rect,
float startAngle, float sweepAngle);
void DrawArc(Pen^ pen, int x, int y, int width, int height,
int startAngle,int sweepAngle);
void DrawArc(Pen^ pen, float x, float y,
float width, float height,
float startAngle, float sweepAngle);
metódusokkal. A
void DrawPie(Pen^ pen, Rectangle rect,
float startAngle, float sweepAngle);
void DrawPie(Pen^ pen, RectangleF rect,
float startAngle, float sweepAngle);
void DrawPie(Pen^ pen, int x, int y, int width, int height,
int startAngle,int sweepAngle);
void DrawPie(Pen^ pen, float x, float y,
float width, float height,
float startAngle, float sweepAngle);
metódusok tortaszeletet rajzolnak az ívből (egyenesek a középponthoz).
A7 (IV.49. ábra - A harmadfokú Bezier-görbe) ábrának megfelelő Bezier-görbét rajzolnak a
void DrawBezier(Pen^ pen, Point pt1, Point pt2,
Point pt3, Point pt4);
void DrawBezier(Pen^ pen, PointF pt1, PointF pt2,
PointF pt3, PointF pt4);
void DrawBezier(Pen^ pen, float x1, float y1,
float x2, float y2,
float x3, float y3,
float x4, float y4);
metódusok. A tartópontokat a pt1, pt2, pt3, pt4 struktúrákkal, illetve az x i , y i koordinátákkal definiálhatjuk.
Megadott Bezier görbeláncot rajzolnak a
void DrawBeziers(Pen^ pen, array<Point>^ points);
void DrawBeziers(Pen^ pen, array<PointF>^ points);
metódusok. Az első 4 pont után minden következő három definiál újabb görbeszakaszt.
A
void DrawCurve(Pen^ pen, array<Point>^ points
[, float tension]);
void DrawCurve(Pen^ pen, array<PointF>^ points
[, float tension]);
void DrawCurve(Pen^ pen, array<PointF>^ points,
int offset, int numberOfSegments
[, float tension]);
metódusok kardinális spline-t (IV.52. ábra - Catmull-Rom spline) rajzolnak a megadott tollal (pen) a ponts tömb pontjain keresztül. Megadhatjuk a feszítést (tension) és a figyelembevett görbeszakaszok számát (numberOfSegments).
Zárt spline-okat is rajzolhatunk a
void DrawClosedCurve(Pen^ pen, array<Point>^ points[,
FillMode fillmode]);
void DrawClosedCurve(Pen^ pen, array<PointF>^ points[,
FillMode fillmode]);
Metódusokkal a points tömb pontjain keresztül a fillmode – a már ismert - FillMode felsorolás típus Alternate és Winding értékekkel (IV.47. ábra - Alternate és Winding görbelánc).
Figurát (path) rajzol a
void DrawPath(Pen^ pen, GraphicsPath^ path);
metódus a pen tollal.
A
void DrawString(String^ s, Font^ font, Brush^ brush,
PointF point[, StringFormat^ format]);
void DrawString(String^ s, Font^ font, Brush^ brush,
float x, float y[, StringFormat^ format]);
void DrawString(String^ s, Font^ font, Brush^ brush,
RectangleF layoutRectangle[,
StringFormat^ format]);
metódusok kiírják a rajzlapra a megadott s sztringet az adott font betűtípussal és brush ecsettel. A kiírás helyét megadhatjuk a point , x és y paraméterekkel, valamint a layoutRectangle befoglaló téglalappal. A StringFormat osztály példánya definiálja a megjelenítés formátumát (például a FormatFlags tulajdonság StringFormatFlags felsorolás DirectionRightToLeft, DirectionVertical, NoWrap stb. értékeivel, vagy az Alignment tulajdonságban az Alignment felsorolás Near, Center és Far elemeivel).
Az Icon ikont rajzolhatjuk ki a
void DrawIcon(Icon^ icon, int x, int y);
a metódussal az x, y pontba a rajzlapra. Torzíthatjuk az ikont a targetRectangle téglalapra.
void DrawIcon(Icon^ icon, Rectangle targetRect);
Az ikon tozítatlanul kerül ki a téglalapra a
void DrawIconUnstretched(Icon^ icon, Rectangle targetRect);
a metódussal.
Az image által definiált képet, illetve egy választható részletét (srcRect a megadott srcUnit egységekben) jeleníthetjük meg a point, vagy az (x,y) pontba a
void DrawImage(Image^ image, Point point);
void DrawImage(Image^ image, PointF point);
void DrawImage(Image^ image, int x, int y [, Rectangle srcRect,
GraphicsUnit srcUnit]);
void DrawImage(Image^ image, float x, float y
[, RectangleF srcRect, GraphicsUnit srcUnit]);
a metódusokkal.
A
void DrawImage(Image^ image, Rectangle rect);
void DrawImage(Image^ image, RectangleF rect);
void DrawImage(Image^ image, int x, int y,
int width, int height);
void DrawImage(Image^ image, float x, float y,
float width, float height);
metódusok a rect, illetve az (x, y, width, height) téglalapra torzítják az image képet.
A kép (image) egy téglalapját (srcRect) kirajzolhatjuk a rajz egy téglalapjára (destRect) a
void DrawImage(Image^ image, Rectangle destRect,
Rectangle srcRect, GraphicsUnit srcUnit);
void DrawImage(Image^ image, RectangleF destRect,
RectangleF srcRect, GraphicsUnit srcUnit);
metódusokkal. Meg kell adnunk a forrás téglán a grafikus egységeket (srcUnit).
A fentiekhez hasonló céllal, ha a forrástéglalapot int vagy float sarokpont adatokkal (srcX, srcY) és int vagy float szélesség és magasságadatokkal (srcWidth, srcHeight), adjuk meg, a forrás grafikus egységeit akkor is meg kell adnunk (srcUnit). Ekkor azonban használhatjuk a ImageAttributes osztály egy példányát az átszínezésre (imageAttr), sőt hibakezelő CallBack függvényt is definiálhatunk, és adatokat is küldhetünk a callback függvénynek (callbackData):
void DrawImage(Image^ image, Rectangle destRect,
int srcX, int srcY, int srcWidth, int srcHeight,
GraphicsUnit srcUnit
[, ImageAttributes^ imageAttr
[,Graphics::DrawImageAbort^ callback
[,IntPtr callbackData]]]);
void DrawImage(Image^ image, Rectangle destRect,
float srcX, float srcY,
float srcWidth, float srcHeight,
GraphicsUnit srcUnit[,
ImageAttributes^ imageAttrs
[,Graphics::DrawImageAbort^ callback
[,IntPtr callbackData]]]);
Paralelogrammára torzítottan is kitehetjük a képet a
void DrawImage(Image^ image, array<Point>^ destPoints
[, Rectangle srcRect, GraphicsUnit srcUnit
[, ImageAttributes^ imageAttr[,
Graphics::DrawImageAbort^ callback
[,int callbackData]]]]);
metódussal. Az image a kirajzolni kívánt kép, a destPoints tömb a kép kirajzolásakor a torzított kép paralelogrammájának három pontja. A további paraméterek megegyeznek a legutóbb említett függvényeknél megismertekkel. Az alábbi példa egy képet egyenesen és torzítva is kirajzol.
private: System::Void Form1_Paint(System::Object^ sender,
System::Windows::Forms::PaintEventArgs^ e) {
Image^ mogi = Image::FromFile( "C:\\M\\Mogi.png" );
int x = 100;
int y = 100;
int width = 250;
int height = 150;
e->Graphics->DrawImage( mogi, x, y, width, height );
Point b_f_sarok = Point(100,100);
Point j_f_sarok = Point(550,100);
Point b_a_sarok = Point(150,250);
array<Point>^ cel = {b_f_sarok,j_f_sarok,b_a_sarok};
e->Graphics->DrawImage( mogi, cel);
}

Kifestett alakzatokat is rajzolhatunk a Graphics osztály Fillxxx() metódusaival. A
void FillRectangle(Brush^ brush, Rectangle rect);
void FillRectangle(Brush^ brush, RectangleF rect);
void FillRectangle(Brush^ brush, int x, int y,
int width, int height);
void FillRectangle(Brush^ brush, float x, float y,
float width, float height);
metódusok rect struktúrával, vagy a x,y, height width adatokkal megadott téglalapot festenek a brush ecsettel.
A rects tömb téglalapjait festik ki a
void FillRectangles(Brush^ brush, array<Rectangle>^ rects);
void FillRectangles(Brush^ brush, array<RectangleF>^ rects);
metódusok.
A points paraméter által megadott zárt poligonokat festik ki a brush ecsettel a
void FillPolygon(Brush^ brush, array<Point>^ points
[, FillMode fillMode]);
void FillPolygon(Brush^ brush, array<PointF>^ points,
[FillMode fillMode]);
metódusok. Az opcionális fillMode paraméterrel a kifestés is megadható (Alternate, Winding – Graphics2D).
A
void FillEllipse(Brush^ brush, Rectangle rect);
void FillEllipse(Brush^ brush, RectangleF rect);
void FillEllipse(Brush^ brush, int x, int y,
int width, int height);
void FillEllipse(Brush^ brush, float x, float y,
float width, float height);
metódusok rect struktúrával, vagy x,y, height width adatokkal megadott ellipszist festenek a brush ecsettel.
A rect struktúrával vagy x,y, height width adatokkal megadott ellipszis egy cikkét festik ki a brush ecsettel az alábbi metódusok:.
void FillPie(Brush^ brush, Rectangle rect,
float startAngle, float sweepAngle);
void FillPie(Brush^ brush, int x, int y,
int width, int height,
int startAngle, int sweepAngle);
void FillPie(Brush^ brush, float x, float y,
float width, float height,
float startAngle, float sweepAngle);
A points tömb tartópontjai által meghatározott, zárt kardinális görbe által határolt területet festik ki a brush ecsettel az alábbi metódusok. Esetleg megadhatjuk a kifestés módját (fillmode) és a görbe feszítését (tension) is.
void FillClosedCurve(Brush^ brush, array<Point>^ points, [
FillMode fillmode, [float tension]]);
void FillClosedCurve(Brush^ brush, array<PointF>^ points, [
FillMode fillmode, [float tension]]);
A path figurát festhetjük ki a brush ecsettel a
void FillPath(Brush^ brush, GraphicsPath^ path);
metódussal.
A region régiót festhetjük ki a brush ecsettel a
void FillRegion(Brush^ brush, Region^ region);
metódussal.
A képernyő egy pontjával (upperLeftSource vagy sourceX, sourceY) a blocskRegionSize méretű téglalapot másolhatunk a rajzlap adott pontjától (upperLeftDestination) elhelyezkedő téglalapba. A copypixelOperation paraméterben megadhatjuk, hogy mi történjen a cél helyén már ottlévő pontokkal (a CopyPixelOperation felsorolás logikai műveletet definiáló elemeivel: SourceCopy, SourceAnd, SourceInvert, MergeCopy stb.).
void CopyFromScreen(Point upperLeftSource,
Point upperLeftDestination,
Size blockRegionSize, [
CopyPixelOperation copyPixelOperation]);
void CopyFromScreen(int sourceX, int sourceY,
int destinationX, int destinationY,
Size blockRegionSize, [
CopyPixelOperation copyPixelOperation]);
A grafikus beállítások állapotát transzformációk, vágások beállítása stb. elmenthetjük a
GraphicsState^ Save()
metódussal, és később visszaolvashatjuk a Save() függvény visszatérési értékének felhasználásával (gstate)
void Restore(GraphicsState^ gstate);
metódussal.
Hasonlóan a
GraphicsContainer^ BeginContainer();
metódussal menthetjük a Graphics pillanatnyi állapotát a verembe.
Az
void EndContainer(GraphicsContainer^ container);
hívás visszaállítja azt a grafika állapotot, amit a BeginContainer() metódus hívásakor mentettünk, és a konténernyitáskor megkapott GraphicsContainer osztály példányával azonosítunk.
IV.4.14. Nyomtatás
A nyomtatási lehetőségek a System::Drawing::Printing névtéren definiáltak.
A nyomtatást a PrintDocument osztály segítségével végezhetjük. Akár a Toolbox-ról felhelyezhetjük a formra az osztály egy példányát, de létrehozhatjuk azt a
PrintDocument()
konstruktorral.
A PrintDocument osztály példányával dokumentumokat nyomtathatunk. A dokumentum nevét is beállíthatjuk a String típusú
DocumentName
írható és olvasható tulajdonsággal.
A PrinterSettings osztály egy példányára mutat a PrintDocument objektum
PrinterSettings
tulajdonsága. Ennek statikus InstalledPrinters tulajdonsága egy sztring-gyűjtemény, amely a rendszerbe telepített nyomtatók nevét tartalmazza. A PrinterName sztring tulajdonságot használhatjuk arra, hogy beállítsuk hova szeretnénk nyomtatni. Ha nem teszünk semmit, akkor az alapértelmezett nyomtatót használjuk. Az IsValid tulajdonságból megtudhatjuk, hogy jó nyomtatót állítottunk-e be.
A PrinterSettings osztály egy sor tulajdonságot tartalmaz a nyomtató lehetőségeinek és beállításainak lekérdezésére. Például, a CanDuplex logikai tulajdonság a kétoldalas nyomtatási lehetőségről informál, a szintén logikai Duplex ennek használatát szabályozza. A Collate a leválogatási lehetőségről tudósít, a Copies a nyomtatott példányszámot állítja be és mutatja a MaximumCopies tulajdonságig. A logikai IsDefaultPrinter megmutatja, hogy alapértelmezett nyomtatóval van e dolgunk, a szintén logikai IsPlotter a rajzgépet, a SupportColor tulajdonság a színes nyomtatót jelzi. A nyomtató tulajdonságaitól függ a PaperSizes gyűjtemény, amely a használható papírméreteket, PaperSources pedig a használható papír-forrásokat tartalmazza. A PrinterResolution az elérhető felbontásokat tárolja. A LandScapeAngle a portré és a tájkép beállítások közti szöget definiálja.
A DefaultPageSettings tulajdonság a PageSetting osztály egy példánya, mely tartalmazza az összes lapbeállítást (színek, margóméretek, felbontások).
Kiválaszthatjuk a dokumentum egy részét a PrintRange tulajdonsággal (AllPages, SomePages, Selection, CurrentPage stb. értékek). A nyomtatás kezdő oldala (FromPage) és utolsó oldala (ToPage) is beállítható. Gondoskodhatunk fájlba való nyomtatásról a PrintToFile logikai tulajdonság beállításával. Ilyenkor a fájl neve megadható a PrintFileName sztring tulajdonságban.
A nyomtatást kezdeményezhetjük a PrintDocument osztály
void Print()
metódusával. A nyomtatás során az osztály eseményei aktiválódnak: a BeginPrint (nyomtatás kezdete), az EndPrint (nyomtatás vége) és PrintPage (oldalnyomtatás). Mindegyiknek paramétere a PrintEventArgs osztály egy-egy példánya, melynek tulajdonságai a PageSettings osztály (a Bounds - laphatárok, Color – színes nyomtatás, LandsCape - tájkép, Margins - margók, PaperSize- papírméret, PrinterResolution – nyomtató felbontás tulajdonságokkal), a margó és oldalbeállítások mellett a már ismert Graphics típusú nyomtató rajzlap is. A HasMorePages írható, olvasható logikai tulajdonság azt mutatja, hogy van-e további nyomtatandó oldal.
Az alábbi példa a formon való kattintás hatására az alapértelmezett nyomtatón (esetünkben a Microsoft Office OnNote program) vonalat rajzol.
private: System::Void printDocument1_PrintPage(
System::Object^ sender,
System::Drawing::Printing::PrintPageEventArgs^ e) {
e->Graphics->DrawLine(gcnew Pen(Color::Red,2),10,10,100,100);
}
private: System::Void Form1_Click(System::Object^ sender,
System::EventArgs^ e) {
printDocument1->Print();
}
Irodalmak:
[4.1.] MicroSoft Developer Network http://msdn.microsoft.com/. 2012.07.
[4.2.] Könnyű a Windowst programozni!? . ComputerBooks . Budapest . 1998.
