I. fejezet - A C++ alapjai és adatkezelése
- I.1. A C++ programok készítése
- I.2. Alaptípusok, változók és konstansok
- I.3. Alapműveletek és kifejezések
-
- I.3.1. Az operátorok csoportosítása az operandusok száma alapján
- I.3.2. Elsőbbségi és csoportosítási szabályok
- I.3.3. Matematikai kifejezések
- I.3.4. Értékadás
- I.3.5. Léptető (inkrementáló/dekrementáló) műveletek
- I.3.6. Feltételek megfogalmazása
- I.3.7. Bitműveletek
- I.3.8. A vessző operátor
- I.3.9. Típuskonverziók
- I.4. Vezérlő utasítások
- I.5. Kivételkezelés
- I.6. Mutatók, hivatkozások és a dinamikus memóriakezelés
- I.7. Tömbök és sztringek
- I.8. Felhasználói típusok
A C++ nyelven történő programfejlesztéshez szükséges ismereteket három nagy csoportba osztva tárgyaljuk. Az első csoport (I. fejezet) olyan alapelemeket, programstruktúrákat mutat be, amelyek többsége egyaránt megtalálható a C és a C++ nyelvekben. Az elmondottak begyakorlásához elegendő egyetlen main() függvényt tartalmazó programot készítenünk.
A következő (II. fejezet) fejezet az algoritmikus gondolkodásnak megfelelő, jól strukturált C és C++ programok készítését segíti a bemutatott megoldásokkal. Ebben a részben a függvényeké a főszerep.
A harmadik (III. fejezet) fejezet a napjainkban egyre inkább egyeduralkodóvá váló objektum-orientált programépítés eszközeit ismerteti. Itt az adatokat és a rajtuk elvégzendő műveleteket egyetlen egységbe kovácsoló osztályoké a főszerep.
I.1. A C++ programok készítése
Mielőtt sorra vennénk a C++ nyelv elemeit, érdemes áttekinteni a C++ programok előállításával és futtatásával kapcsolatos kérdéseket. Megismerkedünk a C++ forráskód írásakor alkalmazható néhány szabállyal, a programok felépítésével, illetve a futtatáshoz szükséges lépésekkel a Microsoft Visual C++ rendszerben.
I.1.1. Néhány fontos szabály
A szabványos C++ nyelv azon hagyományos programozási nyelvek közé tartozik, ahol a program megírása a program teljes szövegének begépelését is magában foglalja. A program szövegének (forráskódjának) beírása során figyelnünk kell néhány megkötésre:
-
A program alapelemei csak a hagyományos 7-bites ASCII kódtábla karaktereit (lásd A.1. szakasz függelék) tartalmazhatják, azonban a karakter- és szöveg konstansok, illetve a megjegyzések tetszőleges kódolású (ANSI, UTF-8, Unicode) karakterekből állhatnak. Néhány példa:
/* Értéket adunk egy egész, egy karakteres és egy szöveges (sztring) változónak (többsoros megjegyzés) */ int valtozo = 12.23; // értékadás (megjegyzés a sor végéig) char jel = 'Á'; string fejlec = "Öröm a programozás"
-
A C++ fordító megkülönbözteti a kis- és a nagybetűket a programban használt szavakban (nevekben). A nyelvet felépítő nevek nagy többsége csak kisbetűket tartalmaz.
-
Bizonyos (angol) szavakat nem használhatunk saját névként, mivel ezek a fordító által lefoglalt kulcsszavak (lásd A.2. szakasz függelék).
-
Saját nevek képzése során ügyelnünk kell arra, hogy a név betűvel (vagy aláhúzás jellel) kezdődjön, és a további pozíciókban is csak betűt, számjegyet vagy aláhúzás jelet tartalmazzon. (Megjegyezzük, hogy az aláhúzás jel használata nem ajánlott.)
-
Még egy utolsó szabály az első C++ program megírása előtt, hogy lehetőleg ne túl hosszú, azonban ún. beszédes neveket képezzünk, mint például: ElemOsszeg, mereshatar, darab, GyokKereso.
I.1.2. Az első C++ program két változatban
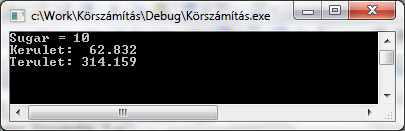
Mivel a C++ nyelv a szabványos (1995) C nyelvvel felülről kompatibilis, egyszerű programok készítése során C programozási ismeretekkel is célt érhetünk. Vegyük például egy síkbeli kör kerületének és területének számítását! Az algoritmus igen egyszerű, hiszen a sugár bekérése után csupán néhány képletet kell használnunk.
Az alábbi két megoldás alapvetően csak az input/output műveletekben különbözik egymástól. A C-stílusú esetben a printf() és a scanf() függvényeket használjuk, míg a C++ jellegű, második esetben a cout és a cin objektumokat alkalmazzuk. (A későbbi példákban az utóbbi megoldásra támaszkodunk.) A forráskódot mindkét esetben .CPP kiterjesztésű szövegfájlban kell elhelyeznünk.
A C stílusú megoldást csekély módosítással C fordítóval is lefordíthatjuk:
// Kör1.cpp
#include "cstdio"
#include "cmath"
int main()
{
const double pi = 3.14159265359;
double sugar, terulet, kerulet;
// A sugár beolvasása
printf("Sugar = ");
scanf("%lf", &sugar);
// Szamítások
kerulet = 2*sugar*pi;
terulet = pow(sugar,2)*pi;
printf("Kerulet: %7.3f\n", kerulet);
printf("Terulet: %7.3f\n", terulet);
// Várakozás az Enter lenyomására
getchar();
getchar();
return 0;
}
A C++ objektumokat alkalmazó megoldás valamivel áttekinthetőbb:
// Kör2.cpp
#include "iostream"
#include "cmath"
using namespace std;
int main()
{
const double pi = 3.14159265359;
// A sugár beolvasása
double sugar;
cout << "Sugar = ";
cin >> sugar;
// Szamítások
double kerulet = 2*sugar*pi;
double terulet = pow(sugar,2)*pi;
cout << "Kerulet: " << kerulet << endl;
cout << "Terulet: " << terulet << endl;
// Várakozás az Enter lenyomására
cin.get();
cin.get();
return 0;
}
Mindkét megoldásban használunk C++ és saját neveket (sugar, terulet, kerulet. pi). Nagyon fontos szabály, hogy minden nevet felhasználása előtt ismertté kell tenni (deklarálni kell) a C++ fordító számára. A példában a double és a const double kezdetű sorok a nevek leírásán túlmenően létre is hozzák (definiálják) a hozzájuk kapcsolódó tárolókat a memóriában. Nem találunk azonban hasonló leírásokat a printf(), scanf(), pow(), cin és cout nevekre. Ezek deklarációit a program legelején beépített (#include) állományok (rendre cstdio, cmath és iostream) tartalmazzák, A cin és cout esetén az std névtérbe zárva.
A printf() függvény segítségével formázottan jeleníthetünk meg adatokat. A cout objektumra irányítva (<<) az adatokat, a formázás sokkal bonyolultabban végezhető el, azonban itt nem kell foglalkoznunk a különböző adattípusokhoz tartozó formátumelemekkel. Ugyanez mondható el az adatbevitelre használt scanf() és cin elemekre is. További fontos különbség az alkalmazott megoldás biztonsága. A scanf() hívásakor meg kell adnunk az adatok tárolására szánt memóriaterület kezdőcímét (&), mely művelet egy sor hibát vihet a programunkba. Ezzel szemben a cin alkalmazása teljesen biztonságos.
Még egy megjegyzés a programok végén álló getchar() és cin.get() hívásokhoz kapcsolódóan. Az utolsó scanf() illetve cin hívását követően az adatbeviteli pufferben benne marad az Enter billentyűnek megfelelő adat. Mivel mindkét, karaktert olvasó függvényhívás az Enter leütése után végzi el a feldolgozást, az első hívások a pufferben maradt Entert veszik ki, és csak a második hívás várakozik egy újabb Enter-lenyomásra.
Mindkét esetben egy egész (int) típusú, main() nevű függvény tartalmazza a program érdemi részét, a függvény törzsét képző kapcsos zárójelek közé zárva. A függvények - a matematikai megfelelőjükhöz hasonlóan - rendelkeznek értékkel, melyet C++ nyelven a return utasítás után adunk meg. Még a C nyelv ősi változataiból származik az érték értelmezése, mely szerint a 0 azt jelenti, hogy minden rendben volt. Ezt a függvényértéket a main() esetében az operációs rendszer kapja meg, hisz a függvényt is ő hívja (elindítva ezzel a program futását).
I.1.3. C++ programok fordítása és futtatása
A legtöbb fejlesztőrendszerben a programkészítés alapját egy ún. projekt összeállítása adja. Ehhez először ki kell választanunk az alkalmazás típusát, majd pedig projekthez kell adnunk a forrásállományokat. A Visual C++ rendszer számos lehetősége közül a Win32 konzolalkalmazás az egyszerű, szöveges felületű C++ alkalmazások típusa. Vegyük sorra a szükséges lépéseket!
A File / New / Project… Win32 / Win32 Console Application választások után meg kell adnunk a projekt nevét:
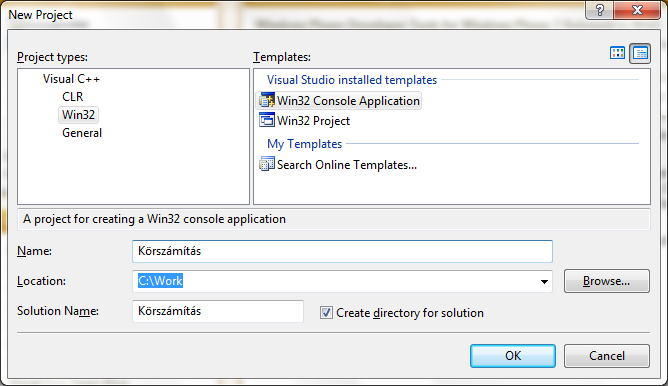
Az OK gomb megnyomása után elindul a Konzolalkalmazás varázsló, melynek beállításaival egy üres projektet készítünk:
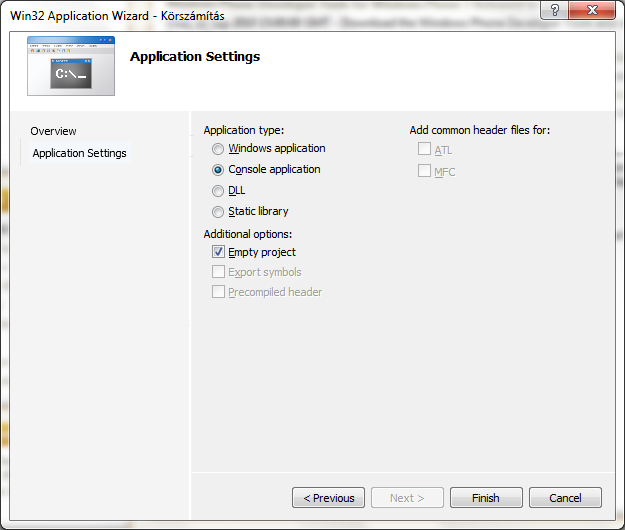
A Finish gomb megnyomását követően megjelenik a megoldás ablaka (Solution Explorer), ahol a Source Files elemre kattintva az egér jobb gombjával, új forrásállomány adhatunk a projekthez ( Add / New Item… ).
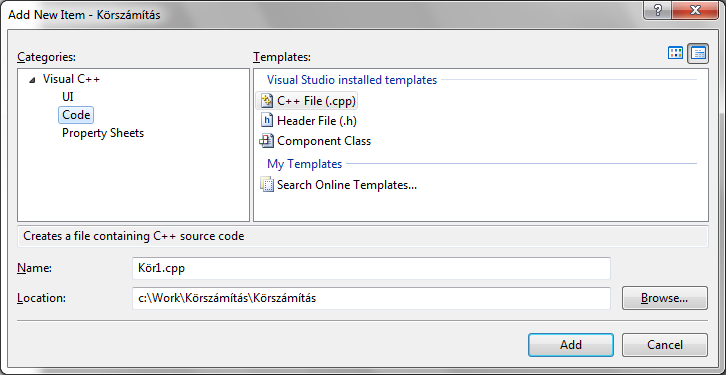
A program szövegének beírása után a fordításhoz a Build / Build Solution vagy a Build / Rebuild Solution menüpontokat használhatjuk. Sikeres fordítás esetén (Körszámítás - 0 error(s), 0 warning(s)) a Debug / Start Debugging (F5) vagy a Debug / Start Without Debugging (Ctrl+F5)menüválasztással indíthatjuk a programot.
A Build / Configuration Manager... menüválasztás hatására megjelenő párbeszédablakban megadhatjuk, hogy nyomon követhető ( Debug ) vagy pedig végleges ( Release ) változatot kívánunk fordítani. (Ez a választás meghatározza a keletkező futtatható állomány tartalmát, illetve a helyét a lemezen.)
Bármelyik Build (felépítés) választásakor a fordítás valójában több lépésben megy végbe. Ez egyes lépéseket a következő ábrán (I.5. ábra) követhetjük nyomon.
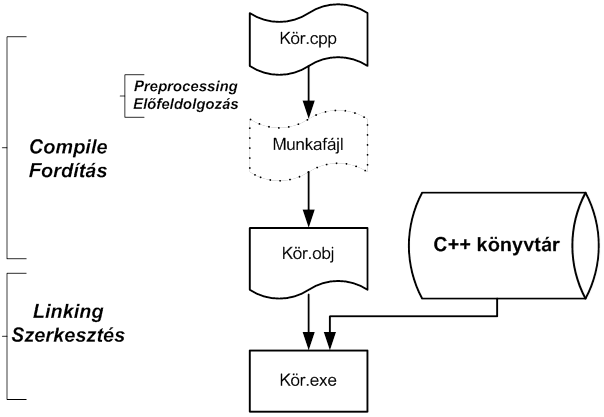
Az előfeldolgozó értelmezi a kettőskereszttel (#) kezdődő sorokat, melynek eredményeként keletkezik a C++ nyelvű forráskód. Ezt a kódot a C++ fordító egy olyan tárgykóddá fordítja, amelyből hiányzik a könyvtári elemeket megvalósító gépi kód. Utolsó lépésben a szerkesztő pótolja ezt a hiányt, és futtaható alkalmazássá alakítja a már teljes gépi (natív) kódot.
Megjegyezzük, hogy több forrásfájlt (modult) tartalmazó projekt esetén a fordítást modulonként végzi az előfeldolgozó és a C++ fordító, majd az így keletkező tárgymodulokat a szerkesztő építi egyetlen futtatható állománnyá.
A futtatást követően még el kell mentenünk az elkészült programot, hogy a későbbiekben ismét tudjunk vele dolgozni. A sokféle megoldás közül a következő bevált lépéssor lehet segítségünkre: először minden fájlt lemezre mentünk ( File / SaveAll ), majd pedig lezárjuk a projektet a megoldással együtt. ( File / Close Solution ). (A megoldás (solution) egymással összefüggő projektek halmazát jelöli, melyeket szüksége esetén egyetlen lépésben újrafordíthatunk.)
Végezetül nézzük meg a projekt fordításakor keletkező könyvtárstruktúrát a merevlemezen!
C:\Work\Körszámítás\Körszámítás.sln C:\Work\Körszámítás\Körszámítás.ncb C:\Work\Körszámítás\Debug\Körszámítás.exe C:\Work\Körszámítás\Release\Körszámítás.exe C:\Work\Körszámítás\Körszámítás\Körszámítás.vcproj C:\Work\Körszámítás\Körszámítás\Kör1.cpp C:\Work\Körszámítás\Körszámítás\Debug\Kör1.obj C:\Work\Körszámítás\Körszámítás\Release\ Kör1.obj
A magasabban elhelyezkedő Debug illetve Release könyvtárak tartalmazzák a kész futtatható alkalmazást, míg a mélyebben fekvő, azonos nevű könyvtárakban munkafájlokat találunk. Ez a négy mappa törölhető, hisz fordításkor ismét létrejönnek. Ugyancsak ajánlott eltávolítani a fejlesztői környezet intellisense szolgáltatásait segítő Körszámítás.ncb fájlt, melynek mérete igen nagyra nőhet. A megoldás (projekt) ismételt megnyitását a Körszámítás.sln állománnyal kezdeményezhetjük ( File / Open / Project / Solution ).
I.1.4. A C++ programok felépítése
Mint ahogy az előző részben láttuk, minden C++ nyelven megírt program egy vagy több forrásfájlban (fordítási egységben, modulban) helyezkedik el, melyek kiterjesztése .CPP. A C++ modulok önállóan fordíthatók tárgykóddá.
A programhoz általában ún. deklarációs (include, header, fej-) állományok is tartoznak, melyeket az #include előfordító utasítás segítségével építünk be a forrásfájlokba. A deklarációs állományok önállóan nem fordíthatók, azonban a legtöbb fejlesztői környezet támogatja azok előfordítását (precompile), meggyorsítva ezzel a C++ modulok feldolgozását.
A C++ modulok felépítése alapvetően követi a C nyelvű programokét. A program kódja - a procedurális programozás elvének megfelelően - függvényekben helyezkedik el. Az adatok (deklarciók/definíciók) a függvényeken kívül (globális, fájlszinten), illetve a függvényeken belül (lokális szinten) egyaránt elhelyezkedhetnek. Az előbbieket külső (extern), míg az utóbbiakat automatikus (auto) tárolási osztályba sorolja a fordító. Az elmondottakat jól szemlélteti az alábbi példaprogram:
// C++ preprocesszor direktívák
#include <iostream>
#define MAX 2012
// a szabványos könyvtár neveinek eléréséhez
using namespace std;
// globális deklarációk és definíciók
double fv1(int, long); // függvény prototípusa
const double pi = 3.14159265; // definíció
// a main() függvény
int main()
{
/* lokális deklarációk és definíciók
utasítások */
return 0; // kilépés a programból
}
// függvénydefiníció
double fv1(int a, long b)
{
/* lokális deklarációk és definíciók
utasítások */
return a+b; // vissztérés a függvényből
}
C++ nyelven az objektum-orientált (OO) megközelítést is alkalmazhatjuk a programok készítése során. Ennek az elvnek megfelelően a programunk alapegysége a függvényeket és adatdefiníciókat összefogó osztály (class) (részletesebben lásd a III. fejezet fejezetet). Ebben az esetben is a main() függvény definiálja a programunk belépési pontját. Az osztályokat általában a globális deklarációk között helyezzük el, akár közvetlenül a C++ modulban, vagy akár egy deklarációs állomány beépítésével. Az osztályban elhelyezett ’’tudást” az osztály példányain (változóin) keresztül érjük el.
Példaként tekintsük a körszámítás feladat objektum-orientált eszközökkel való megfogalmazását!
/// Kör3.cpp
#include "iostream"
#include "cmath"
using namespace std;
// Az osztály definíciója
class Kor
{
double sugar;
static const double pi;
public:
Kor(double s) { sugar = s; }
double Kerulet() { return 2*sugar*pi; }
double Terulet() { return pow(sugar,2)*pi; }
};
const double Kor::pi = 3.14159265359;
int main()
{
// A sugár beolvasása
double sugar;
cout << "Sugar = ";
cin >> sugar;
// A Kor objektumának létrehozása, és használata
Kor kor(sugar);
cout << "Kerulet: " << kor.Kerulet() << endl;
cout << "Terulet: " << kor.Terulet() << endl;
// Várakozás az Enter lenyomására
cin.get();
cin.get();
return 0;
}
I.2. Alaptípusok, változók és konstansok
A programozás során a legkülönbözőbb tevékenységeinket igyekszünk érthetővé tenni a számítógép számára, azzal a céllal, hogy a gép azok elvégzését, illetve, hogy elvégezze azokat helyettünk. Munkavégzés közben adatokat kapunk, amelyeket általában elteszünk, hogy később elővéve feldolgozzuk azokat, és információt nyerjünk belőlük. Adataink igen változatosak, de legtöbbjük számok, szövegek formájában vannak jelen az életünkben.
Ebben a fejezetben az adatok C++ nyelven történő leírásával és tárolásával foglalkozunk. Ugyancsak megismerkedünk az adatok megszerzésének (bevitelének), illetve megjelenítésének módszereivel.
Az adatok tárolása – a Neumann elv alapján – egységes formában történik a számítógép memóriájában, ezért a C++ programban kell gondoskodnunk az adat milyenségének, típusának leírásáról.
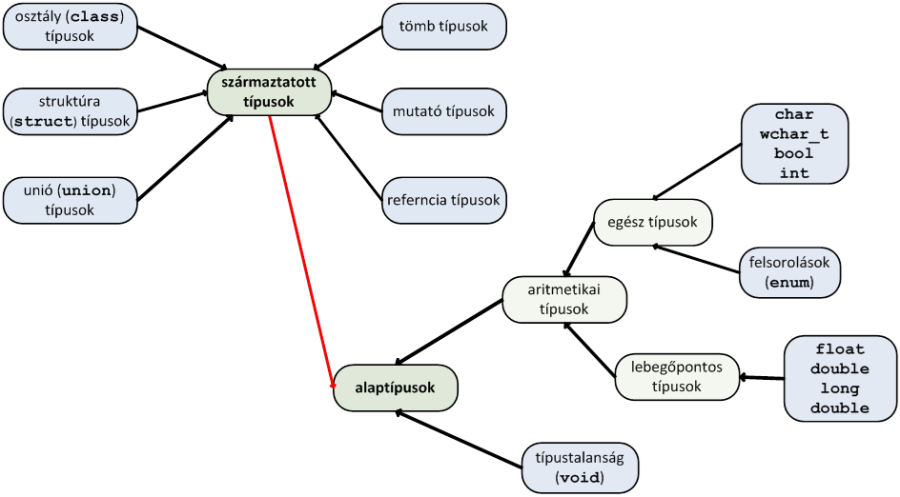
I.2.1. A C++ adattípusok csoportosítása
Az adattípus meghatározza a tárolásra használt memóriaterület (változó) bitjeinek darabszámát és értelmezését. Az adattípus hatással van az adatok feldolgozására is, hisz a C++ nyelv erősen típusos, így nagyon sok mindent ellenőriz a fordítóprogram.
A C++ adattípusait (röviden típusait) sokféle módon csoportosíthatjuk. Szerepeljen itt most a Microsoft VC++ nyelvben is alkalmazott felosztás (I.6. ábra)! E szerint vannak alaptípusaink, amelyek egy-egy érték (egész szám, karakter, valós szám) tárolására képesek. Vannak azonban származtatott típusaink is, amelyek valamilyen módon az alaptípusokra épülve bonyolultabb, akár több értéket is tároló adatstruktúrák kialakítását teszik lehetővé.
I.2.1.1. Típusmódosítók
C++ nyelvben az egész alaptípusok jelentését típusmódosítókkal pontosíthatjuk. A signed/unsigned módosítópárral a tárolt bitek előjeles vagy előjel nélküli értelmezését írhatjuk elő. A short/long párral pedig a tárolási méretet rögzíthetjük 16 illetve 32 bitre. A legtöbb C++ fordító támogatja a 64-bites tárolást előíró long long módosító használatát, ezért könyvünkben ezt is tárgyaljuk. A típusmódosítók önmagukban típuselőírásként is használhatók. Az alábbiakban összefoglaltuk a lehetséges típuselőírásokat. Az előírások soronként azonos típusokat jelölnek.
|
char |
signed char |
||
|
short int |
short |
signed short int |
signed sh o rt |
|
int |
signed |
signed int |
|
|
long int |
long |
signed long int |
signed long |
|
long long int |
long long |
signed long long int |
signed long long |
|
unsigned char |
|||
|
unsigned short int |
unsigned short |
||
|
unsigned int |
unsigned |
||
|
unsigned long int |
unsigned long |
||
|
unsigned long long int |
unsigned long long |
A típusmódosítókkal ellátott aritmetikai típusok memóriaigényét és a tárolt adatok értéktartományát az A.4. szakasz függelékben foglaltuk össze.
Az alaptípusok részletes bemutatása jelen alfejezet témája, míg a származtatott típusokat az I. fejezet fejezet további részeiben tárgyaljuk.
I.2.2. Változók definiálása
Az adatok memóriában való tárolása és elérése alapvető fontosságú minden C++ program számára. Ezért először a névvel ellátott memóriaterületekkel, a változókkal kezdjük az ismerkedést. A változókat az estek többségében definiáljuk, vagyis megadjuk a típusukat (deklaráljuk), és egyúttal helyet is „foglalunk” számukra a memóriában. (A helyfoglalást egyelőre a fordítóra bízzuk.)
Egy változó teljes definíciós sora első látásra igen összetett, azonban a mindennapos használat sokkal egyszerűbb formában történik.
〈tárolási osztály〉 〈típusminősítő〉 〈típusmódosító ... 〉 típus változónév 〈= kezdőérték〉 〈, … 〉;
〈tárolási osztály〉 〈típusminősítő〉 〈típusmódosító ... 〉 típus változónév 〈(kezdőérték)〉 〈, … 〉;
(Az általánosított formában a 〈 〉 jelek az opcionálisan megadható részeket jelölik, míg a három pont az előző definíciós elem ismételhetőségére utal.)
A C++ nyelv tárolási osztályai - auto, register, static, extern – meghatározzák a változók élettartamát és láthatóságát. Egyelőre nem adunk meg tárolási osztályt, így a C++ nyelv alapértelmezése érvényesül. E szerint minden függvényeken kívül definiált változó extern (globális), míg a függvényeken belül megadott változók auto (lokális) tárolási osztállyal rendelkezik. Az extern változók a program indításakor jönnek létre, és a program végéig léteznek, és eközben bárhonnan elérhetők. Ezzel szemben az auto változók csak a definíciójukat tartalmazó függvénybe való belépéskor születnek meg, és függvényből való kilépéskor törlődnek. Elérhetőségük is függvényre korlátozódik.
A típusminősítők alkalmazásával a változókhoz további információkat rendelhetünk.
-
A const kulcsszóval definiált változó értéke nem változtatható meg (csak olvasható - konstans).
-
A volatile típusminősítővel pedig azt jelezzük, hogy a változó értékét a programunktól független kód (például egy másik futó folyamat vagy szál) is megváltoztathatja. A volatile közli a fordítóval, hogy nem tud mindent, ami az adott változóval történhet. (Ezért például a fordító minden egyes, ilyen tulajdonságú változóra történő hivatkozáskor a memóriából veszi fel a változó értéket.)
int const const double volatile char float volatile const volatile bool
I.2.2.1. Változók kezdőértéke
A változódefiníciót a kezdő (kiindulási) érték megadása zárja. A kezdőértéket egyaránt megadhatjuk egy egyenlőségjel után, vagy pedig kerek zárójelek között:
using namespace std;
int osszeg, szorzat(1);
int main()
{
int a, b=2012, c(2004);
double d=12.23, e(b);
}
A fenti példában két változó (osszeg és a) esetén nem szerepel kezdőérték, ami általában programhibához vezet. Ennek ellenére az osszeg változó 0 kiindulási értékkel rendelkezik, mivel a globális változókat mindig inicializálja (nullázza) a fordító. A lokális a esetén azonban más a helyzet, mivel értékét a változóhoz rendelt memória aktuális tartalma adja, ami pedig bármi lehet! Ilyen esetekben a felhasználás előtti értékadással állíthatjuk be a változó értékét. Értékadás során az egyenlőségjel bal oldalán álló változó felveszi a jobb oldalon szereplő kifejezés értékét:
a = 1004;
C++ nyelven a kezdőértéket tetszőleges fordítás, illetve futás közben meghatározható kifejezéssel is megadhatjuk:
#include <cmath>
#include <cstdlib>
using namespace std;
double pi = 4.0*atan(1.0); // π
int veleten(rand() % 1000);
int main()
{
double ahatar = sin(pi/2);
}
Felhívjuk a figyelmet arra, hogy a definíciós és az értékadó utasításokat egyaránt pontosvessző zárja.