[4.3.] Lineáris algebra. Műszaki könyvkiadó . Budapest . 1974.
[4.4.] Háromdimenziós Grafika, animáció és játékfejlesztés. ComputerBooks . Budapest . 2003.
[4.5.] World Wide Web Consortium - www.w3c.org. 2012.
[4.6.] Image Quantization,Halftoning, and Dithering. Előadásanyag Princeton University www.cs.princeton.edu/courses/archive/.../dither.pdf.
V. fejezet - Nyílt forráskódú rendszerek fejlesztése
V.1. A Linux rendszer felépítése
Könyvünk eddigi részében főleg Microsoft Windows alapú programfejlesztéssel foglalkoztunk. Azonban más sikeres szoftverplatformok is léteznek, amelyek manapság elterjedtek. Ezek egyik irányvonala a Unix, amelynek programrészletei, elgondolásai, megoldásai, ötletei be lettek építve a Windows-ba. A további részben a különbségekről és hasonlóságokról lesz szó.
V.1.1. A Unix története
A Unix története 1969-ben kezdődik. Két programozó (Ken Thompson és Dennis Ritchie) a Bell Laboratóriumban nem volt megelégedve a használaton kívüli DEC PDP-7-es operációs rendszerével. Elhatározták, hogy készítenek egy interaktív, többfelhasználós, többfeladatos operációs rendszert a gépre, amelyen a fő alkalmazás a programok fejlesztése. A rendszert el is neveztél UNICS-nak, amiből egyszer csak UNIX lett. Az operációs rendszert BCPL (B) nyelven készítették. 1971-re el is készült, szövegszerkesztőt, assembler fordítót, a dokumentáláshoz szükséges szövegformázó eszközöket is tartalmazott. 1972-ben a B nyelvből Ritchie megalkotta a C nyelvet. A C nyelv megalkotásáról többen azt tartották, hogy lehetetlen olyan magas szintű nyelvet készíteni, amely a különböző bitszélességű processzorokon és memóriaszervezésen is működni képes. A C nyelv használata az operációs rendszert portolhatóvá tette, ugyanis egy új utasításkészletű CPU estén csak az adott CPU assembler-ét kellett megírni, utána az operációs rendszert és a felhasználói programokat le lehetett fordítani az új hardverre. 1975-ben az egyetemeknek, többek közt a Berkeley-nek is odaadták a Unix-ot. Az egyetemen továbbfejlesztették a forrást BSD néven, és a továbbfejlesztések, pl. az Internet kezelését lehetővé tevő Sockets programcsomag, onnan kerültek vissza a Bell Labs utód USG UNIX-ba. A Unix a tudományos társadalom eszközévé vált.
A Unix rendszer fontos eleme a szabványosítás. A kezdetektől fogva többféle rendszer létezett, ahhoz, hogy a programok minden rendszeren futtathatók legyenek, a rendszerhívásokat (pl. fájl megnyitása, karakter kiírása a konzolra) szabványosították. A szabványnak megfelelő rendszerhívásokat tartalmazó programok futtathatók a szabványos Unix operációs rendszeren. A szabványt 1988-ban POSIX-nek nevezték. Többféle szervezet is foglalkozott a szabványosítással, és a UNIX márkanév is gazdáról-gazdára vándorolt. Ilyenek az X/Open, OSF, The Open Group - manapság ezekből a csoportokból megalakult az Austin Common Standards Revision Group, amelynek több, mint 500 tagja van, például az iparból, a kormányzati szférából, a nyílt forráskódú társadalomból. Unix-nak azok a rendszerek tekinthetők, amelyek ennél a szervezetnél található The Open Group-nál szabványosíttatják magukat (ennek természetesen költségei is vannak). Unix-nak tekinthető például a Mac OS X, a HP-UX, a Sun Solaris és az IBM AIX. Nem tekinthető Unix-nak a BSD, annak ellenére, hogy a szabványos rendszerfüggvényeket (Posix - IEEE-1003.1) BSD-n tesztelik.
V.1.2. Az Open Source programkészítési modell
A BSD-nél megjelent egy új elv: a nyílt forráskód elve. A nyílt forráskód annyit jelent, hogy az operációs rendszer (és segédprogramjainak) lefordításához szükséges összes forrás legálisan rendelkezésre áll, módosítható, szabadon tanulmányozható, és másnak átadható. Ugyanezt az elvet vallotta magáénak a GNU projekt, amely jó minőségű, nyílt forráskódú eszközöket készít Unix típusú operációs rendszerekhez. Legismertebb projektjük az 1987-ben indult C fordító, amit GCC-nek hívunk, azóta több nyelvet (C, C++, Fortran) is támogat (Gnu Compiler Collection). A programokat a GPL (General Public License) alatt terjesztik. A GPL és a BSD nyílt forráskódú licenszek közti különbség, hogy a GPL licensszel ellátott termékekből előállított termékhez kötelező forrásprogramot adni, a BSD-nél azonban nem.
V.1.3. A Linux operációs rendszer
A kezdeti Unix-ok (és a BSD-k) csak nagyszámítógépeken működtek. Ugyanis az úgynevezett „személyi számítógép”-ekben az 1980-as években nem volt akkora memória, hogy az operációs rendszer magját (a kernelt) betöltse. Az IBM PC ebben változást hozott: erre a Microsoft is árult Unix-ot Xenix néven, de nem volt sikeres. Jobb próbálkozás volt az Andrew Tanenbaum professzor által készített minix, amely a 80-as évek Pc-in (8086 és 80286-os CPU-val) futó Unix klón, oktatási céllal készült. A Microsoft Windows sem volt túl sikeres (gyors) ezeken a CPU-kon, ekkor az Intel nagy fejlesztésének eredményeként kijött a 80386-os CPU-val, amely 32-bites memóriakezeléssel, valódi védett üzemmóddal támogatta a többfeladatos operációs rendszereket. Ennek a processzornak a memóriakezelésével foglalkozott egy finn egyetemista, Linus Torvalds. Egy internetes levelezőlistán keresztül közzétette a fejlesztéseket, néhányan segítettek neki, és egyszer csak elkészült egy Unix szerű operációs rendszer kernelje, amit valaki – hasonlóan az UNICS-UNIX módosításhoz - Linux-nak nevezett el. GNU GPL licensszel készült, és az akkoriban (a 90-es évek közepén-végén) a nagyközönség számára elérhető Interneten keresztül terjesztették, de sok internetes kiszolgáló operációs rendszerének is a Linux-ot választották, mert egy relatíve olcsó PC-n néha jobb teljesítményt nyújtott, mint az 1-2 nagyságrenddel drágább úgynevezett nagyszámítógépeken a szabványosított Unix-ok. Meg kell jegyeznünk, hogy a Linux nem nevezhető UNIX-nak. A Linux bár megfelel a Posix szabványoknak, nem fizetett a licenszért, így (akárcsak a BSD) nem tekintendő Unix-nak, csak „Unix-like”-nak. A Linux szorosabb értelemben csak a rendszermagot (kernel) jelenti, de önmagában a kernel nem üzemképes. C fordító a Linux-ban a már említett GCC, a legtöbb segédprogram (utility) a Gnu projektből származik, így a GNU projekt kérésére a Linuxot GNU/Linux-nak nevezik. A Linux kernel definíció szerint „úgy van megírva, hogy GCC-vel lefordítható legyen”.
V.1.4. Linux disztribúciók
Disztribúción egy összerakott, üres háttértárral ellátott számítógépre feltelepíthető rendszert értünk. Ennek többféle segédprogramot kell tartalmaznia: lemezpartícionáló, betöltő (boot) készítő, csomagválasztó (más segédprogramok és beállítások kellenek egy internetes kiszolgálóhoz, mint egy szövegszerkesztésre használt munkaállomáshoz), konfiguráció beállító. Több ilyen disztribúció is létezik, és bármelyik disztribúció felhasználói szerint az általuk használt a legjobb, a többi rossz, és annak a felhasználói „hozzá nem értő kezdők”. Az összes disztribúcióban ugyanaz a Linus nevével fémjelzett kernel található, és természetesen a GCC fordító valamelyik verziója. A rendszerindító szkriptek és a telepíthető programcsomagokat kezelő „package manager” minden disztribúcióban más és más. Néhány szoftverekkel foglalkozó cég is felkarolt egy-egy disztribúciót, ezzel megoldva a terméktámogatási kérdést. Ugyanis az ingyenes disztribúciókhoz nem jár terméktámogatás, a bankok, internetszolgáltatók nem használhatnak támogatás nélküli termékeket. A támogatással vásárolható disztribúció legtöbb esetben ugyanaz, amit le is lehet tölteni a disztribúció honlapjáról. Létezik adatbáziskezelővel ellátott nagyvállalati disztribúció is, természetesen megfelelő áron.
V.1.5. X Window System
Amikor a Unix készült, a grafikus megjelenítők még nem voltak elterjedtek. Még a soros kábellel a számítógéphez kapcsolt alfanumerikus display is (terminál) újdonságnak számított. Emiatt a Unix (és a Linux is) a felhasználóval a terminálon tartja a kapcsolatot, alapvetően egy parancsértelmező (shell) programon keresztül. Ha úgy gondoljuk, hogy ez az architektúra – egy központi gép sok rákapcsolt terminállal – elavult, nézzünk meg egy felhő alapú alkalmazást: soros kábel helyett internet, egy számítógép helyett sok számítógép, logikailag egy számítógépként látszik. A Unix-os világban is megjelent azonban a grafikus felhasználói felület (GUI), mint a számítógép kezelésének könnyen elsajátítható eszköze. Nem a kétbetűs parancsot kell megjegyezni, amely nem változott az utóbbi 43 évben, hanem azt, hogy hova kell kattintani az egérrel az adott művelethez, és ezt a gyártók (pl. Microsoft Office) előszeretettel szervezik át minden új verzióban. A Unix-os GUI elnevezése X Window System, amely alatt a jól ismert alapfogalmak jelennek meg: egér, kurzor, ikon, kattintás. Az X Window System tulajdonságai:
nem része az operációs rendszernek, csak egy alkalmazás. A Unix nélküle is üzemképes
network-transparent: a futó alkalmazás és a megjelenítés közt elég, ha internetes (TCP/IP) kapcsolat van.
önmagában nincs felülete, egy grafikus asztalból és egy egérmutatóból áll. Szükséges a használathoz egy Window Manager (WM) program is, amely az ablakokat és az ikonokat kezeli, az ikonok mögött található alkalmazásokat elindítja.
létezik nyílt forráskódú változat is, a GPL operációs rendszereken való használatra. Ezt az X.org internetes oldalon találjuk, ha esetleg le akarnánk fordítani. Grafikus kártya meghajtóprogramokat nem tartalmaz, ezeket az xfree86.org oldalon találjuk. Az xfree86-ot a Linux disztribúciók tartalmazzák, némelyik már az telepítést is grafikusan végzi el.
V.1.6. A beágyazott Linux
A Linux, miután C nyelven íródott, más CPU-ra is lefordítható. A TCP/IP támogatás, a grafika (X Window System), a széles kiszolgáló választék (web, fájl, nyomtatás, adatbázis) ideálissá teszi az internetre kapcsolt termékek (ADSL router, network hard drive, DVD és szórakoztató eszközök: médialejátszó, mobiltelefon, tablet, ipari automatizálás) kis költséggel testreszabható operációs rendszerévé. Egyetlen hátránya: az eszközök méretéhez és energiaellátásához (hordozható eszközök esetén akkumulátor) képest viszonylag nagy memóriaigény. Legismertebb formája a Google mobiltelefonos operációs rendszere, az Android, amely egy módosított Linux kernelen futó módosított GNU felhasználói programok segítségével készült.
V.2. A GCC fordító
A GCC fordító a GNU projekten belül, a GNU operációs rendszerhez készült. Tartalmaz Fortran, Java, C, C++, Ada felületeket, valamint szabványos fejállomány gyűjteményt a programok fordításához, és könyvtárakat a szerkesztéshez/futtatáshoz/hibakereséshez. A GNU rendszerből szinte minden el is készült, hogy egy Unix-like operációs rendszerré váljon – a kernelt kivéve. Az alkalmazások: a fordító, a shell, a segédprogramok viszont jól jöttek a Linux-nak, mert ott csak a kernel készült el.
V.2.1. A GCC keletkezése
A GCC fordító tervezésénél és a kódolásánál a fő szempont egy jó minőségű, ingyenes eszköz készítése volt. Hasonló cél a különféle számítógép architektúrák támogatása. A GNU rendszer is az interneten közreműködő fejlesztők munkájaként alakult ki: a fordító forrásprogramja mindenki számára elérhető, ha valaki javítást vagy bővítést készít hozzá, és elküldi a fejlesztést koordináló szervezetnek, az általa fejlesztett kód is belekerül a rendszerbe.
V.2.2. A forditás lépései GCC-vel
A GCC fordítóprogram a IV.1.1. szakasz - A nativ kód fordítási és futtatási folyamata Windows alatt fejezetben ismertetett módon .C forrásprogramból készít futtatható állományokat, a Windows-os Microsoft fordítóval szemben úgy, hogy a .C fájlok gépi kódú utasításokat tartalmazó assembly nyelvű szövegfájlokra fordulnak le, amit aztán egy assembler fordít le .obj fájlokra. Nézzük az alábbi, lehető legegyszerűbb mintaprogramot, ezt egy szövegszerkesztővel írtuk az x.c nevű fájlba:
#include <stdio.h>
int main(void) {
int i;
i=0;
i++;
printf("%i\n",i);
return 0;
}
Erre a programra először az előfeldolgozót (preprocesszor) engedjük rá, az #include-okat és a #define-okat oldja fel: a #define-t behelyettesíti (ebben a programban nem kell) és az #include-nál bemásolja az ott található header-t. A legegyszerűbb header-t választottuk, amely a kiíratáshoz kell. A preprocesszált c forrás az x.i állományba kerül:
# 1 "x.c"
# 1 "<built-in>"
# 1 "<command line>"
# 1 "x.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 40 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/sys/cdefs.h" 1 3 4
# 59 "/usr/include/sys/cdefs.h" 3 4
# 1 "/usr/include/machine/cdefs.h" 1 3 4
# 60 "/usr/include/sys/cdefs.h" 2 3 4
# 1 "/usr/include/sys/cdefs_elf.h" 1 3 4
# 62 "/usr/include/sys/cdefs.h" 2 3 4
# 41 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/featuretest.h" 1 3 4
# 42 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/ansi.h" 1 3 4
# 35 "/usr/include/sys/ansi.h" 3 4
# 1 "/usr/include/machine/int_types.h" 1 3 4
# 47 "/usr/include/machine/int_types.h" 3 4
typedef signed char __int8_t;
typedef unsigned char __uint8_t;
typedef short int __int16_t;
typedef unsigned short int __uint16_t;
typedef int __int32_t;
typedef unsigned int __uint32_t;
typedef long int __int64_t;
typedef unsigned long int __uint64_t;
typedef long __intptr_t;
typedef unsigned long __uintptr_t;
# 36 "/usr/include/sys/ansi.h" 2 3 4
typedef char * __caddr_t;
typedef __uint32_t __gid_t;
typedef __uint32_t __in_addr_t;
typedef __uint16_t __in_port_t;
typedef __uint32_t __mode_t;
typedef __int64_t __off_t;
typedef __int32_t __pid_t;
typedef __uint8_t __sa_family_t;
typedef unsigned int __socklen_t;
typedef __uint32_t __uid_t;
typedef __uint64_t __fsblkcnt_t;
typedef __uint64_t __fsfilcnt_t;
# 43 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/machine/ansi.h" 1 3 4
# 75 "/usr/include/machine/ansi.h" 3 4
typedef union {
__int64_t __mbstateL;
char __mbstate8[128];
} __mbstate_t;
# 45 "/usr/include/stdio.h" 2 3 4
typedef unsigned long size_t;
# 1 "/usr/include/sys/null.h" 1 3 4
# 51 "/usr/include/stdio.h" 2 3 4
typedef __off_t fpos_t;
# 74 "/usr/include/stdio.h" 3 4
struct __sbuf {
unsigned char *_base;
int _size;
};
# 105 "/usr/include/stdio.h" 3 4
typedef struct __sFILE {
unsigned char *_p;
int _r;
int _w;
unsigned short _flags;
short _file;
struct __sbuf _bf;
int _lbfsize;
void *_cookie;
int (*_close)(void *);
int (*_read) (void *, char *, int);
fpos_t (*_seek) (void *, fpos_t, int);
int (*_write)(void *, const char *, int);
struct __sbuf _ext;
unsigned char *_up;
int _ur;
unsigned char _ubuf[3];
unsigned char _nbuf[1];
struct __sbuf _lb;
int _blksize;
fpos_t _offset;
} FILE;
extern FILE __sF[];
# 214 "/usr/include/stdio.h" 3 4
void clearerr(FILE *);
int fclose(FILE *);
int feof(FILE *);
int ferror(FILE *);
int fflush(FILE *);
int fgetc(FILE *);
int fgetpos(FILE * __restrict, fpos_t * __restrict);
char *fgets(char * __restrict, int, FILE * __restrict);
FILE *fopen(const char * __restrict , const char * __restrict);
int fprintf(FILE * __restrict , const char * __restrict, ...)
__attribute__((__format__(__printf__, 2, 3)));
int fputc(int, FILE *);
int fputs(const char * __restrict, FILE * __restrict);
size_t fread(void * __restrict, size_t, size_t, FILE * __restrict);
FILE *freopen(const char * __restrict, const char * __restrict,
FILE * __restrict);
int fscanf(FILE * __restrict, const char * __restrict, ...)
__attribute__((__format__(__scanf__, 2, 3)));
int fseek(FILE *, long, int);
int fsetpos(FILE *, const fpos_t *);
long ftell(FILE *);
size_t fwrite(const void * __restrict, size_t, size_t, FILE * __restrict);
int getc(FILE *);
int getchar(void);
void perror(const char *);
int printf(const char * __restrict, ...)
__attribute__((__format__(__printf__, 1, 2)));
int putc(int, FILE *);
int putchar(int);
int puts(const char *);
int remove(const char *);
void rewind(FILE *);
int scanf(const char * __restrict, ...)
__attribute__((__format__(__scanf__, 1, 2)));
void setbuf(FILE * __restrict, char * __restrict);
int setvbuf(FILE * __restrict, char * __restrict, int, size_t);
int sscanf(const char * __restrict, const char * __restrict, ...)
__attribute__((__format__(__scanf__, 2, 3)));
FILE *tmpfile(void);
int ungetc(int, FILE *);
int vfprintf(FILE * __restrict, const char * __restrict, __builtin_va_list)
__attribute__((__format__(__printf__, 2, 0)));
int vprintf(const char * __restrict, __builtin_va_list)
__attribute__((__format__(__printf__, 1, 0)));
char *gets(char *);
int sprintf(char * __restrict, const char * __restrict, ...)
__attribute__((__format__(__printf__, 2, 3)));
char *tmpnam(char *);
int vsprintf(char * __restrict, const char * __restrict,
__builtin_va_list)
__attribute__((__format__(__printf__, 2, 0)));
int rename (const char *, const char *);
# 285 "/usr/include/stdio.h" 3 4
char *ctermid(char *);
char *cuserid(char *);
FILE *fdopen(int, const char *);
int fileno(FILE *);
void flockfile(FILE *);
int ftrylockfile(FILE *);
void funlockfile(FILE *);
int getc_unlocked(FILE *);
int getchar_unlocked(void);
int putc_unlocked(int, FILE *);
int putchar_unlocked(int);
int pclose(FILE *);
FILE *popen(const char *, const char *);
# 332 "/usr/include/stdio.h" 3 4
int snprintf(char * __restrict, size_t, const char * __restrict, ...)
__attribute__((__format__(__printf__, 3, 4)));
int vsnprintf(char * __restrict, size_t, const char * __restrict,
__builtin_va_list)
__attribute__((__format__(__printf__, 3, 0)));
int getw(FILE *);
int putw(int, FILE *);
char *tempnam(const char *, const char *);
# 361 "/usr/include/stdio.h" 3 4
typedef __off_t off_t;
int fseeko(FILE *, __off_t, int);
__off_t ftello(FILE *);
int vscanf(const char * __restrict, __builtin_va_list)
__attribute__((__format__(__scanf__, 1, 0)));
int vfscanf(FILE * __restrict, const char * __restrict, __builtin_va_list)
__attribute__((__format__(__scanf__, 2, 0)));
int vsscanf(const char * __restrict, const char * __restrict,
__builtin_va_list)
__attribute__((__format__(__scanf__, 2, 0)));
# 398 "/usr/include/stdio.h" 3 4
int asprintf(char ** __restrict, const char * __restrict, ...)
__attribute__((__format__(__printf__, 2, 3)));
char *fgetln(FILE * __restrict, size_t * __restrict);
char *fparseln(FILE *, size_t *, size_t *, const char[3], int);
int fpurge(FILE *);
void setbuffer(FILE *, char *, int);
int setlinebuf(FILE *);
int vasprintf(char ** __restrict, const char * __restrict,
__builtin_va_list)
__attribute__((__format__(__printf__, 2, 0)));
const char *fmtcheck(const char *, const char *)
__attribute__((__format_arg__(2)));
FILE *funopen(const void *,
int (*)(void *, char *, int),
int (*)(void *, const char *, int),
fpos_t (*)(void *, fpos_t, int),
int (*)(void *));
int __srget(FILE *);
int __swbuf(int, FILE *);
static __inline int __sputc(int _c, FILE *_p) {
if (--_p->_w >= 0 || (_p->_w >= _p->_lbfsize && (char)_c != '\n'))
return (*_p->_p++ = _c);
else
return (__swbuf(_c, _p));
}
# 2 "x.c" 2
int main(void) {
int i;
i=0;
i++;
printf("%i\n",i);
return 0;
}
A példa méretéből látható, hogy egy include több másik include-t is behívhat. A preprocesszált forrás assembly-re lefordítva, az x.s fájlban:
.file "x.c"
.section .rodata
.LC0:
.string "%i\n"
.text
.globl main
.type main, @function
main:
.LFB3:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
subq $16, %rsp
.LCFI2:
movl $0, -4(%rbp)
incl -4(%rbp)
movl -4(%rbp), %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
ret
.LFE3:
.size main, .-main
.section .eh_frame,"a",@progbits
.Lframe1:
.long .LECIE1-.LSCIE1
.LSCIE1:
.long 0x0
.byte 0x1
.string "zR"
.uleb128 0x1
.sleb128 -8
.byte 0x10
.uleb128 0x1
.byte 0x3
.byte 0xc
.uleb128 0x7
.uleb128 0x8
.byte 0x90
.uleb128 0x1
.align 8
.LECIE1:
.LSFDE1:
.long .LEFDE1-.LASFDE1
.LASFDE1:
.long .LASFDE1-.Lframe1
.long .LFB3
.long .LFE3-.LFB3
.uleb128 0x0
.byte 0x4
.long .LCFI0-.LFB3
.byte 0xe
.uleb128 0x10
.byte 0x86
.uleb128 0x2
.byte 0x4
.long .LCFI1-.LCFI0
.byte 0xd
.uleb128 0x6
.align 8
.LEFDE1:
.ident "GCC: (GNU) 4.1.3 20080704"
Ebben is felismerhető a programrészletünk: pl. az i++-ból incl -4(%rbp) lett. A fordító a verziószámát is beletette, de csak szövegként. Ez a szövegrészlet szerkesztés után is benne marad a futtatható állományban.
Alaphelyzetben, külön opció használata nélkül ezek a fájlok törlődnek, és a C állomány mellett csak egy futtatható fájl marad. Ha nem adjuk meg a nevét, a.out lesz. Ha meg szeretnénk adni a futtatható fájl nevét, az –o fájlnév opcióval kell indítani a fordítást:
|
Parancs |
eredmény |
futtatás |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
V.2.3. Host és Target
A fordítóprogram (esetünkben szorítkozzunk a C(++) fordítóra) forrásokban adott. Egyik szövegfájlból (a .c forrásból) egy másik szöveges állományt, az assembler forrásfájlt készíti el. Tehát elvileg a fordító forrása bármelyik számítógépen lefordítható úgy, hogy azon a gépen fusson. A fordítóprogramból készül egy futtatható állomány, amely elindítható (Unix-on gcc, windows-on gcc.exe). Azt a rendszert, ahol a fordítóprogram elindul, Compiler Host-nak nevezzük (fordítási gazda), ugyanis ezen fog történni a fordítás. A compiler lefordításakor meg kell adni, hogy milyen CPU utasításkészletet alkalmazzon. Ezt nevezzük Compiler Target-nek (fordítási cél). A fordítóprogramot általában asztali számítógépen vagy laptopon használjuk, itt történik a programfejlesztés, így a host rendszer általában intel-linux vagy intel-windows. A 64-bites változatot történeti okokból amd64-nek, vagy x86_64-nek hívják. Ha a gép operációs rendszerében fogjuk futtatni a lefordított programunkat (target==host) “natív” fordítóról beszélünk. A Microsoft Visual Studio C++ - a natív fordító: Windows alatt fut, a kimenete is Windows alkalmazás. Az embedded Linux-ok általában terjedelmi okok miatt nem tartalmaznak GCC fordítót, az őket futtató gépek nem alkalmasak programfejlesztésre. Ekkor egy PC-n készítjük el a programot, ott is fordítjuk le, csak a célt állítjuk az embedded rendszerre. A folyamat neve keresztfordítás (cross-compiling). Gyakran a SOC-ok (lásd a VI. fejezet - Célspecifikus alkalmazások fejezetben) teljes programrendszere így készül, a keresztfordító bemenete egy teljes könyvtárstruktúra forrásprogramokkal, kimenete pedig a SOC Rom-jának tartalma.
V.2.4. A GCC gyakran használt opciói
A gcc fordítónak, miután parancssoros üzemeltetésre tervezték, a parancssorba írt kapcsolókkal lehet módosítani a működésén. Alapvető parancs a gcc forrásfájl, amely lefordítja a forrásfájlt egy a.out elnevezésű futtatható fájlba. Vigyázat: Unix alatt nem csak a C nyelvű programok, de az opciók is kis/nagybetű megkülönböztetéssel értelmeződnek.
|
Opció |
Példa |
Hatása |
|---|---|---|
|
|
|
x nevű futtatható fájl készül, nem a.out |
|
|
|
az összes figyelmeztetést megjeleníti, pl. konverziókor pontosságcsökkenést, vagy pointer által mutatott adat máshogy értelmezését |
|
|
|
a futtatható fájl szimbólumtáblát is tartalmaz, így a gdb debuggerrel hiba kereshető |
|
|
|
nem törli le a fordítási folyamat közben keletkező átmeneti fájlokat |
|
|
|
ne készítsen futtatható fájlt, csak az obj fájl készüljön el, mert több lefordítandó fájlból áll a program |
|
|
|
programozási nyelv megadása. Ha nem adjuk meg, a kiterjesztésből állapítja meg: a |
|
|
|
csak a preprocesszort futtassa le, assembly file ne készüljön |
|
|
|
csak az assembly fájlig fordítson, obj file ne készüljön |
|
|
|
verbose: mutassa a fordítás közben végrehajtott parancsokat a preprocesszálástól a szerkesztésig |
|
|
|
optimalizálás: O0-nál nincs, O3-nál teljes optimalizálás, a fordítás lassabb lesz, és több memóriát használ, de a kész program gyorsabban fut |
|
|
|
makró definiálása. Ugyanaz, mint a #define a programszövegben |
|
|
|
a könyvtárnevet hozzáadja az include fájlok keresési útvonalához. Vagyis itt is lehetnek a programunk include-jai. Az opció a nagy “I” betű, mint „Include” |
|
|
|
Ne keresse a szabványos include-okat. SOC-nál az adott rendszer include-jait kell használni, a példa sem fog működni –I opció nélkül |
|
|
|
a szerkesztéshez használt elérési út: itt is lehetnek |
|
|
|
nem futtatható programot fordítunk, csak egy részletet egy könyvtárba, amit majd később használunk fel |
|
|
|
kiírja az egyes fordítási lépések idejét, Unix felfogásban: felhasználói és operációs rendszeridő fogyasztás. |
|
|
|
az assembly fájlba helyezzen megjegyzéseket, pl. a C forrás aktuális sorát, hogy könnyebben olvasható legyen. |
V.2.5. A make segédprogram
A gcc fordító az előzőekben látott módon képes lefordítani egy C nyelven írt programot. Azonban a program lehet nagyobb is: több fájlból is állhat. Ha több C forrásfájl van, akkor először lefordítjuk őket a –c opcióval, a fordítás végén szerkesztünk az erre a célra készített ld (linker) programmal. Erre a folyamatra akár egy shell scriptet (parancsokat tartalmazó text fájl – hasonló, mint a windows .bat vagy .cmd állománya) is írhatunk, hogy az egyes fájlokat milyen sorrendben fordítsuk le, és a végén hogy szerkesszük össze. Ha tényleg nagy a program, a fordítás eltarthat napokig is. Egy ekkora programnál a fejlesztés sem egyszerű: a forrás módosítása után újra lefordítani az összes C fájlt a legelsőtől az utolsóig felesleges lenne, már csak azért is, mert csak néhány fájl változott meg, a többiekből készített tárgy fájlokat szükségtelen lenne újra generálni. A fájlok megváltozása egyszerű módszerrel figyelhető: amelyik .c fájl újabb (az utolsó módosítás dátuma alapján), mint a belőle készült .o fájl, az a fájl megváltozott, az .o fájlt le kell törölni, és a .c fájl újra kell fordítani. Ezt a fájlok közötti kapcsolatot függőségnek (depedency) nevezzük. A futtatható programhoz is készíthető ilyen feltétel, az .o fájlok megváltozásához. A program, amely ezt a feltételrendszert kezelni tudja, a make. Készítünk a programunkhoz egy Makefile nevű fájlt, amelyben megadjuk, hogy melyik fájl melyikből származik, és ha újra szükséges készíteni, milyen paranccsal tegyük ezt meg. Ezen túl még a make-nek további lehetőségei is vannak: a fájlban megadhatók egyéb, parancssori opciók, mit kell tennie például a make clean, makeinstall parancsok kiadásakor. Egy több forrásfájlból álló kis program Makefile-ja a következő lehet:
tr1660: main.o libtr1660.a screen.o
gcc -o tr1660 -lcurses main.o libtr1660.a screen.o
size tr1660
kondi: kondi.o libtr1660.a screen.o
gcc -o kondi -lm -lcurses kondi.o libtr1660.a screen.o
rm kondi.o libtr1660.a screen.o
size kondi
libtr1660.a: tr1660.h tr1660.c
gcc -Wall -c -o tr1660.o tr1660.c
ar rcs libtr1660.a tr1660.o
rm tr1660.o
main.o: main.c
gcc -c -Wall -o main.o main.c
kondi.o: kondi.c
gcc -c -Wall -o kondi.o kondi.c
screen.o: screen.c screen.h
gcc -c -Wall -o screen.o screen.c
clean:
rm -f *.o *.a *.so tr1660 kondi *~ a.out
A főprogram neve a tr1660, és 3 külön forrásból áll: a main.c-ből, a libtr1660-ból (fejből és forrásból egy könyvtár lesz), és a screen.c-ből. Lefordítható még a kondi.c-ből a kondi program, a fenti könyvtárat használva, és a teljes projekt kitakarítható a clean esetén.
V.2.6. A gdb debugger (hibakereső/nyomkövető)
Előfordulhat, hogy a programunk nem úgy működik, ahogy szeretnénk. Lefordítható, de hibaüzenettel kidobja az operációs rendszer, vagy hibás eredmény jön ki. Ekkor használható a debugger: képes töréspontot elhelyezni a programban, addig teljes sebességgel futni, majd ott megállni, és a változók értékét megtekinthetjük, lépésenként mehetünk tovább. A GNU projektnél ezt a programot gdb-nek nevezték el. Fontos megjegyezni, hogy a debuggerben mi a C nyelvű programsorokat és változókat látjuk, miközben a program gépi kódja fut. Ezt csak úgy tudja megtenni, ha a programot a gcc-vel, a –g opcióval fordítottuk le. Ekkor a futtatható fájlba szimbólumok is kerülnek: melyik gépi kódú utasítás melyik forrásfájlból keletkezett.