I.2.3. Az alaptípusok áttekintése
Az alaptípusokra úgy tekinthetünk, mint az emberi írott művekben a számjegyekre és a betűkre. Segítségükkel egy matematikai értékezés és a Micimackó egyaránt előállítható. Az alábbi áttekintésben az egész jellegű típusokat kisebb csoportokra osztjuk.
I.2.3.1. Karakter típusok
A char típus kettős szereppel rendelkezik. Egyrészről lehetővé teszi az ASCII (American Standard Code for Information Interchange) kódtábla (A.1. szakasz függelék) karaktereinek tárolását, másrészről pedig egybájtos előjeles egészként is használható.
char abetu = 'A'; cout << abetu << endl; char valasz; cout << "Igen vagy Nem? "; cin>>valasz; // vagy valasz = cin.get();
A char típus kettős voltát jól mutatják a konstans értékek (literálok) megadási lehetőségei. Egyetlen karaktert egyaránt megadhatunk egyszeres idézőjelek (aposztrófok) között, illetve az egész értékű kódjával. Egész értékek esetén a decimális forma mellet - nullával kezdve - az oktális, illetve - 0x előtaggal - a hexadecimális alak is használható. Példaként tekintsük a nagy C betű megadását!
’C’ 67 0103 0x43
Bizonyos szabványos vezérlő és speciális karakterek megadására az ún. escape szekvenciákat használjuk. Az escape szekvenciában a fordított osztásjel (backslash - \) karaktert speciális karakterek, illetve számok követik, mint ahogy az A.3. szakasz függelék táblázatában látható: ’\n’, ’\t’, ’\’’, ’\”’, ’\\’.
Amennyiben a 8-bites ANSI kódtábla karaktereivel, illetve bájtos egész értékekkel kívánunk dolgozni, az unsigned char típust ajánlott használni.
Az Unicode kódtábla karaktereinek feldolgozásához a kétbájtos wchar_t típussal hozunk létre változót, a konstans karakterértékek előtt pedig a nagy L betűt szerepeltetjük. (Ezek írására olvasására az std névtér wcout és wcin objektumok szolgálnak.)
wchar_t uch1 = L'\u221E'; wchar_t uch2 = L'K'; wcout<<uch1; wcin>>uch1; uch1 = wcin.get();
Felhívjuk a figyelmet arra, hogy nem szabad összekeverni az aposztrófot (’) az idézőjellel ("). Kettős idézőjelek között szöveg konstansokat (sztring literálokat) adunk meg a programban.
"Ez egy ANSI sztring konstans!"
illetve
L"Ez egy Unicode sztring konstans!"
I.2.3.2. A logikai bool típus
A bool típusú változók két értéket vehetnek fel. A false (0) a logikai hamis, míg a true (1) a logikai igaz értéknek felel meg. Input/Output (I/O) műveletekben a logikai értékeket a 0 és az 1 egész számok reprezentálják.
bool start=true, vege(false); cout << start; cin >>vege;
Ezt az alapértelmezés szerinti működést felülbírálhatjuk a boolalpha és a noboolalpha I/O manipulátorok segítségével:
bool start=true, vege(false); cout << boolalpha << start << noboolalpha; // true cout << start; // 1 cin >> boolalpha>> vege; // false cout << vege; // 0
I.2.3.3. Az egész típusok
Valószínűleg a C++ nyelv leggyakrabban használt alaptípusa az int a hozzá tartozó típusmódosítókkal. Amikor a programban megadunk egy egész értéket, akkor a fordító automatikusan az int típust próbálja hozzárendelni. Amennyiben az érték kívül esik az int típus értékkészletén, akkor a fordító valamelyik nagyobb értékkészletű egész típust alkalmazza, illetve hibajelzést ad túl nagy konstans esetén.
A konstans egész értékek típusát U és L utótagokkal mi is meghatározhatjuk. Az U betű az unsigned, míg az L a long típusmódosítók kezdőbetűje:
|
2012 |
int |
|
2012U |
unsigned int |
|
2012L |
long int |
|
2012UL |
unsigned long int |
|
2012LL |
long long int |
|
2012ULL |
unsigned long long int |
Természetesen az egész értékeket a decimális (2012) forma mellett oktális (03724) és hexadecimális (0x7DC) számrendszerben egyaránt megadhatjuk. Ezeket a számrendszereket az I/O műveletekben is előírhatjuk a „kapcsoló” manipulátorok ( dec , oct , hex ) felhasználásával, melyek hatása a következő manipulátorig tart:
#include <iostream>
using namespace std;
int main()
{
int x=20121004;
cout << hex << x << endl;
cout << oct << x << endl;
cout << dec << x << endl;
cin>> hex >> x;
}
Adatbevitel esetén a számrendszert jelző előtagok használata nem kötelező. Más manipulátorok egyszerű formázási lehetőséget biztosítanak. A setw () paraméteres manipulátorral a megjelenítéshez használt mező szélességét állíthatjuk be, melyen belül balra ( left ) és az alapértelmezés szerint jobbra ( right ) is igazíthatunk. A setw () manipulátor hatása csak a következő adatelemre terjed ki, míg a kiigazítás manipulátorainak hatása a következő kiigazítás manipulátorig tart.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
unsigned int szam = 123456;
cout << '|' << setw(10) << szam << '|' << endl;
cout << '|' << right << setw(10) << szam << '|' << endl;
cout << '|' << left << setw(10) << szam << '|' << endl;
cout << '|' << setw(10) << szam << '|' << endl;
}
A program futásának eredménye jól tükrözi a manipulátorok hatását:
| 123456| | 123456| |123456 | |123456 |
I.2.3.4. A lebegőpontos típusok
Matematikai és műszaki számításokhoz az egészek mellett elengedhetetlen a törtrészeket is tartalmazó számok használata. Mivel ezekben a tizedespont helye nem rögzített, az ilyen számok tárolását segítő típusok a lebegőpontos típusok: float, double, long double. Az egyes típusok a szükséges memória mérete, a számok nagyságrendje és a pontos jegyek számában különböznek egymástól (lásd A.4. szakasz függelék). (A Visual C++ a szabvány ajánlásától eltérően double típusként kezeli a long double típust.)
Már az ismerkedés legelején le kell szögeznünk, hogy a lebegőpontos típusok alkalmazásával le kell mondanunk a törtrészek pontos ábrázolásáról. Ennek oka, hogy a számok kitevős alakban (mantissza, kitevő), méghozzá 2-es számrendszerben tárolódnak.
double d =0.01; float f = d; cout<<setprecision(12)<<d*d<< endl; // 0.0001 cout<<setprecision(12)<<f*f<< endl; // 9.99999974738e-005
Egyetlen garantáltan egzakt érték a 0, tehát a lebegőpontos változók nullázása után értékük: 0.0.
A lebegőpontos konstansokat kétféleképpen is megadhatjuk. Kisebb számok esetén általában a tizedes tört alakot használjuk, ahol a törtrészt tizedespont választja el az egész résztől: 3.141592653, 100., 3.0. Nagyobb számok esetén a matematikából ismert kitevős forma számítógépes változatát alkalmazzuk, ahol az e , E betűk 10 hatványát jelölik: 12.34E-4, 1e6.
A lebegőpontos konstans értékek alapértelmezés szerint double típusúak. Az F utótaggal float típusú, míg L utótaggal long double típusú értékeket adhatunk meg: 12.3F, 1.2345E-10L. (Gyakori programhiba, hogy szándékaink szerint lebegőpontos konstans érték megadásakor sem tizedespontot, sem pedig kitevőt nem adunk meg, így a konstans egész típusú lesz.)
A lebegőpontos változók értékének megjelenítése során a már megismert mezőszélesség ( setw ()) mellet a tizedes jegyek számát is megadhatjuk – setprecision () (lásd A.10. szakasz függelék). Amennyiben az érték nem jeleníthető meg a formátum alapján, az alapértelmezés szerinti megjelenítés érvényesül. A tizedes tört és a kitevős forma közül választhatunk a fixed és scientific manipulátorokkal.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double a = 2E2, b=12.345, c=1.;
cout << fixed;
cout << setw(10)<< setprecision(4) << a << endl;
cout << setw(10)<< setprecision(4) << b << endl;
cout << setw(10)<< setprecision(4) << c << endl;
}
A program futásának eredménye:
200.0000
12.3450
1.0000
Mielőtt továbblépnénk érdemes elidőzni a C++ nyelv aritmetikai típusai között végzett automatikus típus-átalakításnál. Könnyen belátható, hogy egy kisebb értékkészletű típus bármely nagyobb értékkészletű típussá adatvesztés nélkül átalakítható. Fordított helyzetben azonban általában adatvesztéssel jár az átalakítás, amire nem figyelmeztet a futtató rendszer, és a nagyobb szám egy része megjelenhet a „kisebb” típusú változóban.
short int s;
double d;
float f;
unsigned char b;
s = 0x1234;
b = s; // 0x34 ↯
// ------------------------
f = 1234567.0F;
b = f; // 135 ↯
s = f; // -10617 ↯
// ------------------------
d = 123456789012345.0;
b = d; // 0 ↯
s = d; // 0 ↯
f = d; // f=1.23457e+014 - pontosságvesztés ↯
I.2.3.5. Az enum típus
A programokban gyakran használunk olyan egész típusú konstans értékeket, amelyek logikailag összetartoznak. A programunk olvashatóságát nagyban növeli, ha ezeket az értékeket nevekkel helyettesítjük. Ennek módja egy új típus a felsorolás (enum) definiálása az értékkészletének megadásával:
enum 〈típusazonosító〉 { felsorolás };
A típusazonosító elhagyásával a típus nem jön létre, csak a konstansok születnek meg. Példaként tekintsük a hét munkanapjait tartalmazó felsorolást!
enum munkanapok {hetfo, kedd, szerda, csutorok, pentek};
A felsorolásban szereplő nevek mindegyike egy-egy egész számot képvisel. Alapértelmezés szerint az első elem (hetfo) értéke 0, a rákövetkező elemé (kedd) pedig 1, és így tovább (a pentek értéke 4 lesz).
A felsorolásban az elemekhez közvetlenül értéket is rendelhetünk. Ilyenkor az automatikus növelés a megadott értéktől folytatódik. Az sem okoz gondot, ha azonos értékek ismétlődnek, vagy ha negatív értéket adunk értékül. Arra azonban ügyelnünk kell, hogy egy adott láthatósági körön (névtéren) belül nem szerepelhet két azonos nevű enum elem a definíciókban.
enum konzolszinek {fekete,kek,zold,piros=4,sarga=14,feher};
Az konzolszinek felsorolásban a feher elem értéke 15.
A közvetlen értékbeállítást nem tartalmazó felsorolásban az elemek számát megkaphatjuk egy további elem megadásával:
enum halmazallapot { jeg, viz, goz, allapotszam};
Az allapotszam elem értéke az állapotok száma, vagyis 3.
Az alábbi példában az enum típus és az enum konstansok felhasználását szemléltetjük:
#include <iostream>
using namespace std;
int main()
{
enum kartya { treff, karo, kor, pikk };
enum kartya lapszin1 = karo;
kartya lapszin2 = treff;
cout << lapszin2 << endl;
int szin = treff;
cin >> szin;
lapszin1 = kartya(szin);
}
Felsorolás típusú változót a C nyelv és a C++ nyelv szabályai szerint egyaránt definiálhatunk. A C nyelv szerint az enum kulcsszó és a típusazonosító együtt alkotják az enum típust. A C++ nyelvben a típusazonosító önállóan is képviseli az enum típust.
Felsorolás típusú változó vagy felsorolási konstans kiírásakor az elemnek megfelelő egész érték jelenik meg. Beolvasással azonban egészen más a helyzet. Mivel az enum nem előre definiált típusa a C++ nyelvnek - ellentétben a fent ismertetett típusokkal -, a cin nem ismeri azt. A beolvasás – a példában látható módon – egy int típusú változó felhasználásával megoldható. Itt azonban gondot jelent a C++ nyelv típusossága, ami bizonyos átalakításokat csak akkor végez el, ha erre külön „megkérjük” a típus-átalakítás (cast) műveletének kijelölésével: típusnév(érték). (A megfelelő értéke ellenőrzéséről magunknak kell gondoskodni, a C++ nem foglalkozik vele.)
I.2.4. A sizeof művelet
A C++ nyelv tartalmaz egy olyan fordítás idején kiértékelésre kerülő operátort, amely megadja tetszőleges típus, illetve változó és kifejezés típusának bájtban kifejezett méretét.
sizeof (típusnév)
sizeof változó/kifejezés
sizeof (változó/kifejezés)
Ebből például következtethetünk a megadott kifejezés eredményének típusára:
cout << sizeof('A' + 'B') <<endl; // 4 - int
cout << sizeof(10 + 5) << endl; // 4 - int
cout << sizeof(10 + 5.0) << endl; // 8 - double
cout << sizeof(10 + 5.0F) << endl; // 4 - float
I.2.5. Szinonim típusnevek készítése
A változók definiálása során alkalmazott típusok - a típusminősítők és a típusmódosítók jóvoltából - általában több kulcsszóból épülnek fel. Az ilyen deklarációs utasítások nehezen olvashatók, sőt nem egy esetben megtévesztőek.
volatile unsigned short int jel;
Valójában előjel nélküli 16-bites egészeket szeretnénk tárolni a jel változóban. A volatile előírás csak a fordító számára közöl kiegészítő információt, a programozás során nincs vele dolgunk. A typedef deklaráció segítségével a fenti definíciót olvashatóbbá tehetjük:
typedef volatile unsigned short int uint16;
A fenti utasítás hatására létrejön az uint16 típusnév, így a jel változó definíciója:
uint16 jel;
A typedef-et felsorolások esetén is haszonnal alkalmazhatjuk:
typedef enum {hamis = -1, ismeretlen, igaz} bool3;
bool3 start = ismeretlen;
A típusnevek készítése mindig eredményes lesz, ha betartjuk a következő tapasztalati szabályt:
-
Írjunk fel egy kezdőérték nélküli változódefiníciót, ahol az a típus szerepel, amelyhez szinonim nevet kívánunk kapcsolni!
-
Írjuk a definíció elé a typedef kulcsszót, ami által a megadott név nem változót, hanem típust fog jelölni!
Különösen hasznos a typedef használata összetett típusok esetén, ahol a típusdefiníció felírása nem mindig egyszerű.
Végezetül nézzünk néhány gyakran használt szinonim típusnevet!
typedef unsigned char byte, uint8;
typedef unsigned short word, uint16;
typedef long long int int64;
I.2.6. Konstansok a C++ nyelvben
A programunk olvashatóságát nagyban növeli, ha a konstans értékek helyett neveket használunk. A C nyelv hagyományait követve C++-ban több lehetőség közül is választhatunk.
Kezdjük az áttekintést a #define konstansokkal (makrókkal), melyeket a C++ nyelvben javasolt elkerülni! A #define előfeldolgozó utasítás után két szöveg szerepel, szóközzel elválasztva. A preprocesszor végigmegy a C++ forráskódon, és felcseréli a definiált első szót a másodikkal. Felhívjuk a figyelmet arra, hogy az előfordító által használt neveket csupa nagybetűvel szokás írni, továbbá, hogy az előfordító utasításokat nem kell pontosvesszővel zárni.
#define ON 1
#define OFF 0
#define PI 3.14159265
int main()
{
int kapcsolo = ON;
double rad90 = 90*PI/180;
kapcsolo = OFF;
}
Az előfeldolgozás után az alábbi C++ programot kapja meg a fordító:
int main()
{
int kapcsolo = 1;
double rad90 = 90*3.14159265/180;
kapcsolo = 0;
}
E megoldás nagy előnye és egyben hátránya is a típusnélküliség.
Az C++ nyelv által támogatott konstans megoldások a const típusminősítőre és az enum típusra épülnek. A const kulcsszóval tetszőleges, kezdőértékkel ellátott változót konstanssá alakíthatunk. A C++ fordító semmilyen körülmények között sem engedi az így létrehozott konstansok értékének megváltoztatását. A fenti példaprogram átírt változata:
const int on = 1;
const int off = 0;
const double pi = 3.14159265;
int main()
{
int kapcsolo = on;
double rad90 = 90*pi/180;
kapcsolo = off;
}
A harmadik lehetőség, az enum típus használata, ami azonban csak egész (int) típusú konstansok esetén alkalmazható. Az előző példa kapcsoló konstansait felsorolásban állítjuk elő:
enum kibe { off, on };
int kapcsolo = on;
kapcsolo = off;
Az enum és a const konstansok igazi konstansok, hisz nem tárolja őket a memóriában a fordító. Míg a #define konstansok a definiálás helyétől a fájl végéig fejtik hatásukat, addig az enum és a const konstansokra a szokásos C++ láthatósági és élettartam szabályok érvényesek.
I.3. Alapműveletek és kifejezések
Az adatok tárolásának megoldását követően továbbléphetünk az információk megszerzésének irányába. Az információ általában egy adatfeldolgozási folyamat eredményeként jön létre, amely folyamat a C++ nyelven utasítások sorozatának végrehajtását jelenti. A legegyszerűbb adatfeldolgozási mód, amikor az adatainkon, mint operandusokon különböző (aritmetikai, logikai, bitenkénti stb.) műveleteket végzünk. Ennek eredménye egy újabb adat, vagy maga a számunkra szükséges információ. (Az adatot a célirányossága teszi információvá.) A műveleti jelekkel (operátorokkal) összekapcsolt operandusokat kifejezésnek nevezzük. C++ nyelvben a legnépesebb utasításcsoportot a pontosvesszővel lezárt kifejezések (értékadás, függvényhívás, …) alkotják
Egy kifejezés kiértékelése általában valamilyen érték kiszámításához vezet, függvényhívást idéz elő, vagy mellékhatást (side effect) okoz. Az esetek többségében a fenti három hatás valamilyen kombinációja megy végbe a kifejezések feldolgozása (kiértékelése) során.
A műveletek az operandusokon fejtik ki hatásukat. Azokat az operandusokat, amelyek nem igényelnek további kiértékelést elsődleges (primary) kifejezéseknek nevezzük. Ilyenek az azonosítók, a konstans értékek és a zárójelben megadott kifejezések.
I.3.1. Az operátorok csoportosítása az operandusok száma alapján
Az operátorokat több szempont alapján lehet csoportosítani. A csoportosítást elvégezhetjük az operandusok száma szerint. Az egyoperandusú (unary) operátorok esetén a kifejezés általános alakja:
op operandus vagy operandus op
Az első esetben, amikor az operátor (op) megelőzi az operandust előrevetett (prefixes), míg a második esetben hátravetett (postfixes) alakról beszélünk:
|
|
előjelváltás, |
|
|
n értékének növelése (postfix), |
|
|
n értékének csökkentése (prefix), |
|
|
n értékének valóssá alakítása. |
A műveletek többsége két operandussal rendelkezik - ezek a kétoperandusú (binary) operátorok: operandus1 op operandus2
Ebben a csoportban a hagyományos aritmetikai és relációs műveletek mellett a bitműveleteket is helyet kapnak:
|
|
n alsó bájtjának kinyerése, |
|
|
n + 2 kiszámítása, |
|
|
n bitjeinek eltolása 3 pozícióval balra, |
|
|
n értékének növelése 5-tel. |
A C++ nyelv egy háromoperandusú művelettel is rendelkezik, ez a feltételes operátor:
operandus1 ? operandus2 : operandus3
I.3.2. Elsőbbségi és csoportosítási szabályok
Akárcsak a matematikában, a kifejezések kiértékelése az elsőbbségi (precedencia) szabályok szerint történik. Ezek a szabályok meghatározzák a kifejezésekben szereplő, különböző elsőbbséggel rendelkező műveletek végrehajtási sorrendjét. Az azonos elsőbbségi operátorok esetén a balról-jobbra, illetve a jobbról-balra csoportosítás (asszociativitás) ad útmutatást. A C++ nyelv műveleteit az A.7. szakasz függelék tartalmazza, az elsőbbségek csökkenő sorrendjében. A táblázat jobb oldalán az azonos precedenciájú műveletek végrehajtási irányát is feltüntettük.
I.3.2.1. A precedencia-szabály
Ha egy kifejezésben különböző elsőbbségű műveletek szerepelnek, akkor mindig a magasabb precedenciával rendelkező operátort tartalmazó részkifejezés értékelődik ki először.
A kiértékelés sorrendjét a matematikából ismert zárójelek segítségével megerősíthetjük vagy megváltoztathatjuk. C++ nyelvben csak a kerek zárójel () használható, bármilyen mélységű zárójelezést is készítünk. Tapasztalati szabályként elmondható, ha egy kifejezésben két vagy kettőnél több különböző művelet szerepel, használjunk zárójeleket az általunk kívánt kiértékelési sorrend biztosítása érdekében. Inkább legyen eggyel több felesleges zárójelünk, mintsem egy hibás kifejezésünk.
Az a+b*c-d*e és az a+(b*c)-(d*e) kifejezések kiértékelési sorrendje megegyezik, így a kifejezések kiértékelésének lépései (* a szorzás művelete):
int a = 6, b = 5, c = 4, d = 2, e = 3; b * c ⇒ 20 d * e ⇒ 6 a + b * c ⇒ a + 20 ⇒ 26 a + b * c - d * e ⇒ 26 - 6 ⇒ 20
Az (a+b)*(c-d)*e kifejezés feldolgozásának lépései:
int a = 6, b = 5, c = 4, d = 2, e = 3; (a + b) ⇒ 11 (c - d) ⇒ 2 (a + b) * (c - d) ⇒ 11 * 2 ⇒ 22 22 * e ⇒ 22 * 3 ⇒ 66
I.3.2.2. Az asszociativitás szabály
Az asszociativitás határozza meg, hogy az adott precedenciaszinten található műveleteket balról-jobbra vagy jobbról-balra haladva kell elvégezni.
Például, az értékadó utasítások csoportjában a kiértékelés jobbról-balra halad, ami lehetővé teszi, hogy több változónak egyszerre adjunk értéket:
a = b = c = 0; azonos az a = (b = (c = 0));
Amennyiben azonos precedenciájú műveletek szerepelnek egy aritmetikai kifejezésben, akkor a balról-jobbra szabály lép életbe. Az a+b*c/d*e kifejezés kiértékelése három azonos elsőbbségű művelet végrehajtásával indul. Az asszociativitás miatt a kiértékelési sorrend:
int a = 6, b = 5, c = 4, d = 2, e = 3; b * c ⇒ 20 b * c / d ⇒ 20 / d ⇒ 10 b * c / d * e ⇒ 10 * e ⇒ 30 a + b * c / d * e ⇒ a + 30 ⇒ 36
Matematikai képletre átírva jól látszik a műveletek sorrendje:
Ha a feladat az 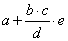 képlet programozása, akkor ezt kétféleképpen is megoldhatjuk:
képlet programozása, akkor ezt kétféleképpen is megoldhatjuk:
-
zárójelbe tesszük a nevezőt, így a szorzattal osztunk:
a+b*c/(d*e), -
a nevezőben szereplő szorzat mindkét tagjával osztunk:
a+b*c/d/e.
I.3.3. Matematikai kifejezések
A legegyszerűbb programokat általában matematikai feladatok megoldásához hívjuk segítségül. A matematikai kifejezésekben az alapműveletek (C++ szóhasznával aritmetikai operátorok) mellett különböző függvényeket is használunk.
I.3.3.1. Aritmetikai operátorok
Az aritmetikai operátorok csoportja a szokásos négy alapműveleten túlmenően a maradékképzés operátorát (%) is tartalmazza. Az összeadás (+), a kivonás (-), a szorzás (*) és az osztás (/) művelete egész és lebegőpontos számok esetén egyaránt elvégezhető. Az osztás egésztípusú operandusok esetén egészosztást jelöl:
29 / 7 a kifejezés értéke (a hányados) 4
29 % 7 az kifejezés értéke (a maradék) 1
Nem nulla, egész a és b esetén mindig igaz az alábbi kifejezés:
(a / b) * b + (a % b) ⇒ a
A csoportba tartoznak az egyoperandusú mínusz (-) és plusz (+) operátorok is. A mínusz előjel a mögötte álló operandus értékét ellentétes előjelűre változtatja (negálja).
I.3.3.2. Matematikai függvények
Amennyiben a fenti alapműveleteken túlmenően további matematikai műveletekre is szükségünk van, a szabványos C++ könyvtár matematikai függvényeit kell használnunk. A függvények eléréséhez a cmath deklarációs állományt szükséges beépíteni a programunkba. A leggyakrabban használt matematikai függvényeket az A.8. szakasz függelékben foglaltuk össze. A könyvtár minden függvényt három változatban bocsát rendelkezésünkre, a három lebegőpontos típusnak (float, double, long double) megfelelően.
Példaként tekintsük a mindenki által jól ismert egyismeretlenes, másodfokú egyenlet megoldóképletét, ahol a, b és c az egyenlet együtthatói!
|
|
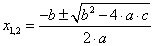
A megoldóképlet C++ programban:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
double a = 1, b = -5, c =6, x1, x2;
x1 = (-b + sqrt(b*b-4*a*c))/(2*a);
x2 = (-b - sqrt(b*b-4*a*c))/(2*a);
cout << x1 << endl;
cout << x2 << endl;
}
I.3.4. Értékadás
A változók általában az értékadás során kapnak értéket, melynek általános alakja:
változó = érték;
A C++ nyelven az értékadó műveletet (=) tartalmazó utasítás valójában egy kifejezés, amit a fordítóprogram kiértékel, és értéke a jobb oldalon megadott érték. Az értékadás operátorának mindkét oldalán szerepelhetnek kifejezések, melyek azonban alapvetően különböznek egymástól. A bal oldalon szereplő kifejezés azt a memóriaterületet jelöli ki, ahol a jobb oldalon megadott kifejezés értékét tárolni kell.
I.3.4.1. Balérték és jobbérték
A C++ nyelv külön nevet ad az értékadás két oldalán álló kifejezések értékeinek. Az egyenlőségjel bal oldalán álló kifejezésnek az értéke a balérték (lvalue), míg a jobb oldalon szereplő kifejezés értéke a jobbérték (rvalue). Tekintsünk példaként két egyszerű értékadást!
int x;
x = 12;
x = x + 11;
Az első értékadás során az x változó, mint balérték szerepel, vagyis a változó címe jelöli ki azt a tárolót, ahova a jobb oldalon megadott konstans értéket be kell másolni. A második értékadás során az x változó az értékadás mindkét oldalán megtalálható. A bal oldalon álló x ugyancsak a tárolót jelöli ki a memóriában (lvalue), míg a jobb oldalon álló x egy jobbérték kifejezésben szerepel, melynek értékét (23) a fordító határozza meg az értékadás elvégzése előtt. (Megjegyezzük, hogy a teljes kifejezés értéke is egy jobbérték, melyet semmire sem használunk.)
I.3.4.2. Mellékhatások a kiértékelésekben
Mint már említettük, minden kifejezés kiértékelésének alapvető célja a kifejezés értékének kiszámítása. Ennek ellenére bizonyos műveletek – az értékadás, a függvényhívás és a később bemutatásra kerülő léptetés (++, --) – feldolgozása során a kifejezés értékének megjelenése mellett az operandusok értéke is megváltozhat. Ezt a jelenséget mellékhatásnak (side effect) hívjuk.
A mellékhatások kiértékelésének sorrendjét nem határozza meg a C++ szabvány, ezért javasolt minden olyan megoldás elkerülése, ahol a kifejezés eredménye függ a mellékhatások kiértékelésének sorrendjétől, például:
a[i] = i++; // ↯ y = y++ + ++y; // ↯ cout<<++n<<pow(2,n)<<endl; // ↯
I.3.4.3. Értékadó operátorok
Már említettük, hogy C++ nyelvben az értékadás egy olyan kifejezés, amely a bal oldali operandus által kijelölt tárolónak adja a jobb oldalon megadott kifejezés értékét, másrészt pedig ez az érték egyben az értékadó kifejezés értéke is. Ebből következik, hogy értékadás tetszőleges kifejezésben szerepelhet. Az alábbi példában a bal oldalon álló kifejezések eredménye megegyezik a jobb oldalon állókéval:
|
|
|
|
|
|
Az értékadások gyakran használt formája, amikor egy változó értékét valamilyen művelettel módosítjuk, és a keletkező új értéket tároljuk a változóban:
a = a + 2;
Az ilyen alakú kifejezések tömörebb formában is felírhatók:
a += 2;
Általánosan is elmondható, hogy a
kifejezés1 = kifejezés1 op kifejezés2
alakú kifejezések felírására az ún. összetett értékadás műveletét is használhatjuk:
kifejezés1 op= kifejezés2
A két felírás egyenértékű, attól a különbségtől eltekintve, hogy a második esetben a bal oldali kifejezés kiértékelése csak egyszer történik meg. Operátorként (op) a kétoperandusú aritmetikai és bitműveleteket használhatjuk. (Megjegyezzük, hogy az operátorokban szereplő karakterek közzé nem szabad szóközt tenni!)