A következő példában kövessük nyomon az V.2.2. szakasz - A forditás lépései GCC-vel fejezet programját: helyezzünk el töréspontot a programban, hajtsuk végre lépésenként és nézzük meg a változó értékét!
Először fordítsuk le nyomkövetésre alkalmas módon a programunkat!
bash-4.2# gcc -Wall -g x.c -o x
Majd indítsuk el a debuggert, a programunkkal!
bash-4.2# gdb x GNU gdb 6.5 Copyright (C) 2006 Free Software Foundation, Inc.
Kérjünk forráslistát, ha már nem emlékszünk, mit is irtunk!
(gdb) l
1 #include <stdio.h>
2
3 int main(void) {
4 int i;
5 i=0;
6 i++;
7 printf("%i\n",i);
8 return 0;
9 }
Tegyünk töréspontot az 5. sorra!
(gdb) b 5 Breakpoint 1 at 0x400918: file x.c, line 5.
Indulhat a program !
(gdb) r Starting program: /root/prg.c/x Breakpoint 1, main () at x.c:5 5 i=0;
Megállt a program, az 5. sorban. Lépjünk egyet és hajtsuk végre az i=0-t!
(gdb) n 6 i++;
Hajtsuk végre az i++-t is!
(gdb) n
7 printf("%i\n",i);
Írassuk ki i értékét !
(gdb) p i $1 = 1
Menjünk tovább teljes sebességgel!
(gdb) c Program exited normally.
A nyomkövetés kész, kiléphetünk a debuggerből.
(gdb) q
V.3. Posix C, C++ rendszerkönyvtárak
Az V.1.1. szakasz - A Unix története szakaszban láttuk, hogy a C(++) nyelvű programjaink akkor lesznek hordozhatók, ha több rendszeren is le lehet őket fordítani. Ehhez a szabványosítási szervezetek definiáltak egy közösen használható függvénykönyvtárat, amelynek elemei minden posix szabvány szerinti rendszerben megtalálhatók. Ezekben a függvényekben gyakran használt programrészleteket találunk, amelyekre a programozó számíthat. Például nem kell megírnia a lebegőpontos számok kiíratását, mert a printf(”%f”) függvény rendelkezésre áll, az #include <stdio.h> után. A Posix ugyan a Unix-okról szólt, de ezek a könyvtárak elérhetők akár a Visual Studióban is. A könyvtár nagyszámú fejállományt és nagyszámú include-ot tartalmaz, terjedelmi okok miatt a további részben csak az oktatásban előforduló függvényeket ismertetjük röviden. A teljes rendszer megtalálható a Wikipedián, „C POSIX library” címszó alatt. A következőkben az egyes fejállományokban található függvényeket ismertetjük röviden.
V.3.1. stdio.h
Az stdio.h-ban (c++: cstdio) alapvető i/o műveletek találhatók.
fopen: fájl megnyitása,freopen: fájl újranyitása,fflush: kimenet szinkronizálása az aktuális állapotra,fclose: fájl bezárása,fread: fájlból adat olvasása,fwrite: fájlba adat írása,getc/fgetc: karakter beolvasás szabványos inputról/fájlból,gets/fgets: string olvasása szabványos inputról/fájlból,putc/fputc: karakter kiírása standard outputra/fájlba,puts/fputs: string írása standard outputra/fájlba,ungetc: már kiolvasott karakter visszatétele az adatfolyamba,scanf/fscanf/sscanf: adat formázott olvasása a szabványos inputról/fájlból/sztringből. A formátumbeállításokat lásd az I.2. szakasz - Alaptípusok, változók és konstansok fejezetben,printf/fprintf/sprintf/snprintf: adat formázott kiírása a szabványos outputra/fájlba/sztringbe/ adott hosszúságú sztringbe. Azsnprintf()-nél nem léphet fel buffer túlcsordulási hiba,ftell: az aktuális fájlpozíció lekérdezése,fseek: a fájlpozíció beállítása, fájlmutató mozgatásával,rewind: fájlmutató mozgatása a fájl elejére,feof: a fájl végének ellenőrzése,perror: szöveg kiírása standard error fájlra,remove: fájl törlése,rename: fájl átnevezése,tmpfile: átmeneti, egyedi nevű fájl létrehozása, és pointerének visszaadása,tmpnam: átmeneti, egyedi fájlnév visszaadása,EOF: a fájlvége konstans,NULL: garantáltan sehova sem mutató pointer konstans,SEEK_CUR: az aktuális pozícióhoz képest mozgatjuk a fájlmutatót,SEEK_END: a fájl végéhez képest mozgatjuk a fájlmutatót,SEEK_SET: a fájl elejéhez képest mozgatjuk a fájlmutatót,stdin, stdout,stderr: a szabványos adatfolyamok definíciói,FILE: a fájlváltozók struktúrája,size_t: a sizeof operátor visszatérési típusa.
V.3.2. math.h
A math.h fájlban (c++: cmath) matematikai függvényeket és konstansokat találunk.
abs/fabs: abszolút érték egész/valós számokra,div/ldiv: egész osztás eredménye és maradéka egy div_t típusú struktúrába,exp: az exponenciális függvény,log: a logaritmus függvény (e alapú),log10: 10-es alapú logaritmus függvény,sqrt: a négyzetgyök függvény,pow: a hatványozó függvény (hatványozás művelet nincs a C++-ban, de függvény igen),sin/cos/tan/atan: a trigonometrikus függvények: szinusz/koszinusz/tangens/inverz tangens,sinh/cosh/tanh/atanh: a hiperbolikus trigonometrikus függvények,ceil: visszaadja az argumentumánál nem nagyobb egészet (lefele kerekít),floor: visszaadja az argumentumánál nem kisebb egészet (felfele kerekít),round: egészre kerekít.
V.3.3. stdlib.h
Az stdlib.h-ban (c++: cstdlib) a Unix-ban szükséges egyéb, szokásosnak tekinthető függvényeket találunk: szöveg-szám konverzióra, véletlen szám generálásra, memóriafoglalásra, folyamatvezérlésre.
atof: sztringet konvertál lebegőpontosra (gyakorlatilag double),atoi: sztringet konvertál egészre,atol: sztringet konvertál hosszú egészre,rand: egy egész véletlen számot ad vissza,srand: beállítja a véletlen szám generátor kezdőértékét. A gépi idővel szokásos inicializálni,malloc: helyfoglalás a memóriában,realloc: lefoglalt memória átméretezése,calloc: memória foglalás, és a kapott memóriablokk feltöltése 0-val,free: a lefoglalt memória felszabadítása,abort: a programunk azonnal leáll, takarítás nélkül,exit: a programunk leáll, normál leállítással, takarítással,atexit: megadhatjuk, hogy kilépéskor melyik függvényünk hívódjon meg,getenv: a program a környezeti változóihoz fér hozzá, amelyek név=érték formátumúak,system: az operációs rendszer parancsértelmezőjének hívása, az argumentumában megadott parancssorral. Külső programok futtatására szolgál.
V.3.4. time.h
A time.h (c++: ctime) fejállományban az idő kezeléséhez szükséges adatstruktúrák és függvények találhatók. A Unix típusú idő egy egész szám, az 1970 január 1. éjfél óta eltelt másodpercek száma, UTC-ben (régi nevén GMT), hogy a különböző időzónákban lévő gépek is jól kommunikáljanak. A gépnek a helyi időt az aktuális időzóna segítségével kell kiszámolnia. A 32-bites érték használata időként a Unix rendszer tervezésekor jó ötletnek tűnt, de manapság már – főleg az y2k-s pánikkeltés hatására – figyelembe vesszük, hogy a 32-bites idő 2038 január 18-án túlcsordul. A mai rendszereken a time_t már 64-bites, amely 293 billió évig lesz használható.
time: az aktuális idővel tér vissza, time_t formátumban (Unix time),difftime: két időpont különbségét számítja ki,clock: megadja az aktuális programunk (mint folyamat) indítása óta lefutott CPU órajelek számát,asctime: a tm struktúrát konvertálja szöveggé,ctime: a tm struktúrában található időt, a helyi idő szerint, konvertálja sztringgé,strftime: mint az asctime, csak mi adhatjuk meg a formátumot (például: éééé-hh-nn óó:pp:mm),gmtime: a time_t típusból (egész) tm struktúrába konvertál UTC időt,localtime: a time_t típusból (egész) tm struktúrába konvertál helyi időt,mktime: a tm struktúrából konvertál time_t típusú időt,tm: az idő adattípus. Tagjai: tm_sec másodperc, tm_min perc, tm_hour óra , tm_mday hónap napja, tm_mon hónap (0:január.. 11:december), tm_year: év 1900 óta, tm_wday: a hét napja (0:vasárnap), tm_yday: napok január 1 óta, tm_isdst: nyári időszámítás aktív jelző,time_t: egész típusú idő, a másodpercek száma 1970 január 1 óta,clock_t: egész típus, cpu órajelek számlálására.
V.3.5. stdarg.h
Az stdarg.h (c++: cstdarg) fejlécek közt a II.2. szakasz - A függvényekről magasabb szinten fejezetben ismertetett változó paraméterszámú függvények (mint pl. a printf) írásához szükséges típusokat és makrókat találjuk:
va_list: a változó számú lista típusa,va_start: a lista kezdetére állás makrója,va_arg: a következő elem lekérése a listából,va_end: a lista felszabadítása,va_copy: a lista másolása egy másik listába.
V.3.6. string.h
A string.h (c++: cstring) fejállományok a "C típusú", 0-val végződő, egybájtos karakterekből álló sztringeket kezelő függvényeket és konstansokat tartalmazza. A sztring/folytonos memóriablokk kezelés minden programozási nyelvben fontos feladat. Léteznek függvények, amelyek a 0 végjelig dolgoznak az adattömbön, és léteznek, amelyek nem veszik figyelembe a végjelet: ezekben mindig van legalább egy paraméter, amely a kezelendő adat hosszára utal.
strcpy: sztring másolása 0 végjelig,strncpy: sztring másolása megadott darabszámú karakter hosszan,strcat: egyik sztring végéhez a másik másolása, konkatenáció, 0 végjelig,strncat: egyik sztring végéhez a másik másolása, konkatenáció, megadott darabszámú karakter hosszan,strlen: a sztring aktuális hosszának (0 végjelig) kiszámítása,strcmp: két sztring összehasonlítása, 0 végjelig. Kimenet: 0, ha a két sztring azonos karaktereket tartalmaz, negatív, ha az első kisebb (ASCII-ban), mint a második, pozitív, ha a második argumentum kisebb,strncmp: két sztring összehasonlítása, megadott hosszan. Kimenet az strcmp()-nél definiált,strchr: a sztringben egy karakter (char) keresése. Ha megtalálta, visszaadja a karakterre mutató pointert, ha nem találta, NULL értékkel tér vissza,strstr: a sztringben egy másik sztringet keres. Visszatérő értéke az strchr()-nél leírttal azonos,strtok: a sztringet tokenek mentén szétdarabolja. Vigyázat, a sztring eredeti tartalmát elrontja!strerror: az operációs rendszer által visszaadott numerikus hibakódot angol nyelvű hibaüzetenet tartalmazó sztringgé alakítja,memset: a pointer által mutatott memóriaterületet ugyanazzal a karakterrel tölti fel, az argumentumként megadott mennyiségben,memcpy: az egyik pointer által mutatott memóriaterületet átmásolja a másik pointer által mutatott területre, az argumentumként megadott számú bájtot másol,memmove: mint a memcpy(), csak a memóriaterületek átlapoltak is lehetnek (vagyis az egyik mutató+hossz<=másik muató). Ekkor először átmeneti memóriába másol, majd onnan a célmemóriába,memcmp: a két memóriaterület összehasonlítása, adott hosszon,memchr: megkeresi az adott karaktert a memóriában, adott hosszon. Ha nem találja, NULL-t ad vissza.
V.3.7. dirent.h
A dirent.h fájlban a háttértárolón található könyvtárak kezelésének adattípusai és függvényei találhatók. A dirent.h nem része a C szabványnak, de a POSIX rendszer tartalmazza. A Microsoft Visual C++ nem tartalmaz dirent.h-t. Ott ezen függvények Win32-es megfelelőit kell alkalmazni (FindFirstFile, FindNextFile,FindClose).
struct dirent: a könyvtárbejegyzés adattípusa a memóriában. Tartalmazza a fájl sorozatszámát, és nevét, mint char[] tömböt. Tartalmazhat még fájl offsetet, rekordméretet, névhosszat, és fájltípust,
opendir: megadott nevű könyvtár kinyitása, memóriaváltozóba helyezése,readdir: bejegyzés olvasása a kinyitott könyvtárból. A könyvtár végén (ha már nincs több bejegyzés), NULL-t ad vissza,readdir_r: a közvetlen elérésű fájlokhoz hasonlóan direkt cimzéssel is olvashatjuk a katalógust,seekdir: areaddir_r()által használt mutató mozgatása,rewinddir: areaddir_r()által használt mutató mozgatása az első elemre,telldir: areaddir_r()által használt mutató lekérdezése,closedir: a könyvtár bezárása. Egyetlen rendszerben sincs végtelen sok fájl vagy könyvtárkezelő.
V.3.8. sys/stat.h
Ebben a fejállományban a fájlok állapotával kapcsolatos függvények és konstansok kaptak helyet.
struct stat: a fájl állapotát ebbe a struktúrába képes beolvasni. A struktúra tagjai:st_dev: az eszköz, ahol a fájl található,st_ino: a fájl inode-ja,st_mode: a fájl elérési jogok, és tipus: ST_ISREG: közönséges fájl, ST_ISDIR: könyvtár.st_nlink: a fájlhoz tartozó hard linkek (=további fájlnevek) száma,st_uid: a fájl tulajdonosának felhasználói azonosítója (user id),st_gid: a fájl tulajdonosának goup id-je,st_rdev: az eszköz azonosítója, ha az nem reguláris fájl (pl. eszköz),st_size: a fájl mérete,st_blksize: a fájl blokkmérete,st_blocks: a fájl által lefoglalt blokkok száma,st_atime: az utolsó elérés ideje,st_mtime: az utolsó tartalommódosítás ideje,st_ctime: az utolsó állapotmódosítás ideje.
stat: egy névvel adott fájl állapotát lekérdező függvény a struct stat típusú mutató által megcímzett területre. Ha a file egy szimbolikus link, a stat az eredeti file paramétereit adja vissza,fstat: mint astat(), de nem fájlnevet adunk meg, hanem a nyitott fájlra jellemző leírót,lstat: mint astat(), de nem az eredeti fájl állapotát adja vissza, hanem visszatér a linkkel.
V.3.9. unistd.h
Az unistd.h fájlban a szabványos Unix-ok alatti programüzemeltetéssel kapcsolatos konstansok és függvények találhatók. Ezek közül néhányat ismertetünk:
chdir: az aktuális könyvtár cseréje,chown: a fájltulajdonos cseréje,close: nyitott fálj zárása, leírójának segítségével,crypt: jelszó titkosítása,dup: fájlkezelő másolása,execl/ecexle/execv: új folyamat (program) futtatása,_exit: kilépés a programból,fork: alfolyamat futtatása, a sajátunkból indítva. Lemásoljuk neki a környezetünket, elindítjuk, majd megvárjuk, amíg végez,link: fájlhoz hard vagy szimbolikus link készítése,lseek: a fájlmutató mozgatása,nice: program futtatása, ha a rendszer terhelése alacsony,pipe: csővezeték készítése az adatoknak,read: olvasás fájlból, leírójának használatával,rmdir: könyvtár törlése,setuid: aktuális felhasználó azonosítójának beállítása,sleep: várakozás megadott ideig,sync: a fájlrendszer puffereinek aktualizálása,unlink: fájl törlése,write: fájl írása, leírójának használatával.
VI. fejezet - Célspecifikus alkalmazások
VI.1. SOC (System On a Chip)
VI.1.1. A SOC definíciója
A „SOC” rövidítés jelentése „System on a Chip”, vagyis rendszer egy integrált áramköri tokban. Kifejlesztési szempontjainál lényeges szerepet játszott a teljes berendezés alacsony összköltsége, a berendezés kis mérete, fogyasztása. Nem tudunk éles határvonalat húzni a SOC és a mikrovezérlő közt, szokásosan a 128 kb RAM memória feletti eszközöket nevezzük SOC-nak, az ez alattiakat pedig mikrovezérlőnek. Természetesen ez a határvonal sem éles, ugyanis létezik mikrovezérlőként gyártott eszköz 512k memóriával is. Más szempontból is húzhatunk határvonalat (bár ez sem lesz éles): a SOC-on általában interaktív felületű operációs rendszert futtatunk (legtöbbször valami Unix-klónt, pl. Linuxot), míg a mikrovezérlőn egy feladatspecifikus program működik. Ez a szempont is a memóriamérettel operál: általában a Unix-klónoknak nem elég a 128 kbyte körüli memória.
VI.1.2. A SOC részei
A SOC (és a mikrovezérlő is) különböző hardverelemekből állhat, azonban mindig tartalmaz egy vagy több CPU (esetleg DSP) magot, amely egy műveletvégző egység. Szokásos gyártási eljárás, hogy a SOC gyártója a CPU magot másik gyártótól veszi, majd körberakja a saját hardverelemeivel, és betokozza. Ez a rész felel meg kb. a PC-k processzorának. A tápellátó és buszvezérlő áramkörök is mindig megtalálhatók. Ezen elemek (pl a CPU mag) lábai közvetlenül nem jelennek meg a SOC lábai közt. A busz is jellemzően belső busz szokott lenni, ha külső memória/periféria csatlakoztatási lehetőség is van, azt buszillesztőn keresztül vezetik ki.
Opcionális, szokásos hardverelemek:
RAM: operatív memória. A mikrovezérlőnél a kisméretű memória a tokban kapott helyet, míg a SOC-nál általában memóriabusz van kivezetve, amelyen keresztül külső, általában dinamikus RAM IC-ket lehet a SOC-hoz kötni. Ennél a megoldásnál a rendszertervező a szükséges méretű memóriával láthatja el a rendszert. A mikrovezérlőket többféle memóriamérettel gyártják, hogy az adott alkalmazáshoz leggazdaságosabban alkalmazhatót lehessen beszerezni.
ROM: csak olvasható memória. Mikrovezérlőnél a teljes programot tárolja, és a tokban van elhelyezve, míg a SOC-nál külső ROM busz lett kialakítva, amely vagy a teljes operációs rendszert tárolja, vagy csak egy betöltő programot, a tényleges operációs rendszer valahonnan betöltődik (háttértár, hálózat). A manapság használatos SOC-okat és mikrovezérlőket flash típusú EEPROM-mal látják el, hogy a szoftver (firmware) felhasználók által is lecserélhető legyen. Programfejlesztés közben ez a megoldás kényelmes: az UV fénnyel törölhető EPROM-ok korszakában egy programhiba javítása a törlés miatt legalább 10 percet vett igénybe, ma ezredmásodperces a nagyságrend. A SOC/mikrovezérlő tartalmazhat olyan kódot, amely a saját ROM memóriáját képes programozni (self-write, bootloader). A mikrovezérlő gyártók kész program és nagy mennyiség rendelése esetén maszkprogramozott ROM-mal is gyártanak, amikor már gyártás közben belekerül a módosíthatatlan program a mikrovezérlőbe, így lesz a fajlagos költség a legkisebb.
Oszcillátor: a kisebb mikrovezérlők tartalmaznak belső RC oszcillátort, amely az órajelgenerátor szerepét képes betölteni. Az előállított frekvencia nem elég pontos az USB-hez és az ethernethez, de elég az RS-232-höz.
Watchdog: egy CPU-tól független számláló, amelyet programból periodikusan le kell nulláznunk. Amennyiben „elszáll” a program (vagy elfelejtettük nullázni), a túlcsordulásakor egy hardver reset jelet küld a CPU-nak, vagyis hardveres újraindítás történik.
Interrupt és DMA vezérlők: a megszakítások és a direkt memóriába történő adatmozgatás vezérlését végzik. Az összes periféria (időzítők, A/D átalakító, GPIO) képesek bizonyos feltételek esetén megszakítást kérni, amely után a megszakításkezelő programok futnak le.
GPIO szabadon felhasználható digitális ki/bemenet, általában párhuzamos portillesztéssel, vagyis a processzor szóhosszúságának megfelelő számú vezeték, amelyeket egyetlen utasítással lehet aktualizálni vagy beolvasni. A GPIO minden SOC-nál megtalálható, hogy a rendszer tervezője képes legyen perifériákkal (pl. egy LED-del) jelezni a készülék üzemállapotát. A GPIO általában programozható kimenetre és bemenetre is: egy programrészlet mondja meg, hogy a láb a kimeneti regiszterben található értéket vegye fel (ekkor beolvasva természetesen a kimeneti regiszter értékét kapjuk), vagy nagyimpedanciás állapotban (TRI-State) a külvilág állíthatja be a bit tartalmát, amelyet beolvashatunk (például egy nyomógomb).
A/D átalakító: az adott lábra analóg feszültség kapcsolható, amelyet programból beolvashatunk. A beépített átalakítók 10-12 bitesek, és néhány megaHertz az átalakítási órajelük. Több láb is lehet analóg bemenet egy átalakítóhoz, ekkor először egy multiplexerrel kell kiválasztani, melyik csatornát szeretnénk használni. Az A/D átalakító referenciafeszültsége lehet a vezérlő tápfeszültsége, valamelyik analóg inputot fogadni képes lába, vagy belső, programozható feszültségreferencia.
Komparátor: az analóg bemenetre használt lábakat egy összehasonlító áramkörre is vezethetjük, amelynek a másik bemenetén ugyanazon lehetőségek közül választhatunk, mint az A/D átalakítónál. A komparátor kimenete a két jel összehasonlításának eredménye (kisebb, egyenlő, nagyobb).
Időzítő/számláló (Timer/Counter): Ezek az eszközök növekvő számlálót tartalmaznak. Az időzítő adott érték elérésekor kimeneti jelet ad vagy megszakítást kér. A számláló bemenete lehet egy digitális bemenet láb, vagy a rendszer órajele, valamilyen leosztás (prescaler) után. A számláló túlcsorduláskor kér megszakítást. A számláló értéke ki is olvasható. 8- és 16-bites számláló használata szokásos, a többi bitet a megszakításkezelőben szoftverből kell megvalósítani.
PWM kimenet: impulzusszélesség-modulált kimenet. Egy adott frekvenciájú (timer kimenete) négyszögjel, amelynek kitöltési tényezője programozható (0%-nál csak L szintű, 100%-nál csak H szintű). DC motorok és lámpák kis veszteségű teljesítményszabályozására használható. Rendszerint legalább 2 van belőle, hogy a teljes H hidat meg lehessen valósítani (két másik digitális kimenettel a forgásirány szabályozáshoz). Teljesítményfokozat nincs beépítve, mindig külső FET-eket kell illeszteni.
Soros ki/bemenet: kétvezetékes aszinkron kommunikáció, egyszerűen megvalósítható akár gépi kódban is. A régebbi PC-k soros portjához (COM) tudtunk kapcsolódni, a port mára eltűnt a PC-kről, de az iparban még mindig használják egyszerűsége és robosztussága miatt. A SOC (és mikrovezérlő) tápfeszültségei nem teszik lehetővé az RS-232 szabvány szerinti jelszinteket, így mindig külső szintillesztőt kell alkalmazni. Hasonlóan RS-422-re is illeszthető a rendszer, ha nagyobb távolságú átvitelre van szükség. Az adatátviteli sebesség 75 bit/sec-től (baud) 115200 bit/sec-ig terjedhet. Szokásos sebességek a 9600 és a 19200 bit/sec. A modern pc-hez soros bővítőkártyával vagy USB-serial konverterrel csatlakozhatunk, amely a PC-n egy virtuális soros portot hoz létre. Gyakran a SOC-nál (amelyben operációs rendszer is fut) a soros portra irányítják a konzol üzeneteket, kezdve a kernel indításától. A soros port csatlakozó header-ét (tüskesor) a SOC-ot tartalmazó nyomtatott áramköri lapon szintillesztés nélkül kivezetik. Szintillesztővel és egy, a PC-n futó terminálprogrammal közvetlenül az operációs rendszernek adhatunk parancsokat.
USB: ma szinte minden számítógép tartalmaz USB portot, és rengeteg USB-s eszköz kapható. Az USB előnyei, hogy tápfeszültséget is találunk benne (5V/500mA), az adatátviteli sebesség magasabb, mint a soros portnál: 1.5 Mbit/sec (1.0 low speed) , 12 Mbit/sec (1.0 full speed), 480 Mbit/sec (2.0 high speed), 5 Gbit/sec (3.0 superspeed), valamint menet közben is rácsatlakoztatható a gépre, amely vezérlő programját automatikusan elindítja. Többfajta megvalósítása lehet az USB-s kommunikációnak: lehet a PC a master, a SOC pedig az USB-s periféria, vagy lehet a SOC a master (USB Host), és egy pendrive vagy külső HDD, webkamera a periféria. A SOC által megvalósított periféria is többféle lehet: általában az USB stack valamelyik szintjét használják, például a CDC-t, amely soros portként látszik a PC-n, és emiatt a soros portot kezelni tudó programokkal külön meghajtó program nélkül is tud kommunikálni. Készülhet még HID protokollal és a nyílt forráskódú libusb-vel a kommunikáció, ekkor a PC-re is telepíteni kell a szükséges programokat.
Ethernet: a helyi hálózat, 10/100/1000 Mbit/sec sebességgel. Általában nem épül be a SOC-ba, mert külső transzformátort és transceivert igényel, de a SOC-ot fel kell készíteni a kezelésére, a szükséges bitszélességű MII porttal. Az ethernettel felszerelt SOC-ot általában nem natív ethernet protokollal kezeljük, hanem TCP/IP-vel. Így a SOC internetre köthető, emiatt távolságproblémák nem lépnek fel a kommunikációban. A TCP/IP szintje felett szabványos kimenetű alkalmazások állhatnak: például webszerver, ekkor a PC-n (vagy akár mobiletelefonon) web böngészővel kommunikálhatunk a SOC-cal. Tipikus alkalmazása a SOC-oknak a szélessávú router, amely egy ethernet portot tartalmaz az Internethez való csatlakozáshoz (ezen a porton DHCP vagy PPPoE kliens fut a szolgáltatóhoz bejelentkezve) és egy 4-portos ethernet kapcsolót (switch), ezeken a portokon DHCP és egyéb szerverek biztosítják a gépek csatlakoztatását. A konfigurálás webes felületen történik, a beépített webszerverrel. Az operációs rendszer általában Linux, az EEPROM és a RAM külső. Soros port a nyomtatott áramköri lapon kiépítve, ide kerülnek a kernel üzenetei. Némelyik eszközben USB port is helyet kapott, az ide kötött perifériákat (nyomtató, külső HDD) a hálózat eszközei is láthatják.
I2C: a Philips által kifejlesztett kétvezetékes (SDA, SCL) soros kommunikáció, ahol egy mester (master) eszközhöz több szolga (slave) eszköz is csatlakoztatható, a nyitott kollektoros kimeneteknek és a felhúzó ellenállásoknak köszönhetően. A SOC képes a master és a slave szerepében is működni, de legtöbbször masterként alkalmazzuk. I2C -n különféle perifériákat kapcsolhatunk a SOC-hoz: például EEPROMot, hőmérőt, gyorsulásmérőt, hangerőszabályzót, tv-tunert. Az I2C órajelének sebessége max. 100 kHz, az újabb eszközöknél 400 kHz. Minden eszköznek 7-bites címe van, így 127 eszköz használható egy buszon. Az Intel néhány alaplapján alkalmazza a protokollt, smbus néven. A kommunikációt mindig a master kezdeményezi, a végén „ACK” jelzést küld a megcímzett eszköz, így jelenléte detektálható.
SPI: soros periféria busz. Az adatvonalakból kettőt alkalmaz: egyet a mastertől a slave-ig, egyet pedig visszafele, így a kommunikáció full-duplex is lehet. Órajelből csak egy van: mastertől a slave-ig. Célszerűen pont-pont összeköttetésre tervezték, de több slave is felfűzhető a buszra, a „Slave Select” jel segítségével, amelyek közül csak egyet kell aktivizálni. A szabványban nem szerepel maximális sebesség, az adott gyártó adatlapján kell tájékozódni. Azonban ez a sebesség Mbit/s nagyságrendbe szokott esni, ami az I2C -nél nagyobb.
RTCC: valós idejű óra, különálló táplálással. A rendszeridő aktualizálódik a SOC kikapcsolása után is.
CAN busz interfész: főleg a járműiparban használt hardver és protokoll a központi számítógép (ECU) (esetleg SOC) valamint a szenzorok és aktuátorok közti kommunikációra. Néhány ipari és egészségügyi berendezés is alkalmazza.
Képmegjelenítő egység: a médialejátszókba épített SOC-ok tartalmaznak mpeg-2 és h.264 videó dekódert, manapság HDMI kimenettel.
Álljon itt két tipikus blokk-diagram: egy mindentudó mikrovezérlőé (forrás: Microchip, típus: PIC32MX család), és egy médialejátszóba szánt SOC-é (forrás: Realtek, tipus: RTD1073) A Realtek kevésbé dokumentált, ott csak a külső csatlakozásokat tüntették fel.
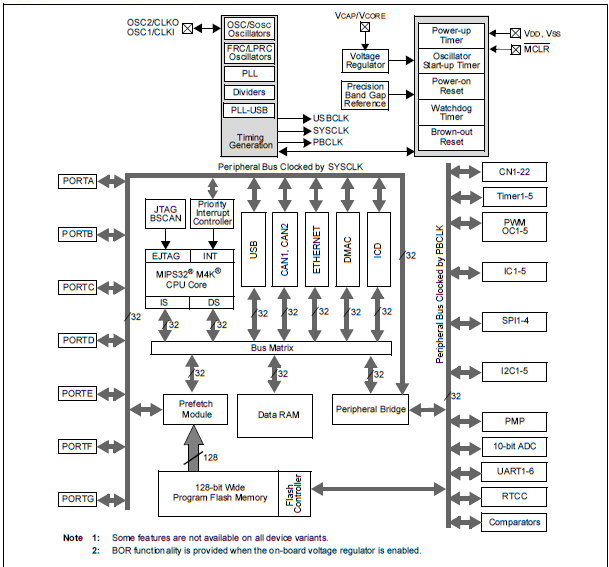
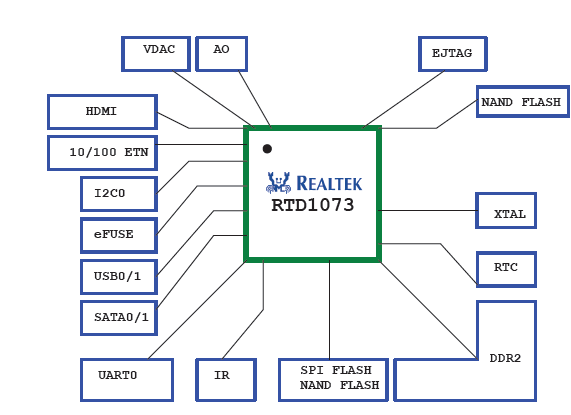
VI.2. Beágyazott eszközök, PC-s fejlesztő rendszerek
Mint ahogy láttuk, a SOC-ok egy PC-hez képest kisebb memóriával és háttértárral rendelkeznek, megjelenítő eszközzel általában nem. A mikrovezérlők még kisebb memóriát tartalmaznak. Ezekre az eszközökre készülő fejlesztő rendszerek nem az adott eszközön futnak (nem is futhatnának), hanem egy általános célú számítógépen, ami általában PC. A SOC-ok magja valamilyen RISC processzor szokott lenni, ehhez a GCC képes kódot generálni, cross-compiler üzemmódban. Kezelői felület nincs a fejlesztő eszközhöz: szövegszerkesztővel írjuk a C forrásprogramokat, majd lefordítjuk a cross-compiler GCC-vel. Összerakjuk a Linux kernelt, és a rendszerfájlokat, valamint a felhasználói állományokat és a rendszerbetöltőt egy ROM fájlba, és ezt a fájlt töltjük be a SOC EEPROM-jába. Az első alkalommal, amíg még a rendszerbetöltő nincs bent, a SOC JTAG csatlakozóján keresztül tudjuk az EEPROM-ot írni, egy JTAG égető segítségével. A SOC-okhoz általában nem készül SDK (szoftver fejlesztő készlet), mert azok egyedi gyártással születnek, így a kereskedelemben az IC-k nem is kaphatók, csak valamilyen eszközbe építve. A kész berendezéshez (pl. szélessávú router) amennyiben Linux-ot használ, kötelező forrást adni a gyártó honlapján. Ennek módosításával tudunk beavatkozni az eszköz működésébe, vagy egy másik Linux-ot fordítani hozzá. Ilyen például az OpenWRT projekt, amelyben Linux alatt, egy cross-gcc-vel saját disztribúciót készítettek, amely egyes, a dokumentációban megjelölt routerekre feltölthető. Az OpenWRT viszonylag jól dokumentált projekt, a dokumentáció reverse-engineering módszerrel keletkezett, valamelyik gyártmány GPL forrásából.