Az összetett értékadás használata általában gyorsabb kódot eredményez, és könnyebben értelmezhetővé teszi a forrásprogramot.
I.3.5. Léptető (inkrementáló/dekrementáló) műveletek
A C++ nyelv hatékony lehetőséget biztosít a numerikus változók értékének eggyel való növelésére ++ (increment), illetve eggyel való csökkentésére -- (decrement). Az operátorok csak balérték operandussal használhatók, azonban mind az előrevetett, mind pedig a hátravetett forma alkalmazható:
int a; // prefixes alakok: ++a; --a; // postfixes alakok: a++; a--;
Amennyiben az operátorokat a fent bemutatott módon használjuk, nem látszik különbség az előrevetett és hátravetett forma között, hiszen mindkét esetben a változó értéke léptetődik. Ha azonban az operátort bonyolultabb kifejezésben alkalmazzuk, akkor a prefixes alak használata esetén a léptetés a kifejezés feldolgozása előtt megy végbe, és az operandus az új értékével vesz részt a kifejezés kiértékelésében:
int n, m = 5; m = ++n; // m ⇒ 6, n ⇒ 6
Postfixes forma esetén a léptetés az kifejezés kiértékelését követi, így az operandus az eredeti értékével vesz részt a kifejezés feldolgozásában:
double x, y = 5.0; x = y++; // x ⇒ 5.0, y ⇒ 6.0
A léptető operátorok működését jobban megértjük, ha a bonyolultabb kifejezéseket részkifejezésekre bontjuk. Az
int a = 2, b = 3, c; c = ++a + b--; // a 3, b 2, c pedig 6 lesz
kifejezés az alábbi (egy, illetve többutasításos) kifejezésekkel megegyező eredményt szolgáltat (a vessző műveletről később szólunk):
a++, c=a+b, b--; a++; c=a+b; b--;
Az eggyel való növelés és csökkentés hagyományos formái
a = a + 1; a += 1; a = a - 1; a -= 1;
helyett mindig érdemes a megfelelő léptető operátort alkalmazni,
++a; vagy a++; --a; vagy a--;
amely a jobb áttekinthetőség mellett, gyorsabb kód létrehozását is eredményezi.
Felhívjuk a figyelmet arra, hogy egy adott változó, egy kifejezésen belül ne szerepeljen többször léptető művelet operandusaként! Az ilyen kifejezések értéke teljes mértékben fordítófüggő.
a += a++ * ++a; // ↯
I.3.6. Feltételek megfogalmazása
A C++ nyelv utasításainak egy része valamilyen feltétel függvényében végzi a tevékenységét. Az utasításokban szereplő feltételek tetszőleges kifejezések lehetnek, melyek nulla vagy nem nulla értéke szolgáltatja a logikai hamis, illetve igaz eredményt. A feltételek felírása során összehasonlító (relációs) és logikai műveleteket használunk.
I.3.6.1. Összehasonlító műveletek
Az összehasonlítások elvégzésére kétoperandusú, összehasonlító operátorok állnak rendelkezésünkre, az alábbi táblázatnak megfelelően:
|
Matematikai alak |
C++ kifejezés |
Jelentés |
|---|---|---|
|
|
|
a kisebb, mint b |
|
|
|
a kisebb vagy egyenlő, mint b |
|
|
|
a nagyobb, mint b |
|
|
|
a nagyobb vagy egyenlő, mint b |
|
|
|
a egyenlő b-vel |
|
|
|
a nem egyenlő b-vel |
A fenti C++ kifejezések mindegyike int típusú. A kifejezések értéke true (1), ha a vizsgált reláció igaz, illetve false (0), ha nem.
Példaként írjunk fel néhány különböző típusú operandusokat tartalmazó igaz kifejezést!
int i = 3, k = 2, n = -3; i > k n <= 0 i+k > n i != k char elso = 'A', utolso = 'Z'; elso <= utolso elso == 65 'N' > elso double x = 1.2, y = -1.23E-7; -1.0 < y 3 * x >= (2 + y) fabs(x-y)>1E-5
Felhívjuk a figyelmet arra, hogy számítási és ábrázolási pontatlanságok következtében két lebegőpontos változó azonosságát általában nem szabad az == operátorral ellenőrizni. Helyette a két változó különbségének abszolút értékét kell vizsgálnunk adott hibahatárral:
double x = log(sin(3.1415926/2)); double y = exp(x); cout << setprecision(15)<<scientific<< x<< endl; // x ⇒ -3.330669073875470e-016 cout << setprecision(15)<<scientific<< y<< endl; // y ⇒ .999999999999997e-001 cout << (x == 0) << endl; // hamis cout << (y == 1) << endl; // hamis cout << (fabs(x)<1e-6) << endl; // igaz cout << (fabs(y-1.0)<1e-6)<< endl; // igaz
Gyakori programhiba az értékadás (=) és az azonosságvizsgálat (==) műveleteinek összekeverése. Változó konstanssal való összehasonlítása biztonságossá tehető, ha bal oldali operandusként a konstanst adjuk meg, hiszen értékadás esetén itt balértéket vár a fordító:
dt == 2004 helyett 2004 == dt
I.3.6.2. Logikai műveletek
Ahhoz, hogy bonyolultabb feltételeket is meg tudjunk fogalmazni, a relációs operátorok mellett logikai operátorokra is szükségünk van. C++-ban a logikai ÉS (konjunkció , &&), a logikai VAGY (diszjunkció, ||) és a tagadás (negáció, !) művelete használható a feltételek felírása során.
A logikai operátorok működését ún. igazságtáblával írhatjuk le:
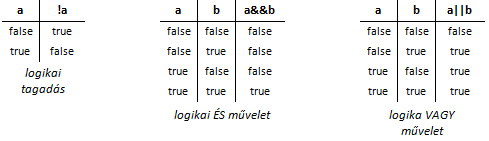
Az alábbi feltétel akkor igaz, ha az x változó értéke -1 és +1 közé esik. A zárójelekkel csupán megerősítjük a precedenciát.
-1 < x && x < 1
(-1 < x) && (x < 1)
Vannak esetek, amikor valamely feltétel felírása helyett egyszerűbb az ellentett feltételt megfogalmazni, és alkalmazni rá a logikai tagadás (NEM) operátorát (!). Az előző példában alkalmazott feltétel egyenértékű az alábbi feltétellel:
!(-1 >= x || x >= 1)
A logikai tagadás során minden relációt az ellentétes irányú relációra, az ÉS operátort pedig a VAGY operátorra (illetve fordítva) cseréljük.
A C++ programokban, a numerikus ok változóval gyakran találkozhatunk a
ok == 0 kifejezés helyett a !ok
ok != 0 kifejezés helyett az ok
kifejezéssel. A jobb oldali kifejezéseket leginkább bool típusú ok változóval javasolt alkalmazni.
I.3.6.3. Rövidzár kiértékelés
A művelettáblázatból látható, hogy a logikai kifejezések kiértékelése balról-jobbra haladva történik. Bizonyos műveleteknél nem szükséges a teljes kifejezést feldolgozni ahhoz, hogy egyértelmű legyen a kifejezés értéke.
Példaként vegyük a logikai ÉS (&&) műveletet, mely használata esetén a bal oldali operandus false (0) értéke a jobb oldali operandus feldolgozását feleslegessé teszi! Ezt a kiértékelési módot rövidzár (short-circuit) kiértékelésnek nevezzük.
Ha a rövidzár kiértékelése során a logikai operátor jobb oldalán valamilyen mellékhatás kifejezés áll,
x || y++
az eredmény nem mindig lesz az, amit várunk. A fenti példában x nem nulla értéke esetén az y léptetésére már nem kerül sor. A rövidzár kiértékelés akkor is érvényesül, ha a logikai műveletek operandusait zárójelek közé helyezzük:
(x) || (y++)
I.3.6.4. A feltételes operátor
A feltételes operátor (?:) három operandussal rendelkezik:
feltétel ? igaz_kifejezés : hamis_kifejezés
Ha a feltétel igaz (true), akkor az igaz_kifejezés értéke adja a feltételes kifejezés értékét, ellenkező esetben pedig a kettőspont (:) után álló hamis_kifejezés. Ily módon a kettőspont két oldalán álló kifejezések közül mindig csak az egyik értékelődik ki. A feltételes kifejezés típusa a nagyobb pontosságú részkifejezés típusával egyezik meg. Az
(n > 0) ? 3.141534 : 54321L;
kifejezés típusa, függetlenül az n értékétől mindig double lesz.
Nézzünk egy jellegzetes példát a feltételes operátor alkalmazására! Az alábbi kifejezés segítségével az n változó 0 és 15 közötti értékeit hexadecimális számjeggyé alakítjuk:
ch = n >= 0 && n <= 9 ? '0' + n : 'A' + n - 10;
Felhívjuk a figyelmet arra, hogy a feltételes művelet elsőbbsége elég alacsony, épphogy megelőzi az értékadásét, ezért összetettebb kifejezésekben zárójelet kell használnunk:
c = 1 > 2 ? 4 : 7 * 2 < 3 ? 4 : 7 ; // 7 ↯
c = (1 > 2 ? 4 : (7 * 2)) < 3 ? 4 : 7 ; // 7 ↯
c = (1 > 2 ? 4 : 7) * (2 < 3 ? 4 : 7) ; //28
I.3.7. Bitműveletek
Régebben a számítógépek igen kevés memóriával rendelkeztek, így nagyon értékesek voltak azok a megoldások, amelyek a legkisebb címezhető egységen, a bájton belül is lehetővé tették több adat tárolását és feldolgozását. Bitműveletek segítségével egy bájtban akár 8 darab logikai értéket is elhelyezhetünk. Napjainkban ez a szempont csak igen ritkán érvényesül, és inkább a program érthetőségét tartjuk szem előtt.
Van mégis egy terület, ahol a bitműveleteknek napjainkban is hasznát vehetjük, nevezetesen a különböző hardverelemek, mikrovezérlők programozása. A C++ nyelv tartalmaz hat operátort, amelyekkel különböző bitenkénti műveleteket végezhetünk előjeles és előjel nélküli egész adatokon.
I.3.7.1. Bitenkénti logikai műveletek
A műveletek első csoportja, a bitenkénti logikai műveletek, lehetővé teszik, hogy biteket teszteljünk, töröljünk vagy beállítsunk:
|
Operátor |
Művelet |
|---|---|
|
|
1-es komplemens, bitenkénti tagadás |
|
|
bitenkénti ÉS |
|
|
bitenkénti VAGY |
|
|
bitenkénti kizáró VAGY |
A bitenkénti logikai műveletek működésének leírását az alábbi táblázat tartalmazza, ahol a 0 és az 1 számjegyek a törölt, illetve a beállított bitállapotot jelölik.
|
a |
b |
a & b |
a | b |
a ^ b |
~a |
|---|---|---|---|---|---|
|
0 |
0 |
0 |
0 |
0 |
1 |
|
0 |
1 |
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
1 |
1 |
0 |
|
1 |
1 |
1 |
1 |
0 |
0 |
A számítógép hardverelemeinek alacsony szintű vezérlése általában bizonyos bitek beállítását, törlését, illetve kapcsolását igényli. Ezeket a műveleteket összefoglaló néven „maszkolásnak” nevezzük, mivel minden egyes művelethez megfelelő bitmaszkot kell készítenünk, amellyel aztán logikai kapcsolatba hozva a megváltoztatni kívánt értéket, végbemegy a kívánt bitművelet.
Mielőtt sorra vennénk a szokásos bitműveleteket, meg kell ismerkednünk az egész adatelemek bitjeinek sorszámozásával. A bitek sorszámozása a bájton a legkisebb helyértékű bittől indulva 0-val kezdődik, és balra haladva növekszik. Több bájtból álló egészek esetén azonban tisztáznunk kell a számítógép processzorában alkalmazott bájtsorrendet is.
A Motorola 68000, SPARC, PowerPC stb. processzorok által támogatott „nagy a végén” (big-endian) bájtsorrend esetén a legnagyobb helyiértékű bájt (MSB) a memóriában a legalacsonyabb címen tárolódik, míg az eggyel kisebb helyiértékű a következő címen és így tovább.
Ezzel szemben a legelterjedtebb Intel x86 alapú processzorcsalád tagjai a „kicsi a végén” (little-endian) bájtsorrendet használják, amely szerint legkisebb helyiértékű bájt (LSB) helyezkedik el a legalacsonyabb címen a memóriában.
A hosszú bitsorozatok elkerülése érdekében a példáinkban unsigned short int típusú adatelemeket használunk. Nézzük meg ezen adatok felépítését és tárolását mindkét bájtsorrend szerint! A tárolt adat legyen 2012, ami hexadecimálisan 0x07DC!
big-endian bájtsorrend:

little-endian bájtsorrend:

(A példákban a memóriacímek balról jobbra növekednek.) Az ábrán jól látható, hogy a hexadecimális konstans értékek megadásakor az első, „nagy a végén” formát használjuk, ami megfelel a 16-os számrendszer matematikai értelmezésének. Ez nem okoz gondot, hisz a memóriában való tárolás a fordítóprogram feladata. Ha azonban az egész változókat bájtonként kívánjuk feldolgozni, ismernünk kell a bájtsorrendet. Könyvünk további részeiben a második, a „kicsi a végén” forma szerint készítjük el a példaprogramjainkat, amelyek azonban az elmondottak alapján az első tárolási módszerre is adaptálhatók.
Az alábbi példákban az unsigned short int típusú 2525 szám 4. és 13. bitjeit kezeljük:
unsigned short int x = 2525; // 0x09dd
|
Művelet |
Maszk |
C++ utasítás |
Eredmény |
|---|---|---|---|
|
Bitek beállítása |
0010 0000 0001 0000 |
x = x | 0x2010; |
0x29dd |
|
Bitek törlése |
1101 1111 1110 1111 |
x = x & 0xdfef; |
0x09cd |
|
Bitek negálása (kapcsolása) |
0010 0000 0001 0000 |
x = x ^ 0x2010; x = x ^ 0x2010; |
0x29cd (10701) 0x09dd (2525) |
|
Az összes bit negálása |
1111 1111 1111 1111 |
x = x ^ 0xFFFF; |
0xf622 |
|
Az összes bit negálása |
x = ~x; |
0xf622 |
Felhívjuk a figyelmet a kizáró vagy operátor (^) érdekes viselkedésére. Ha ugyanazzal a maszkkal kétszer végezzük el a kizáró vagy műveletet, akkor visszakapjuk az eredeti értéket, esetünkben a 2525-öt. Ezt a működést felhasználhatjuk két egész változó értékének segédváltozó nélküli felcserélésére:
int m = 2, n = 7; m = m ^ n; n = m ^ n; m = m ^ n;
Nehezen kideríthető programhibához vezet, ha a programunkban összekeverjük a feltételekben használt logikai műveleti jeleket (!, &&, ||) a bitenkénti operátorokkal (~, &, |).
I.3.7.2. Biteltoló műveletek
A bitműveletek másik csoportjába, a biteltoló (shift) operátorok tartoznak. Az eltolás balra (<<) és jobbra (>>) egyaránt elvégezhető. Az eltolás során a bal oldali operandus bitjei annyiszor lépnek balra (jobbra), amennyi a jobb oldali operandus értéke.
Balra eltolás esetén a felszabaduló bitpozíciókba 0-ás bitek kerülnek, míg a kilépő bitek elvesznek. A jobbra eltolás azonban figyelembe veszi, hogy a szám előjeles vagy sem. Előjel nélküli (unsigned) típusok esetén balról 0-ás bit lép be, míg előjeles (signed) számoknál 1-es bit. Ez azt jelenti, hogy a jobbra való biteltolás előjelmegőrző.
short int x;
|
Értékadás |
Bináris érték |
Művelet |
Eredmény decimális (hexadecimális) bináris |
|---|---|---|---|
|
x = 2525; |
0000 1001 1101 1101 |
x = x << 2; |
10100 (0x2774) 0010 0111 0111 0100 |
|
x = 2525; |
0000 1001 1101 1101 |
x = x >> 3; |
315 (0x013b) 0000 0001 0011 1011 |
|
x = -2525; |
1111 0110 0010 0011 |
x = x >> 3; |
-316 (0xfec4) 1111 1110 1100 0100 |
Az eredményeket megvizsgálva láthatjuk, hogy az 2 bittel való balra eltolás során az x változó értéke négyszeresére (22) nőtt, míg három lépéssel jobbra eltolva, x értéke nyolcad (23) részére csökkent. Általánosan is megfogalmazható, hogy valamely egész szám bitjeinek balra tolása n lépéssel a szám 2n értékkel való megszorzását eredményezi. Az m bittel való jobbra eltolás pedig 2m értékkel elvégzett egész osztásnak felel meg. Megjegyezzük, hogy egy egész szám 2n-nel való szorzásának/osztásának ez a leggyorsabb módja.
Az alábbi példában a beolvasott 16-bites egész számot két bájtra bontjuk:
short int num; unsigned char lo, hi; // A szám beolvasása cout<<"\nKerek egy egesz szamot [-32768,32767] : "; cin>>num; // Az alsó bájt meghatározása maszkolással lo=num & 0x00FFU; // Az felső byte meghatározása biteltolással hi=num >> 8;
Az utolsó példában felcseréljük a 4-bájtos, int típusú változó bájtsorrendjét:
int n =0x12345678U;
n = (n >> 24) | // az első bájtot a végére mozgatjuk,
((n << 8) & 0x00FF0000U) | // a 2. bájtot a 3. bájtba,
((n >> 8) & 0x0000FF00U) | // a 3. bájtot a 2. bájtba,
(n << 24); // az utolsó bájtot pedig az elejére.
cout <<hex << n <<endl; // 78563412
I.3.7.3. Bitműveletek az összetett értékadásban
A C++ mind az öt kétoperandusú bitművelethez összetett értékadás művelet is tartozik, melyekkel a változók értéke könnyebben módosítható.
|
Operátor |
Műveleti jel |
Használat |
Művelet |
|---|---|---|---|
|
Balra eltoló értékadás |
|
|
x bitjeinek eltolása balra y bittel, |
|
Jobbra eltoló értékadás |
|
|
x bitjeinek eltolása jobbra y bittel, |
|
Bitenkénti VAGY értékadás |
|
|
x új értéke: x | y, |
|
Bitenkénti ÉS értékadás |
|
|
x új értéke: x & y, |
|
Bitenkénti kizáró VAGY értékadás |
|
|
x új értéke: x ^ y, |
Fontos megjegyeznünk, hogy a bitműveletek eredményének típusa legalább int vagy az int-nél nagyobb egész típus, a bal oldali operandus típusától függően. Biteltolás esetén a lépések számát ugyan tetszőlegesen megadhatjuk, azonban a fordító a típus bitméretével képzett maradékát alkalmazza az eltoláshoz. Például a 32-bites int típusú változók esetében az alábbiakat tapasztalhatjuk:
unsigned z; z = 0xFFFFFFFF, z <<= 31; // z ⇒ 80000000 z = 0xFFFFFFFF, z <<= 32; // z ⇒ ffffffff z = 0xFFFFFFFF, z <<= 33; // z ⇒ fffffffe
I.3.8. A vessző operátor
Egyetlen kifejezésben több, akár egymástól független kifejezést is elhelyezhetünk, a legkisebb elsőbbségű vessző operátor felhasználásával. A vessző operátort tartalmazó kifejezés balról-jobbra haladva értékelődik ki, a kifejezés értéke és típusa megegyezik a jobb oldali operandus értékével, illetve típusával. Példaként tekintsük az
x = (y = 4 , y + 3);
kifejezést! A kiértékelés a zárójelbe helyezett vessző operátorral kezdődik, melynek során először az y változó kap értéket (4), majd pedig a zárójelezett kifejezés (4+3=7). Végezetül az x változó megkapja a 7 értéket.
A vessző operátort gyakran használjuk változók különböző kezdőértékének egyetlen utasításban (kifejezésben) történő beállítására:
x = 2, y = 7, z = 1.2345 ;
Ugyancsak a vessző operátort kell alkalmaznunk, ha két változó értékét egyetlen utasításban kívánjuk felcserélni (harmadik változó felhasználásával):
c = a, a = b, b = c;
Felhívjuk a figyelmet arra, hogy azok a vesszők, amelyeket a deklarációkban a változónevek, illetve a függvényhíváskor az argumentumok elkülönítésére használunk nem vessző operátorok.
I.3.9. Típuskonverziók
A kifejezések kiértékelése során gyakran előfordul, hogy egy kétoperandusú műveletet különböző típusú operandusokkal kell végrehajtani. Ahhoz azonban, hogy a művelet elvégezhető legyen, a fordítónak azonos típusúra kell átalakítania a két operandust, vagyis típuskonverziót kell végrehajtania.
C++-ban a típus-átalakítások egy része automatikusan, a programozó beavatkozása nélkül megy végbe, a nyelv definíciójában rögzített szabályok alapján. Ezeket a konverziókat implicit vagy automatikus konverzióknak nevezzük.
C++ programban a programozó is előírhat típus-átalakítást a típuskonverziós operátorok (cast) felhasználásával ( explicit típuskonverzió).
I.3.9.1. Implicit típus-átalakítások
Általánosságban elmondható, hogy az automatikus konverziók során a „szűkebb értéktartományú” operandus adatvesztés nélkül átalakul a „szélesebb értéktartományú” operandus típusára. Az alábbi példában az m+d kifejezés kiértékelése során az int típusú m operandus double típusúvá alakul, ami egyben a kifejezés típusát is jelenti:
int m=4, n; double d=3.75; n = m + d;
Az implicit konverziók azonban nem minden esetben mennek végbe adatvesztés nélkül. Az értékadás és a függvényhívás során tetszőleges típusok közötti konverzió is előfordulhatnak. Például, a fenti példában az összeg n változóba töltésekor adatvesztés lép fel, hiszen az összeg törtrésze elvész, és 7 lesz a változó értéke. (Felhívjuk a figyelmet, hogy semmilyen kerekítés nem történt az értékadás során!)
A következőkben röviden összefoglaljuk az x op y alakú kifejezések kiértékelése során automatikusan végrehajtódó konverziókat.
-
A char, wchar_t, short, bool, enum típusú adatok automatikusan int típussá konvertálódnak. Ha az int típus nem alkalmas az értékük tárolására, akkor unsigned int lesz a konverzió céltípusa. Ez a típus-átalakítási szabály az „egész konverzió” (integral promotion) nevet viseli. A fenti konverziók értékmegőrző átalakítások, mivel érték- és előjelhelyes eredményt adnak.
-
Ha az első lépés után a kifejezésben különböző típusok szerepelnek, életbe lép a típusok hierarchiája szerinti konverzió. A típus-átalakítás során a „kisebb” típusú operandus a „nagyobb” típusúvá konvertálódik. Az átalakítás során felhasznált szabályok a „szokásos aritmetikai konverziók” nevet viselik.
int < unsigned < long < unsigned long < longlong < unsigned longlong < float < double < long double
I.3.9.2. Explicit típus-átalakítások
Az explicit módon megadott felhasználói típus-átalakítások célja az implicit módon nem végrehajtódó típuskonverziók elvégzése. Most csak az alaptípusokkal használható átalakításokkal foglalkozunk, míg a const_cast, a dynamic_cast és a reinterpret_cast műveletekről az I.6. szakasz fejezetben olvashatunk.
Az alábbi (statikus) típuskonverziók mindegyike a C++ program fordítása során hajtódik végre. A típus-átalakítások egy lehetséges csoportosítása:
|
típus-átalakítás (C/C++) |
(típusnév) kifejezés |
|
|
függvényszerű forma |
típusnév (kifejezés) |
|
|
ellenőrzött típus-átalakítások |
static_cast< típusnév >(kifejezés) |
|
Minden kifejezés felírásakor gondolnunk kell az implicit és az esetleg szükséges explicit konverziókra. Az alábbi programrészlettel két hosszú egész változó átlagát kívánjuk meghatározni, és double típusú változóba tárolni:
long a =12, b=7; double d = (a+b)/2; cout << d << endl; // 9
Az eredmény hibás, mivel az egész konverziók következtében az értékadás jobb oldalán egy long típusú eredmény keletkezik, és ez kerül a d változóba. Az eredmény csak akkor lesz helyes (9.5), ha az osztás valamelyik operandusát double típusúvá alakítjuk, az alábbi lehetőségek egyikével:
d = (a+b)/2.0; d = (double)(a+b)/2; d = double(a+b)/2; d = static_cast<double>(a+b)/2;
I.4. Vezérlő utasítások
Az eddigi ismereteink alapján csak olyan programokat tudunk készíteni, melynek main () függvényében csak pontosvesszővel lezárt kifejezések szerepelnek (adatbevitel, értékadás, kiírás stb.) egymás után. Bonyolultabb algoritmusok programozásához azonban ez a soros felépítésű programszerkezet nem elegendő. Meg kell ismerkednünk a C++ nyelv vezérlő utasításaival, melyek lehetővé teszik bizonyos programrészek feltételtől függő, illetve ismételt végrehajtását. (Tájékoztatásul, a C++ utasítások összefoglalását az A.5. szakasz függelék tartalmazza.)
I.4.1. Az üres utasítás és az utasításblokk
Az C++ nyelv vezérlő utasításai más utasítások végrehajtását „vezérlik”. Amennyiben semmilyen tevékenységes sem kívánunk „vezéreltetni” az üres utasítást adjuk meg. Ha azonban több utasítás „vezérlésére” van szüksége, akkor az ún. összetett utasítást, vagyis az utasításblokkot kell alkalmaznunk.
Az üres utasítás egyetlen pontosvesszőből (;) áll. Használatára akkor van szükség, amikor logikailag nem kívánunk semmilyen tevékenységet végrehajtani, azonban a szintaktikai szabályok szerint a program adott pontján utasításnak kell szerepelnie.
Kapcsos zárójelek ( { és } ) segítségével a logikailag összefüggő deklarációkat és utasításokat egyetlen összetett utasításba vagy blokkba csoportosíthatjuk. Az összetett utasítás mindenütt felhasználható, ahol egyetlen utasítás megadását engedélyezi a C++ nyelv leírása. Összetett utasítást, melynek általános formája:
{
lokális definíciók, deklarációk
utasítások
}
a következő három esetben használunk:
-
amikor több, logikailag összefüggő utasítást egyetlen utasításként kell kezelni (ilyenkor általában csak utasításokat tartalmaz a blokk),
-
függvények törzseként,
-
definíciók és deklarációk érvényességének lokalizálására.
Az utasításblokkon belül az utasításokat és a definíciókat/deklarációkat tetszőleges sorrendben megadhatjuk. (Felhívjuk a figyelmet arra, hogy blokkot nem kell pontosvesszővel lezárni.)
Az alábbi példában az egyismeretlenes másodfokú egyenlet megoldását csak akkor végezzük el, ha az egyenlet diszkriminánsa (a gyök alatti mennyiség) nem negatív. A helyes programszerkezet kialakításához a következő részben bemutatásra kerülő if utasítást használjuk:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
double a, b, c;
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
cout << "c = "; cin >> c;
if (b*b-4*a*c>=0) {
double x1, x2;
x1 = (-b + sqrt(b*b-4*a*c))/(2*a);
x2 = (-b - sqrt(b*b-4*a*c))/(2*a);
cout << x1 << endl;
cout << x2 << endl;
}
}
I.4.2. Szelekciós utasítások
A szelekciós utasításokkal (if, switch) feltételtől függően jelölhetjük ki a program további futásának lépéseit. Megvalósíthatunk leágazást, kettéágaztatást vagy többirányú elágaztatást. A szelekciókat egymásba is ágyazhatjuk. A feltételek megfogalmazásakor a már megismert összehasonlító (relációs) és logikai műveleteket használjuk.