A mikrokovezérlők esetén más a helyzet. Általános célú, program nélküli eszközök, amelyeket nagy mennyiségben gyártanak, lehetővé téve a felhasználó számára a feladatnak megfelelő program beleírását. Az alkalmazott nyelv leggyakrabban a K&R C (a C++ kód futtatása túl nagy memóriát igényelne). A kisebb, 8-bites mikrokovezérlőket lehet gépi kódban is programozni. A gépi kód előnye, hogy kisméretű, hatékony és gyors program keletkezik, hátránya, hogy a kód (és az utasításkészlet ismerete) nem hordozható. A mikrovezérlő gyártók minden esetben biztosítanak fejlesztő eszközöket az ingyenes, oktatási célú felhasználásra szánt (de már működő és a gyártó oldaláról letölthető) fordítótól, a professzionális, cégeknek szánt komplett fejlesztő környezetig. Más mikrovezérlőket a GCC is támogat, ott a gyártó csak fejállományokat és kezelői felületet biztosít. Miután a fordítóprogramok C nyelvű fájlokat fordítanak futtatható ROM fájlokká parancssoros fordítóprogrammal, ezért akár a Visual Studio is használható kezelői felületként, megfelelő beállítások után. Az elkészült kódot itt is JTAG-gal, vagy az adott mikrovezérlő programozójával lehet a mikrovezérlőbe betölteni. Általában a költséges JTAG helyett 50$ körüli áron kaphatók ezek a programozók, és az internet tele van kapcsolási rajzokkal, amelyek 1-2$-ból kihoznak valami használható megoldást. A továbbiakban a két legnagyobb mikrovezérlő gyártó, az Atmel és a Microchip fejlesztő eszközeit ismertetjük. A két gyártó nagyjából ugyanazt gyártja, izlés dolga, hogy melyiket alkalmazzuk. Az Atmel inkább a professzionális felhasználókat célozza meg, ez az árakban is érvényesül. A Microchip az amatőr felhasználóknak is gyárt: DIP foglalatos mikrovezérlő otthoni körülmények közti forrasztáshoz, kis mennyiségben (1 darab) is általában beszerezhető a magyarországi hivatalos disztribútornál. Mindkét gyártó készít úgynevezett kezdő készleteket (starter kit), amelyek egy kész próbapanelt mikrovezérlővel, ki- és bemeneti perifériákat (az olcsó változatban LED és nyomógomb, a drágában DC motor és érintőképernyő), programozót, és készen lefordítható és futtatható demo-programokat tartalmaznak.
VI.2.1. Atmel: WinAVR és AVR studio
A legtöbb Atmel mikrovezérlőt a GCC fordító is támogatja, így nyílt forráskódú IDE is készült hozzá: a WinAVR a Sourceforge weblapon található. Ingyenes, regisztrációmentes letöltés és telepítés után a GCC fordító és a szükséges binutils, valmint a gdb debugger is használható. Az ingyenes programokra jellemzően nincsenek kényelmi funkciók, vagy programkönyvtárak a speciális hardverekhez; ezeket külön kell telepítenünk. A VI.3. ábra - A mintaprogram ábra egy interneten található led-villogtató mintaprogram fordítását mutatja a WinAVR-rel. A Makefile-t és a led.c fájlt kellett ehhez a projekthez megírni a szövegszerkesztővel, majd a Tools menü „Make All” menüpontját kiválasztani.
Az első két értékadó utasítás lefordítva:
void main(void)
{ unsigned char i;
// set PORTD for output
DDRB = 0xFF;
34: 8f ef ldi r24, 0xFF ; 255
36: 87 bb out 0x17, r24 ; 23
PORTB = 0b00000001;
38: 81 e0 ldi r24, 0x01 ; 1
3a: 88 bb out 0x18, r24 ; 24
Elkészült az EEPROM tartalom (led.eep), amit az avrdude programozó szoftverrel, stk600-as hardverrel (200$) vagy AVRISP-vel (40$) be lehetne égetni az ATTiny2313-ba.
Az Atmel is elkészítette a saját IDE-jét, amelyhez több programkönyvtárat is adnak, ennek neve AVR Studio. Tartalmaz beépített C fordítót, de az internetes világ a GCC fordítót használja, így az AVR Studio beállítható úgy, hogy a WinAVR-ben található GCC fordítóval működjön együtt.
VI.2.2. Microchip: MPLAB IDE és MPLAB-X
A Microchip-nél gcc támogatás nincs (picgcc projekt ugyan létezik, de letölthető változat nincs), így a cég weboldaláról ingyenesen letölthetjük az MPLAB IDE-t, amely assembler fordítót (MPASM) tartalmaz az összes termékükhöz (16xx,18xx,24xx,dsPIC), kivéve a PIC32 családot (MIPS core:asm32), és a C fordítóból az oktatási licenszű verziót a 18-as (c18), 24-es (c24) és 32-es (c32) sorozathoz. Az IDE a szerkesztésen kívül az összes beszerezhető programozót és debuggert is támogatja. Amennyiben kényelmesen szeretnénk használni, ne kérjünk teljes telepítést (full installation), csak a meglévő (tervezett) eszközeinket és fordítóprogramokat telepítsük fel. Hasznos eszköz lehet az MPLAB SIM, amellyel konkrét hardver nélkül futtathatjuk, debuggolhatjuk programjainkat, egy virtuális CPU-n. A virtuális CPU nagy előnye, hogy fordított polaritású tápcsatlakoztatással nem tehető tönkre, a valódi változattal szemben. A következő ábrán (VI.4. ábra - Az MPLAB IDE) a IV.2.23. szakasz - A SerialPort szakaszban található programmal (SerialPort) kommunikáló programrészlet fejlesztése látható.
A VI.4. ábra - Az MPLAB IDE programrészletete egy PicKit2-vel (eredeti: 40$, klón: 25$) beégethetjük egy PIC18f4550-be, és USB-n keresztül már kommunikálhatunk is a hardverrel.
Az MPLAB IDE fejlesztése során alkalmazott problémákat (Windows-függőség) próbálja meg feloldani az új MPLAB-X. A NetBeans alapú környezet fut Linuxon és MacOS-X-en is. Ez már tartalmazza a Visual Studio-ban alkalmazott automatikus kódkiegészítő funkciót és a függvény-definíció keresőt.
VI.3. Elosztott rendszerek programozása
Az internet és alapprotokolljának elterjedésével nemcsak az emberek közti kommunikáció gyorsult fel. Ma már a szuperszámítógépek nem egy nagy órajelű processzort és nagymennyiségű operatív és háttértárat tartalmaznak. Az órajelben elértük a technológiai határt, teljesítménynöveléshez csak a párhuzamosan egyszerre működő elemi számoló egységek számának növelésével juthatunk el. Ezt a célt szolgálja az egyetlen integrált áramkörbe tokozott több processzor mag (Dual, Quad stb core). Kézenfekvő volt, hogy valahogy szétoszthatók legyenek a feladatok interneten keresztül is. Az internetes kapcsolat két gép közt szekvenciális fájlként jelentkezik, a socket programcsomagot használva. Az első, socketre épülő, de annál magasabb szintű elérést lehetővé tevő módszer a távoli függvényhívás (RPC), amelyet pl. a SUN NFS Unix alapú fileszerver valósít meg. A programozó viszont nem protokollt, hibakezelést és fájlelérést szeretne fejleszteni, rendelkezésre állnak a socketre épülő objektumorientált technológiák is. Ezeknél a technológiáknál a kiszolgálón levő objektum tulajdonságai az ügyfélen elérhetők, metódusai a kiszolgálón futtathatók, az ügyfélen egyszerű függvényhívásként. Hasonlóan, a szerveren fellépő esemény is a kliensen lévő triggerelt metódussal kezelhető. Arra is van lehetőség, hogy az IP címen csak egy proxy szerepeljen, és továbbítsa a felhasználó kérését egy éppen szabad kiszolgáló gép számára. A mai nagy számításigényű rendszerek a kereskedelemben és a kutatásban is hasonló elven működnek. Példaként az amazon.com-ot, a google rendszerét vagy a JUQUEEN és JUROPA gépeket (IBM) említhetjük.
VI.3.1. CORBA
A CORBA egy, az OMG (Object Management Group) által definiált szabványos objektum környezet, 1990-ben jelent meg az első verziója, amellyel különféle nyelveken írt, és/vagy különálló gépeken futó alkalmazások együtt képesek dolgozni. Az alkalmazás a metódusokat ugyanúgy használhatja a távoli gépen is, mint a helyi gépen. A szabvány fontos eleme az interfész definíciós nyelv (IDL), amely a konkrétan használt fordítóprogramtól (amely fordíthat C-ről, C++-ról, Java-ról, Cobol-ról és még néhány egyéb nyelvről) független. A CORBA fordító elkészíti az adott nyelvhez az IDL-ben megírt objektumokhoz a függvények fejléceit (skeleton - csontváz), amelyet nekünk kell az adott nyelven implementálni, ezt a folyamatot „mapping”-nek, az így készített objektumokat pedig „adapter”-nek nevezzük. A mapping a Java nyelvben egyszerű, a nyelv erősen objektum-orientált tulajdonságai miatt. C++-ban kissé többet kell dolgozni: összetett adatszerkezetek felhasználására van szükség, amelyek néha összekeverednek a szabványos sablonkönyvtár (STL) típusaival. A CORBA implementáció tartalmaz egy IDL fordítót, amely már a felhasznált nyelvre (pl C++) fordít, és a szabályos fordítóval és szerkesztővel készíthetünk futtatható programot, természetesen az IDL-ből fordított függvények definiálásával (a csontváz „felöltöztetésével”) az adott programnyelven. Emellett tartalmaz natív kommunikációs komponenseket, amelyek az internetes, socket szintű kommunikációt bonyolítják, a felhasználó számára transzparens módon. Az alábbi (VI.5. ábra - CORBA beépítés) ábrán egy kiszolgálón működő objektum ügyfélből történő elérését szemléltetjük:
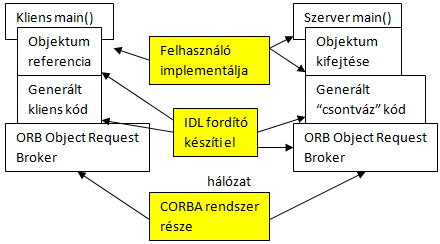
VI.3.2. A CORBA nyílt forráskódú implementációi
A CORBA egy szabvány, emiatt nem egy gyártótól szerezhető be: többen is implementálták a struktúrát. Licenszelhető (vásárolható) és nyílt forráskódú változatok egyaránt léteznek. A licenszelhető implementációk főleg a pénzügyi szektorban terjedtek el, az oktatásban az ingyenesen hozzáférhető nyílt forráskódú változatok valamelyikét használjuk.
MICO: www.mico.org a Frankfurti egyetem fejlesztéséből született, C++ nyelven íródott, egyedül Unix API hívásokat alkalmaz. A forrásfileokat a SourceForge-n tárolják, onnan letölthetők.
JacORB: www.jacorb.org Java nyelvű ORB, LGPL licensszel. JDK 1.6 kell a működéséhez.
TAO: www.ociweb.com A Washingtoni egyetem fejlesztése, létezik ingyenes és kereskedelmi változatban is. Unix-on és Windows-on is használhatjuk, létezik valós idejű (real-time) operációs rendszeren futó verzió is.
ORBiT: orbit-resource.sourceforge.net Alap C-ben és Perl-ben is használható, nyílt forráskódú CORBA 2.4 implementáció. Mivel a GNOME rendszerhez fejlesztették ki, a legtöbb Linux disztribúció tartalmazza. Win32 alatt futó változat is készült belőle.
Az alábbi példában egy "távoli" számítást fogunk elvégezni, az ügyfél megadja a műveletet, a kiszolgáló elvégzi, az ügyfél pedig kijelzi az eredményt. A példában mindkét program (a kliens és a szerver) is ugyanazon a számítógépen fut. Az IDL fájl a lehető legegyszerűbb, egy interfészt két függvénnyel tartalmaz:
// Calculator interface: calculator.idl
//
interface Calculator
{
double add(in double number1, in double number2);
double sub(in double number1, in double number2);
};
Fordítsuk le az idl compilerrel: /usr/pkg/bin/orbit-idl-2 calculator.idl !
orbit-idl-2 2.14.17 compiling mode, hide preprocessor errors, passes: stubs skels common headers Processing file calculator.idl
Ekkor elkészül a „csontváz” (calculator-skel.c), a kliensen futtatható stub (calculator-stubs.c), és a fejállomány (calculator.h). A header fájlban megtaláljuk a CORBA kompatibilis osztályt (alap C, struct függvényekkel):
typedef struct {
void *_private;
CORBA_double (*add)(PortableServer_Servant _servant, const CORBA_double number1, const CORBA_double number2, CORBA_Environment *ev);
CORBA_double (*sub)(PortableServer_Servant _servant, const CORBA_double number1, const CORBA_double number2, CORBA_Environment *ev);
} POA_Calculator__epv;
Ezeket kell implentálnunk (skelimpl.c):
static CORBA_double
impl_Calculator_add(impl_POA_Calculator * servant,
const CORBA_double number1,
const CORBA_double number2, CORBA_Environment * ev)
{
CORBA_double retval;
/* ------ insert method code here ------ */
g_print ("%f + %f\n", number1, number2);
retval = number1 + number2;
/* ------ ---------- end ------------ ------ */
return retval;
}
static CORBA_double
impl_Calculator_sub(impl_POA_Calculator * servant,
const CORBA_double number1,
const CORBA_double number2, CORBA_Environment * ev)
{
CORBA_double retval;
/* ------ insert method code here ------ */
g_print ("%f - %f\n", number1, number2);
retval = number1 - number2;
/* ------ ---------- end ------------ ------ */
return retval;
}
Ezután következhet a kiszolgáló oldali főprogram:
static CORBA_Object
server_activate_service (CORBA_ORB orb,
PortableServer_POA poa,
CORBA_Environment *ev)
{
Calculator ref = CORBA_OBJECT_NIL;
ref = impl_Calculator__create (poa, ev);
if (etk_raised_exception(ev))
return CORBA_OBJECT_NIL;
return ref;
}
A kiszolgáló main() függvényben elindítjuk a szolgáltatást:
servant = server_activate_service (global_orb, root_poa, ev); server_run (global_orb, ev);
Az ügyfélen a stubon nem kell változtatnunk, csak a main() függvény megírása hiányzik:
static
void
client_run (Calculator service,
CORBA_Environment *ev)
{
CORBA_double result=0.0;
result = Calculator_add(service, 1.0, 2.0, ev);
g_print("Result: 1.0 + 2.0 = %2.0f\n", result);
}
Ezt az ügyfél main() függvényéből meghívjuk, és a kiszolgáló elvégzi a számolást:
calculator-server & elindítjuk a kiszolgálót a háttérben, ami vár a kliens csatlakozására
calculator-client elindítjuk az ügyfelet
1.000000 + 2.000000
Result: 1.0 + 2.0 = 3
VI.3.3. ICE – internet communication engine
A CORBA rendszert megvizsgálva azt láthatjuk, hogy sok feladatra alkalmazható, azonban a szükséges programozási munka nagy része a feleslegesen túlbonyolított objektumokra és osztályokra megy el. Néhány CORBA fejlesztő ezért egy kis fejlesztő csapatot alakított, hogy a CORBA elveit újragondolva, készítsenek egy bizonyos szempontból leegyszerűsített, bizonyos szempontból bővített távoli objektumelérést támogató rendszert. Erre a feladatra egy céget is alapítottak, ZeroC néven (www.zeroc.com). A rendszert ICE-nak nevezték el, és kétfajta licenszeléssel hozzáférhető: GPL és kereskedelmi licensz is létezik belőle. A kereskedelmi (fizetős) licenszhez terméktámogatás jár. Külön előny, hogy az ICE-hez lélezik a manapság divatos érintőképernyős platformokon futó változat, pl. az IceTouch, amely az OS-X fordítójához (Xcode) készült, és iOS szimulátort is tartalmaz. Az ICE disztribúció tartalmaz mindent, amire a környezetnek szüksége van: eszközöket, API-kat, könyvtárakat az objektumorientált kiszolgáló-ügyfél alkalmazások készítéséhez. Támogatja az architektúrák és nyelvek közti átjárhatóságot: az ügyfél és a kiszolgáló is futhat más platformon, más programozási nyelven megírva. A leíró nyelvet, amelyben definiáljuk az ICE objektumot, Slice-nek nevezzük (Specification Language for Ice). Ez tartalmazza az interfészeket, a műveleteket és az adattípusokat, amelyek a kiszolgálón és az ügyfélen közösen definiáltak. Ezeket a Slice fájlokat egy fordító API hívásokra fordítja, forrásnyelvű programrészletekre, amelyek az aktuális rendszerben és programozási nyelven lefordíthatók, természetesen csak a skeleton kitöltése (a függvények {} közti részének megírása) után. Az egyes nyelvekre való fordítást "language mapping"-nak nevezzük. Az ICE rendszerben a használt nyelv lehet C++, Java, C#, Python, Objective-C. Az ügyféloldalon PHP is alkalmazható. Az ICE-t használó programok szerkezete az alábbi (VI.6. ábra - Az ICE programok szerkezete) ábrán látható:
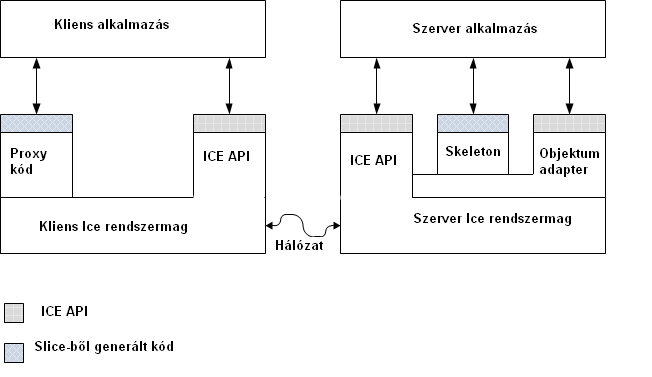
Az ICE saját protokollt használ az IP fölött, ez lehet TCP vagy UDP is. Amennyiben érzékeny adatokat tartalmaznak az objektumaink, SSL-t is használhatunk a kiszolgáló és az ügyfél között. A hagyományos távoli objektumhoz képest plusz szolgáltatásokat is kínál, mint pl. az IceGrid, amelyben több kiszolgáló is tartalmazhatja az objektumot, teherelosztás (load-balancing) céljából, vagy az IceStorm, amely események szétosztását végzi a közzétevők és az esemény iránt érdeklődő előfizetők között.
Az alábbi, egyszerűsített példában egy ipari robot ICE kiszolgáló oldalát készítjük el, a robothoz kapcsolódó ügyfelek képesek a robot mozgatására és az aktuális koordináták lekérdezésére. A slice definiciós állomány a következő (Kuka.ice – a Visual Studioval csak mint szövegfájl nyitható ki):
module CyberLab
{
struct e6pos
{
float x; // x,y,z milliméterek
float y;
float z;
float a; // a,b,c szögek, fokban
float b;
float c;
};
interface Robot6Dof
{
void GotoHome(); // alap pozíció a robot programban
e6pos GetPosition(); // hol vagy ?
void GotoPosition(e6pos p); // menj egy pozícióba
};
};
Ezt a fájlt a slice2cpp.exe-vel lefordítjuk, keletkezik 2 állomány: Kuka.cpp, és Kuka.h. Ez az úgynevezett „csontváz”, amelyben a definiált metódusok, mint absztrakt virtuális tagfüggvények szerepelnek:
virtual void GotoPosition(const ::CyberLab::e6pos&, const ::Ice::Current& = ::Ice::Current()) = 0;
Ráismerhetünk az interfész utolsó függvényére. Ahhoz, hogy az osztályt példányosítsuk, ezt a függvényt definiálnuk kell. A Robot6Dof osztályból örököltetünk egy új osztályt (az implementációs osztályt: Robot6DofI), amelyben ezen tagfüggvények kifejtése szerepel:
class Robot6DofI : public Robot6Dof {
public:
virtual void GotoHome(const Current& c);
virtual e6pos GetPosition(const Current& c);
virtual void GotoPosition(const e6pos& e6, const Current& c);
};
Majd ezeket a függvényeket ki is fejtjük:
void Robot6DofI::GotoHome(const Current& c)
{
Send_command_to_robot(CMD_ROBOT_HOME);
}
e6pos Robot6DofI::GetPosition(const Current& c)
{
e6pos poz;
Send_command_to_robot(CMD_ROBOT_GET_POSITION,poz);
return poz;
}
void Robot6DofI::GotoPosition(const e6pos& e6, const Current& c)
{
Send_command_to_robot(CMD_ROBOT_GOTO_POSITION,e6);
}
A kifejtésben felhasználtuk a már meglévő kommunikációs függvényeket, amelyek a robotnak RS-232-n keresztül parancsokat küldtek. Már csak a főprogramot kell megírni, létrehozni a kommunikációs adaptert (az ICE demo program alapján):
int _tmain(int argc, _TCHAR* argv[])
{
int status = 0;
std::string s1="KukaAdapter";
std::string s2="default -p 10000";
Ice::CommunicatorPtr ic;
Ice::InitializationData id;
argc=0;
try
{
ic = Ice::initialize(id);
Ice::ObjectAdapterPtr adapter=ic->createObjectAdapterWithEndpoints
(s1,s2);
Ice::ObjectPtr object = new Robot6DofI;
adapter->add(object,ic->stringToIdentity("Kuka"));
adapter->activate();
ic->waitForShutdown();
}
catch (const Ice::Exception& e)
{
cerr << e << endl;
status = 1;
}
catch (const char* msg)
{
cerr << msg << endl;
status = 1;
}
if (ic)
{
try
{
ic->destroy();
}
catch (const Ice::Exception& e)
{
cerr << e << endl;
status = 1;
}
}
return status;
}
Ne felejtsük el a projektünk tulajdonságaiban beállítani az ICE include és library könyvtárait, mert azok nélkül nem képes lefordítani és összeszerkeszteni a programot!
A hibátlan fordítás után már csak az ICE-hez tartozó DLL-eket kell a program futása közben elérhetővé tenni, és indulhat a szerver. A Kuka.ice file-t átküldve a külföldi partnernek, ő elkészíti az ügyfelet (valamilyen programozási nyelven, pl C++-ban, vagy C#-ban), és távolról képes irányítani a robotot.
A. függelék - Függelék – Szabványos C++ összefoglaló táblázatok
- A.1. Az ASCII kódtábla
- A.2. C++ nyelv foglalt szavai
- A.3. Escape karakterek
- A.4. C++ adattípusok és értékkészletük
- A.5. A C++ nyelv utasításai
- A.6. C++ előfeldolgozó (perprocesszor) utasítások
- A.7. C++ műveletek elsőbbsége és csoportosítása
- A.8. Néhány gyakran használt matematikai függvény
- A.9. C++ tárolási osztályok
- A.10. Input/Output (I/O) manipulátorok
- A.11. A szabványos C++ nyelv deklarációs állományai
A.1. Az ASCII kódtábla
|
CHAR |
DEC |
HEX |
CHAR |
DEC |
HEX |
CHAR |
DEC |
HEX |
CHAR |
DEC |
HEX | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
[NUL] |
0 |
00 |
32 |
20 |
@ |
64 |
40 |
` |
96 |
60 | ||||
|
[SOH] |
1 |
01 |
! |
33 |
21 |
A |
65 |
41 |
a |
97 |
61 | |||
|
[STX] |
2 |
02 |
" |
34 |
22 |
B |
66 |
42 |
b |
98 |
62 | |||
|
[ETX] |
3 |
03 |
# |
35 |
23 |
C |
67 |
43 |
c |
99 |
63 | |||
|
[EOT] |
4 |
04 |
$ |
36 |
24 |
D |
68 |
44 |
d |
100 |
64 | |||
|
[ENQ] |
5 |
05 |
% |
37 |
25 |
E |
69 |
45 |
e |
101 |
65 | |||
|
[ACK] |
6 |
06 |
& |
38 |
26 |
F |
70 |
46 |
f |
102 |
66 | |||
|
[BEL] |
7 |
07 |
' |
39 |
27 |
G |
71 |
47 |
g |
103 |
67 | |||
|
[BS] |
8 |
08 |
( |
40 |
28 |
H |
72 |
48 |
h |
104 |
68 | |||
|
[HT] |
9 |
09 |
) |
41 |
29 |
I |
73 |
49 |
i |
105 |
69 | |||
|
[LF] |
10 |
0A |
* |
42 |
2A |
J |
74 |
4A |
j |
106 |
6A | |||
|
[VT] |
11 |
0B |
+ |
43 |
2B |
K |
75 |
4B |
k |
107 |
6B | |||
|
[FF] |
12 |
0C |
, |
44 |
2C |
L |
76 |
4C |
l |
108 |
6C | |||
|
[CR] |
13 |
0D |
- |
45 |
2D |
M |
77 |
4D |
m |
109 |
6D | |||
|
[SO] |
14 |
0E |
. |
46 |
2E |
N |
78 |
4E |
n |
110 |
6E | |||
|
[SI] |
15 |
0F |
/ |
47 |
2F |
O |
79 |
4F |
o |
111 |
6F | |||
|
[DLE] |
16 |
10 |
0 |
48 |
30 |
P |
80 |
50 |
p |
112 |
70 | |||
|
[DC1] |
17 |
11 |
1 |
49 |
31 |
Q |
81 |
51 |
q |
113 |
71 | |||
|
[DC2] |
18 |
12 |
2 |
50 |
32 |
R |
82 |
52 |
r |
114 |
72 | |||
|
[DC3] |
19 |
13 |
3 |
51 |
33 |
S |
83 |
53 |
s |
115 |
73 | |||
|
[DC4] |
20 |
14 |
4 |
52 |
34 |
T |
84 |
54 |
t |
116 |
74 | |||
|
[NAK] |
21 |
15 |
5 |
53 |
35 |
U |
85 |
55 |
u |
117 |
75 | |||
|
[SYN] |
22 |
16 |
6 |
54 |
36 |
V |
86 |
56 |
v |
118 |
76 | |||
|
[ETB] |
23 |
17 |
7 |
55 |
37 |
W |
87 |
57 |
w |
119 |
77 | |||
|
[CAN] |
24 |
18 |
8 |
56 |
38 |
X |
88 |
58 |
x |
120 |
78 | |||
|
[EM] |
25 |
19 |
9 |
57 |
39 |
Y |
89 |
59 |
y |
121 |
79 | |||
|
[SUB] |
26 |
1A |
: |
58 |
3A |
Z |
90 |
5A |
z |
122 |
7A | |||
|
[ESC] |
27 |
1B |
; |
59 |
3B |
[ |
91 |
5B |
{ |
123 |
7B | |||
|
[FS] |
28 |
1C |
< |
60 |
3C |
\ |
92 |
5C |
| |
124 |
7C | |||
|
[GS] |
29 |
1D |
= |
61 |
3D |
] |
93 |
5D |
} |
125 |
7D | |||
|
[RS] |
30 |
1E |
> |
62 |
3E |
^ |
94 |
5E |
~ |
126 |
7E | |||
|
[US] |
31 |
1F |
? |
63 |
3F |
_ |
95 |
5F |
[DEL] |
127 |
7F |
A.2. C++ nyelv foglalt szavai
|
and |
double |
not |
this |
|
and_eq |
dynamic_cast |
not_eq |
throw |
|
asm |
else |
operator |
true |
|
auto |
enum |
or |
try |
|
bitand |
explicit |
or_eq |
typedef |
|
bitor |
export |
private |
typeid |
|
bool |
extern |
protected |
typename |
|
break |
false |
public |
union |
|
case |
float |
register |
unsigned |
|
catch |
for |
reinterpret_cast |
using |
|
char |
friend |
return |
virtual |
|
class |
goto |
short |
void |
|
compl |
if |
signed |
volatile |
|
const |
inline |
sizeof |
wchar_t |
|
const_cast |
int |
static |
while |
|
continue |
long |
static_cast |
xor |
|
default |
mutable |
struct |
xor_eq |
|
delete |
namespace |
switch | |
|
do |
new |
template |
Az ANSI/ISO C++ 1998. szabvány szerint
|
alignas |
char32_t |
final |
override |
|
alignof |
constexpr |
noexcept |
static_assert |
|
char16_t |
decltype |
nullptr |
thread_local |
A C++11 szabvány által hozzáadott
|
abstract |
for each |
interior_ptr |
ref class/struct |
|
array |
gcnew |
literal |
safe_cast |
|
delegate |
generic |
nullptr |
sealed |
|
enum class/struct |
in |
override |
value class/struct |
|
event |
initonly |
pin_ptr |
where |
|
finally |
interface class/struct |
property |
A C++/CLI nyelvdefiníció által hozzáadott
A.3. Escape karakterek
|
Értelmezés |
ASCII karakter |
Escape szekvencia |
|---|---|---|
|
csengő |
BEL |
'\a' |
|
visszatörlés |
BS |
'\b' |
|
lapdobás |
FF |
'\f' |
|
újsor |
NL (LF) |
'\n' |
|
kocsi-vissza |
CR |
'\r' |
|
vízszintes tabulálás |
HT |
'\t' |
|
függőleges tabulálás |
VT |
'\v' |
|
aposztróf |
' |
'\'' |
|
idézőjel |
" |
'\"' |
|
visszaperjel |
\ |
'\\' |
|
kérdőjel |
? |
'\?' |
|