I.4.2.1. Az if utasítás
Az if utasítás segítségével valamely tevékenység (utasítás) végrehajtását egy kifejezés (feltétel) értékétől tehetjük függővé. Az if utasítás három formában szerepelhet a programunkban
Leágazás
Az if alábbi formájában az utasítás csak akkor hajtódik végre, ha a feltétel értéke nem nulla (igaz, true). (Felhívjuk a figyelmet arra, hogy a feltételt mindig kerek zárójelek között kell megadni.)
if (feltétel)
utasítás
Blokk-diagram segítségével a különböző vezérlési szerkezetek működése grafikus formában ábrázolható. Az egyszerű if utasítás feldolgozását akövetkező ábrán(I.7. ábra) követhetjük nyomon.
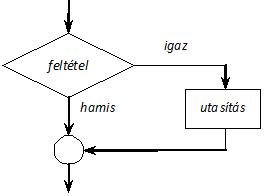
A következő példában csak akkor számítjuk ki a beolvasott szám négyzetgyökét, ha az nem negatív:
#include <iostream>
#include <cmath>
using namespace std;
int main() {
double x = 0;
cout << "x = "; cin >> x;
if (x >= 0) {
cout<<sqrt(x)<<endl;
}
}
Kétirányú elágazás
Az if utasítás teljes formájában arra az esetre is megadhatunk egy tevékenységet (utasítás2), amikor a feltétel kifejezés értéke nulla (hamis, false) (I.8. ábra). (Ha az utasítás1 és az utasítás2 nem összetett utasítások, akkor pontosvesszővel kell őket lezárni.)
if (feltétel)
utasítás1
else
utasítás2
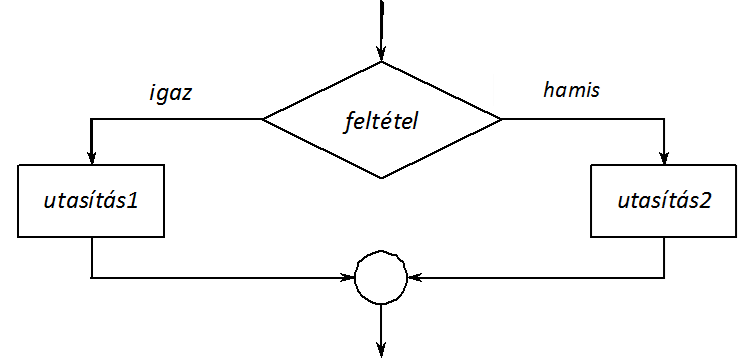
Az alábbi példában a beolvasott egész számról if utasítás segítségével döntjük el, hogy páros vagy páratlan:
#include <iostream>
using namespace std;
int main()
{
int n;
cout<<"Kerek egy egesz szamot: "; cin>>n;
if (n % 2 == 0)
cout<<"A szam paros!"<<endl;
else
cout<<"A szam paratlan!"<<endl;
}
Az if utasítások egymásba is ágyazhatók. Ilyenkor azonban körültekintően kell eljárnunk az else ág(ak) használatával. A fordító mindig a legközelebbi, megelőző if utasításhoz kapcsolja az else ágat.
Az alábbi példában egy megadott egész számról megmondjuk, hogy az pozitív páratlan szám-e, vagy nem pozitív szám. A helyes megoldáshoz kétféleképpen is eljuthatunk. Az egyik lehetőség, ha a belső if utasításhoz egy üres utasítást (;) tartalmazó else-ágat kapcsolunk:
if (n > 0)
if (n % 2 == 1)
cout<<"Pozitiv paratlan szam."<< endl;
else;
else
cout<<"Nem pozitiv szam."<<endl;
A másik járható út, ha a belső if utasítást kapcsos zárójelek közé, azaz utasításblokkba helyezzük:
if (n > 0) {
if (n % 2 == 1)
cout<<"Pozitiv paratlan szam."<< endl;
} else
cout<<"Nem pozitiv szam."<<endl;
A probléma fel sem vetődik, ha eleve utasításblokkokat használunk minkét if esetén, ahogy azt a biztonságos programozás megkívánja:
if (n > 0) {
if (n % 2 == 1) {
cout<<"Pozitiv paratlan szam."<< endl;
}
}
else {
cout<<"Nem pozitiv szam."<<endl;
}
Ebben az esetben bármelyik ág biztonságosan bővíthető újabb utasításokkal.
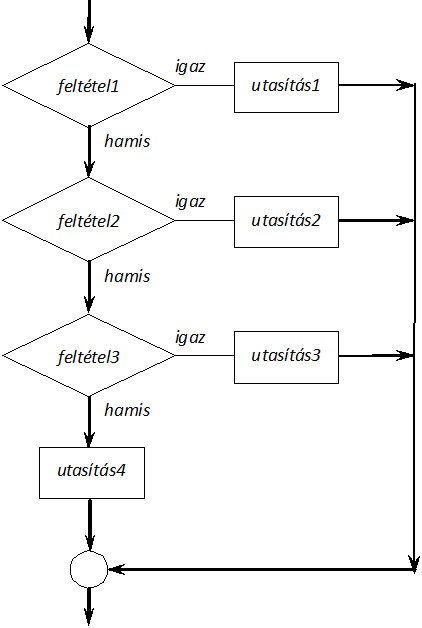
Többirányú elágazás
Az egymásba ágyazott if utasítások gyakori formája, amikor az else-ágakban szerepelnek az újabb if utasítások (I.9. ábra).
Ezzel a szerkezettel a programunk többirányú elágaztatását valósíthatjuk meg. Ha bármelyik feltétel igaz, akkor a hozzá kapcsolódó utasítás hajtódik végre. Amennyiben egyik feltétel sem teljesül, a program végrehajtása az utolsó else utasítással folytatódik.
if (feltétel1)
utasítás1
else if (feltétel2)
utasítás2
else if (feltétel3)
utasítás3
else
utasítás4
Az alábbi példában az n számról eldöntjük, hogy az negatív, 0 vagy pozitív:
if (n > 0)
cout<<"Pozitiv szam"<<endl;
else if (n==0)
cout<<"0"<<endl;
else
cout<<"Negativ szam"<<endl;
Az else-if szerkezet speciális esete, amikor feltételek egyenlőség-vizsgálatokat (==) tartalmaznak. A következő példában egyszerű összeget és különbséget számoló kalkulátort valósítunk meg:
#include <iostream>
using namespace std;
int main()
{
char op;
double a, b, c;
cout<<"kifejezes : ";
cin >>a>>op>>b; // beolvasás, pl. 4+10 <Enter>
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else {
cout << "Hibas muveleti jel: " << op <<endl;
return -1;
}
cout <<a<<op<<b<<'='<<c<<endl;
return 0;
}
Az utolsó példában a szerzett pontszámok alapján leosztályozzuk a hallgatókat С++ programozásból:
#include <iostream>
using namespace std;
int main()
{
int pontszam, erdemjegy = 0;
cout << "Pontszam: "; cin >> pontszam;
if (pontszam >= 0 && pontszam <= 100)
{
if (pontszam < 40)
erdemjegy = 1;
else if (pontszam >= 40 && pontszam < 55)
erdemjegy = 2;
else if (pontszam >= 55 && pontszam < 70)
erdemjegy = 3;
else if (pontszam >= 70 && pontszam < 85)
erdemjegy = 4;
else if (pontszam >= 86)
erdemjegy = 5;
cout << "Erdemjegy: " << erdemjegy << endl;
}
else
cout <<"Hibas adat!" << endl;
}
I.4.2.2. A switch utasítás
A switch utasítás valójában egy utasításblokk, amelybe a megadott egész kifejezés értékétől függően különböző helyen léphetünk be. A belépési pontokat az ún. esetcímkék (case konstans kifejezés) jelölik ki.
switch (kifejezés)
{
case konstans_kifejezés1 :
utasítások1
case konstans_kifejezés2 :
utasítások2
case konstans_kifejezés3 :
utasítások3
default :
utasítások4
}
A switch utasítás először kiértékeli a kifejezést, majd átadja a vezérlést arra a case (eset) címkére, amelyben a konstans_kifejezés értéke megegyezik a kiértékelt kifejezés értékével. Ezt követően a belépési ponttól az összes utasítás végrehajtódik, egészen a blokk végéig. Amennyiben egyik case konstans sem egyezik meg a kifejezés értékével, a program futása a default címkével megjelölt utasítástól folytatódik. Ha nem adtuk meg a default címkét, akkor a vezérlés a switch utasítás blokkját záró kapcsos zárójel utáni utasításra kerül.
Ezt a kissé furcsa működést egy rendhagyó példaprogrammal szemléltetjük. Az alábbi switch utasítás képes meghatározni 0 és 5 közé eső egészszámok faktoriálisát. (A rendhagyó jelző esetünkben azt jelenti, hogy nem követendő.)
int n = 4, f(1);
switch (n) {
case 5: f *= 5;
case 4: f *= 4;
case 3: f *= 3;
case 2: f *= 2;
case 1: f *= 1;
case 0: f *= 1;
}
A switch utasítást az esetek többségében - az else-if szerkezethez hasonlóan - többirányú programelágazás megvalósítására használjuk. Ehhez azonban minden esethez tartozó utasítássorozatot valamilyen ugró utasítással (break, goto vagy return) kell lezárnunk. A break a switch blokkot közvetlenül követő utasításra, a goto a függvényen belül címkével megjelölt utasításra adja a vezérlést, míg a return kilép a függvényből.
Mivel célunk áttekinthető szerkezetű, jól működő programok készítése, az ugró utasítások használatát a programban minimálisra kell csökkenteni. Ennek ellenére a break alkalmazása a switch utasításokban teljes mértékben megengedett. Általában a default címke utáni utasításokat is break-kel zárjuk, azon egyszerű oknál fogva, hogy a default eset bárhol elhelyezkedhet a switch utasításon belül.
Az elmondottak alapján minden nehézség nélkül elkészíthetjük az előző alfejezet kalkulátor programját switch alkalmazásával:
#include <iostream>
using namespace std;
int main()
{
char op;
double a, b, c;
cout<<"kifejezes :";
cin >>a>>op>>b;
switch (op) {
case '+':
c = a + b;
break;
case '-':
c = a - b;
break;
default:
cout << "Hibas muveleti jel: " << op <<endl;
return -1;
}
cout <<a<<op<<b<<'='<<c<<endl;
return 0;
}
A következő példában bemutatjuk, hogyan lehet több esethez ugyanazt a programrészletet rendelni. A programban a válaszkaraktert feldolgozó switch utasításban az 'i' és 'I', illetve az 'n' és 'N' esetekhez tartozó case címkéket egymás után helyeztük el.
#include <iostream>
using namespace std;
int main()
{
cout<<"A valasz [I/N]?";
char valasz=cin.get();
switch (valasz) {
case 'i': case 'I':
cout<<"A valasz IGEN."<<endl;
break;
case 'n':
case 'N':
cout<<"A valasz NEM."<<endl;
break;
default:
cout<<"Hibas valasz!"<<endl;
break;
}
}
I.4.3. Iterációs utasítások
A programozási nyelveken utasítások automatikus ismétlését biztosító programszerkezetet iterációnak vagy ciklusnak (loop) nevezzük. A C++ nyelv ciklusutasításai egy ún. ismétlési feltétel függvényében mindaddig ismétlik a megadott utasítást, amíg a feltétel igaz.
while (feltétel) utasítás
for (inicializáló kifejezés opt ; feltétel opt ; léptető kifejezés opt ) utasítás
do utasítás while (feltétel)
A for utasítás esetén az opt index arra utal, hogy a megjelölt kifejezések használata opcionális.
A ciklusokat csoportosíthatjuk a vezérlőfeltétel feldolgozásának helye alapján. Azokat a ciklusokat, amelyeknél az utasítás végrehajtása előtt értékelődik ki vezérlőfeltétel, az elöltesztelő ciklusok. A ciklus utasítása csak akkor hajtódik végre, ha a feltétel igaz. A C++ elöltesztelő ciklusai a while és a for.
Ezzel szemben a do ciklus utasítása legalább egyszer mindig lefut, hisz a vezérlőfeltétel ellenőrzése az utasítás végrehajtása után történik – hátultesztelő ciklus.
Mindhárom esetben a helyesen szervezett ciklus befejezi működését, amikor a vezérlőfeltétel hamissá (0) válik. Vannak azonban olyan esetek is, amikor szándékosan vagy véletlenül olyan ciklust hozunk létre, melynek vezérlőfeltétele soha sem lesz hamis. Ezeket a ciklusokat végtelen ciklusnak nevezzük:
for (;;) utasítás; while (true) utasítás; do utasítás while (true);
A ciklusokból a vezérlőfeltétel hamis értékének bekövetkezte előtt is ki lehet ugrani (a végtelen ciklusból is). Erre a célra további utasításokat biztosít a C++ nyelv, mint a break, a return, illetve a ciklus törzsén kívülre irányuló goto. A ciklus törzsének bizonyos utasításait átugorhatjuk a continue utasítás felhasználásával. A continue hatására a ciklus következő iterációjával folytatódik a program futása.
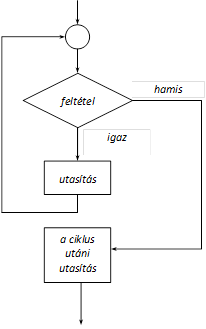
I.4.3.1. A while ciklus
A while ciklus mindaddig ismétli a hozzá tartozó utasítást (a ciklus törzsét), amíg a vizsgált feltétel értéke true (igaz, nem 0). A vizsgálat mindig megelőzi az utasítás végrehajtását. A while ciklus működésének folyamata az elöző ábrán (I.10. ábra) követhető nyomon.
while (feltétel)
utasítás
A következő példaprogramban meghatározzuk az első n természetes szám összegét:
#include <iostream>
using namespace std;
int main()
{
int n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
unsigned long sum = 0;
while (n>0) {
sum += n;
n--;
}
cout<<"osszege: "<<sum<<endl;
}
A megoldás while ciklusát tömörebben is felírhatjuk, természetesen a program olvashatóságának rovására:
|
|
|
|
A C++ nyelv megengedi, hogy a változók deklarációját bárhova helyezzük a program kódján belül. Egyetlen feltétel, hogy a változót mindenképpen deklarálnunk (definiálnunk) kell a felhasználása előtt. Bizonyos esetekben a változó-definíciót a ciklusutasítások fejlécébe is bevihetjük, amennyiben a változót azonnal inicializáljuk, például véletlen számmal.
Az alábbi példaprogram while ciklusa az első 10-el osztható véletlen számig fut. A megoldásban az
srand((unsigned)time(NULL));
utasítás a véletlen szám generátorát az aktuális idővel inicializálja, így minden futtatáskor új számsort kapunk. A véletlen számot a rand () függvény szolgáltatja 0 és RAND_MAX (32767) értékhatáron belül.
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main()
{
srand((unsigned)time(NULL));
while (int n = rand()%10)
cout<< n<< endl;
}
Felhívjuk a figyelmet arra, hogy az így definiált n változó csak a while cikluson belül érhető el, vagyis a while ciklusra nézve lokális.
I.4.3.2. A for ciklus
A for utasítást általában akkor használjuk, ha a ciklusmagban megadott utasítást adott számsor mentén kívánjuk végrehajtani (I.11. ábra). A for utasítás általános alakjában feltüntettük az egyes kifejezések szerepét:
for (inicilizáció; feltétel; léptetés)
utasítás
A for utasítás valójában a while utasítás speciális alkalmazása, így a fenti for ciklus minden további nélkül átírható while ciklussá:
inicilizáció;
while (feltétel) {
utasítás;
léptetés;
}
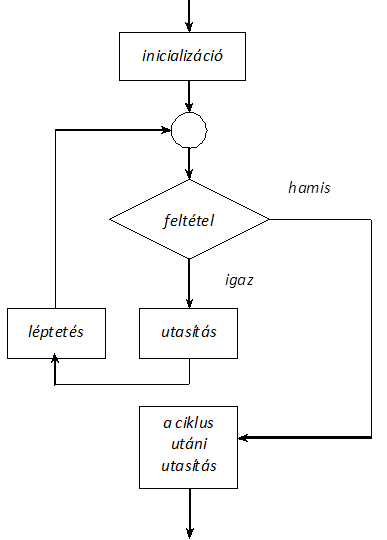
Példaként a for ciklusra, tekintsük a már megoldott, természetes számok összegét meghatározó programot! Azonnal látható, hogy a megoldásnak ez a változata sokkal áttekinthetőbb és egyszerűbb:
#include <iostream>
using namespace std;
int main()
{
unsigned long sum;
int i, n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
for (i=1, sum=0 ; i<=n ; i++)
sum += i;
cout<<"osszege: "<<sum<<endl;
}
A példában szereplő ciklus magjában csak egyetlen kifejezés-utasítás található, ezért a for ciklus az alábbi tömörebb formákban is felírható:
for (i=1, sum=0 ; i<=n ; sum += i, i++) ;
illetve
for (i=1, sum=0 ; i<=n ; sum += i++) ;
A ciklusokat egymásba is ágyazhatjuk, hisz a ciklus utasítása újabb ciklusutasítás is lehet. A következő példában egymásba ágyazott ciklusokat használunk a megadott méretű piramis megjelenítésére. Mindhárom ciklusban lokálissá tettük a ciklusváltozót:
#include <iostream>
using namespace std;
int main ()
{
const int maxn = 12;
for (int i=0; i<maxn; i++) {
for (int j=0; j<maxn-i; j++) {
cout <<" ";
}
for (int j=0; j<i; j++) {
cout <<"* ";
}
cout << endl;
}
}
|
*
* *
* * *
* * * *
* * * * *
* * * * * *
* * * * * * *
* * * * * * * *
* * * * * * * * *
* * * * * * * * * *
* * * * * * * * * * *
|
I.4.3.3. A do-while ciklus
A do-while utasításban a ciklus törzsét képező utasítás végrehajtása után kerül sor a tesztelésre (I.12. ábra), így a ciklus törzse legalább egyszer mindig végrehajtódik.
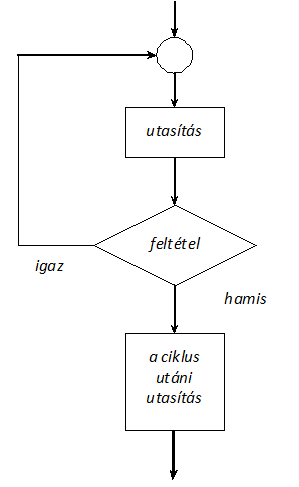
do
utasítás
while (feltétel);
Első példaként készítsük el a természetes számokat összegző program do-while ciklust használó változatát!
#include <iostream>
using namespace std;
int main()
{
int n = 2012;
cout<<"Az elso "<<n<<" egesz szam ";
unsigned long sum = 0;
do {
sum += n;
n--;
} while (n>0);
cout<<"osszege: "<<sum<<endl;
}
Az alábbi ciklus segítségével ellenőrzött módon olvasunk be egy egész számot 2 és 100 között:
int m =0;
do {
cout<<"Kerek egy egesz szamot 2 es 100 kozott: ";
cin >> m;
} while (m < 2 || m > 100);
Az utolsó példánkban egész kitevőjű hatványt számolunk:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
double alap;
int kitevo;
cout << "alap: "; cin >> alap;
cout << "kitevo: "; cin >> kitevo;
double hatvany = 1;
if (kitevo != 0)
{
int i = 1;
do
{
hatvany *= alap;
i++;
} while (i <= abs(kitevo));
hatvany = kitevo < 0 ? 1.0 / hatvany : hatvany;
}
cout <<"a hatvany erteke: " << hatvany << endl;
}
Igen gyakori programozási hiba, amikor a ciklusok fejlécét pontosvesszővel zárjuk. Nézzük az 1-től 10-ig a páratlan egész számok kiírására tett kísérleteket!
|
|
|
|
A while esetén az üres utasítást ismétli vég nélkül a ciklus. A for ciklus lefut az üres utasítás ismétlésével, majd pedig kiírja a ciklusváltozó kilépés utáni értékét, a 11-et. A do-while ciklus esetén a fordító hibát jelez, ha a do után pontosvesszőt teszünk, így a közölt kód teljesen jó megoldást takar.
I.4.3.4. A brake utasítás a ciklusokban
Vannak esetek, amikor egy ciklus szokásos működésébe közvetlenül be kell avatkoznunk. Ilyen feladat például, amikor adott feltétel teljesülése esetén ki kell ugrani egy ciklusból. Erre ad egyszerű megoldást a break utasítás, melynek hatására az utasítást tartalmazó legközelebbi while, for és do-while utasítások működése megszakad, és a vezérlés a megszakított ciklus utáni első utasításra kerül.
Az alábbi while ciklus kilép, ha megtalálja a megadott két egész szám legkisebb közös többszörösét:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
int a, b, lkt;
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
lkt = min(a,b);
while (lkt<=a*b) {
if (lkt % a == 0 && lkt % b == 0)
break;
lkt++;
}
cout << "Legkisebb kozos tobbszoros: " << lkt << endl;
}
A break utasítás használata kiküszöbölhető, ha a hozzá kapcsolódó if utasítás feltételét beépítjük a ciklus feltételébe, ami ezáltal sokkal bonyolultabb lesz:
while (lkt<=a*b && !(lkt % a == 0 && lkt % b == 0)) {
lkt++;
}
Ha a break utasítást egymásba ágyazott ciklusok közül a belsőben használjuk, akkor csak a belső ciklusból lépünk ki vele. Az alábbi példában megjelenítjük a prímszámokat 2 és maxn között. A kilépés okát egy logikai (flag, jelző) változó (prim) segítségével adjuk a külső ciklus tudtára:
#include <iostream>
using namespace std;
int main () {
const int maxn =2012;
int oszto;
bool prim;
for(int szam=2; szam<=maxn; szam++) {
prim = true;
for(oszto = 2; oszto <= (szam/oszto); oszto++) {
if (szam % oszto == 0) {
prim = false;
break; // van osztoja, nem prím
}
}
if (prim)
cout << szam << " primszam" << endl;
}
}
Ha feladat úgy hangzik, hogy keressük meg a legelső Pitagoraszi számhármast a megadott intervallumban, akkor találat esetén egyszerre két for ciklusból kell kilépnünk. Ekkor a legegyszerűbb megoldáshoz egy jelző (talalt) bevezetésével jutunk:
#include <iostream>
#include<cmath>
using namespace std;
int main () {
int bal, jobb;
cout <<"bal = "; cin >> bal;
cout <<"jobb = "; cin >> jobb;
bool talalt = false;
for(int a = bal, c, c2; a<=jobb && !talalt; a++) {
for(int b = bal; b<=jobb && !talalt; b++) {
c2 = a*a + b*b;
c = static_cast<int>(sqrt(float(c2)));
if (c*c == c2) {
talalt = true;
cout << a << ", " << b << ", " << c << endl;
} // if
} // for
} // for
} // main()
I.4.3.5. A continue utasítás
A continue utasítás elindítja a while, a for és a do-while ciklusok soron következő iterációját. Ekkor a ciklustörzsben a continue után elhelyezkedő utasítások nem hajtódnak végre.
A while és a do-while utasítások esetén a következő iteráció a ciklus feltételének ismételt kiértékelésével kezdődik. A for ciklus esetében azonban, a feltétel feldolgozását megelőzi a léptetés elvégzése.
A következő példában a continue segítségével értük el, hogy a 1-től maxn-ig egyesével lépkedő ciklusban csak a 7-tel vagy 12-gyel osztható számok jelenjenek meg:
#include <iostream>
using namespace std;
int main(){
const int maxn = 123;
for (int i = 1; i <= maxn; i++) {
if ((i % 7 != 0) && (i % 12 != 0))
continue;
cout<<i<<endl;
}
}
A break és a continue utasítások gyakori használata rossz programozói gyakorlat. Mindig érdemes átgondolnunk, hogy meg lehet-e valósítani az adott programszerkezetet vezérlésátadó utasítások nélkül. Az előző példában ezt könnyedén megtehetjük az if feltételének megfordításával:
for (int i = 1; i <= maxn; i++) {
if ((i % 7 == 0) || (i % 12 == 0))
cout<<i<<endl;
}
I.4.4. A goto utasítás
A fejezet lezárásaként nézzük meg a C++ nyelv vezérlésátadó utasításainak egy, még nem tárgyalt tagját! Már a break és a continue utasításoknál is óva intettünk a gyakori használattól, azonban ez hatványozottan igaz a goto utasításra.
A függvényeken belüli ugrásokra használható goto utasítás rászolgált a rossz hírnevére, ugyanis kuszává, áttekinthetetlenné teszi a forrásprogramot. Nem is beszélve egy ciklusba való beugrás tragikus következményeiről. Ezért kijelenthetjük, hogy strukturált, jól áttekinthető programszerkezet kialakítása során nem szabad goto utasítást használni. A legtöbb programfejlesztő cégnél ez egyenesen tilos.
A goto utasítás felhasználásához utasításcímkével kell megjelölnünk azt az utasítást, ahova később ugrani szeretnénk. Az utasításcímke valójában egy azonosító, amelyet kettősponttal választunk el az utána álló utasítástól:
utasításcímke: utasítás
A goto utasítás, amellyel a fenti címkével megjelölt sorra adhatjuk a vezérlést:
goto utasításcímke;
Bizonyos, jól megindokolt esetekben, például kiugrás egy nagyon bonyolult programszerkezetből, egyszerű megoldást biztosít a goto.
I.5. Kivételkezelés
Kivételnek (exception) nevezzük azt a hibás állapotot vagy eseményt, melynek bekövetkezte esetén az alkalmazás további, szabályszerű futása már nem lehetséges.
C nyelven a program minden kérdéses helyén felkészültünk a hibák helyi kezelésére. Általában ez egy hibaüzenet megjelenítését ( cerr ) jelentette, majd pedig a program futásának megszakítását ( exit ()). Például, ha a másodfokú egyenlet együtthatóinak bekérése után a másodfokú tag együtthatója 0, nem használható a megoldóképlet:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
double a, b, c;
cout<<" egyutthatok (szokozzel tagolva) :";
cin >> a >> b >> c;
if (0 == a) {
cerr << "Az egyenlet nem masodfoku!" << endl;
exit(-1);
}
cout <<a<<"x^2+"<<b<<"x+"<<c<<"=0"<< endl;
}
A C++ nyelv lehetővé teszi, hogy a kivételeket (hibákat) különböző típussal azonosítva, a hibakezelést akár egyetlen helyen végezzük el. A kivételek kezelése a megszakításos (termination) modell alapján történik, ami azt jelenti, hogy a kivételt kiváltó programrész (függvény) futása megszakad a kivétel bekövetkeztekor.
A szabványos C++ nyelv viszonylag kevés beépített kivételt tartalmaz, azonban a különböző osztálykönyvtárak előszeretettel alkalmazzák a kivételeket a hibás állapotok jelzésére. Kivételeket mi is kiválthatunk egy adott típusú érték „dobásával” (throw). A továbbított (dobott) kivételek a legközelebbi kezelőkhöz kerülnek, amelyek vagy “elkapják” (catch) vagy pedig továbbítják azokat.
A fentiekben vázolt működés csak akkor érvényesül, ha a hibagyanús kódrészletünket egy olyan utasításblokkba zárjuk, amely megkísérli (try) azt végrehajtani.
Az elmondottaknak megfelelően a C++ nyelv típusorientált kivételkezeléséhez az alábbi három elem szükséges:
-
kivételkezelés alatt álló programrész kijelölése (try-blokk),
-
a kivételek továbbítása (throw),
-
a kivételek „elfogása” és kezelése (catch).