ANSI karakter oktális kóddal |
ooo |
'\ooo' |
|
nulla karakter |
NUL |
'\0' |
|
ANSI karakter hexadecimális kóddal |
hh |
'\xhh' |
|
16-bites Unicode karakter |
hhhh |
'\uhhhh' |
|
32-bites Unicode karakter |
hhhhhhhh |
'\Uhhhhhhhh' |
A.4. C++ adattípusok és értékkészletük
|
Adattípus |
Értékkészlet |
Méret (bájt) |
Pontosság (számjegy) |
|---|---|---|---|
|
bool |
false, true |
1 | |
|
char |
-128..127 |
1 | |
|
signed char |
-128..127 |
1 | |
|
unsigned char |
0..255 |
1 | |
|
wchar_t |
0..65535 |
2 | |
|
int |
-2147483648..2147483647 |
4 | |
|
unsigned int |
0..4294967295 |
4 | |
|
short |
-32768..32767 |
2 | |
|
unsigned short |
0..65535 |
2 | |
|
long |
-2147483648..2147483647 |
4 | |
|
unsigned long |
0..4294967295 |
4 | |
|
long long |
-9223372036854775808.. 9223372036854775807 |
8 | |
|
unsigned long long |
0..18446744073709551615 |
8 | |
|
float |
3.4E-38..3.8E+38 |
4 |
6 |
|
double |
1.7E-308..1.7E+308 |
8 |
15 |
|
long double |
3.4E-4932..3.4E+4932 |
10 |
19 |
A.5. A C++ nyelv utasításai
|
Kategória |
C++ jelek, kulcsszavak |
|---|---|
|
Deklarációs/definíciós utasítások |
típusok (class, struct, union, enum, typedef), függvények, objektumok |
|
Kifejezés utasítások |
kifejezés; |
|
Üres utasítás |
; |
|
Összetett utasítás |
{ utasítások } |
|
Szelekciós utasítások |
if, else, switch, case |
|
Iterációs utasítások |
do, for, while |
|
Vezérlésátadó utasítások |
break, continue, default, goto, return |
|
Kivételkezelő utasítások |
throw, try-catch |
A.6. C++ előfeldolgozó (perprocesszor) utasítások
|
Kategória |
Direktíva |
|---|---|
|
Feltételes fordítás |
#ifdef, #ifndef, #if, #endif, #else, #elif |
|
Szimbólum/makró definiálása |
#define |
|
Szimbólum/makró definiáltságának megszüntetése |
#undef |
|
Forrásállomány beépítése |
#include |
|
Fordítási hiba előállítása |
#error |
|
Fordítói üzenetekben a sorszám (és a fájlnév) módosítása |
#line |
|
A fordítási folyamat implementációfüggő vezérlése |
#pragma |
Előre definiált makrók
|
Makró |
Leírás |
|---|---|
|
|
A fordítás dátumát tartalmazó sztring. |
|
|
A fordítás időpontját tartalmazó sztring. |
|
|
A forrásfájl nevét tartalmazó sztring. |
|
|
A forrásállomány aktuális sorának sorszámát tartalmazó konstans (1-től sorszámoz). |
|
|
A értéke 1, ha a fordító ANSI C++ fordítóként működik, különben nem definiált. |
|
|
A értéke 1, ha C++ forrásállományban, különben nem definiált. |
|
|
A értéke 1, ha C++/CLI forrásállományban, különben nem definiált. |
A.7. C++ műveletek elsőbbsége és csoportosítása
|
Precedencia |
Művelet |
Leírás |
Csoportosítás |
|---|---|---|---|
|
1. |
:: |
hatókörfeloldás |
nincs |
|
2. |
( ) |
függvényhívás |
balról-jobbra |
|
[ ] |
tömbindexelés | ||
|
-> |
közvetett tagkiválasztás | ||
|
. |
közvetlen tagkiválasztás | ||
|
++ |
(postfix) léptetés előre | ||
|
-- |
(postfix) léptetés vissza | ||
|
típus () |
típus-átalakítás | ||
|
dynamic_cast |
futásidejű ellenőrzött típus-átalakítás | ||
|
static_cast |
fordításidejű ellenőrzött típus-átalakítás | ||
|
reinterpret_cast |
ellenőrizetlen típus-átalakítás | ||
|
const_cast |
konstans típus-átalakítás | ||
|
typeid |
típus-azonosítás | ||
|
3. |
! |
logikai tagadás (NEM) |
jobbról-balra |
|
~ |
bitenkénti negálás | ||
|
+ |
+ előjel | ||
|
- |
- előjel | ||
|
++ |
(prefix) léptetés előre | ||
|
-- |
(prefix) léptetés vissza | ||
|
& |
a címe operátor | ||
|
* |
az indirektség operátor | ||
|
( típus ) |
típus-átalakítás | ||
|
sizeof |
objektum/típus bájtban kifejezett mérete | ||
|
new |
dinamikus tárterület foglalása | ||
|
delete |
dinamikus tárterület felszabadítása | ||
|
4. |
.* |
osztálytagra történő indirekt hivatkozás |
balról-jobbra |
|
->* |
mutatóval megadott objektum tagjára való indirekt hivatkozás | ||
|
5. |
* |
szorzás |
balról-jobbra |
|
/ |
osztás | ||
|
% |
maradék | ||
|
6. |
+ |
összeadás |
balról-jobbra |
|
– |
kivonás | ||
|
7. |
<< |
biteltolás balra |
balról-jobbra |
|
>> |
biteltolás jobbra | ||
|
8. |
< |
kisebb |
balról-jobbra |
|
<= |
kisebb vagy egyenlő | ||
|
> |
nagyobb | ||
|
>= |
nagyobb vagy egyenlő | ||
|
9. |
== |
egyenlő |
balról-jobbra |
|
!= |
nem egyenlő |
balról-jobbra | |
|
10. |
& |
bitenkénti ÉS |
balról-jobbra |
|
11. |
| |
bitenkénti VAGY |
balról-jobbra |
|
12. |
^ |
bitenkénti kizáró VAGY |
balról-jobbra |
|
13. |
&& |
logikai ÉS |
balról-jobbra |
|
14. |
|| |
logikai VAGY |
balról-jobbra |
|
15. |
kif ? kif : kif |
feltételes kifejezés |
jobbról-balra |
|
16. |
= |
egyszerű értékadás |
jobbról-balra |
|
*= |
szorzat megfeleltetése | ||
|
/= |
hányados megfeleltetése | ||
|
%= |
maradék megfeleltetése | ||
|
+= |
összeg megfeleltetése | ||
|
-= |
különbség megfeleltetése | ||
|
<<= |
balra eltolt bitek megfeleltetése | ||
|
>>= |
jobbra eltolt bitek megfeleltetése | ||
|
&= |
bitenkénti ÉS megfeleltetése | ||
|
^= |
bitenkénti kizáró VAGY megfeleltetése | ||
|
|= |
bitenkénti VAGY megfeleltetése | ||
|
17. |
throw kif |
kivétel kiváltása |
jobbról-balra |
|
18. |
kif , kif |
műveletsor (vessző operátor) |
balról-jobbra |
A.8. Néhány gyakran használt matematikai függvény
|
Használat |
Típusa |
Függvény |
Include fájl |
|---|---|---|---|
|
abszolút érték képzése |
valós |
|
|
|
abszolút érték képzése |
egész |
|
|
|
szög (radián) koszinusza |
valós |
|
|
|
szög (radián) szinusza |
valós |
|
|
|
szög (radián) tangense |
valós |
|
|
|
az argumentum arkusz koszinusza (radián) |
valós |
|
|
|
az argumentum arkusz szinusza (radián) |
valós |
|
|
|
az argumentum arkusz tangense (radián) |
valós |
|
|
|
az y/x arkusz tangense (radián) |
valós |
|
|
|
természetes alapú logaritmus |
valós |
|
|
|
tízes alapú logaritmus |
valós |
|
|
|
ex |
valós |
|
|
|
hatványozás (xy) |
valós |
|
|
|
négyzetgyök |
valós |
|
|
|
véletlen szám 0 és RAND_MAX között |
valós |
|
|
|
π értéke |
valós |
|
|
Ahol a valós típus a float, double és a long double típusok egyikét jelöli, míg az egész az int és long típusok valamelyikét.
A.9. C++ tárolási osztályok
|
Jellemzők |
Eredmény | |||
|---|---|---|---|---|
|
Szint |
Tétel |
Tárolási osztály |
Élettartam |
Láthatóság |
|
fájlszintű hatókör |
változó-definíció |
|
globális |
korlátozva az adott állományra, a definíció helyétől a fájl végéig |
|
változó-deklaráció |
|
globális |
a definíció helyétől a fájl végéig | |
|
prototípus vagy függvénydefiníció |
|
globális |
korlátozva az adott állományra | |
|
függvény prototípus |
|
globális |
a definíció helyétől a fájl végéig | |
|
blokk-szintű hatókör |
változó-deklaráció |
|
globális |
blokk |
|
változó-definíció |
|
globális |
blokk | |
|
változó-definíció |
|
lokális |
blokk | |
|
változó-definíció |
|
lokális |
blokk | |
A.10. Input/Output (I/O) manipulátorok
Paraméter nélküli manipulátorok <iostream>
Az alábbi manipulátorokat párban használjuk, hatásuk a bekapcsolástól a kikapcsolásig terjed:
|
Manipulátor |
Irány |
Leírás (bekapcsolva) |
|---|---|---|
|
|
I/O |
A logikai értékek megadhatók a true és a false szavakkal. |
|
|
O |
A számok előtt a számrendszer jele (0, vagy 0x) is megjelenik. |
|
|
O |
A tizedespont mindig megjelenik. |
|
|
O |
A pozitív előjel is megjelenik. |
|
|
I |
Az elválasztó karakterek átlépése. |
|
|
O |
Automatikus puffer ürítés minden művelet után. |
|
|
O |
A számok megjelenítésében az (e és az x) nagybetűk lesznek |
Néhány adatfolyamot módosító manipulátor:
|
Manipulátor |
Irány |
Leírás |
|---|---|---|
|
|
O |
Sorvége-karakter. |
|
|
O |
Sztringvége karakter. |
|
|
I |
Az elválasztó karakterek átlépése. |
Az alábbi manipulátorok hatását az ugyanazon csoportban megadottal módosíthatjuk:
|
Manipulátor |
Irány |
Leírás |
|---|---|---|
|
Kiigazítás | ||
|
|
O |
Balra igazít. |
|
|
O |
Jobbra igazít – alapértelmezés |
|
|
O |
A mezőben a lehető legjobban széthúzva jelennek meg az értékek. |
|
Számrendszer | ||
|
|
I/O |
Tízes - alapértelmezés |
|
|
I/O |
Tizenhatos. |
|
|
I/O |
Nyolcas. |
|
A valós számok megjelenítése (hiányukban a fordító választ formátumot) | ||
|
|
O |
Tizedes tört alakban. |
|
|
O |
Hatványkitevős formában. |
Paraméterrel rendelkező manipulátorok <iomanip>:
A paraméterrel rendelkező manipulátorok hatása általában csak a közvetlenül utánuk álló adatelemre terjed ki.
|
Manipulátor |
Irány |
Leírás |
|---|---|---|
|
|
O |
Kitöltő-karakter |
|
|
O |
Tizedes jegyek |
|
|
O |
Mező-szélesség |
|
|
O |
Szám-rendszer. |
A.11. A szabványos C++ nyelv deklarációs állományai
|
A C++ nyelvet támogató könyvtár | |
|
Típusok (NULL, size_t stb.) |
<cstddef> |
|
Az implementáció jellemzői |
<limits>, <climits>, <cfloat> |
|
Programindítás és –befejezés |
<cstdlib> |
|
Dinamikus memóriakezelés |
<new> |
|
Típusazonosítás |
<typeinfo>, <typeindex>, <type_traits> |
|
Kivételkezelés |
<exception> |
|
Egyéb futásidejű támogatás |
<cstdarg>, <csetjmp>, <ctime>, <csignal>, <cstdlib>,<cstdbool>, <cstdalign> |
|
Hibakezelési könyvtár | |
|
Kivételosztályok |
<stdexcept> |
|
Assert makrók |
<cassert> |
|
Hibakódok |
<cerrno> |
|
Rendszerhiba-támogatás |
<system_error> |
|
Általános szolgáltatások könyvtára | |
|
Műveleti elemek (STL) |
<utility> |
|
Műveletobjektumok (STL) |
<functional> |
|
Memóriakezelés (STL) |
<memory>, <scoped_allocator> |
|
Speciális osztálysablonok (STL) |
<bitset>, <tuple> |
|
Dátum- és időkezelés |
<ctime> , <chrono> |
|
Sztring könyvtár | |
|
Sztring osztályok |
<string> |
|
Nullavégű karakterláncok kezelését segítő függvények |
<cctype>, <cwctype>, <cstring>, <cwchar>, <cstdlib>, <cuchar> |
|
Országfüggő (helyi) beállítások könyvtára | |
|
A helyi sajátosságok szabványos kezelés |
<locale> |
|
A C könyvtár helyi beállításai |
<clocale> |
|
Unicode konverziók támogatása |
<codecvt> |
|
A tárolók könyvtára (STL) | |
|
Szekvenciális tárolók (STL) |
<array>, <deque>, <list>, <vector>, <forward_list> |
|
Asszociatív tárolók (STL) |
<map>, <set> |
|
Nem rendezett asszociatív tárolók (STL) |
<unordered _map>, <unordered_set> |
|
Tároló adaptációk (STL) |
<queue>, <stack> |
|
Iterárotok (általánosított mutatók) könyvtára (STL) | |
|
Iterátorelemek, előre definiált iterátorok, adatfolyam iterátorok (STL) |
<iterator> |
|
Algoritmusok könyvtára | |
|
Adatsorkezelés, rendezés, keresés stb. (STL) |
<algorithm> |
|
A C könyvtár algoritmusai |
<cstdlib> |
|
Numerikus könyvtár | |
|
Komplex számok |
<complex> |
|
Számtömbök |
<valarray> |
|
Általánosított numerikus műveletek (STL) |
<numeric> |
|
A C könyvtár numerikus elemei |
<cmath>, <cstdlib>, <ctgmath> |
|
Fordításidejű racionális aritmetika |
<ratio> |
|
Véletlen szám előállítása |
<random> |
|
A lebegőpontos környezet kezelése |
<cfenv> |
|
Input/output könyvtár | |
|
Forward (előrevetett) deklarációk |
<iosfwd> |
|
Szabványos iostream objektumok |
<iostream> |
|
Az iostream osztályok alaposztálya |
<ios> |
|
Adatfolyam pufferek |
<streambuf> |
|
Adatformázás és manipulátorok |
<istream>, <ostream>, <iomanip> |
|
Sztring adatfolyamok |
<sstream> |
|
Fájl adatfolyamok |
<fstream>, <cstdio>, <cinttypes> |
|
Reguláris kifejezések könyvtár | |
|
Reguláris kifejezések kezelése |
<regex> |
|
Műveletek a konkurens programozáshoz | |
|
Magtípusok és -műveletek |
<atomic> |
|
Thread (programszál) könyvtár | |
|
Szálak létrehozása és vezérlése |
<thread>, <mutex>, <condition_variable>, <future> |
Az aláhúzott nevek a C++11 szabvány deklarációs állományait jelölik.
B. függelék - Függelék – C++/CLI összefoglaló táblázatok
B.1. A C++/CLI foglalt szavai
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B.2. A C++/CLI osztály és struktúra típusai
|
Kulcsszó |
Terület |
Alapelérés |
Ekvivalens |
Használat |
|---|---|---|---|---|
|
|
natív |
private |
C++ class |
érték, natív pointer vagy referencia |
|
|
natív |
public |
C++ struct |
érték, natív pointer vagy referencia |
|
|
felügyelt |
private |
C# class |
felügyelt hivatkozás |
|
|
felügyelt |
public |
C# class |
felügyelt hivatkozás |
|
|
felügyelt |
private |
C# struct |
érték |
|
|
felügyelt |
public |
C# struct |
érték |
B.3. Mutató és hivatkozás műveletek a C++/CLI-ben
|
Művelet |
Natív kód |
Felügyelt kód |
|---|---|---|
|
pointer definícióa mutatott objektum |
* |
^ |
|
referencia definíció a cím lekérdezése |
& |
% |
|
tagelérés |
-> |
-> |
|
memóriafoglalás |
new |
gcnew |
|
memória felszabadítása |
delete |
delete (hívja a Dispose-t) |
B.4. A .NET és a C++/CLI egyszerű típusok
|
.NET típus |
C++/CLI |
|---|---|
|
Char |
wchar_t |
|
Boolean |
bool |
|
Byte |
unsigned char |
|
SByte |
char |
|
Int16 |
short |
|
UInt16 |
unsigned short |
|
Int32 |
int, long |
|
UInt32 |
unsigned int, unsigned long |
|
Int64 |
long long |
|
UInt64 |
unsigned long long |
|
Double |
double |
|
Single |
float |