I.5.1. A try – catch programszerkezet
A try-catch programstruktúra általános formája egyetlen try blokkot és tetszőleges számú catch blokkot tartalmaz:
try
{
// kivételfigyelés alatt álló utasítások
utasítások
}
catch (kivétel1 deklaráció) {
// a kivétel1 kezelője
utasítások1
}
catch (kivétel2 deklaráció) {
// a kivétel2 kezelője
utasítások2
}
catch (...) {
// minden más kivétel kezelője
utasítások3
}
// a sikeres kezelés utáni utasítások
utasítások4
Amennyiben a try (próbálkozás) blokk bármelyik utasítása kivételt okoz, az utasítások végrehajtása megszakad, és a vezérlés a try blokkot követő, megfelelő típusú catch blokkhoz adódik (ha van ilyen). Ha nincs megfelelő típusú kezelő, akkor a kivétel egy külső try blokkhoz tartozó kezelőhöz továbbítódik. A típusegyezés nélküli kivételek végső soron a futtató rendszerhez kerülnek (kezeletlen kivételként). Ezt a helyzetet egy angol nyelvű, szöveges üzenetet jelzi: „This application has requested the Runtime to terminate it in an unusual way. Please contact the application's support team for more information.”, ami arról tudósít, hogy a programunk nem a szokásos módon fejeződött be, és keressük fel az alkalmazás fejlesztőcsapatát további információért.
A catch kulcsszó után álló kivétel deklarációkat többféleképpen is megadhatjuk. Szerepelhet egy típus , egy változó deklaráció (típus azonosító) vagy három pont . Az eldobott kivételhez csak a 2. forma használatával férhetünk hozzá. A három pont az jelenti, hogy tetszőleges típusú kivételt fogadunk. Mivel a kivételek azonosítása a catch blokkok megadási sorrendjében történik, a három pontos alakot a lista végén adjuk meg.
Példaként alakítsuk át a bevezetőben szereplő program hibavizsgálatát kivételkezeléssé!
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
try {
double a, b, c;
cout<<" egyutthatok (szokozzel tagolva) :";
cin >> a >> b >> c;
if (0 == a) throw false;
cout <<a<<"x^2+"<<b<<"x+"<<c<<"=0"<< endl;
}
catch (bool) {
cerr << "Az egyenlet nem masodfoku!" << endl;
exit(-1);
}
catch (...) {
cerr << "Valami hiba tortent..." << endl;
exit(-1);
}
}
I.5.2. Kivételek kiváltása – a throw utasítás
A kivételkezelést a programunk adott részén belül, lokálisan kell kialakítanunk a try, a throw és a catch kulcsszavak felhasználásával. A kivételkezelés csak a próbálkozás blokkban megadott (illetve az abból hívott) kód végrehajtása esetén fejti ki hatását. A kijelölt kódrészleten belül a throw utasítással
throw kifejezés;
adhatjuk át a vezérlést a kifejezés típusának megfelelő kezelőnek (handler), amelyet a catch kulcsszót követően adunk meg.
Amikor egy kivételt a throw utasítással továbbítunk, akkor az utasításban megadott kifejezés értéke átmásolódik a catch fejlécében szereplő paraméterébe, így a kezelőben lehetőség nyílik ezen érték feldolgozására. Ehhez persze arra van szüksége, hogy a típus mellett egy azonosító is szerepeljen a catch utasításban.
A catch blokkban elhelyezett throw utasítással a kapott kivételt más kivétellé alakítva továbbíthatjuk, illetve a megkapott kivételt is továbbadhatjuk. Ez utóbbihoz a throw kifejezés nélküli alakját kell használnunk: throw;
Programjaink kivételkezelését igazából kivételosztályok definiálásával tehetjük teljessé. Az exception fejállomány tartalmazza az exception osztály leírását, amely a különböző logikai és futásidejű kivételek alaposztálya. Az osztályok what () függvénye megadja a kivétel szöveges leírását. Az alábbi táblázatban összefoglaltuk a C++ szabványos könyvtáraiban definiált osztályok által továbbított kivételeket. Minden kivétel alapját az exception osztály képezi.
|
Kivételosztályok |
Fejállomány |
||
|---|---|---|---|
|
exception |
<exception> |
||
|
bad_alloc |
<new> |
||
|
bad_cast |
<typeinfo> |
||
|
bad_typeid |
<typeinfo> |
||
|
logic_failure |
<stdexcept> |
||
|
domain_error |
<stdexcept> |
||
|
invalid_argument |
<stdexcept> |
||
|
length_error |
<stdexcept> |
||
|
out_of_range |
<stdexcept> |
||
|
runtime_error |
<stdexcept> |
||
|
range_error |
<stdexcept> |
||
|
overflow_error |
<stdexcept> |
||
|
underflow_error |
<stdexcept> |
||
|
ios_base::failure |
<ios> |
||
|
bad_exception |
<exception> |
||
Kivételosztályok segítségével egyszerű értékek helyett „okos” objektumokat továbbíthatunk kivételként. A szükséges ismereteket csak könyvünk III. fejezet fejezetében tárjuk az Olvasó elé.
Kényelmes hibakezelést biztosít, amikor csak szöveget továbbítunk kivételként. Így a program felhasználója mindig értelmes üzenetet kap a munkája során. (A sztringkonstansokat a következő fejezet const char * típusával azonosítjuk.)
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
int szam;
srand(unsigned(time(NULL)));
try {
while (true) {
szam = rand();
if (szam>1000)
throw "A szam tul nagy";
else if (szam<10)
throw "A szam tul kicsi";
cout << 10*szam << endl;
} // while
} // try
catch (const char * s) {
cerr << s << endl;
} // catch
} // main()
I.5.3. Kivételek szűrése
A C++ függvények is fontos szerepet játszanak a kivételkezelésben. Egy függvényben keletkező kivételeket általában a függvényen belül dolgozzuk fel, hisz ott van meg a feldolgozáshoz szükséges ismeret. Vannak azonban olyan kivételek is, amelyek a függvény sikertelen működését jelzik a függvény hívójának. Ezeket természetesen továbbítjuk a függvényen kívülre.
A függvény-definíció fejlécében a throw kulcsszó speciális alakjával megadhatjuk, hogy milyen típusú kivételek továbbítódjanak a függvényen kívüli kezelőhöz. Alaphelyzetben minden kivétel továbbítódik.
// minden kivétel továbbítódik int fv1(); // csak a bool típusú kivételek továbbítódnak int fv2() throw(char, bool); // a char és a bool típusú kivételek továbbítódnak int fv3() throw(bool); // egyetlen kivétel sem továbbítódik int fv4() throw();
Amikor egy olyan kivételt továbbítunk, amelynek nincs kezelője a programban, a futtató rendszer a terminate () függvényt aktivizálja, amely kilépteti a programunkat ( abort ()). Ha egy olyan kivételt továbbítunk, amelyik nincs benne az adott függvény által továbbítandó kivételek listájában, akkor az unexpected () rendszerhívás állítja le a programunkat. Mindkét kilépési folyamatba beavatkozhatunk saját kezelők definiálásával, melyek regisztrációját az except fejállományban deklarált set_termi nate (), illetve set_unexpected () függvényekkel végezhetjük el.
I.5.4. Egymásba ágyazott kivételek
Valamely próbálkozás blokkban egy másik try-catch kivételkezelő szerkezet is elhelyezhető, akár közvetlenül, akár közvetve, a próbálkozás blokkból hívott függvényben.
Példaként egy szöveges kivételt továbbítunk a belső próbálkozás blokkból. Ezt feldogozzuk a belső szerkezetben, majd továbbadjuk a kifejezés nélküli throw; felhasználásával. A külső szerkezetben véglegesen kezeljük azt.
#include <iostream>
using namespace std;
int main()
{
try {
try {
throw "kivetel";
}
catch (bool) {
cerr << "bool hiba" << endl;
}
catch(const char * s) {
cout << "belso " << s << endl;
throw;
}
}
catch(const char * s) {
cout << "kulso " << s << endl;
}
catch(...) {
cout << "ismeretlen kivetel" << endl;
}
}
A fejezet zárásaként tanulmányozzuk az alábbi számológép programot! A saját kivételeket felsorolásként hoztuk létre. A programból az x operátor megadásával léphetünk ki.
#include <iostream>
using namespace std;
enum nulloszt {NullavalOsztas};
enum hibasmuv {HibasMuvelet};
int main()
{
double a, b, e=0;
char op;
while (true) // kilepes, ha op x vagy X
{
cout << ':';
cin >>a>>op>>b;
try {
switch (op) {
case '+': e = a + b;
break;
case '-': e = a - b;
break;
case '*': e = a * b;
break;
case '/': if (b==0)
throw NullavalOsztas;
else
e = a / b;
break;
case 'x': case 'X' :
throw true;
default: throw HibasMuvelet;
}
cout << e <<endl;
} // try
catch (nulloszt) {
cout <<" Nullaval osztas" <<endl;
}
catch (hibasmuv) {
cout <<" Hibas muvelet" <<endl;
}
catch (bool) {
cout<<"Off"<<endl;
break; // while
}
catch(...) {
cout<<" Valami nem jo "<< endl;
}
} // while
}
I.6. Mutatók, hivatkozások és a dinamikus memóriakezelés
Minden program legértékesebb erőforrása a számítógép memóriája, hisz a program kódja mellett a közvetlenül elérhető (on-line) adataink is itt tárolódnak. Az eddigi példáinkban a memóriakezelést teljes mértékben a fordítóra bíztuk.
|
A fordító – a tárolási osztály alapján – a globális (extern) adatokat egybegyűjtve helyezi el egy olyan területen, amely a program futása során végig rendelkezésre áll. A lokális (auto) adatok a függvényekbe lépve jönnek létre a verem (stack) memóriablokkban, illetve törlődnek kilépéskor (I.13. ábra). Van azonban egy terület, az ún. halomterület (heap), ahol mi magunk helyezhetünk el változókat, illetve törölhetjük azokat, ha már nincs szükség rájuk. Ezek a - dinamikus módon - kezelt változók eltérnek az eddig használt változóktól, hisz nincs nevük. Rájuk a címüket tároló változókkal, a mutatókkal (pointerekkel) hivatkozhatunk. A C++ nyelv operátorok sorával is segíti a dinamikus memóriakezelést *, &, new, delete. |
 I.13. ábra - C++ program memóriahasználat
|
Az elmondottakon túlmenően nagyon sok területeken használunk mutatókat a C/C++ programokban: függvények paraméterezése, láncolt adatstruktúrák kezelése stb. A pointerek kizárólagos alkalmazását a C++ egy sokkal biztonságosabb típussal, a hivatkozással (referenciával) igyekszik ellensúlyozni.
I.6.1. Mutatók (pointerek)
Minden változó definiálásakor a fordító lefoglalja a változó típusának megfelelő méretű területet a memóriában, és hozzárendeli a definícióban szereplő nevet. Az esetek többségében a változónevet használva adunk értéket a változónak, illetve kiolvassuk a tartalmát. Van amikor ez a megközelítés nem elegendő, és közvetlenül a változó memóriabeli címét kell használnunk (például a scanf () könyvtári függvény hívása).
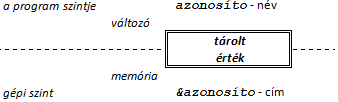
A mutatók segítségével tárolhatjuk, illetve kezelhetjük a változók (memóriában tárolt adatok) és függvények címét. Egy mutató azonban nemcsak címet tárol, hanem azt az információt is hordozza, hogy az adott címtől kezdve hány bájtot, hogyan kell értelmezni. Ez utóbbi pedig nem más, mint a hivatkozott adat típusa, amit felhasználunk a pointer(változó) definíciójában.
I.6.1.1. Egyszeres indirektségű mutatók
Először ismerkedjünk meg a mutatók leggyakrabban használt, és egyben legegyszerűbb formájával, az egyszeres indirektségű pointerekkel, melyek általános definíciója:
típus *azonosító;
A csillag jelzi, hogy mutatót definiálunk, míg a csillag előtti típus a hivatkozott adat típusát jelöli. A mutató automatikus kezdőértékére a szokásos szabályok érvényesek: 0, ha a függvényeken kívül hozzuk létre, és definiálatlan, ha valamely függvényen belül. Biztonságos megoldás, ha a mutatót a létrehozása után mindig inicializáljuk - a legtöbb fejállományban megtalálható - NULL értékkel:
típus *azonosító = NULL;
Több, azonos típusú mutató létrehozásakor a csillagot minden egyes azonosító előtt meg kell adni:
típus *azonosító1, *azonosító2;
A mutatókkal egy sor művelet elvégezhető, azonban létezik három olyan operátor, melyeket kizárólag pointerekkel használunk:
|
*ptr |
A ptr által mutatott objektum elérése. |
|
ptr->tag |
A ptr által mutatott struktúra adott tagjának elérése (I.8. szakasz fejezet). |
|
&balérték |
A balérték címének lekérdezése. |
Érthetőbbé válik a bevezetőben vázolt két szint, ha példa segítségével szemléltetjük az elmondottakat. Hozzunk létre egy egész típusú változót!
int x = 2;
A változó definiálásakor a memóriában (például az 2004-es címen) létrejön egy (int típusú) terület, amelybe bemásolódik a kezdőérték:

Az
int *p;
definíció hatására szintén keletkezik egy változó (például az 2008-as címen), melynek típusa int*. A C++ nyelv szóhasználatával élve a p egy int* típusú változó, vagy a p egy int típusú mutató. Ez a mutató int típusú változók címének tárolására használható, melyet például a „címe” & művelet során szerezhetünk meg, például:
p = &x;
A művelet után az x név és a *p érték ugyanarra a memóriaterületre hivatkoznak. (A *p kifejezés a „p által mutatott” tárolót jelöli.)
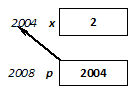
Ennek következtében a
*p = x +10;
kifejezés feldolgozása során az x változó értéke 12-re módosul.
Alternatív mutatótípus is létrehozható a typedef kulcsszó felhasználásával:
int x = 2; typedef int *tpi; tpi p = &x;
Egyetlen változóra több mutatóval is hivatkozhatunk, és a változó értékét bármelyik felhasználásával módosíthatjuk:
int x = 2; int * p, *pp; p = &x; pp = p; *pp += 10; // x tartalma ismét 12 lesz
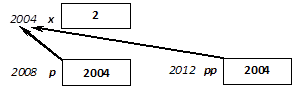
Ha egy mutatót eltérő típusú változó címével inicializálunk, fordítási hibát kapunk
long y = 0; char *p = &y; // hiba! ↯
Amennyiben nem tévedésről van szó, és valóban bájtonként szeretnénk elérni a long típusú adatot, a fordítót típus-átalakítással kérhetjük az értékadás elvégzésére:
long y = 0; char *p = (char *)&y;
vagy
char *p = reinterpret_cast<char *>(&y);
Gyakori, súlyos programhiba, ha egy mutatót inicializálás nélkül kezdünk el használni. Ez általában a program futásának megszakadását eredményezi:
int *p; *p = 1002; // ↯ ↯ ↯
I.6.1.2. Mutató-aritmetika
Mutató operandusokkal a már bemutatott (* és &) operátorokon túlmenően további műveleti jeleket is használhatunk. Ezeket a műveleteket összefoglaló néven pointer-aritmetikának nevezzük. Minden más művelet elvégzése definiálatlan eredményre vezet, így azokat javasolt elkerülni.
A megengedett pointer-aritmetikai műveleteket táblázatban foglaltuk össze, ahol a q és a p (nem void* típusú) mutatók, az n pedig egész (int vagy long):
|
Művelet |
Kifejezés |
Eredmény |
|---|---|---|
|
két, azonos típusú mutató kivonható egymásból |
q - p |
egész |
|
a mutatóhoz egész szám hozzáadható |
p + n, p++,++p, p += n, |
mutató |
|
a mutatóból egész szám kivonható |
p – n, p--, --p, p -= n |
mutató |
|
két mutató összehasonlítható |
p == q, p > q stb. |
bool (false vagy true) |
Amikor hozzáadunk vagy kivonunk egy egészet egy pointerhez/ből, akkor a fordító automatikusan skálázza az egészet a mutató típusának megfelelően, így a tárolt cím nem n bájttal, hanem
n * sizeof(pointertípus)
bájttal módosul, vagyis a mutató n elemnyit „lép” a memóriában.
Ennek megfelelően a léptető operátorok az aritmetikai típusokon kívül a mutatókra is alkalmazhatók, ahol azonban nem 1 bájttal való elmozdulást, hanem a szomszédos elemre való léptetést jelentik.
A pointer léptetése a szomszédos elemre többféle módon is elvégezhető:
int *p, *q; p = p + 1; p += 1; p++; ++p;
Az előző elemre való visszalépésre szintén több lehetőség közül választhatunk:
p = p - 1; p -= 1; p--; --p;
A két mutató különbségénél szintén érvényesül a skálázás, így a két mutató között elhelyezkedő elemek számát kapjuk eredményül:
int h = p - q;
I.6.1.3. A void * típusú általános mutatók
A C++ nyelv típus nélküli (void típusú), általános mutatók használatát is lehetővé teszi,
int x; void * ptr = &x;
amelyek csak címet tárolnak, így sohasem jelölnek ki változót.
A C++ nyelv a mutatókkal kapcsolatban két implicit konverziót biztosít. Tetszőleges típusú mutató átalakítható általános (void) típusú mutatóvá, valamint a nulla (0) számértékkel minden mutató inicializálható. Ellenkező irányú konverzióhoz explicit típusátalakítást kell használnunk.
Ezért, ha értéket szeretnénk adni a ptr által megcímzett változónak, akkor felhasználói típuskonverzióval típust kell rendelnünk a cím mellé. A típus-átalakítást többféleképpen is elvégezhetjük:
int x; void *ptr = &x; *(int *)ptr = 1002; typedef int * iptr; *iptr(ptr) = 1002; *static_cast<int *>(ptr) = 1002; *reinterpret_cast<int *>(ptr) = 1002;
Mindegyik indirekt módon elvégzett értékadást követően, az x változó értéke 1002 lesz.
Megjegyezzük, hogy a mutatót visszaadó könyvtári függvények többsége void* típusú.
I.6.1.4. Többszörös indirektségű mutatók
A mutatókat többszörös indirektségű kapcsolatok esetén is használhatjuk. Ekkor a mutatók definíciójában több csillag (*) szerepel:
típus * *mutató;
A mutató előtt közvetlenül álló csillag azt jelöli, hogy pointert definiálunk, és ami ettől a csillagtól balra található, az a mutató típusa (típus *). Ehhez hasonlóan tetszőleges számú csillagot értelmezhetünk, azonban megnyugtatásul megjegyezzük, hogy a C++ nyelv szabványos könyvtárának elemei is legfeljebb kétszeres indirektségű mutatókat használnak.
Tekintsünk néhány definíciót, és mondjuk meg, hogy mi a létrehozott változó!
|
int x; |
x egy int típusú változó, |
|
int *p; |
p egy int típusú mutató (amely int változóra mutathat), |
|
int * *q; |
q egy int* típusú mutató (amely int* változóra, vagyis egészre mutató pointerre mutathat). |
Alternatív (typedef) típusnevekkel a fenti definíciók érthetőbb formában is felírhatók:
typedef int *iptr; // iptr - egészre mutató pointer típusa iptr p, *q;
vagy
typedef int *iptr; // iptr - egészre mutató pointer típusa // iptr típusú változóra mutató pointer típusa typedef iptr *ipptr; iptr p; ipptr q;
|
A fenti definíciók megadása után az x = 2; p = &x; q = &p; x = x + *p + **q; utasítások végrehajtását követően az x változó értéke 6 lesz. |
|
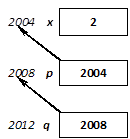
Megjegyezzük, hogy bonyolultabb pointeres kapcsolatok értelmezésében hasznos segítséget jelent a grafikus ábrázolás.
I.6.1.5. Konstans mutatók
A C++ fordító szigorúan ellenőrzi a const típusú konstansok felhasználását, például egy konstansra csak megfelelő mutatóval hivatkozhatunk:
const double pi = 3.141592565; // double adatra mutató pointer double *ppi = π // hiba! ↯
Konstansra mutató pointer segítségével az értékadás már elvégezhető:
// double konstansra mutató pointer const double *pdc; const double dc = 10.2; double d = 2012; pdc = &dc; // a pdc pointer a dc-re mutat
cout <<*pdc<<endl; // 10.2
pdc = &d; // a pdc pointert a d-re állítjuk
cout <<*pdc<<endl; // 2012
A pdc pointer felhasználásával a d változó értéke nem módosítható:
*pdc = 7.29; // hiba! ↯
Konstans értékű pointer, vagyis a mutató értéke nem változtatható meg:
int honap; // int típusú adatra mutató konstans pointer int *const akthonap = &honap; //
Az akthonap pointer értéke nem változtatható meg, de a *akthonap módosítható!
*akthonap = 9; cout<< honap << endl; // 9 akthonap = &honap; // hiba! ↯
Konstansra mutató konstans értékű pointer:
const int honap = 10; const int ahonap = 8; // int típusú konstansra mutató konstans pointer const int *const akthonap = &honap; cout << *akthonap << endl; // 10
Sem a mutató, sem pedig a hivatkozott adat nem változtatható meg!
akthonap = &ahonap; // hiba! ↯ *akthonap = 12 // hiba! ↯
I.6.2. Hivatkozások (referenciák)
A hivatkozási (referencia) típus felhasználásával már létező változókra hivatkozhatunk, alternatív nevet definiálva. A definíció általános formája:
típus &azonosító = változó;
Az & jelzi, hogy referenciát definiálunk, míg az & előtti típus a hivatkozott adat típusát jelöli, melynek egyeznie kell a kezdőértékként megadott változó típusával. Több azonos típusú hivatkozás készítésekor az & jelet minden referencia előtt meg kell adnunk:
típus &azonosító1 = változó1, &azonosító2 = változó2 ;
A referencia definiálásakor a balértékkel történő inicializálás kötelező. Példaként készítsünk hivatkozást az int típusú x változóra!
int x = 2; int &r = x;
Ellentétben a mutatókkal, a referencia tárolására általában nem jön létre külön változó. A fordító egyszerűen második névként egy új nevet ad az x változónak (r).

Ennek következtében az alábbi kifejezés kiértékelése után 12 lesz az x változó értéke:
r = x +10;
Míg a mutatók értéke, ezáltal a hivatkozott tároló bármikor megváltoztatható, az r referencia a változóhoz kötött.
int x = 2, y = 4; int &r = x; r = y; // normál értékadás cout << x << endl; // 4
Ha egy referenciát konstans értékkel, vagy eltérő típusú változóval inicializálunk fordítási hibát kapunk. Még az sem segít, ha a második esetben típus-átalakítást használunk. Az ilyen eseteket csak akkor kezeli a fordító, ha ún. konstans (csak olvasható) referenciát készítünk. Ekkor a fordító először létrehozza a hivatkozás típusával megegyező típusú tárolót, majd pedig inicializálja az egyenlőségjel után szereplő jobbérték kifejezés értékével.
const char &lf = '\n'; |
unsigned int b = 2004; const int &r = b; b = 2012; cout << r << endl; // 2004 |
Szinonim referenciatípus szintén létrehozható a typedef kulcsszó segítségével:
typedef int &rint; int x = 2; rint r = x;
Mutatóhoz referenciát más típusú változókhoz hasonlóan készíthetünk:
int n = 10; int *p = &n; // p mutató az n változóra int* &rp = p; // rp referencia a p mutatóra *rp = 4; cout << n << endl; // 4
Ugyanez a typedef segítségével:
typedef int *tpi; // egészre mutató pointer típusa typedef tpi &rtpi; // referencia egészre mutató pointerre int n = 10; tpi p = &n; rtpi rp = p;
Felhívjuk a figyelmet arra, hogy referenciához referenciát, illetve mutatót nem definiálhatunk.
int n = 10; int &r = n; int& *pr = &r; // hiba! ↯ int& &rr =r; // hiba! ↯ int *p = &r; // a p mutató az r referencián keresztül az n-re mutat
Referenciát bitmezőkhöz (I.8. szakasz) sem készíthetünk, sőt referencia elemeket tartalmazó tömböt (I.7. szakasz) sem hozhatunk létre.
A referencia típus igazi jelentőségét függvények készítésekor fogjuk megtapasztalni.
I.6.3. Dinamikus memóriakezelés
Általában nem azért használunk mutatókat, hogy más változókra mutassunk velük, bár ez sem elvetendő (lásd paraméterátadás). A mutatók a kulcs a C++ nyelv egyik fontos lehetőségéhez, az ún. dinamikus memóriakezeléshez. Ennek segítségével a program futásához szükséges tárolóterületeket mi foglaljuk le, amikor szükségesek, és mi szabadítjuk fel, amikor már nem kellenek.
A szabad memória (heap) dinamikus kezelése alapvető részét képezi minden programnak. A C nyelv könyvtári függvényeket biztosít a szükséges memóriafoglalási ( malloc (),...) illetve felszabadítási ( free ()) műveletekhez. A C++ nyelvben a new és delete operátorok nyelvdefiníció szintjén helyettesítik a fenti könyvtári függvényeket (bár szükség esetén azok is elérhetők).
A dinamikus memóriakezelés az alábbi három lépést foglalja magában:
-
egy szabad memóriablokk foglalása, a foglalás sikerességének ellenőrzésével,
-
a terület elérése mutató segítségével,
-
a lefoglalt memória felszabadítása.
I.6.3.1. Szabad memória foglalása és elérése
A dinamikus memóriakezelés első lépése egy szükséges méretű tárterület lefoglalása a szabad memóriából (heap). Erre a célra a new operátor áll rendelkezésünkre. A new operátor az operandusában megadott típusnak megfelelő méretű területet foglal a szabad memóriában, és a terület elejére mutató pointert ad eredményül. Szükség esetén kezdőértéket is megadhatunk a típust követő zárójelben.
mutató = new típus;
mutató = new típus(kezdőérték);
A new segítségével nemcsak egyetlen elemnek, hanem több egymás után elhelyezkedő elemnek is helyet foglalhatunk a memóriában. Ez így létrejövő adatstruktúrát dinamikus tömbnek nevezzük (I.7. szakasz).
mutató = new típus[elemszám];
Nézzünk néhány példát a new műveletre!
int main() {
int *p1;
double *p2;
p1 = new int(2);
p2 = new double;
}
Az definíció hatására a veremben létrejönnek a p1 és p2 mutatóváltozók. Az értékadásokat követően a halomterületen megszületik két dinamikus változó, melyek címe megjelenik a megfelelő mutatókban (I.14. ábra).
A memóriafoglalásnál, főleg amikor nagyméretű dinamikus tömb számára kívánunk tárterületet foglalni, előfordulhat, hogy nem áll rendelkezésünkre elegendő, összefüggő, szabad memória. A C++ futtatórendszer ezt a helyzetet a bad_alloc kivétel (exception fejállomány) létrehozásával jelzi. Így a kivételkezelés eszköztárát használva programunkat biztonságossá tehetjük.
#include <iostream>
#include <exception>
using namespace std;
int main() {
long * padat;
// Memóriafoglalás
try {
padat = new long;
}
catch (bad_alloc) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria!" << endl;
return -1; // Kilépünk a programból
}
// ...
// A lefoglalt memória felszabadítása
delete padat;
return 0;
}
Amennyiben nem kívánunk élni a kivételkezelés adta lehetőségekkel, a new operátor után meg kell adnunk a nothrow memóriafoglalót (new fejállomány). Ennek hatására a new operátor sikertelen tárfoglalás esetén a kivétel helyett 0 értékkel tér vissza.
#include <iostream>
#include <new>
using namespace std;
int main() {
long * padat;
// Memóriafoglalás
padat = new (nothrow)long;
if (0 == padat) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria!" << endl;
return -1; // Kilépünk a programból
}
// ...
// A lefoglalt memória felszabadítása
delete padat;
return 0;
}
Az alfejezet végén felhívjuk a figyelmet a new operátor egy további lehetőségére. A new után közvetlenül zárójelben megadott mutató is állhat, melynek hatására az operátor a mutató címével tér vissza (vagyis nem foglal memóriát):
int *p=new int(10); int *q=new(p) int(2); cout <<*p << endl; // 2
A fenti példákban a q pointer a p által mutatott területre hivatkozik. A mutatók eltérő típusúak is lehetnek:
long a = 0x20042012; short *p = new(&a) short; cout << hex <<*p << endl; // 2012
I.6.3.2. A lefoglalt memória felszabadítása
A new operátorral lefoglalt memóriablokkot a delete operátorral szabadíthatjuk fel:
delete mutató;
delete[] mutató;
A művelet első formáját egyetlen dinamikus változó felszabadítására, míg a második alakot dinamikus tömbök esetén használjuk.
A delete művelet 0 értékű mutatók esetén is helyesen működik. Minden más, nem new-val előállított érték esetén a delete működése megjósolhatatlan.
A tárterület felszabadításával az előző rész bevezető példája teljessé tehető:
int main() {
int *p1;
double *p2;
p1 = new int(2);
p2 = new double;
delete p1;
delete p2;
p1 = 0;
p2 = 0;
}
I.7. Tömbök és sztringek
Az eddigi példáink változói egyszerre csak egy érték (skalár) tárolására voltak alkalmasak. A programozás során azonban gyakran van arra szükség, hogy több, azonos vagy különböző típusú elemekből álló adathalmazt a memóriában tároljunk, és azon műveleteket végezzünk. C++ nyelven a származtatott típusok közé tartozó tömb és felhasználói típusok (struct, class, union – I.8. szakasz) segítségével hatékonyan megoldhatjuk ezeket a feladatokat.
I.7.1. A C++ nyelv tömbtípusai
A tömb (array) azonos típusú adatok (elemek) halmaza, amelyek a memóriában folytonosan helyezkednek el. Az elemek elérése a tömb nevét követő indexelés operátor(ok)ban ( [] ) megadott elemsorszám(ok) (index(ek)) segítségével történik, mely(ek) kezdőértéke mindig 0.
A leggyakrabban használt tömbtípus egyetlen kiterjedéssel (dimenzióval) rendelkezik – egydimenziós tömb (vektor) Amennyiben az adatainkat több egész számmal kívánjuk azonosítani, a tárolásra többdimenziós tömböket vehetünk igénybe. Ezek közül könyvünkben csak a második leggyakoribb, kétdimenziós tömbtípussal (mátrix) foglalkozunk részletesen, mely elemeinek tárolása soronként (sorfolytonosan) történik.
Mielőtt rátérnék a kétféle tömbtípus tárgyalására, nézzük általánosan a tömbtípus használatát! Az n-dimenziós tömb definíciója:
elemtípus tömbnév[méret 1 ][méret 2 ][méret 3 ]…[méret n-1 ][méret n ]
ahol a méret i az i-dik kiterjedés méretét határozza meg. Az elemekre való hivatkozáshoz minden dimenzióban meg kell adni egy sorszámot a 0, méret i -1 zárt intervallumon:
tömbnév[index 1 ][index 2 ][index 3 ]…[index n-1 ][index n ]
Így, első látásra igen ijesztőnek tűnhet a tömbtípus, azonban egyszerűbb esetekben igen hasznos és kényelmes adattárolása megoldás jelent.
I.7.1.1. Egydimenziós tömbök
Az egydimenziós tömbök definíciójának formája:
elemtípus tömbnév[méret];
A tömbelemek típusát meghatározó elemtípus a void és a függvénytípusok kivételével tetszőleges típus lehet. A szögletes zárójelek között megadott méretnek a fordító által kiszámítható konstans kifejezésnek kell lennie. A méret a tömbben tárolható elemek számát definiálja. Az elemeket 0-tól (méret-1)-ig indexeljük.

Példaként tekintsünk egy 7-elemű egész tömböt, melynek egész típusú elemeit az indexek négyzetével töltjük fel (I.15. ábra)! Helyes gyakorlat a tömbméret konstansban való tárolása. Az elmondattak alapján a negyzet tömb definíciója:
const int maxn =7; int negyzet[maxn];
A tömb elemeinek egymás után történő elérésére általában a for ciklust használjuk, melynek változója a tömb indexe. (A ciklus helyes felírásában az index 0-tól kisebb, mint a méret fut). A tömb elemeire az indexelés operátorával ([]) hivatkozunk.
for (int i = 0; i< maxn; i++)
negyzet[i] = i * i;
A negyzet tömb számára lefoglalt memóriaterület bájtban kifejezett mérete a sizeof (negyzet) kifejezéssel pontosan lekérdezhető, míg a sizeof (negyzet[0]) kifejezés egyetlen elem méretét adja meg. Így a két kifejezés hányadosából (egész osztás) mindig megtudható a tömb elemeinek száma:
int elemszam = sizeof(negyzet) / sizeof(negyzet[0]);
Felhívjuk a figyelmet arra, hogy a C++ nyelv semmilyen ellenőrzést nem végez a tömb indexeire vonatkozóan. Az indexhatár átlépése a legkülönbözőbb futás közbeni hibákhoz vezethet, melyek felderítése sok időt vehet igénybe.
double oktober [31]; oktober [-1] = 0; // hiba ↯ oktober [31] = 0; // hiba ↯
Az alábbi példában egy 5-elemű vektorba beolvasott float számokat átlagoljuk, majd kiírjuk az átlagot és az egyes elemek eltérését ettől az átlagtól.
#include <iostream>
using namespace std;
const int maxn = 5 ;
int main()
{
float szamok[maxn], atlag = 0.0;
for (int i = 0; i <maxn; i++)
{
cout<<"szamok["<< i <<"] = ";
cin>>szamok[i]; // az elemek beolvasása
atlag += szamok[i]; // az elemek összegzése
}
cin.get();
atlag /= maxn; // az átlag kiszámítása
cout<< endl << "Az atlag: " << atlag << endl;
// az eltérések kiírása
for (int i = 0; i <maxn; i++) {
cout<< i << ".\t" << szamok[i];
cout<< '\t' << atlag-szamok[i] << endl;
}
}
A program futási eredményének tanulmányozásakor felhívjuk a figyelmet az adatbevitel megvalósítására. A tömböket csak elemenként olvashatjuk be, és elemenként jeleníthetjük meg.
szamok[0] = 12.23 szamok[1] = 10.2 szamok[2] = 7.29 szamok[3] = 11.3 szamok[4] = 12.7 Az atlag: 10.744 0. 12.23 -1.486 1. 10.2 0.544001 2. 7.29 3.454 3. 11.3 -0.556 4. 12.7 -1.956 |
I.7.1.1.1. Az egydimenziós tömbök inicializálása és értékadása
A C++ nyelv lehetővé teszi, hogy a tömbelemeknek kezdőértéket adjunk. A tömbdefinícióban az egyenlőség jel után, kapcsos zárójelek között megadott inicializációs lista értékeit a tömbelemek a tárolási sorrendjüknek megfelelően veszik fel:
elemtípus tömbnév[méret] = { vesszővel tagolt inicilizációs lista };
Nézzünk néhány példát vektorok inicializálására!
int primek[10] = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 27 };
char nev[8] = { 'I', 'v', 'á', 'n'};
double szamok[] = { 1.23, 2.34, 3.45, 4.56, 5.67 };
A primek esetében vigyáztunk, és pontosan az elemszámnak megfelelő számú értéket adtunk meg. Ha véletlenül a szükségesnél több kezdőérték szerep a listában, a fordító hibával jelzi azt.
A második példában az inicializációs lista a tömb elemeinek számánál kevesebb értéket tartalmaz. Ekkor a nev tömb első 4 eleme felveszi a megadott értékeket, míg a többi elem értéke 0 lesz. Ezt kihasználva bármekkora tömböt egyszerűen nullázhatunk:
int nagy[2013] = {0};
Az utolsó példában a szamok tömb elemeinek számát az inicializációs listában megadott konstansok számának (5) megfelelően állítja be a fordítóprogram. Jól használható ez a megoldás, ha a tömb elemeit fordításonként változtatjuk. Ekkor az elemek számát a fentiekben bemutatott módszerrel tudhatjuk meg:
double szamok[] = { 1.23, 2.34, 3.45, 4.56, 5.67 };
const int nszam = sizeof(szamok) / sizeof(szamok[0]);
Az inicializációs lista tetszőleges futásidejű kifejezést is tartalmazhat:
double eh[3]= { sqrt(2.3), exp(1.2), sin(3.14159265/4) };
Tömbök gyors, de kevésbé biztonságos kezeléséhez a cstring fejállományban deklarált „mem” kezdetű könyvtári függvényeket is használhatjuk. A memset () függvény segítségével char tömböket tölthetünk fel azonos karakterekkel, illetve bármilyen típusú tömböt 0 értékű bájtokkal:
char vonal[80]; memset( vonal, '=', 80 ); double merleg[365]; memset( merleg, 0, 365*sizeof(double) ); // vagy memset( merleg, 0, sizeof(merleg) );
Ez utóbbi példa felvet egy jogos kérdést, hogy az indexelésen és a sizeof operátoron kívül milyen C++ műveleteket használhatunk a tömbökkel. A válasz gyors és igen tömör, semmilyet. Ennek oka, hogy a C/C++ nyelvek a tömbneveket konstans értékű pointerként kezelik, melyeket a fordító állít be. Ezt memset () hívásakor ki is használtuk, hisz a függvény első argumentumaként egy mutatót vár.
Két azonos típusú és méretű tömb közötti értékadás elvégzésére kétfele megoldás közül is választhatunk. Első esetben a for ciklusban végezzük az elemek átmásolását, míg második megoldásban a könyvtári memcpy () könyvtári függvényt használjuk.
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
const int maxn = 8 ;
int forras[maxn]= { 2, 10, 29, 7, 30, 11, 7, 12 };
int cel[maxn];
for (int i=0; i<maxn; i++) {
cel[i] = forras[i]; // elemek másolása
}
// vagy
memcpy(cel, forras, sizeof(cel));
}
A memcpy () nem mindig működik helyesen, ha a forrás- és a célterület átfedésben van, például amikor a tömb egy részét kell elmozdítani, helyet felszabadítva egy új elemnek. Ekkor is két lehetőségünk van, a for ciklus, illetve a memmove () könyvtári függvény. Az alábbi példa rendezett tömbjének az 1 indexű pozíciójába szeretnénk egy új elemet beszúrni:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
const int maxn = 10 ;
int rendezett[maxn]= { 2, 7, 12, 23, 29 };
for (int i=5; i>1; i--) {
rendezett[i] = rendezett[i-1]; // elemek másolása
}
rendezett[1] = 3;
// vagy
memmove(rendezett+2, rendezett+1, 4*sizeof(int));
rendezett[1] = 3;
}
Megjegyezzük, hogy a cél- és a forrásterület címét a pointer-aritmetikát használva adtuk meg: rendezett+2, rendezett+1.
I.7.1.1.2. Egydimenziós tömbök és a typedef
Mint már említettük a programunk olvashatóságát nagyban növeli, ha a bonyolultabb típusneveket szinonim nevekkel helyettesítjük. Erre származtatott típusok esetén is a typedef biztosít lehetőséget.
Legyen a feladatunk két 3-elemű egész vektor vektoriális szorzatának számítása, és elhelyezése egy harmadik vektorban! A számításhoz az alábbi összefüggést használjuk:
|
|
||
|
|
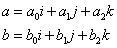
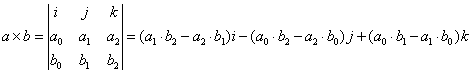
A feladat megoldásához szükséges tömböket kétféleképpen is létrehozhatjuk:
int a[3], b[3], c[3];
vagy
typedef int vektor3[3]; vektor3 a, b, c;
Az a és b vektorokat konstansokkal inicializáljuk:
typedef int vektor3[3];
vektor3 a = {1, 0, 0}, b = {0, 1, 0}, c;
c[0] = a[1]*b[2] - a[2]*b[1];
c[1] = -(a[0]*b[2] - a[2]*b[0]);
c[2] = a[0]*b[1] - a[1]*b[0];
Ugyancsak segít a typedef, ha például egy 12-elemű double elemeket tartalmazó tömbre pointerrel szeretnénk hivatkozni. Első gondolatunk a
double *xp[12];
típus felírása. A típuskifejezések értelmezésénél is az operátorok elsőbbségi táblázata lehet segítségünkre (A.7. szakasz függelék). Ez alapján az xp először egy 12-elemű tömb, és a tömbnév előtt az elemek típusa szerepel. Ebből következik xp 12-elemű mutatótömb. Az értelmezés sorrendjét zárójelekkel módosíthatjuk:
double (*xp)[12];
Ekkor xp először egy mutató, és a hivatkozott adat típusa double[12], vagyis 12-elemű double tömb. Készen vagyunk! Azonban sokkal gyorsabban és biztonságosabban célt érünk a typedef felhasználásával:
typedef double dvect12[12]; dvect12 *xp; double a[12]; xp = &a; (*xp)[0]=12.3; cout << a[0]; // 12.3
I.7.1.2. Kétdimenziós tömbök
Műszaki feladatok megoldása során szükség lehet arra, hogy mátrixokat számítógépen tároljunk. Ehhez a többdimenziós tömbök legegyszerűbb formáját, a kétdimenziós tömböket használhatjuk
elemtípus tömbnév[méret1][méret2];
ahol dimenziónként kell megmondani a méreteket. Példaként tároljuk az alábbi 3x4-es, egész elemeket tartalmazó mátrixot kétdimenziós tömbben!
|
|

A definíciós utasításban többféleképpen is megadhatjuk a mátrix elemeit, csak arra kell ügyelnünk, hogy sorfolytonos legyen a megadás.
int matrix[3][4] = { { 12, 23, 7, 29 },
{ 11, 30, 12, 7 },
{ 10, 2, 20, 12 } };
A tömb elemeinek eléréséhez az indexelés operátorát használjuk méghozzá kétszer. A
matrix[1][2]
hivatkozással a 1. sor 2. sorszámú elemét (12) jelöljük ki. (Emlékeztetünk arra, hogy az indexek értéke minden dimenzióban 0-val kezdődik!)
A következő ábrán (I.16. ábra) a kétdimenziós matrix tömb elemei mellett feltüntettük a sorok és az oszlopok (s/o) indexeit is.
A következő programrészletben megkeressük a fenti matrix legnagyobb (maxe) és legkisebb (mine) elemét. A megoldásban, a kétdimenziós tömbök feldolgozásához használt, egymásba ágyazott for ciklusok szerepelnek:
int maxe, mine;
maxe = mine = matrix[0][0];
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
if (matrix[i][j] > maxe )
maxe = matrix[i][j];
if (matrix[i][j] < mine )
mine = matrix[i][j];
}
}
A kétdimenziós tömbök mátrixos formában való megjelenítését az alábbi tipikus kódrészlet végzi:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++)
cout<<'\t'<<matrix[i][j];
cout<<endl;
}
I.7.1.3. Változó hosszúságú tömbök
A korábbi C++ szabvány szerint a tömbök a fordítás során jönnek létre, a méretet definiáló konstans kifejezések felhasználásával. A C++11 szabvány (Visual C++ 2012) a változó méretű tömbök (variable-length array) bevezetésével bővíti a tömbök használatának lehetőségeit. A futásidőben létrejövő változó hosszúságú tömb csak automatikus élettartamú, lokális változó lehet, és a definíciója nem tartalmazhat kezdőértéket. Mivel az ilyen tömbök csak függvényben használhatók, elképzelhető, hogy a tömbök mérete minden híváskor más és más - innen az elnevezés.
A változó hosszúságú tömb méretét tetszőleges egész típusú kifejezéssel megadhatjuk, azonban a létrehozást követően a méret nem módosítható. A változóméretű tömbökkel a sizeof operátor futásidejű változatát alkalmazza a fordító.
Az alábbi példában a tömb létrehozása előtt bekérjük annak méretét:
#include <iostream>
using namespace std;
int main() {
int meret;
cout << "A vektor elemeinek szama: ";
cin >> meret;
int vektor[meret];
for (int i=0; i<meret; i++) {
vektor[i] = i*i;
}
}
I.7.1.4. Mutatók és a tömbök kapcsolata
A C++ nyelvben a mutatók és a tömbök között szoros kapcsolat áll fenn. Minden művelet, ami tömbindexeléssel elvégezhető, mutatók segítségével szintén megvalósítható. Az egydimenziós tömbök (vektorok) és az egyszeres indirektségű („egycsillagos”) mutatók között teljes a tartalmi és a formai analógia. A többdimenziós tömbök és a többszörös indirektségű („többcsillagos”) mutatók esetén ez a kapcsolat csak formai.
Nézzük meg, honnan származik ez a vektorok és az egyszeres indirektségű mutatók között fennálló szoros kapcsolat! Definiáljunk egy 5-elemű egész vektort!
int a[5];
A vektor elemei a memóriában adott címtől kezdve folytonosan helyezkednek el. Mindegyik elemre a[i] formában hivatkozhatunk (I.17. ábra). Vegyünk fel egy p, egészre mutató pointert, majd a „címe” operátor segítségével állítsuk az a tömb elejére (a 0. elemre)!
int *p; p = &a[0]; vagy p = a;
A mutató beállítására a tömb nevét is használhatjuk, hisz az is egy int * típusú mutató, csak éppen nem módosítható. (Fordítási hibához vezet azonban a p = &a; kifejezés, hisz ekkor a jobb oldal típusa int (*)[5].)
Ezek után, ha hivatkozunk a p mutató által kijelölt (*p) változóra, akkor valójában az a[0] elemet érjük el.
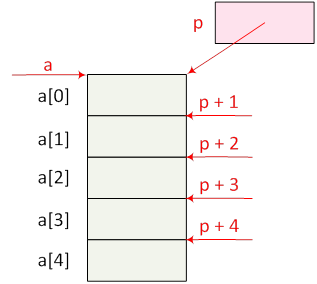
A mutatóaritmetika szabályai alapján a p+1, a p+2 stb. címek a p által kijelölt elem után elhelyezkedő elemeket jelölik ki. (Megjegyezzük, hogy negatív számokkal a változót megelőző elemeket címezhetjük meg.) Ennek alapján a *(p+i) kifejezéssel a tömb minden elemét elérhetjük:
A p mutató szerepe teljesen megegyezik az a tömbnév szerepével, hisz mindkettő az elemek sorozatának kezdetét jelöli ki a memóriában. Lényeges különbség azonban a két mutató között, hogy míg a p mutató változó (tehát értéke tetszőlegesen módosítható), addig az a egy konstans értékű mutató, amelyet a fordító rögzít a memóriában.
Az I.17. ábra jelöléseit használva, az alábbi táblázat soraiban szereplő hivatkozások azonosak:
|
|
A tömb i-dik elemének címe: |
|||||
|
|
|
|
|
|||
|
A tömb 0-dik eleme: |
||||||
|
|
|
|
|
|
|
|
|
A tömb i-dik eleme: |
||||||
|
|
|
|
|
|||
A legtöbb C++ fordító az a[i] hivatkozásokat automatikusan *(a+i) alakúra alakítja, majd ezt a pointeres alakot lefordítja. Az analógia azonban visszafelé is igaz, vagyis az indirektség (*) operátora helyett mindig használhatjuk az indexelés ([]) operátorát.
Többdimenziós esetben az analógia csak formai, azonban sok esetben ez is segíthet bonyolult adatszerkezetek helyes kezelésében. Példaként tekintsük az alábbi valós mátrixot:
double m[2][3] = { { 10, 2, 4 },
{ 7, 2, 9 } };
A tömb elemei a memóriában sorfolytonosan helyezkednek el. Ha az utolsó dimenziót elhagyjuk, a kijelölt sor mutatójához jutunk: m[0], m[1], míg a tömb m neve a teljes tömbre mutat (I.18. ábra). Megállapíthatjuk, hogy a kétdimenziós tömb valójában egy olyan vektor (egydimenziós tömb), melynek elemei vektorok (mutatók). Ennek ellenére a többdimenziós tömbök mindig folytonos memóriaterületen helyezkednek el. A példánkban a kezdőértékként megadott mátrix sorai képezik azokat a vektorokat, amelyekből az m vektor felépül.
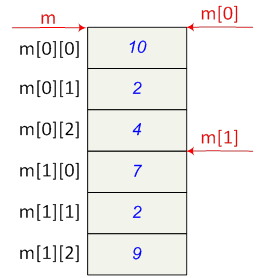
Használva a vektorok és a mutatók közötti formai analógiát, az indexelés operátorai minden további nélkül átírhatók indirektség operátorává. Az alábbi kifejezések mindegyike a kétdimenziós m tömb ugyanazon elemére (9) hivatkozik:
m[1][2] *(m[1] + 2) *(*(m+1)+2)
I.7.2. Dinamikus helyfoglalású tömbök
A tömbök segítségével nagymennyiségű adatot egyszerűen és hatékonyan tárolhatunk, illetve feldolgozhatunk. A hagyományos tömbök használatának azonban nagy hátránya, hogy méretük már a fordítás során eldől, és csak futás közben derül ki, ha túl nagy memóriát igényeltünk. Különösen igaz ez a függvényekben létrehozott lokális tömbökre.
Általános szabály, hogy függvényen belül, csak kisméretű tömböket definiáljunk. Amennyiben nagyobb adatmennyiséget kell tárolnunk, alkalmazzuk a dinamikus memóriafoglalás eszközeit, hisz a halomterületen sokkal több szabad tárterület áll a rendelkezésünkre, mint a veremben.
Emlékeztetőül, a new operátor segítségével nemcsak egyetlen elemnek, hanem több egymás után elhelyezkedő elemnek is helyet foglalhatunk a memóriában. Ebben az esetben a lefoglalt tárterület felszabadításához a delete[] operátor kell használnunk.
A dinamikus memóriafoglalás és felszabadítás műveletei szabványos könyvtári függvények formájában is jelen vannak a C/C++ nyelvben. A függvények eléréséhez az cstdlib fejállományt kell a programunkba építeni. A malloc () függvény adott bájtméretű területet foglal le, és visszaadja a terület kezdőcímét. A calloc () hasonlóan működik, azonban a tárterület méretét elemszám, elemméret formában kell megadni, és nullázza a lefoglalt memóriablokkot. A realloc () újraméretezi a már lefoglalt memóriaterületet, megőrizve annak eredeti tartalmát (ha nagyobbat foglalunk). A free () függvényt a lefoglalt területet felszabadítására használjuk.
Amennyiben objektumokat kezelünk a programunkban, a new és a delete operátorokat kell alkalmaznunk, a hozzájuk kapcsolódó kiegészítő működés elérése érdekében.
I.7.2.1. Egydimenziós dinamikus tömbök
Leggyakrabban egydimenziós, dinamikus tömböket használunk a programozási feladatok megoldása során.
típus *mutató;
mutató = new típus [elemszám];
vagy
mutató = new (nothrow) típus [elemszám];
A különbség a kétféle megoldás között csak sikertelen foglalás esetén tapasztalható. Az első esetben a rendszer kivétellel ( bad_alloc ) jelzi, ha nem áll rendelkezésre a kívánt méretű, folytonos tárterület, míg a második formával 0 értékű pointert kapunk.
Tömbök esetén különösen fontos, hogy ne feledkezzünk meg a lefoglalt memória szabaddá tételéről:
delete [] mutató;
Az alábbi példában a felhasználótól kérjük be a tömb méretét, helyet foglalunk a tömb számára, majd pedig feltöltjük véletlen számokkal.
#include <iostream>
#include <exception>
#include <ctime>
#include <cstdlib>
using namespace std;
int main() {
long *adatok, meret;
cout << "\nKerem a tomb meretet: ";
cin >> meret;
cin.get();
// Memóriafoglalás
try {
adatok = new long [meret];
}
catch (bad_alloc) {
// Sikertelen foglalás
cerr << "\nNincs eleg memoria !\n" << endl;
return -1; // Kilépünk a programból
}
// A tömb feltöltése véletlen számokkal
srand(unsigned(time(0)));
for (int i=0; i<meret; i++) {
adatok[i] = rand() % 2012;
// vagy *(adatok+i) = rand() %2012;
}
// A lefoglalt memória felszabadítása
delete[] adatok;
return 0;
}
I.7.2.2. Kétdimenziós dinamikus tömbök
Már a korábbi részekben is említettük, hogy a kétdimenziós tömbök valójában egydimenziós vektorok (a sorok) vektora. Ennek következménye, hogy nem tudunk akármekkora kétdimenziós tömböt futás közben létrehozni, hisz a fordítónak ismernie kell az elemek (sorvektorok) típusát (méretét). Az elemek (sorok) száma azonban tetszőlegesen megadható. A new az alábbi példában is egy mutatót ad vissza, ami a létrehozott kétdimenziós tömbre mutat.
const int sorhossz = 4; int sorokszama; cout<<"Sorok szama: "; cin >> sorokszama; int (*mp)[sorhossz] = new int [sorokszama][sorhossz];
Sokkal érthetőbb a megoldás, ha segítségül hívjuk a typedef kulcsszót:
const int sorhossz = 4; int sorokszama; cout<<"Sorok szama: "; cin >> sorokszama; typedef int sortipus[sorhossz]; sortipus *mp = new sortipus [sorokszama];
Bármelyik megoldást is választjuk, az egész elemek nullázására az alábbi ciklusokat használhatjuk:
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
mp[i][j]=0;
ahol mp[i] kijelöli az i-dik sort, az mp[i][j] pedig az i-dik sor j-dik elemét. A fenti utasításokat a main () függvénybe helyezve, az mp mutató a veremben jön létre, míg a teljes kétdimenziós tömb a halomterületen. A megoldásunk két szépséghibával rendelkezik: a tömb számára folytonos tárterületre van szükség, másrészt pedig zavaró a sorok hosszának fordítás közben való megadása.
Nézzük meg, miként küszöbölhetjük ki a folytonos memóriaterület és a rögzített sorhossz adta korlátozásokat! A következő két megoldás alapját az adja, hogy a mutatókból is készíthetünk tömböket.
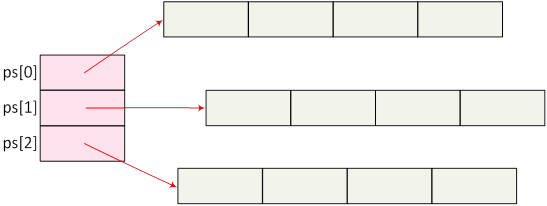
Az első esetben a sorok számát rögzítő mutatótömböt a veremben hozzuk létre, és csak a sorvektorok jönnek létre dinamikusan (I.19. ábra).
-
A sorokat kijelölő háromelemű mutatóvektor:
int* ps[3]= {0}; -
A sorok dinamikus létrehozása 4-elemű sorokat feltételezve:
for (int i=0; i<3; i++) ps[i] = new int[4]; -
Az elemeket a * és az [] operátorok segítségével egyaránt elérhetjük:
*(ps[1] + 2) = 123; cout << ps[1][2];
-
Végül ne feledkezzünk meg a dinamikusan foglalt területek felszabadításáról!
for (int i=0; i<3; i++) delete[] ps[i];
Amennyiben a sorok és az oszlopok számát egyaránt futás közben szeretnénk beállítani, az előző megoldás mutatótömbjét is dinamikusan kell létrehoznunk. Ekkor a verem egyetlen int * típusú mutatót tartalmaz (I.20. ábra).
A memória foglalása, elérése és felszabadítása jól nyomom követhető az alábbi példaprogramban:
#include <iostream>
using namespace std;
int main() {
int sorokszama, sorhossz;
cout<<"Sorok szama : "; cin >> sorokszama;
cout<<"Sorok hossza: "; cin >> sorhossz;
// Memóriafoglalás
int* *pps;
// A mutatóvektor létrehozása
pps = new int* [sorokszama];
// A sorok foglalása
for (int i=0; i<sorokszama; i++)
pps[i] = new int [sorhossz];
// A tömb elérése
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
pps[i][j]=0;
// A memória felszabadítása
for (int i=0; i<sorokszama; i++)
delete pps[i];
delete pps;
}
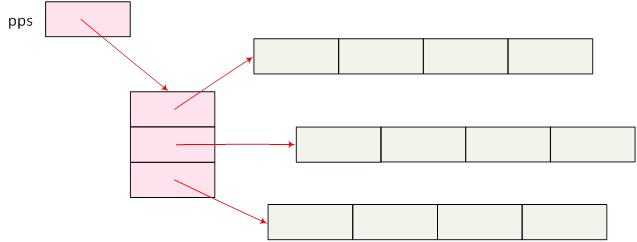
I.7.3. A vector típus használata
Napjaink C++ programjaiban a hagyományos egy- és kétdimenziós tömbök helyett egyre inkább teret hódít a C++ szabványos sablonkönyvtárának (STL) vector típusa. Ez a típus minden olyan jellemzővel (újraméretezés, indexhatár-ellenőrzés, automatikus memória-felszabadítás) rendelkezik, amelyek teljesen biztonságossá teszik a tömbök használatát.
A vector típus az eddig használt típusokkal szemben egy paraméterezhető típus, ami azt jelenti, hogy a tárolt elemek típusát vector szó után <> jelek között kell megadnunk. A létrehozott vektor - a cout és cin objektumokhoz hasonlóan - szintén objektum, melyhez műveletek és függvények egyaránt tartoznak.
I.7.3.1. Egydimenziós tömbök a vektorban
A vector típussal - a nevének megfelelően - az egydimenziós tömböket helyettesíthetjük. A típus teljes eszköztárának bemutatása helyett, néhány alapfogásra korlátozzuk az ismerkedést.
Nézzünk néhány vektordefiniálási megoldást, melyekhez a vector fejállomány kell a programunkba beépíteni!
vector<int> ivektor; ivektor.resize(10); vector<long> lvektor(12); vector<float> fvector(7, 1.0);
Az ivektor egy üres vektor, melynek méretét a resize () függvénnyel 10-re állítjuk. Az lvektor 12 darab long típusú elemet tartalmaz. Mindkét esetben az elemek 0 kezdőértéket kapnak. Az fvektor 7 darab float típusú elemmel jön létre, melyek mindegyike 1.0 értékkel inicializálódik.
A vektor aktuális elemszámát a size () függvénnyel bármikor lekérdezhetjük, az elemek elérésére pedig a szokásos indexelés operátorát használhatjuk. A vector típus érdekes lehetősége, hogy az elemeit akár egyesével is bővíthetjük a push_back () hívással.
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> ivektor(10, 5);
ivektor.push_back(10);
ivektor.push_back(2);
for (unsigned index=0; index<ivektor.size(); index++) {
cout << ivektor[index] << endl;
}
}
Megjegyezzük, hogy az STL adattárolók használata az előre definiált algoritmusokkal válik teljessé ( algorithm fejállomány).
I.7.3.2. Kétdimenziós tömb vektorokban
A vector típusok egymásba ágyazásával kétdimenziós, dinamikus tömböket is létrehozhatunk, az eddigieknél sokkal egyszerűbb módon.
#include <iostream>
#include <vector>
using namespace std;
int main() {
int sorokszama, sorhossz;
cout<<"Sorok szama : "; cin >> sorokszama;
cout<<"Sorok hossza: "; cin >> sorhossz;
vector< vector<int> > m (sorokszama, sorhossz);
// A tömb elérése
for (int i=0; i<sorokszama; i++)
for (int j=0; j<sorhossz; j++)
m[i][j]= i+j;
}
I.7.4. C-stílusú sztringek kezelése
A C/C++ nyelv az alaptípusai között nem tartalmazza a karaktersorozatok tárolására alkalmas sztring típust. Mivel azonban a szövegek tárolása és feldolgozása elengedhetetlen része a C/C++ programoknak, a tároláshoz egydimenziós karaktertömböket használhatunk. A feldolgozáshoz szükséges még egy megegyezés, ami szerint az értékes karaktereket mindig egy 0 értékű bájt zárja a tömbben. A sztringek kezelését operátorok ugyan nem segítik, azonban egy gazdag függvénykészlet áll a rendelkezésünkre (lásd cstring fejállomány).
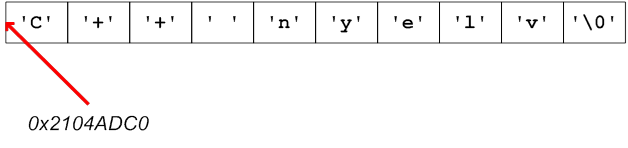
A programban gyakran használunk kettős idézőjelekkel határolt szövegeket (sztringliterálokat), amiket a fordító az inicializált adatok között tárol a fent elmondottak szerint. A
cout << "C++ nyelv";
utasítás fordításakor a szöveg a memóriába másolódik, (I.21. ábra) és a << művelet jobb operandusaként a const char * típusú tárolási cím jelenik meg. Futtatáskor a cout objektum karakterenként megjeleníti a kijelöl tárterület tartalmát, a 0 értékű bájt eléréséig.
A széles karakterekből álló sztringek szintén a fentiek szerint tárolódnak, azonban ebben az esetben a tömb elemeinek típusa wchar_t.
wcout << L"C++ nyelv";
A C++ nyelven a string illetve a wstring típusokat is használhatjuk szövegek feldolgozásához, ezért dióhéjban ezekkel a típusokkal is megismerkedünk.
I.7.4.1. Sztringek egydimenziós tömbökben
Amikor helyet foglalunk valamely karaktersorozat számára, akkor a sztring végét jelző bájtot is figyelembe kell vennünk. Ha az str tömbben maximálisan 80-karakteres szöveget szeretnénk tárolni, akkor a tömb méretét 80+1=81-nek kell megadnunk:
char sor[81];
A programozás során gyakran használunk kezdőértékkel ellátott sztringeket. A kezdőérték megadására alkalmazhatjuk a tömböknél bemutatott megoldásokat, azonban nem szabad megfeledkeznünk a '\0' karakter elhelyezéséről:
char st1[10] = { 'O', 'm', 'e', 'g', 'a', '\0' };
wchar_t wst1[10] = { L'O', L'm', L'e', L'g', L'a', L'\0' };
char st2[] = { 'O', 'm', 'e', 'g', 'a', '\0' };
wchar_t wst2[] = { L'O', L'm', L'e', L'g', L'a', L'\0' };
Az st1 sztring számára 10 bájt helyet foglal a fordító, és az első 6 bájtba bemásolja a megadott karaktereket. Az st2 azonban pontosan annyi bájt hosszú lesz, ahány karaktert megadtunk az inicializációs listában. A széles karakteres wst1 és wst2 sztringek esetén az előző bájméretek kétszeresét foglalja le a fordító.
A karaktertömbök inicializálása azonban sokkal biztonságosabban elvégezhető a sztringliterálok (sztring konstansok) felhasználásával:
char st1[10] = "Omega"; wchar_t wst1[10] = L"Omega"; char st2[] = "Omega"; wchar_t wst2[] = L"Omega";
A kezdőértékadás ugyan mindkét esetben - a karakterenként illetve a sztring konstanssal elvégzett - azonos eredményt ad, azonban a sztring konstans használata sokkal áttekinthetőbb. Nem beszélve arról, hogy a sztringeket lezáró 0-ás bájtot szintén a fordító helyezi el a memóriában.
A tömbben történő tárolás következménye, hogy a sztringekre vonatkozóan szintén nem tartalmaz semmilyen műveletet (értékadás, összehasonlítás stb.) a C++ nyelv. A karaktersorozatok kezelésére szolgáló könyvtári függvények azonban gazdag lehetőséget biztosítanak a programozónak. Nézzünk néhány karaktersorozatokra vonatkozó alapművelet elvégzésére szolgáló függvényt!
|
Művelet |
Függvény (char) |
Függvény (wchar_t) |
|---|---|---|
|
szöveg beolvasása |
cin>>, cin.get () , cin.getline () |
wcin>>, wcin.get () , wcin.getline () |
|
szöveg kiírása |
cout<< |
wcout<< |
|
értékadás |
strcpy () , strncpy () |
wcscpy () , wcsncpy () |
|
hozzáfűzés |
strcat () , strncat () |
wcscat () , wcsncat () |
|
sztring hosszának lekérdezése |
strlen () |
wcslen () |
|
sztringek összehasonlítása |
strcmp () , strcnmp () |
wcscmp () , wcsncmp () |
|
karakter keresése szringben |
strchr () |
wcschr () |
A char típusú karakterekből álló sztringek kezeléséhez az iostream és a cstring deklarációs állományok beépítése szükséges, míg a széles karakteres függvényekhez a cwchar .
Az alábbi példaprogram a beolvasott szöveget nagybetűssé alakítva, fordítva írja vissza a képernyőre. A példából jól látható, hogy a sztringek hatékony kezelése érdekében egyaránt használjuk a könyvtári függvényeket és a karaktertömb értelmezést.
#include <iostream>
#include <cstring>
#include <cctype>
using namespace std;
int main() {
char s[80];
cout <<"Kerek egy szoveget: ";
cin.get(s, 80);
cout<<"A beolvasott szoveg: "<< s << endl;
for (int i = strlen(s)-1; i >= 0; i--)
cout<<(char)toupper(s[i]);
cout<<endl;
}
A megoldás széles karakteres változata:
#include <iostream>
#include <cwchar>
#include <cwctype>
using namespace std;
int main() {
wchar_t s[80];
wcout <<L"Kerek egy szoveget: ";
wcin.get(s, 80);
wcout<<L"A beolvasott szoveg: "<< s << endl;
for (int i = wcslen(s)-1; i >= 0; i--)
wcout<<(wchar_t)towupper(s[i]);
wcout<<endl;
}
Mindkét példában a szöveg beolvasásához a biztonságos cin . get () függvényt használtuk. A függvény minden karaktert beolvas az <Enter> lenyomásáig. A megadott tömbbe azonban legfeljebb az argumentumként megadott méret -1 karakter kerül, így nem lehet túlírni a tömböt.
I.7.4.2. Sztringek és a pointerek
A sztringek kezelésére karaktertömböket és karaktermutatókat egyaránt használhatunk, azonban a mutatókkal óvatosan kell bánni. Tekintsük az alábbi gyakran alkalmazott definíciókat!
char str[16] = "alfa"; char *pstr = "gamma";
Első esetben a fordító létrehozza a 16-elemű str tömböt, majd belemásolja a kezdőértékként megadott szöveg karaktereit, valamint a 0-ás bájtot. A második esetben a fordító az inicializáló szöveget eltárolja a sztringliterálok számára fenntartott területen, majd a sztring kezdőcímével inicializálja a pstr mutatót.
A pstr mutató értéke a későbbiek folyamán természetesen megváltoztatható (ami a példánkban a "gamma" sztring elvesztését okozza):
pstr = "iota";
Ekkor mutató-értékadás történik, hisz a pstr felveszi az új sztringliterál címét. Ezzel szemben az str tömb nevére irányuló értékadás fordítási hibához vezet:
str = "iota"; // hiba! ↯
Amennyiben egy sztringet karakterenként kell feldolgozni, akkor választhatunk a tömbös és a pointeres megközelítés között. A következő példaprogramban a beolvasott karaktersorozatot először titkosítjuk a kizáró vagy művelet felhasználásával, majd pedig visszaállítjuk az eredeti tartalmát. (A titkosításnál a karaktertömb, míg a visszakódolásnál a mutató értelmezést alkalmazzuk.) Mind a két esetben a ciklusok leállási feltétele a sztringet záró nullás bájt elérése.
#include <iostream>
using namespace std;
const unsigned char kulcs = 0xCD;
int main() {
usigned char s[80], *p;
cout <<"Kerek egy szoveget: ";
cin.get(s, 80);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
cout << "A titkositott szoveg : "<< s << endl;
p = s;
while (*p) // visszaállítás
*p++ ^= kulcs;
cout << "Az eredeti szoveg : "<< s << endl;
}
A következő példában a léptető és az indirektség operátorokat együtt alkalmazzuk, amihez kellő óvatosság szükséges. Az alábbi példában az sp mutatóval egy dinamikusan tárolt karaktersorozatra mutatunk. (Megjegyezzük, hogy a C++ implementációk többsége nem engedi módosítani a sztringliterálokat.)
char *sp = new char [33]; strcpy(sp, "C++"); cout << ++*sp << endl; // D cout << sp << endl; // D++ cout << *sp++ << endl; // D cout << sp << endl; // ++
Az első esetben (++*sp) először az indirektség operátorát értelmezi a fordító, majd pedig elvégzi a hivatkozott karakter léptetését. A második esetben (*sp++) először a mutató léptetése értékelődik ki, azonban a hátravetett forma következtében csak a teljes kifejezés feldolgozása után megy végbe a léptetés. A kifejezés értéke pedig a hivatkozott karakter.
I.7.4.3. Sztringtömbök használata
A C++ programok többsége tartalmaz olyan szövegeket, például üzeneteket, amelyeket adott index (hibakód) alapján kívánunk kiválasztani. Az ilyen szövegek tárolására a legegyszerűbb megoldás a sztringtömbök definiálása.
A sztringtömbök kialakítása során választhatunk a kétdimenziós tömb és a mutatótömb között. Kezdő C++ programozók számára sokszor gondot jelent ezek megkülönböztetése. Tekintsük az alábbi két definíciót!
int a[4][6]; int* b[4];
Az a „igazi” kétdimenziós tömb, amely számára a fordító 24 (4x6) darab int típusú elem tárolására alkalmas folytonos területet foglal le a memóriában. Ezzel szemben a b 4-elemű mutatóvektor. A fordító csak a 4 darab mutató számára foglal helyet a definíció hatására. A inicializáció további részeit a programból kell elvégeznünk. Inicializáljuk úgy a mutatótömböt, hogy az alkalmas legyen 5x10 egész elem tárolására!
int s1[6], s2[6], s3[6], s4[6];
int* b[4] = { s1, s2, s3, s4 };
Látható, hogy a 24 int elem tárolására szükséges memóriaterületen felül, további területet is felhasználtunk (a mutatók számára). Joggal vetődik fel a kérdés, hogy mi az előnye a mutatótömbök használatának. A választ a sorok hosszában kell keresni. Míg a kétdimenziós tömb esetén minden sor ugyanannyi elemet tartalmaz,
addig a mutatótömb esetén az egyes sorok mérete tetszőleges lehet.
int s1[1], s2[3], s3[2], s4[6];
int* b[4] = { s1, s2, s3, s4 };
A mutatótömb másik előnye, hogy a felépítése összhangban van a dinamikus memóriafoglalás lehetőségeivel, így fontos szerepet játszik a dinamikus helyfoglalású tömbök kialakításánál.
E kis bevezető után térjünk rá az alfejezet témájára, a sztringtömbök kialakítására! A sztringtömböket általában kezdőértékek megadásával definiáljuk. Az első példában kétdimenziós karaktertömböt definiálunk, az alábbi utasítással:
static char nevek1[][10] = { "Iván",
"Olesya",
"Anna",
"Adrienn" };
Az definíció során létrejön egy 4x10-es karaktertömb - a sorok számát a fordítóprogram az inicializációs lista alapján határozza meg. A kétdimenziós karaktertömb sorai a memóriában folytonosan helyezkednek el (I.22. ábra).

A második esetben mutatótömböt használunk a nevek címének tárolására:
static char* nevek2[] = { "Iván",
"Olesya",
"Anna",
"Adrienn" };
A fordító a memóriában négy különböző méretű területet foglal le a következő ábrán (I.23. ábra) látható módon:
Érdemes összehasonlítani a két megoldást mind a definíció, mind pedig a memóriaelérés szempontjából.
cout << nevek1[0] << endl; // Iván cout << nevek1[1][4] << endl; // y cout << nevek2[0] << endl; // Iván cout << nevek2[1][4] << endl; // y
I.7.5. A string típus
A C++ nyelv szabványos sablonkönyvtárában (STL) a szövegkezelést támogató osztályokat is találunk. Az előzőekben bemutatott megoldások a C-stílusú karaktersorozatokra vonatkoznak, most azonban megismerkedünk a string és a wstring típusok lehetőségeivel.
A C++ stílusú karaktersorozat-kezelés eléréséhez a string nevű fejállományt kell a programunkba beépíteni. A string típussal definiált objektumokon keresztül egy sor kényelmes szövegkezelő művelet áll a rendelkezésünkre, operátorok és tagfüggvények formájában. Nézzünk néhányat ezek közül! (A táblázatban a tagfüggvények előtt pont szerepel. A tagfüggvények nevét az objektum neve után, ponttal elválasztva adjuk meg.) Széles karakterekből álló karaktersorozatok kezeléséhez a string fejállomány mellet a cwchar fájlra is szükségünk van.
|
Művelet |
C++ megoldás - string |
C++ megoldás - wstring |
|---|---|---|
|
szöveg beolvasása |
cin>>, getline () |
wcin>>, getline () |
|
szöveg kiírása |
cout<< |
wcout<< |
|
értékadás |
=, .assign () |
=, .assign () |
|
összefűzés |
+, += |
+, += |
|
a sztring karaktereinek elérése |
[] |
[] |
|
sztring hosszának lekérdezése |
.size() |
.size () |
|
sztringek összehasonlítása |
.compare () , ==, !=, <, <=, >, >= |
.compare () , ==, !=, <, <=, >, >= |
|
átalakítás C-stílusú karaktersorozattá |
.c_str () , .data () |
.c_str () , .data () |
Példaként írjuk át szövegtitkosító programunkat C++ stílusú sztringkezelés felhasználásával!
#include <string>
#include <iostream>
using namespace std;
const unsigned char kulcs = 0xCD;
int main() {
string s;
char *p;
cout<<"Kerek egy szoveget : ";
getline(cin, s);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
cout<<"A titkositott szoveg : "<<s<<endl;
p=(char *)s.c_str();
while (*p) // visszaállítás
*p++ ^= kulcs;
cout<<"Az eredeti szoveg : "<<s<<endl;
}
A feladat megoldása széles karaktereket tartalmazó sztringekkel (wstring) az alábbiakban látható
#include <string>
#include <iostream>
#include <cwchar>
using namespace std;
const unsigned wchar_t kulcs = 0xCD;
int main()
{
wstring s;
wchar_t *p;
wcout<<L"Kerek egy szoveget : ";
getline(wcin, s);
for (int i = 0; s[i]; i++) // titkosítás
s[i] ^= kulcs;
wcout<<L"A titkositott szoveg : "<<s<<endl;
p=(wchar_t *)s.c_str();
while (*p) // visszaállítás
*p++ ^= kulcs;
wcout<<L"Az eredeti szoveg : "<<s<<endl;
}
I.8. Felhasználói típusok
A tömbök segítségével azonos típusú adatokat összefogva tárolhatunk, és könnyen fel is dolgozhatunk. A programozási feladatok nagy részében azonban különböző típusú adatokat kell logikailag egyetlen egységben kezelni. A C++ nyelv több lehetőséget is kínál erre, melyek közül a struktúra (struct) és az osztály (class) típusok külön jelentőséggel bírnak, hiszen rájuk épülnek a könyvünkben (III. fejezet) tárgyalt objektum-orientált megoldások.
A következő részben az összeállított (aggregate) típusok közül megismerkedünk a struktúra, az osztály, a bitmező és az unió (union) típusokkal. Az ismerkedés során a hangsúlyt a struktúrára (struct) helyezzük. Ennek oka, hogy a struktúra típussal kapcsolatos fogalmak és megoldások minden további nélkül alkalmazhatók a többi felhasználói típusra.
I.8.1. A struktúra típus
C++ nyelven a struktúra (struct) típus több tetszőleges típusú (kivéve a void és a függvénytípust) adatelem együttese. Ezek az adatelemek, melyek szokásos elnevezése struktúraelem vagy adattag (data member), csak a struktúrán belül érvényes nevekkel rendelkeznek. (A más nyelveken a mező (field) elnevezést alkalmazzák, mely elnevezést azonban a bitstruktúrákhoz kapcsolja a C++ nyelv.)
I.8.1.1. Struktúra típus és struktúra változó
Egy struktúra típusú változót két lépésben hozunk létre. Először megadjuk magát a struktúra típust, melyet felhasználva változókat definiálhatunk. A struktúra felépítését meghatározó deklaráció általános formája:
struct struktúra_típus {
típus 1 tag 1 ; // kezdőérték nélkül!
típus 2 tag 2 ;
. . .
típus n tag n ;
};
Felhívjuk a figyelmet arra, hogy a struktúra deklarációját záró kapcsos zárójel mögé a pontosvesszőt kötelező kitenni. Az adattagok deklarációjára a C++ nyelv szokásos változó-deklarációs szabályai érvényesek, azonban kezdőérték nem adható meg. A fenti típussal struktúra változót (struktúrát) a már megismert módon készíthetünk:
struct struktúra_típus struktúra_változó; // C/C++
struktúra_típus struktúra_változó; // csak C++
A C++ nyelvben a struct, a union és a class kulcsszavak után álló név típusnévként használható a kulcsszó megadása nélkül. A typedef alkalmazásával eltűnik a különbség a két nyelv között:
typedef struct {
típus 1 tag 1 ;
típus 2 tag 2 ;
. . .
típus n tag n ;
} struktúra_típus;
struktúra_típus struktúra_változó; // C/C++
A tömbökhöz hasonlóan a struktúra definíciójában is szerepelhet kezdőértékadás. Az egyes adattagokat inicializáló kifejezések vesszővel elválasztott listáját kapcsos zárójelek közé kell zárni.
struktúra_típus struktúra_változó = {kezdőértéklista}; // C/C++
Megjegyezzük, hogy a legtöbb szoftverfejlesztő cégnél ez utóbbi (typedef-es) struktúra definíciót támogatják a keveredések elkerülése érdekében.
Felhívjuk a figyelmet arra, hogy a struct típusban megadott tagnevek láthatósága a struktúrára korlátozódik. Ez azt jelenti, hogy ugyanazt a nevet egy adott láthatósági szinten belül (modul, blokk), több struktúrában valamint független névként egyaránt felhasználhatjuk:
struct s1 {
int a;
double b;
};
struct s2 {
char a[7];
s1 b;
};
long a;
double b[12];
Nézzünk egy példát a struktúratípus megadására! Zenei CD-ket nyilvántartó program készítése során jól használható a következő adatstruktúra:
struct zeneCD {
string eloado, cim; // a CD előadója és címe
int ev; // a kiadás éve
int ar; // a CD ára
};
A zeneCD típussal változókat is definiálhatunk:
zeneCD klasszikus = {"Vivaldi", "A negy evszak", 2009, 2590};
zeneCD *pzene = 0, rock, mese = {};
A struktúra típusú változók közül a rock inicializálatlan, míg a mese struktúra minden tagja a típusának megfelelő az alapértelmezés szerinti kezdőértéket veszi fel. A pzene mutató nem hivatkozik egyetlen struktúrára sem.
A struktúra definíciójával létrehoztunk egy új felhasználói típust. A struktúra típusú változó adattagjait a fordító a deklaráció sorrendjében tárolja a memóriában. Az I.24. ábra grafikusan ábrázolja a
zeneCD relax;
definícióval létrehozott adatstruktúra felépítését.
Az ábráról is leolvasható, hogy az adattagok nevei a struktúra elejétől mért távolságokat jelölnek. A struktúra mérete általában megegyezik az adattagok méretének összegével. Bizonyos esetekben azonban (optimalizálás sebességre, adatok memóriahatárra való igazítása stb.) „lyukak” keletkezhetnek a struktúra tagjai között. A sizeof operátor alkalmazásával azonban mindig a pontos méretet kapjuk.
Az esetek többségében az adattagok memóriahatárra igazítását rábízzuk a fordítóra, ami a gyors elérés érdekében az adott hardverre optimalizálva helyezi el az adatokat. Ha azonban különböző platformok között struktúrákat fájl segítségével cserélünk, a mentéshez használt igazítást kell a felolvasó programban beállítanunk.
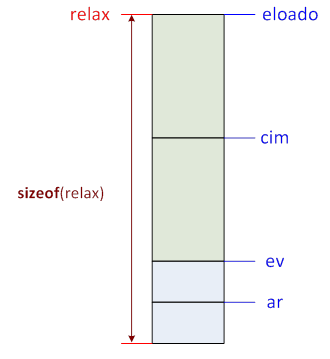
A C++ fordítóprogram működésének vezérlésére a #pragma előfordító előírást (direktívát) használjuk, melynek lehetőségei teljes egészében implementációfüggők.
I.8.1.2. Hivatkozás a struktúra adattagjaira
A struktúra szót gyakran önállóan is használjuk, ilyenkor azonban nem a típusra, hanem az adott struktúra típussal létrehozott változóra gondolunk. Definiáljunk néhány változót az előzőekben deklarált zeneCD típus felhasználásával!
zeneCD s1, s2, *ps;
Az s1 és s2 zeneCD típusú változók tárolásához szükséges memóriaterület lefoglalásáról a fordító gondoskodik. Ahhoz, hogy a pszeneCD típusú mutatóval is hivatkozhassunk egy struktúrára, két lehetőség közül választhatunk. Az első esetben a ps-t egyszerűen ráirányítjuk az s1 struktúrára:
ps = &s1;
A második lehetőség a dinamikus memóriafoglalás alkalmazását jelenti. Az alábbi programrészletben memóriát foglalunk a zeneCD struktúra számára, majd pedig felszabadítjuk azt:
ps = new (nothrow) zeneCD; if (!ps) exit(-1); // ... delete ps;
A megfelelő definíciók megadása után három struktúrával rendelkezünk: s1, s2 és *ps. Nézzük meg, hogyan lehet értéket adni a struktúráknak! Erre a célra a C++ nyelvben a pont ( . ) operátor használható. A pont operátor bal oldali operandusa a struktúra-változó, a jobb oldali operandusa pedig a struktúrán belül jelöli ki az adattagot.
s1.eloado = "Vivaldi"; s1.cim = "A négy évszak"; s1.ev = 2005; s1.ar = 2560;
Amikor a pont operátort a ps által mutatott struktúrára alkalmazzuk, a precedencia szabályok miatt zárójelek között kell megadnunk a *ps kifejezést:
(*ps).eloado = "Vivaldi"; (*ps).cim = "A négy évszak"; (*ps).ev = 2005; (*ps).ar = 2560;
Mivel a C++ nyelvben gyakran használunk mutató által kijelölt struktúrákat, a nyelv ezekben az esetekben egy önálló operátort – a nyíl (->) operátor – biztosít az adattag-hivatkozások elvégzésére. (A nyíl operátor két karakterből, a mínusz és a nagyobb jelből áll.) A nyíl operátor használatával olvashatóbb formában írhatjuk fel ps által kijelölt struktúra adattagjaira vonatkozó értékadásokat:
ps->eloado = "Vivaldi"; ps->cim = "A négy évszak"; ps->ev = 2005; ps->ar = 2560;
A nyíl operátor bal oldali operandusa a struktúra változóra mutató pointer, míg a jobb oldali operandusa – a pont operátorhoz hasonlóan – a struktúrán belül jelöli ki az adattagot. Ennek megfelelően a ps->ar kifejezés jelentése: "a ps mutató által kijelölt struktúra ar adattagja".
A pont és a nyíl operátorok használatával kapcsolatban javasoljuk, hogy a pont operátort csak közvetlen (a struktúra típusú változó adattagjára történő) hivatkozás esetén, míg a nyíl operátort kizárólag közvetett (mutató által kijelölt struktúra adattagjára vonatkozó) hivatkozás esetén használjuk.
A struktúrára vonatkozó értékadás speciális esete, amikor egy struktúra típusú változó tartalmát egy másik, azonos típusú változónak kívánjuk megfeleltetni. Ezt a műveletet adattagonként is elvégezhetjük,
s2.eloado = s1.eloado; s2.cim = s1.cim; s2.ev = s1.ev; s2.ar = s1.ar;
azonban a C++ nyelv a struktúra változókra vonatkozó értékadás (=) műveletét is értelmezi:
s2 = s1 ; // ez megfelel a fenti 4 értékadásnak *ps = s2 ; s1 = *ps = s2 ;
Az értékadásnak ez a módja egyszerűen a struktúra által lefoglalt memóriablokk átmásolását jelenti. Ez a művelet azonban gondot okoz, amikor a struktúra olyan mutatót tartalmaz, amely külső memóriaterületre hivatkozik. Ekkor az adattagonkénti értékadás módszerét használva magunknak kell kiküszöbölni a jelentkező problémát, másrészt pedig a másolás műveletének túlterhelésével (operator overloading) saját értékadó operátort (lásd III. fejezet) hozhatunk létre a struktúrához.
Az adatbeviteli és -kiviteli műveletek során szintén tagonként érjük el a struktúrákat. Az alábbi példában billentyűzetről töltjük fel a zeneCD típusú struktúrát, majd pedig megjelenítjük a bevitt adatokat:
#include <iostream>
#include <string>
using namespace std;
struct zeneCD {
string eloado, cim;
int ev, ar;
};
int main() {
zeneCD cd;
// az adatok beolvasása
cout<<"Kerem a zenei CD adatait!" << endl;
cout<<"Eloado : "; getline(cin, cd.eloado);
cout<<"Cim : "; getline(cin, cd.cim);
cout<<"Megjelenes eve : "; cin>>cd.ev;
cout<<"Ar : "; cin>>cd.ar;
cin.get();
// az adatok megjelenítése
cout<<"\nA zenei CD adatai:" << endl;
cout<<"Eloado : "; cout << cd.eloado << endl;
cout<<"Cim : "; cout << cd.cim << endl;
cout<<"Megjelenes eve : "; cout << cd.ev << endl;
cout<<"Ar : "; cout << cd.ar << endl;
}
I.8.1.3. Egymásba ágyazott struktúrák
Már említettük, hogy a struktúráknak tetszőleges típusú adattagjai lehetnek. Ha egy struktúrában elhelyezünk egy vagy több struktúra adattagot, akkor ún. egymásba ágyazott struktúrákat kapunk.
Tételezzük fel, hogy személyi adatokat struktúra felhasználásával szeretnénk tárolni! A személyi adatok közül a dátumok kezelésére külön struktúrát definiálunk:
struct datum {
int ev, ho, nap;
};
struct szemely {
string nev;
datum szulinap;
};
Hozzunk létre két személyt, méghozzá úgy, hogy az egyiknél használjunk kezdőértékadást, míg a másikat tagonkénti értékadással inicializáljuk!
szemely fiver = { "Iván", {2004, 10, 2} };
szemely hallgato;
hallgato.nev = "Nagy Ákos";
hallgato.szulinap.ev = 1990;
hallgato.szulinap.ho = 10;
hallgato.szulinap.nap = 20;
A kezdőértékadás során a belső struktúrát inicializáló konstansokat nem kötelező kapcsos zárójelek közé helyezni. A hallgato struktúra adattagjait inicializáló értékadás során az első pont (.) operátorral a hallgato struktúrában elhelyezkedő szulinap struktúrára hivatkozunk, majd ezt követi a belső struktúra adattagjaira vonatkozó hivatkozás.
Ha a datum típusú struktúrát máshol nem használjuk, akkor névtelen struktúraként közvetlenül beépíthetjük a szemely struktúrába:
struct szemely {
string nev;
struct {
int ev, ho, nap;
} szulinap;
};
Bonyolultabb dinamikus adatszerkezetek (például lineáris lista) kialakításánál adott típusú elemeket kell láncba fűznünk. Az ilyen elemek általában valamilyen adatot és egy mutatót tartalmaznak. A C++ nyelv lehetővé teszi, hogy a mutatót az éppen deklarálás alatt álló struktúra típusával definiáljuk. Az ilyen struktúrákat, amelyek önmagukra mutató pointert tartalmaznak adattagként, önhivatkozó struktúráknak nevezzük. Példaként tekintsük az alábbi listaelem deklarációt!
struct listaelem {
double adattag;
listaelem *kapcsolat;
};
Ez a rekurzív deklaráció mindössze annyit tesz, hogy a kapcsolat mutatóval listaelem típusú struktúrára mutathatunk. A fenti megoldás nem ágyazza egymásba a két struktúrát, hiszen az a struktúra, amelyre a későbbiek során a mutatóval hivatkozunk, valahol máshol fog elhelyezkedni a memóriában. A C++ fordító számára a deklaráció általában azért szükséges, hogy a deklarációnak megfelelően tudjon memóriát foglalni, vagyis hogy ismerje a létrehozandó változó méretét. A fenti deklarációban a létrehozandó tároló egy mutató, amelynek mérete független a struktúra méretétől.
I.8.1.4. Struktúrák és tömbök
A programkészítés lehetőségeit nagyban megnöveli, ha a tömböket és struktúrákat együtt használjuk, egyetlen adattípusba ötvözve. Az alábbi, egyszerű megoldásokban először egydimenziós tömböt helyezünk el struktúrán belül, majd pedig struktúra típusú elemekből készítünk egydimenziós tömböt.
I.8.1.4.1. Tömb, mint struktúratag
Az alábbi példában az egész vektor (v) mellet az értékes elemek számát is tároljuk (n) az svektor struktúrában:
const int maxn = 10;
struct svektor {
int v[maxn];
int n;
};
svektor a = {{23, 7, 12}, 3};
svektor b = {{0}, maxn};
svektor c = {};
int sum=0;
for (int i=0; i<a.n; i++) {
sum += a.v[i];
}
c = a;
Az a.v[i] kifejezésben nem kell zárójelezni, mivel a két azonos elsőbbségű művelet balról jobbra haladva értékelődik ki. Vagyis először kiválasztódik az a struktúra v tagja, majd pedig az a.v tömb i-dik eleme. További érdekessége ennek a megoldásnak, a struktúrák közötti értékadás során a vektor elemei is átmásolódnak.
Az svektor típusú struktúrát dinamikusan is létrehozhatjuk. Ekkor azonban a nyíl operátorral kell kijelölni a struktúrát a memóriában.
svektor *p = new svektor; p->v[0] = 2; p->v[1] = 10; p->n = 2; delete p;
I.8.1.4.2. Struktúra, mint tömbelem
Struktúratömböt pontosan ugyanúgy kell definiálni, mint bármilyen más típusú tömböt. Példaként, az előzőekben deklarált zeneCD típust használva hozzunk létre egy 100-elemű CD-tárat, és lássuk el kezdőértékkel a CDtar első két elemét!
zeneCD CDtar[100]={{"Vivaldi","A négy évszak",2004,1002},{}};
A tömbelem struktúrák adattagjaira való hivatkozáshoz először kiválasztjuk a tömbelemet, majd pedig a struktúratagot:
CDtar[10].ar = 2004;
Amennyiben dinamikusan kívánjuk a CD-tárat létrehozni, mutatót kell használnunk az azonosításhoz:
zeneCD *pCDtar;
A struktúraelemek számára a new operátorral foglalhatunk helyet a dinamikusan kezelt memóriaterületen:
pCDtar = new zeneCD[100];
A tömbelemben tárolt struktúrára a pont operátor segítségével hivatkozhatunk:
pCDtar[10].ar = 2004;
Ha már nincs szükségünk a tömb elemeire, akkor a delete [] operátorral felszabadítjuk a lefoglalt tárterületet:
delete[] pCDtar;
Bizonyos műveletek (például a rendezés) hatékonyabban elvégezhetők, ha mutatótömbben tároljuk a dinamikusan létrehozott CD-lemezek mutatóit:
zeneCD* dCDtar[100];
A struktúrák számára az alábbi ciklus segítségével foglalhatunk helyet a dinamikusan kezelt memóriaterületen:
for (int i=0; i<100; i++) dCDtar[i] = new zeneCD;
Ekkor a tömbelemek által kijelölt struktúrákra a nyíl operátor segítségével hivatkozhatunk:
dCDtar[10]->ar = 2004;
Ha már nincs szükségünk a struktúrákra, akkor az elemeken végighaladva felszabadítjuk a lefoglalt memóriaterületeket:
for (int i = 0; i < 100; i++) delete dCDtar[i];
Az alábbi példában a dinamikusan létrehozott, adott számú CD-lemezt tartalmazó CD-tárból, kigyűjtjük az 2010 és 2012 között megjelent műveket.
#include <iostream>
#include <string>
using namespace std;
struct zeneCD {
string eloado, cim;
int ev, ar;
};
int main() {
cout<<"A CD-lemezek szama:";
int darab;
cin>>darab;
cin.ignore(80, '\n');
// Helyfoglalás ellenőrzéssel
zeneCD *pCDtar = new (nothrow) zeneCD[darab];
if (!pCDtar) {
cerr<<"\a\nNincs eleg memoria!\n";
return -1;
}
// A CD-lemezek beolvasása
for (int i=0; i<darab; i++) {
cout<<endl<<i<<". CD adatai:"<<endl;
cout<<"Eloado: "; getline(cin, pCDtar[i].eloado);
cout<<"Cim: "; getline(cin, pCDtar[i].cim);
cout<<"Ev: "; cin>>pCDtar[i].ev;
cout<<"Ar: "; cin>>pCDtar[i].ar;
cin.ignore(80, '\n');
}
// A keresett CD-k kiválogatása
int talalt = 0;
for (int i = 0; i < darab; i++) {
if (pCDtar[i].ev >=2010 && pCDtar[i].ev <= 2012) {
cout<<endl<<pCDtar[i].eloado<<endl;
cout<<pCDtar[i].cim<<endl;
cout<<pCDtar[i].ev<<endl;
talalt++;
}
}
// A keresés eredményének kijelzése
if (talalt)
cout<<"\nA talalatok szama: "<<talalt<<endl;
else
cout<<"Nincs a feltetelnek megfelelo CD!"<<endl;
// A lefoglalt terület felszabadítása
delete [] pCDtar;
}
A program interaktív, vagyis a felhasználótól várja az adatokat, és a képernyőn jeleníti meg az eredményeket. Nagyobb adatmennyiséggel való tesztelés igen fáradtságos ily módon.
Az operációs rendszerek többsége azonban lehetővé teszi, hogy a program szabványos bemenetét és kimentét fájlba irányítsuk. Az átirányításhoz egy fájlba kell begépelnünk az input adatokat, abban a formában, ahogy azt a program várja (például CDk.txt), és meg kell adnunk egy kisebb jel után a program (CDTar) parancssorában:
CDTar <CDk.txt CDTar <CDk.txt >Eredmeny.txt
A második parancssorral az eredményeket is fájlban kapjuk meg (I.25. ábra). (A Visual C++ fejlesztői környezetben az átirányítási előírásokat a Project /projekt Properties ablak, Debugging lapjának Command Arguments sorában is elhelyezhetjük.)

I.8.1.5. Egyszeresen láncolt lista kezelése
A láncolt listák legegyszerűbb formája az egyszeresen láncolt lista, amelyben elemenként egy hivatkozás található, ami a lista következő elemére mutat. Az utolsó elem esetén ez a hivatkozás nulla értékű (I.26. ábra).
A lista pStart mutató jelöli ki a memóriában, ezért ennek értékét mindig meg kell őriznünk. Amennyiben a pStart felülíródik, a lista elérhetetlenné válik a programunk számára.
Nézzük meg, milyen előnyökkel jár a lineáris lista használata a vektorral (egydimenziós tömbbel) összehasonlítva! A vektor mérete definiáláskor eldől, a lista mérete azonban dinamikusan növelhető, illetve csökkenthető. Ugyancsak lényeges eltérés tapasztalható az elemek beszúrása és törlése között. Míg a listában ezek a műveletek csupán néhány mutató másolását jelentik, addig a vektorban nagymennyiségű adat mozgatását igénylik. További lényeges különbség van a tárolási egység, az elem felépítésében:
A vektor elemei csak a tárolandó adatokat tartalmazzák, míg a lista esetében az adaton kívül a kapcsolati információk tárolására (mutató) is szükség van. C++ nyelven a listaelemeket a már bemutatott önhivatkozó struktúrával hozhatjuk létre.
Példaként tároljuk egész számokat lineáris listában, mely elemeinek típusa:
struct listaelem {
int adat;
listaelem *pkov;
};
Mivel a példában többször foglalunk memóriát egy új listaelem számára, ezt a műveletet a könyvünk következő részében ismertetésre kerülő függvénnyel valósítjuk meg:
listaelem *UjElem(int adat) {
listaelem * p = new (nothrow) listaelem;
assert(p);
p->adat = adat;
p->pkov = NULL;
return p;
}
A függvény sikeres esetben az új listaelem mutatójával tér vissza, és egyben inicializálja is az új elemet. Felhívjuk a figyelmet nothrow argumentumra, mely arra szolgál, hogy foglalási hiba esetén ne kapjunk hibaüzenetet, hanem a null pointerrel térjen vissza a new (I.6. szakasz). Az assert () makró megszakítja a program futását, és kiírja az „Assertion failed: p, file c:\temp\lista.cpp, line 16” üzenetet, ha az argumentuma 0 értékű.
A listát létrehozáskor az alábbi tömb elemeivel töltjük fel.
int adatok [] = {2, 7, 10, 12, 23, 29, 30};
const int elemszam = sizeof(adatok)/sizeof(adatok[0]);
A lista kezelése során szükségünk van segédváltozókra, illetve a lista kezdetét jelölő pStart mutatóra:
listaelem *pStart = NULL, *pAktualis, *pElozo, *pKovetkezo;
Amikor a lista adott elemével (pAktualis) dolgozunk, szükségünk lehet a megelőző (pElozo) és a rákövetkező (pKovetkezo) elemek helyének ismeretére is. A példában a vizsgálatok elkerülése érdekében feltételezzük, hogy a lista a létrehozása után mindig létezik, tehát a pStart mutatója soha sem 0.
A lista felépítése, és az elemek feltöltése az adatok tömbből. A lista létrehozása során minden egyes elem esetén három jól elkülöníthető tevékenységet kell elvégeznünk:
-
helyfoglalás (ellenőrzéssel) a listaelem számára (UjElem()),
-
a listaelem adatainak feltöltése (UjElem()),
-
a listaelem hozzáfűzése a listához (a végéhez). A hozzáfűzés során az első és a nem első elemek esetén más-más lépéseket kell végrehajtanunk.
for (int index = 0; index<elemszam; index++) { pKovetkezo = UjElem(adatok[index]); if (pStart==NULL) pAktualis = pStart = pKovetkezo ; // első elem else pAktualis = pAktualis->pkov = pKovetkezo; // nem első elem } pAktualis->pkov = NULL; // a lista lezárása // a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30
A lista elemeinek megjelenítése során a pStart mutatótól indulunk, és a ciklusban mindaddig lépkedünk a következő elemre, amíg el nem érjük a lista végét jelző nullaértékű mutatót:
pAktualis = pStart;
while (pAktualis != NULL) {
cout<< pAktualis->adat << endl;
// lépés a következő elemre
pAktualis = pAktualis->pkov;
}
Gyakran használt művelet a listaelem törlése. A példában a törlendő listaelemet a sorszáma alapján azonosítjuk (A sorszámozás 0-val kezdődik a pStart által kijelölt elemtől kezdődően – a programrészlet nem alkalmas a 0. és az utolsó elem törlésére!) A törlés művelete szintén három tevékenységre tagolható:
// a 4. sorszámú elem (23) helyének meghatározása
pAktualis = pStart;
for (int index = 0; index<4; index++) {
pElozo = pAktualis;
pAktualis = pAktualis->pkov;
}
// törlés - kifűzés a láncból
pElozo->pkov = pAktualis->pkov;
// a terület felszabadítása
delete pAktualis;
// a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 29 ➝ 30
A 0. elem eltávolítása esetén a pStart mutató értékét a törlés előtt a pStart->pkov értékre kell állítanunk. Az utolsó elem törlése esetén pedig az utolsó előtti elem pkov tagjának nullázásáról is gondoskodnunk kell.
A törléssel ellentétes művelet az új elem beillesztése a listába, két meglévő elem közé. A beszúrás helyét annak az elemnek a sorszámával azonosítjuk, amely mögé az új elem kerül. A példában a 3. sorszámú elem mögé illesztünk új listaelemet:
// a megelőző, 3. sorszámú elem (12) helyének meghatározása
pAktualis = pStart;
for (int index = 0; index<3; index++)
pAktualis = pAktualis->pkov;
// területfoglalás az új elem számára
pKovetkezo = UjElem(23);
// az új elem befűzés a láncba
pKovetkezo->pkov = pAktualis->pkov;
pAktualis ->pkov = pKovetkezo;
// a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30
A fenti programrészlet az utolsó elem után is helyesen illeszti be az új listaelemet.
Szintén gyakori művelet új elem hozzáfűzése a listához (a lista végére).
// az utolsó elem megkeresése pAktualis = pStart; while (pAktualis->pkov!=NULL && (pAktualis = pAktualis->pkov)); // területfoglalás az új elem számára pKovetkezo = UjElem(80); // az új elem hozzáfűzése a listához pAktualis->pkov = pKovetkezo; // a lista: pStart ➝ 2 ➝ 7 ➝ 10 ➝ 12 ➝ 23 ➝ 29 ➝ 30 ➝ 80
Hasonlóképpen, adott értékű elemre is rákereshetünk a listában.
int adat = 29;
pAktualis = pStart;
while (pAktualis->adat!=adat && (pAktualis = pAktualis->pkov));
if (pAktualis!=NULL)
cout<<"Talalt: "<<pAktualis->adat<< endl;
else
cout<<" Nem talalt!"<<endl;
A programból való kilépés előtt fel kell szabadítanunk a dinamikusan foglalt memóriaterületeket. A lista elemeinek megszüntetése céljából végig kell mennünk a listán, ügyelve arra, hogy még az aktuális listaelem törlése előtt kiolvassuk a következő elem helyét:
pAktualis = pStart;
while (pAktualis != NULL) {
pKovetkezo = pAktualis->pkov;
delete pAktualis;
pAktualis = pKovetkezo;
}
pStart = NULL; // nincs listaelem!
I.8.2. A class osztály típus
A C++ nyelv, a könyvünkben szereplő (III. fejezet) objektum-orientált programozás megvalósításához egyrészt kibővíti a C nyelv struct típusát, másrészről pedig egy új class típust vezet be. Mindkét típus alkalmas arra, hogy osztályt definiáljunk segítségükkel. (Az osztályban az adattagok mellett általában tagfüggvényeket is elhelyezünk.) Minden, amit az előző pontban az struktúrával kapcsolatban elmondtunk, érvényes az osztály típusra is, egyetlen apró, ám igen lényeges különbséggel. Ez a különbség a tagok alapértelmezés szerinti elérhetőségében jelentkezik.
A C nyelvvel való kompatibilitás megtartása érdekében a struktúra tagjainak korlátozás nélküli (nyilvános, public) elérését meg kellett tartani a C++ nyelvben. Az objektum-orientált programozás alapelveinek azonban olyan adatstruktúra felel meg, melynek tagjai alapértelmezés szerint nem érhetők el. Annak érdekében, hogy mindkét követelménynek megfeleljen a C++ nyelv, bevezették az új class kulcsszót. A class segítségével olyan „struktúrát” definiálhatunk, melynek tagjai (saját, private) alaphelyzetben nem érhetők el kívülről.
Az osztálytagok szabályozott elérése érdekében a struktúra, illetve az osztály deklarációkban public (nyilvános), private (privát) és protected (védett) kulcsszavakat helyezhetünk el. Az elérhetőség megadása nélkül (alapértelmezés szerint), a class típusú osztály tagjai kívülről nem érhetők el (private), míg a struct típusú osztály tagjai korlátozás nélkül elérhetők (public).
Az elmondottak alapján az alábbi táblázat soraiban megadott típusdefiníciók - a felhasználás szempontjából - azonosnak tekinthetők:
|
struct ido { int ora; int perc; int masodperc; };
|
class ido { public: int ora; int perc; int masodperc; }; |
|
struct ido { private: int ora; int perc; int masodperc; }; |
class ido { int ora; int perc; int masodperc; };
|
A struct vagy class típusú változók definíciójában csak akkor adhatunk meg kezdőértéket, ha az osztály típus csupa nyilvános adattaggal rendelkezik.
class ido {
public:
int ora;
int perc;
int masodperc;
};
int main() {
ido kezdet ={7, 10, 2};
}
I.8.3. A union típus
A C nyelv kidolgozásakor a takarékos memóriahasználat céljából olyan lehetőségeket is beépítettek a nyelvbe, amelyek jóval kisebb jelentőséggel bírnak, mint például a dinamikus memóriakezelés. Nézzük meg, miben áll a következő két alfejezetben bemutatott megoldások lényege!
-
Helyet takarítunk meg, ha ugyanazt a memóriaterületet több változó közösen használja (de nem egyidejűleg). Az ilyen változók összerendelése a union (unió - egyesítés) típussal valósítható meg.
-
A másik lehetőség, hogy azokat a változókat, amelyek értéke 1 bájtnál kisebb területen is elfér, egyetlen bájtban helyezzük el. Ehhez a megoldáshoz a C++ nyelv a bitmezőket biztosítja. Azt, hogy milyen (hány bites) adatok kerüljenek egymás mellé, a struct típussal rokon bitstruktúra deklarációjával adhatjuk meg.
Az unió és a bitstruktúra alkalmazásával nem lehet jelentős memória-megtakarítást elérni, viszont annál inkább romlik a programunk hordozhatósága. A memóriaigény csökkentését célzó módszerek hordozható változata a dinamikus memóriakezelés. Fontos megjegyeznünk, hogy az unió tagjainak nyilvános elérése nem korlátozható.
Napjainkban az uniót elsősorban gyors, gépfüggő adatkonverziók megvalósítására, míg a bitstruktúrát a hardver különböző elemeinek vezérlését végző parancsszavak előállítására használjuk.
A struct típussal kapcsolatban elmondott formai megoldások, kezdve a deklarációtól, a pont és nyíl operátorokon át, egészen a struktúratömbök kialakításáig, a union típusra is alkalmazhatók. Az egyetlen és egyben lényegi különbség a két típus között az adattagok elhelyezkedése között áll fenn. Míg a struktúra adattagjai a memóriában egymás után helyezkednek el, addig az unió adattagjai közös címen kezdődnek (átlapoltak). A struct típus méretét az adattagok összmérete (a kiigazításokkal korrigálva) adja, míg a union mérete megegyezik a „leghosszabb” adattagjának méretével.
Az alábbi példában egy 4-bájtos, unsigned long típusú adattagot szavanként, illetve bájtonként egyaránt elérhetünk. A konv unió adattagjainak elhelyezkedését a memóriában az I.27. ábra szemlélteti.
#include <iostream>
using namespace std;
union konv {
unsigned long l;
struct {
unsigned short lo;
unsigned short hi;
} s;
unsigned char c[4];
};
int main()
{
konv adat = { 0xABCD1234 };
cout<<hex<<adat.s.lo<<endl; // 1234
cout<<adat.s.hi<<endl; // ABCD
for (int i=0; i<4; i++)
cout<<(int)adat.c[i]<<endl; // 34 12 CD AB
adat.c[0]++;
adat.s.hi+=2;
cout <<adat.l<<endl; // ABCF1235
}
I.8.3.1. Névtelen uniók használata
A C++ szabvány lehetővé teszi, hogy az unió definíciójában csupán adattagok szerepeljenek. Az ilyen, ún. névtelen uniók tagjai az uniót tartalmazó környezet változóiként jelennek meg. Ez a környezet lehet egy modul, egy függvény, egy struktúra vagy egy osztály.
Az alábbi példában az a és b, illetve a c és f normál változókként érhetők el, azonban az uniónak megfelelő módon, átlapoltan tárolódnak a memóriában.
static union {
long a;
double b;
};
int main() {
union {
char c[4];
float f;
};
a = 2012;
b = 1.2; // a értéke megváltozott!
f = 0;
c[0] = 1; // f értéke megváltozott!
}
Amennyiben egy struktúrába (osztályba) névtelen uniót ágyazunk, annak adattagjai a struktúra (osztály) tagjaivá válnak, bár továbbra is átlapoltak lesznek.
A következő példában bemutatjuk a struct és a union típusok együttes alkalmazását. Sokszor szükség lehet arra, hogy egy állomány rekordjaiban tárolt adatok rekordonként más-más felépítésűek legyenek. Tételezzük fel, hogy minden rekord tartalmaz egy nevet és egy értéket, amely hol szöveg, hol pedig szám! Helytakarékos megoldáshoz jutunk, ha a struktúrán belül unióba egyesítjük a két lehetséges értéket ( variáns rekord ):
#include <iostream>
using namespace std;
struct vrekord {
char tipus;
char nev[25];
union {
char cim[50];
unsigned long ID;
}; // <---- nincs tagnév!
};
int main() {
vrekord vr1={0,"BME","Budapest, Muegyetem rkpt 3-11."};
vrekord vr2={1, "Nemzeti Bank"};
vr2.ID=3751564U;
for (int i=0; i<2; i++) {
cout<<"Nev : "<<vr1.nev<<endl;
switch (vr1.tipus) {
case 1 :
cout<<"ID : "<<vr1.ID<<endl;
break;
case 0 :
cout<<"Cim : "<<vr1.cim<<endl;
break;
default :
cout<<"Hibas adattipus!"<<endl;
}
vr1 = vr2;
}
}
A program futásának eredménye:
|
Nev : BME Cim : Budapest, Muegyetem rkpt 3-11. Nev : Nemzeti Bank ID : 3751564 |
I.8.4. Bitmezők használata
Az osztályok és a struktúrák olyan tagokat is tartalmazhatnak, melyek tárolásához az egész típusoknál kisebb helyet használ a fordító. Mivel ezeknél a tagoknál bitszámban mondjuk meg a tárolási hosszt, bitmezőknek hívjuk őket. A bitmezők általános deklarációja:
típus bitmezőnév : bithossz;
A típus tetszőleges egész jellegű típus lehet (az enum is). A bitmező nevének elhagyásával névtelen bitmezőt hozunk létre, melynek célja a nem használt bitpozíciók kitöltése. A bitmező hosszát konstans kifejezéssel kell megadnunk. A bithossz maximális értékét az adott számítógépen a legnagyobb egész típus bitmérete határozza meg.
A struktúra és az osztály típusokban a bitmezők és az adattagok vegyesen is szerepelhetnek:
#include <iostream>
using namespace std;
#pragma pack(1)
struct datum {
unsigned char unnep : 1; // 0..1
unsigned char nap : 6; // 0..31
unsigned char honap : 5; // 0..16
unsigned short ev;
};
int main() {
datum ma = { 0, 2, 10, 2012 };
datum unnep = {1};
unnep.ev = 2012;
unnep.honap = 12;
unnep.nap = 25;
}
Ha a bitstruktúra deklarációjában nem adunk nevet a bitmezőnek, akkor a megadott bithosszúságú területet nem tudjuk elérni (hézagpótló bitek). Amennyiben a névtelen bitmezők hosszát 0-nak adjuk meg, akkor az ezt követő adattagot (vagy bitmezőt) int határra igazítja a fordítóprogram.
Az alábbi példában az RS232 portok vonalvezérlő regiszterének (LCR) elérését tesszük kényelmessé bitmezők segítségével:
#include <iostream>
#include <conio.h>
using namespace std;
union LCR {
struct {
unsigned char adathoosz : 2;
unsigned char stopbitek : 1;
unsigned char paritas : 3;
unsigned char : 2;
} bsLCR;
unsigned char byLCR;
};
enum RS232port {eCOM1=0x3f8, eCOM2=0x2f8 };
int main() {
LCR reg = {};
reg.bsLCR.adathoosz = 3; // 8 adatbit
reg.bsLCR.stopbitek = 0; // 1 stopbit
reg.bsLCR.paritas = 0; // nincs paritás
outport(eCOM1+3, reg.byLCR);
}
A már megismert bitenkénti operátorok segítségével szintén elvégezhetők a szükséges műveletek, azonban a bitmezők használatával strukturáltabb kódot kapunk.
A fejezet végén felhívjuk a figyelmet a bitmezők használatának hátrányaira:
-
A keletkező forráskód nem hordozható, hiszen a különböző rendszerekben a bitek elhelyezkedése a bájtokban, a szavakban eltérő lehet.
-
A bitmezők címe nem kérdezhető le (&), hiszen nem biztos, hogy bájthatáron helyezkednek el.
-
Amennyiben a bitmezőkkel közös tárolási egységben több változót is elhelyezünk, a fordító kiegészítő kódot generál a változók kezelésére (lassul a program futása, és nő a kód mérete.)